概述
数据库索引对于数据库的性能优化是至关重要的。
因此,在本文中,我们将会对数据库进行展开,详细讲解数据库索引的原理、使用原则和推荐使用模式。
什么是索引
数据库中的索引,就好比一本书的目录,它可以帮我们快速进行特定值的定位与查找,从而加快数据查询的效率。也就是说索引就是帮助数据库管理系统高效获取数据的数据结构。
如果我们不使用索引,就必须从第 1 条记录开始扫描,直到把所有的数据表都扫描完,才能找到想要的数据。
索引的种类
从功能逻辑上说,索引主要有 4 种:
- 普通索引:是基础的索引,没有任何约束,主要用于提高查询效率。
- 唯一索引:在普通索引的基础上增加了数据唯一性的约束,在一张数据表里可以有多个唯一索引。
- 主键索引:在唯一索引的基础上增加了不为空的约束,也就是 NOT NULL+UNIQUE,一张表里最多只有一个主键索引。
- 全文索引:MySQL 自带的全文索引只支持英文,通常全文索引主要用于 ES、Solr 等专用的全文索引存储引擎。
从物理实现上看,索引可以分为 2 种:
- 聚集索引:聚集索引通常是针对主键的,可以按照主键来在物理空间排序并存储数据,这样在查找行的时候非常有效。如果是一本汉语字典,我们想要查找“数”这个字,直接在书中找汉语拼音的位置即可,也就是拼音“shu”。这样找到了索引的位置,在它后面就是我们想要找的数据行。(字母表索引就是聚集索引)
- 非聚集索引(二级索引/辅助索引):在数据库系统会有单独的存储空间存放非聚集索引,这些索引项是按照顺序存储的,但索引项指向的内容是随机存储的。也就是说系统会进行两次查找,第一次先找到索引,第二次找到索引对应的位置取出数据行。还以汉语字典为例,如果想要查找“数”字,那么按照部首查找的方式,先找到“数”字的偏旁部首,然后这个目录会告诉我们“数”字存放到第多少页,我们再去指定的页码找这个字。(偏旁部首索引就是非聚集索引)
聚集索引与非聚集索引的原理不同,在使用上也有一些区别:
- 聚集索引的叶子节点存储的就是我们的数据记录,非聚集索引的叶子节点存储的是数据位置。非聚集索引不会影响数据表的物理存储顺序。
- 一个表只能有一个聚集索引(对应主键),因为只能有一种排序存储的方式,但可以有多个非聚集索引,也就是多个索引目录提供数据检索。
- 使用聚集索引的时候,数据的查询效率比非聚集索引会更高,但如果对数据进行插入,删除,更新等操作,效率会比非聚集索引低。
从索引字段个数上看,索引也可以分为 2 种:
- 单一索引:索引列为一列。
联合索引:多个列组合在一起创建的索引。创建联合索引时,我们需要注意创建时的顺序问题,不同顺序的索引对于查询的效率影响非常大,联合索引存在最左匹配原则,也就是按照最左优先的方式进行索引的匹配。
索引的使用原则
其实索引不是万能的,在有些情况下使用索引反而会让效率变低。
那么,我们在什么情况下不需要使用索引?在数据表中的数据行数比较少的情况下,比如不到 1000 行,是不需要创建索引的;
- 当数据重复度大,比如高于 10% 的时候,也不需要对这个字段使用索引;
了解了什么场景下不需要创建索引之后,我们再来看一下什么场景需要创建索引吧:
索引的原理
数据库服务器有两种存储介质,分别为硬盘和内存。内存属于临时存储,容量有限,而且当发生意外时(比如断电或者发生故障重启)会造成数据丢失;硬盘相当于永久存储介质,这也是为什么我们需要把数据保存到硬盘上。
虽然内存的读取速度很快,但我们还是需要将索引存放到硬盘上,这样的话,当我们在硬盘上进行查询时,也就产生了硬盘的 I/O 操作。相比于内存的存取来说,硬盘的 I/O 存取消耗的时间要高很多。我们通过索引来查找某行数据的时候,需要计算产生的磁盘 I/O 次数,当磁盘 I/O 次数越多,所消耗的时间也就越大。如果我们能让索引的数据结构尽量减少硬盘的 I/O 操作,所消耗的时间也就越小。
二叉树 & 平衡二叉树
二分查找法是一种高效的数据检索方式,时间复杂度为 O(log2n),是不是采用二叉树就适合作为索引的数据结构呢?
我们先来简单了解一下什么是二叉树:
最基础的二叉搜索树(Binary Search Tree),搜索某个节点和插入节点的规则一样,我们假设搜索插入的数值为 key:
- 如果 key 大于根节点,则在右子树中进行查找;
- 如果 key 小于根节点,则在左子树中进行查找;
- 如果 key 等于根节点,也就是找到了这个节点,返回根节点即可。
以下图为例,就是一个标准的二叉树: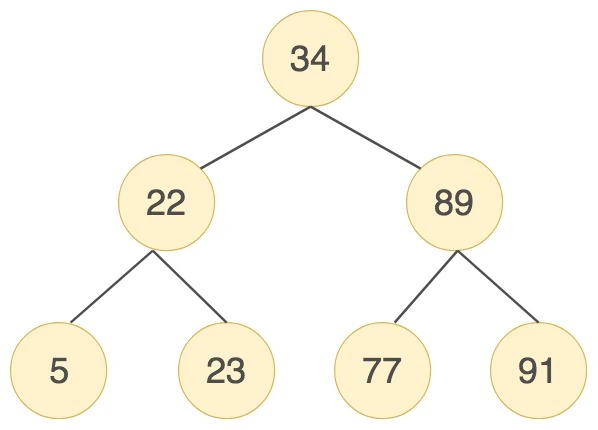
但是存在特殊的情况,就是有时候二叉树的深度非常大。比如我们给出的数据顺序是 (5, 22, 23, 34, 77, 89, 91),创造出来的二分搜索树如下图所示:
可以看到,第一个树的深度是 3,也就是说最多只需 3 次比较,就可以找到节点,而第二个树的深度是 7,最多需要 7 次比较才能找到节点。
为了解决这个问题,人们提出了平衡二叉搜索树(AVL 树),它在二分搜索树的基础上增加了约束,每个节点的左子树和右子树的高度差不能超过 1,也就是说节点的左子树和右子树仍然为平衡二叉树。
那么,平衡二叉树是不是非常适合用于做数据库索引呢?实际上不是的。
之前我们在索引原理部分提到了相比于内存的存取来说,硬盘的 I/O 存取消耗的时间要高很多。如果我们采用二叉树的形式,即使通过平衡二叉搜索树进行了改进,树的深度也是 O(log2n),当 n 比较大时,深度也是比较高的,比如下图的情况:
每访问一次节点就需要进行一次磁盘 I/O 操作,对于上面的树来说,我们最多需要进行 5 次 I/O 操作。虽然平衡二叉树比较的效率高,但是树的深度也同样比较高,而每增加一层树的深度,就需要多进行一次磁盘I/O操作。这就意味着磁盘 I/O 操作次数多,会影响整体数据查询的效率。
针对同样的数据,如果我们把二叉树改成 M 叉树(M>2)呢?当 M=3 时,同样的 31 个节点可以由下面的三叉树来进行存储:
这样一来,可以看到树的高度就降低了,随着 M 分叉增多,可以有效的降低磁盘 I/O 操作。
B 树
B 树的出现就是为了解决二叉树高度过高的问题。B 树的英文是 Balance Tree,也就是平衡的多路搜索树,它的高度远小于平衡二叉树的高度。在文件系统和数据库系统中的索引结构经常采用 B 树来实现。
B 树的结构如下图所示: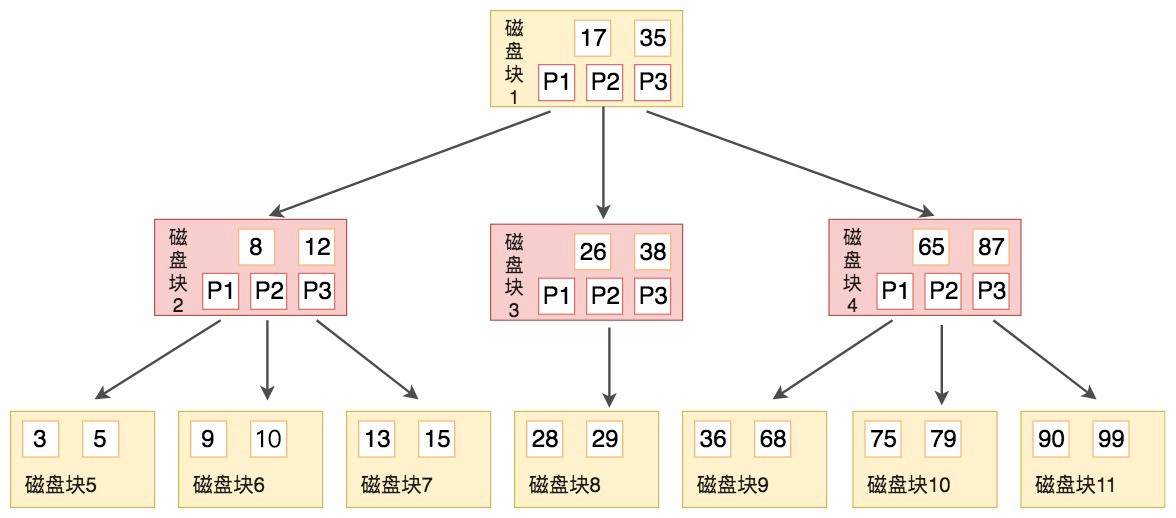
B 树作为平衡的多路搜索树,它的每一个节点最多可以包括 M 个子节点(如上图所示,M为3),M 称为 B 树的阶。其中,每个磁盘块中包括了关键字和子节点的指针。如果一个磁盘块中包括了 x 个关键字,那么指针数就是 x+1。
对于一个 100 阶的 B 树来说,如果有 3 层的话最多可以存储约 100 万的索引数据。对于大量的索引数据来说,采用 B 树的结构是非常适合的,因为树的高度要远小于二叉树的高度。
一个 M 阶的 B 树(M>2)有以下的特性:
- 根节点的儿子数的范围是[2,M]。
- 每个中间节点包含 k-1 个关键字和 k 个孩子,k 的取值范围为[ceil(M/2), M]。
- 叶子节点包括 k-1 个关键字(叶子节点没有孩子),k 的取值范围为[ceil(M/2), M]。
- 假设中间节点节点的关键字为:Key[1], Key[2], …, Key[k-1],且关键字按照升序排序,即 Key[i] < Key[i+1]。此时 k-1 个关键字相当于划分了 k 个范围,也就是对应着 k 个指针,即为:P[1], P[2], …, P[k],其中 P[1]指向关键字小于 Key[1]的子树,P[i]指向关键字属于 (Key[i-1], Key[i]) 的子树,P[k]指向关键字大于 Key[k-1]的子树。
- 所有叶子节点位于同一层。
B+树索引
Hash索引
数据页

若有收获,就点个赞吧
0 人点赞
