概述
在本文中,我们会先后介绍如何在 Python 中通过 mysql-connector 和 SQL Alchemy 两种模式进行 MySQL 等关系型数据库的操作。
Python 可以支持非常多的数据库管理系统,比如 MySQL、Oracle、SQL Server 和 PostgreSQL 等。
为了实现对这些 DBMS 的统一访问,Python 需要遵守一个规范,这就是 DB API 规范。我在下图中列出了 DB API 规范的作用,这个规范给我们提供了数据库对象连接、对象交互和异常处理的方式,为各种 DBMS 提供了统一的访问接口。
这样做的好处就是如果项目需要切换数据库,Python 层的代码移植会比较简单。
我们在使用 Python 对 DBMS 进行操作的时候,需要经过下面的几个步骤:
- 引入 API 模块;
- 与数据库建立连接;
- 执行 SQL 语句;
- 关闭数据库连接。
mysql-connector-python 快速上手
mysql-connector-python 是 MySQL 官方提供的针对 Python 的驱动 Driver,下面,我们以 mysql-connector-python 为例,演示在 Python 中如何连接 MySQL 进行数据操作。安装
在 Python 中,我们可以通过 pip 包管理器来进行依赖安装:pip install mysql-connector-python
初识 mysql-connector-python
安装完成后,我们可以编写一个示例代码进行数据库的操作:
在上述代码中,我们查询了 MySQL 的版本信息。# -*- coding: UTF-8 -*-import mysql.connector# 打开数据库连接db = mysql.connector.connect(host="127.0.0.1",port=3306,user="root", # 用户名password="123456", # 密码database="demo",)# 获取操作游标cursor = db.cursor()# 执行SQL语句cursor.execute("SELECT VERSION()")# 获取一条数据data = cursor.fetchone()print("MySQL版本: %s " % data)# 关闭游标&数据库连接cursor.close()db.close()
期望输出如下:
上面这段代码中有两个重要的对象你需要了解下,分别是 Connection 和 Cursor。
Connection 就是对数据库的当前连接进行管理,我们可以通过它来进行以下操作:
- 通过指定 host、user、passwd 和 port 等参数来创建数据库连接,这些参数分别对应着数据库 IP 地址、用户名、密码和端口号;
- 使用 db.close() 关闭数据库连接;
- 使用 db.cursor() 创建游标,操作数据库中的数据;
- 使用 db.begin() 开启事务;
- 使用 db.commit() 和 db.rollback(),对事务进行提交以及回滚。
当我们通过cursor = db.cursor()创建游标后,就可以通过面向过程的编程方式对数据库中的数据进行操作:
- 使用cursor.execute(query_sql),执行数据库查询;
- 使用cursor.fetchone(),读取数据集中的一条数据;
- 使用cursor.fetchall(),取出数据集中的所有行,返回一个元组 tuples 类型;
- 使用cursor.fetchmany(n),取出数据集中的多条数据,同样返回一个元组 tuples;
- 使用cursor.rowcount,返回查询结果集中的行数。
- 如果没有查询到数据或者还没有查询,则结果为 -1,否则会返回查询得到的数据行数;
-
数据表的增、删、改、查
下面,我们来看下如何来对 heros 数据表进行 CRUD 的操作,即增加、读取、更新和删除。
首先是新增数据,假设我们想在 player 表中增加一名新球员,姓名为“约翰·科林斯”,球队 ID 为 1003(即亚特兰大老鹰),身高为 2.08m。代码如下:# 插入新球员sql = "INSERT INTO player (team_id, player_name, height) VALUES (%s, %s, %s)"val = (1003, "约翰-科林斯", 2.08)cursor.execute(sql, val)db.commit()print(cursor.rowcount, "记录插入成功。")
我们使用 cursor.execute 来执行相应的 SQL 语句,val 为 SQL 语句中的参数,SQL 执行后使用 db.commit() 进行提交。
PS: 我们在使用 SQL 语句的时候,可以向 SQL 语句传递参数,这时 SQL 语句里要统一用(%s)进行占位,否则就会报错。不论插入的数值为整数类型,还是浮点类型,都需要统一用(%s)进行占位。
- 在用游标进行 SQL 操作之后,还需要使用 db.commit() 进行提交,否则数据不会被插入。
然后是读取数据,我们来看下数据是否被插入成功,这里我们查询下身高大于等于 2.08m 的球员都有哪些,代码如下:
# 查询身高大于等于2.08的球员sql = 'SELECT player_id, player_name, height FROM player WHERE height>=2.08'cursor.execute(sql)data = cursor.fetchall()for each_player in data:print(each_player)
运行结果:
可以看到球员约翰·科林斯被正确插入。
如何修改数据呢?假如我想修改刚才插入的球员约翰·科林斯的身高,将身高修改成 2.09,代码如下:
# 修改球员约翰-科林斯sql = 'UPDATE player SET height = %s WHERE player_name = %s'val = (2.09, "约翰-科林斯")cursor.execute(sql, val)db.commit()print(cursor.rowcount, "记录被修改。")
最后,我们来删除掉对应记录:
sql = 'DELETE FROM player WHERE player_name = %s'val = ("约翰-科林斯",)cursor.execute(sql, val)db.commit()print(cursor.rowcount, "记录删除成功。")
ORM 介绍
用 Python 操作 MySQL,还有很多种姿势,mysql-connector 只是其中一种,实际上还有另外一种方式,就是采用 ORM 框架。
在讲解 ORM 框架之前,我们需要先了解什么是持久化。
如下图所示,持久化层在业务逻辑层和数据库层起到了衔接的作用,它可以将内存中的数据模型转化为存储模型,或者将存储模型转化为内存中的数据模型。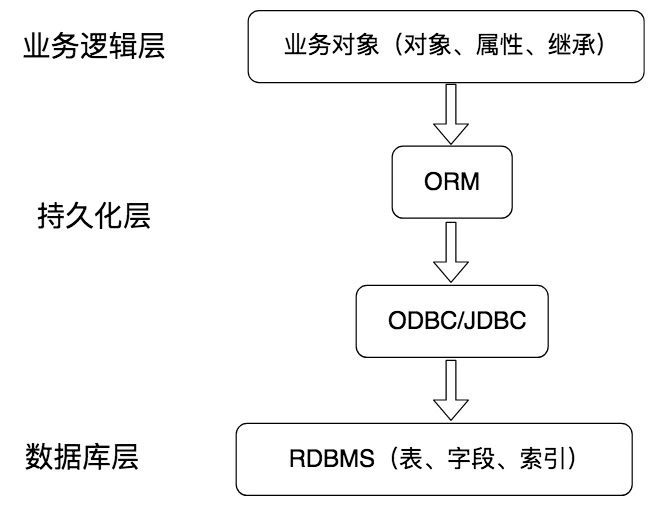
ORM 的英文是 Object Relational Mapping,也就是采用对象关系映射的模式,使用这种模式可以将数据库中各种数据表之间的关系映射到程序中的对象。这种模式可以屏蔽底层的数据库的细节,不需要我们与复杂的 SQL 语句打交道,直接采用操作对象的形式操作就可以。
采用 ORM,就可以从数据库的设计层面转化成面向对象的思维。
随着项目规模的增大,在代码层编写 SQL 语句访问数据库会降低开发效率,也会提升维护成本,因此越来越多的开发人员会采用基于 ORM 的方式来操作数据库。这样做的好处就是一旦定义好了对象模型,就可以让它们简单可复用,从而不必关注底层的数据库访问细节,我们只要将注意力集中到业务逻辑层面就可以了。由此还可以带来另一点好处,那就是即便数据库本身进行了更换,在业务逻辑代码上也不会有大的调整。这是因为 ORM 抽象了数据的存取,同时也兼容多种 DBMS,我们不用关心底层采用的到底是哪种 DBMS,是 MySQL,SQL Server,PostgreSQL 还是 SQLite。
当然,采用 ORM 当然也会付出一些代价,比如性能上的一些损失。面对一些复杂的数据查询,ORM 会显得力不从心。虽然可以实现功能,但相比于直接编写 SQL 查询语句来说,ORM 需要编写的代码量和花费的时间会比较多,这种情况下,直接编写 SQL 反而会更简单有效。
Python 中的 ORM 框架
目前 Python 中有三种主流的 ORM 框架。
第一个是 Django,它是 Python 的 WEB 应用开发框架,本身走大而全的方式。Django 采用了 MTV 的框架模式,包括了 Model(模型),View(视图)和 Template(模版)。Model 模型只是 Django 的一部分功能,我们可以通过它来实现数据库的增删改查操作。
第二个是 SQLALchemy,它也是 Python 中常用的 ORM 框架之一。它提供了 SQL 工具包及 ORM 工具,如果你想用支持 ORM 和支持原生 SQL 两种方式的工具,那么 SQLALchemy 是很好的选择。
第三个是 peewee,这是一个轻量级的 ORM 框架,简单易用。peewee 采用了 Model 类、Field 实例和 Model 实例来与数据库建立映射关系,从而完成面向对象的管理方式。使用起来方便,学习成本也低。
SQLAlchemy 快速上手
下面,我们以 SQLAlchemy 为例,对 player 数据表进行增删改查。
安装
开始之前,我们还是需要安装对应的第三方库:
pip install sqlalchemy
下面,我们来验证一下安装是否成功:
# -*- coding: UTF-8 -*-from sqlalchemy import create_engineengine = create_engine('mysql+mysqlconnector://root:123456@localhost:3306/demo')engine.connect()print(engine.name)
如果能够正常打印 MySQL ,那么就说明 sqlalchemy 已经安装成功啦!
创建模型
我们以之前的 player 表为例,创建一个 Python 对应的 player 类模型:
from sqlalchemy.orm import declarative_basefrom sqlalchemy import Column, String, Integer, FloatBase = declarative_base()# 定义Player对象:class Player(Base):# 表的名字:__tablename__ = 'player'# 表的结构:player_id = Column(Integer, primary_key=True, autoincrement=True)team_id = Column(Integer)player_name = Column(String(255))height = Column(Float(3,2))
其中:
- tablename 指明了模型对应的数据表名称,即 player 数据表;
- Player 类中对采用的变量名进行定义,变量名需要和数据表中的字段名称保持一致,否则会找不到数据表中的字段。
在 SQLAlchemy 中,我们采用 Column 对字段进行定义,常用的数据类型如下:
除了指定 Column 的数据类型以外,我们也可以指定 Column 的参数,这些参数可以帮我们对对象创建列约束: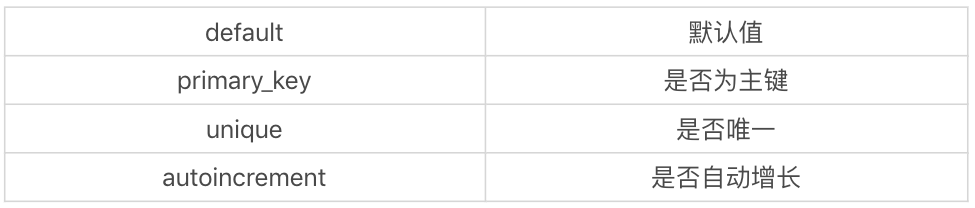
数据的增、删、改、查
假设我们想给 player 表增加一名新球员,姓名为“约翰·科林斯”,球队 ID 为 1003(即亚特兰大老鹰),身高为 2.08。代码如下:
from sqlalchemy.orm import sessionmaker# 创建DBSession类型:DBSession = sessionmaker(bind=engine)# 创建session对象:session = DBSession()# 创建Player对象:new_player = Player(team_id=1003, player_name="约翰-科林斯", height=2.08)# 添加到session:session.add(new_player)# 提交即保存到数据库:session.commit()# 关闭session:session.close()
其中:
- 首先。需要初始化 DBSession,相当于创建一个数据库的会话实例 session。
- 然后,通过 Player 类来完成创建,在参数中指定相应的team_id, player_name, height即可。
- 再把创建好的对象 new_player 添加到 session 中,提交到数据库即可完成添加数据的操作。
接下来看一下如何查询数据,添加完插入的新球员之后,我们可以查询下身高 ≥ 2.08m 的球员都有哪些,代码如下:
#增加to_dict()方法到Base类中def to_dict(self):return {c.name: getattr(self, c.name, None)for c in self.__table__.columns}#将对象可以转化为dict类型Base.to_dict = to_dict# 查询身高>=2.08的球员有哪些rows = session.query(Player).filter(Player.height >= 2.08).all()print([row.to_dict() for row in rows])
在进行查询的时候,我们使用的是 filter 方法,对应的是 SQL 中的 WHERE 条件查询。除此之外,filter 也支持多条件查询。
如果是 AND 的关系,比如我们想要查询身高 ≥ 2.08,同时身高 ≤ 2.10 的球员,可以写成下面这样:
rows = session.query(Player).filter(Player.height >= 2.08, Player.height <= 2.10).all()
如果是 OR 的关系,比如我们想要查询身高 ≥ 2.08,或者身高 ≤ 2.10 的球员,可以写成这样:
from sqlalchemy import or_rows = session.query(Player).filter(or_(Player.height >=2.08, Player.height <=2.10)).all()
除了多条件查询,SQLAlchemy 也同样支持分组操作、排序和返回指定数量的结果。
比如我想要按照 team_id 进行分组,同时筛选分组后数据行数大于 5 的分组,并且按照分组后数据行数递增的顺序进行排序,显示 team_id 字段,以及每个分组的数据行数。那么代码如下:
from sqlalchemy import funcrows = session.query(Player.team_id, func.count(Player.player_id)).group_by(Player.team_id).having(func.count(Player.player_id) > 5).order_by(func.count(Player.player_id).asc()).all()print(rows)
我们需要注意如下几点:
- 把需要显示的字段 Player.team_id, func.count(Player.player_id) 作为 query 的参数,其中我们需要用到 sqlalchemy 的 func 类,它提供了各种聚集函数,比如 func.count 函数。
- 在 query() 后面使用了 group_by() 进行分组,参数设置为 Player.team_id 字段,再使用 having 对分组条件进行筛选,参数为func.count(Player.player_id)>5。
- 使用 order_by 进行排序,参数为func.count(Player.player_id).asc(),也就是按照分组后的数据行数递增的顺序进行排序,最后使用.all() 方法需要返回全部的数据。
事实上,SQLAlchemy 使用的规则和使用 SELECT 语句的规则差不多,只是封装到了类中作为方法进行调用。
最后来看一下如何进行数据删除,如果我们想要删除某些数据,需要先进行查询,然后再从 session 中把这些数据删除掉。
比如我们想要删除姓名为约翰·科林斯的球员,首先我们需要进行查询,然后从 session 对象中进行删除,最后进行 commit 提交,代码如下:
row = session.query(Player).filter(Player.player_name=='约翰-科林斯').first()session.delete(row)session.commit()session.close()
PS:判断球员姓名是否为约翰·科林斯,这里需要使用(==)。
修改数据与删除类似,如果我们想要修改某条数据,也需要进行查询,然后再进行修改。比如我想把球员索恩·马克的身高改成 2.17,那么执行完之后直接对 session 对象进行 commit 操作,代码如下:
row = session.query(Player).filter(Player.player_name=='索恩-马克').first()row.height = 2.17session.commit()session.close()

若有收获,就点个赞吧
0 人点赞
