概述
在 MySQL 5.5 版本之前,默认的存储引擎是 MyISAM,在 5.5 版本之后默认存储引擎是 InnoDB。InnoDB 和 MyISAM 区别之一就是 InnoDB 支持事务,也可以说这是 InnoDB 取代 MyISAM 的重要原因。
事务的英文是 transaction,从英文中你也能看出来它是进行一次处理的基本单元,要么完全执行,要么都不执行。
在本文中,我们将会围绕数据库中的事务相关概念进行展开介绍。
事务特性
我们经常会提到事物的 4 个特性,有英文字母表示就是ACID。我们来拆开看一下:
- A,也就是原子性(Atomicity)。原子的概念就是不可分割,你可以把它理解为组成物质的基本单位,也是我们进行数据处理操作的基本单位。
- C,就是一致性(Consistency)。一致性指的就是数据库在进行事务操作后,会由原来的一致状态,变成另一种一致的状态。也就是说当事务提交后,或者当事务发生回滚后,数据库的完整性约束不能被破坏。
- I,就是隔离性(Isolation)。它指的是每个事务都是彼此独立的,不会受到其他事务的执行影响。也就是说一个事务在提交之前,对其他事务都是不可见的。
D,指的是持久性(Durability)。事务提交之后对数据的修改是持久性的,即使在系统出故障的情况下,比如系统崩溃或者存储介质发生故障,数据的修改依然是有效的。
快速上手事务
在 MySQL 中,则需要选择适合的存储引擎才可以支持事务。如果你使用的是 MySQL,可以通过 SHOW ENGINES 命令来查看当前 MySQL 支持的存储引擎都有哪些,以及这些存储引擎是否支持事务:
SHOW ENGINES;

可以看出,InnoDB 是支持事务的,而 MyISAM 存储引擎不支持事务。
我们再来看下事务的常用控制语句都有哪些:START TRANSACTION 或者 BEGIN,作用是显式开启一个事务。
- COMMIT:提交事务。当提交事务后,对数据库的修改是永久性的。
- SAVEPOINT:在事务中创建保存点,方便后续针对保存点进行回滚。一个事务中可以存在多个保存点。
- RELEASE SAVEPOINT:删除某个保存点。
- ROLLBACK 或者 ROLLBACK TO [SAVEPOINT],意为回滚事务。意思是撤销正在进行的所有没有提交的修改,或者将事务回滚到某个保存点。
- SET TRANSACTION,设置事务的隔离级别。
事实上,事务又可以分为隐式事务和显式事务。隐式事务实际上就是自动提交,而显示事务就是需要手写COMMIT命令才会提交。
像 Oracle 默认就是显式事务,即只有COMMIT后才会提交。而 MySQL 默认自动提交,即如果没有开启事务,默认每条命令完成后都会自动提交,无需 COMMIT 操作。
当然,我们可以配置 MySQL 的参数来控制是否自动提交:
set autocommit = 0; //关闭自动提交set autocommit = 1; //开启自动提交
下面,我们来以一个具体的实例来演示一下什么是事务,在默认状态下(自动提交):
CREATE TABLE test(name varchar(255), PRIMARY KEY (name)) ENGINE=InnoDB;BEGIN;INSERT INTO test SELECT '关羽';COMMIT;BEGIN;INSERT INTO test SELECT '张飞';INSERT INTO test SELECT '张飞';ROLLBACK;SELECT * FROM test;
上述指令的运行结果会得到一条记录,就是”关羽”。
具体来说,针对第一个事务,插入关羽记录成功后,然后通过 COMMIT 指令来提交并持久化。
而针对第二个事务,连续两次写入张飞后,由于表中要求 name 为主键,即需要满足唯一性,因此,第二次写入张飞会失败,而由于失败后我们执行了 ROLLBACK 操作,因此整个事务内的操作均会回滚,即第一次写入张飞的操作也会回滚掉。最终一次张飞都没有写入。
那观察一下下述 SQL 的执行结果呢?
CREATE TABLE test(name varchar(255), PRIMARY KEY (name)) ENGINE=InnoDB;BEGIN;INSERT INTO test SELECT '关羽';COMMIT;INSERT INTO test SELECT '张飞';INSERT INTO test SELECT '张飞';ROLLBACK;SELECT * FROM test;
整体逻辑与上述代码非常类似,唯一的区别在于写入张飞数据之前没有主动开启一个事务。
而正是因为上述的调整,会导致命令执行完成后会得到两条记录:关羽、张飞。
那么为什么呢?我们来看一下。
针对第一个事务,和上述场景一致,直接自动写入了。
而由于没有主动开启事务,MySQL 默认会进行自动提交,即接下来的两次插入张飞记录会直接提交并执行,第一次写入张飞会成功、第二次写入张飞时由于主键冲突会写入失败。此时的 ROLLBACK 由于没有处于一个事务中,因此也没有实际效果。所以查询结果会有两条,分别是关羽和张飞。
但是如果我们再次修改一下 SQL 逻辑如下:
CREATE TABLE test(name varchar(255), PRIMARY KEY (name)) ENGINE=InnoDB;SET @@completion_type = 1;BEGIN;INSERT INTO test SELECT '关羽';COMMIT;INSERT INTO test SELECT '张飞';INSERT INTO test SELECT '张飞';ROLLBACK;SELECT * FROM test;
可以看到,我们在事务开始之前设置了SET @@completion_type = 1;,结果就和我们第一次处理的一样,只有一个“关羽”。这是为什么呢?
这就涉及到了 completion_type 参数的作用啦!completion_type 参数可以有三个取值,分别表示不同的含义:
- 0:默认情况。也就是说当我们执行 COMMIT 的时候会提交事务,在执行下一个事务时,还需要我们使用 START TRANSACTION 或者 BEGIN 来开启。
- 1:当我们提交事务后,相当于执行了 COMMIT AND CHAIN,也就是开启一个链式事务,即当我们提交事务之后会开启一个相同隔离级别的事务。
- 2:相当于 COMMIT=COMMIT AND RELEASE,也就是当我们提交后,会自动与服务器断开连接。
因为,我们设置 completion_type 为 1 之后,第一个 COMMIT 相当于了 COMMIT and BEGIN,因此最终的效果上和示例 1 是一致的。
事务并发处理可能导致的问题
我们已经知道隔离性是事务的基本特性之一,它可以防止数据库在并发处理时出现数据不一致的情况。最严格的情况下,我们可以采用串行化的方式来执行每一个事务,这就意味着事务之间是相互独立的,不存在并发的情况。
然而在实际生产环境下,考虑到随着用户量的增多,会存在大规模并发访问的情况,这就要求数据库有更高的吞吐能力,这个时候串行化的方式就无法满足数据库高并发访问的需求,我们还需要降低数据库的隔离标准,来换取事务之间的并发能力。
那么,降低数据库的隔离标准就会可能导致一系列相关的问题,SQL-92 标准中已经对 3 种异常情况进行了定义,这些异常情况级别分别为脏读(Dirty Read)、不可重复读(Nonrepeatable Read)和幻读(Phantom Read)。
脏读
比如说我们有个英雄表 heros_temp,如下所示: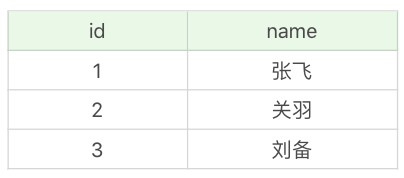
假设我们不对事务进行隔离操作,那么数据库在进行事务的并发处理时会出现怎样的情况?
假设 A 正在访问数据库,开启了一个事务,准备写入一条记录”吕布”:
BEGIN;INSERT INTO heros_temp values(4, '吕布');
但是在数据操作还没有 COMMIT 之前,B 发起了数据查询,结果已经查询到了”吕布”,如下所示:
这个时候,假设 A 没有 COMMIT,还是发起了 ROLLBACK 操作,那么数据库中实际上从来不应该有”吕布”,而 B 读到的”吕布”数据实际是不应该的,因此这其实就是脏数据,也称为”脏读”。
简单总结一下:读取到了某个事务中还没有COMMIT的数据,就这是脏读。
不可重复读
那什么是不可重复读呢?我们再来看一个示例。
A 想查看 id=1 的英雄是谁,于是他进行了 SQL 查询并开启了一个事务:
BEGIN;SELECT name FROM heros_temp WHERE id = 1;
运行结果如下:
就在此时,B 也开始了一个事务,对 id=1 的英雄姓名进行了修改,把原来的“张飞”改成了“张翼德”:
BEGIN;UPDATE heros_temp SET name = '张翼德' WHERE id = 1;COMMIT;
然后 A 在当前事务中又再一次进行查询,同样也是查看 id=1 的英雄是谁:
SELECT name FROM heros_temp WHERE id = 1;

这个时候你会发现,两次查询的结果并不一样。即在同一个事务中,连续两次查询同一条记录,结果两次的查询结果不同。这就是我们说的”不可重复读”。
简单总结一下:在同一个事务中,重复读取同一条数据返回的结果有所不同,就这是不可重复读。
幻读
我们再来看一个幻读的示例。
A 想要查询数据表中有哪些英雄,于是他进行了 SQL 查询并开启了一个事务:
BEGIN;SELECT * FROM heros_temp;
运行结果如下:
与此同时,B 开始了一个事务,往数据库里插入一个新的英雄“吕布”,并 COMMIT 了:
BEGIN;INSERT INTO heros_temp values(4, '吕布');COMMIT;
当 B Commit 之后,A 又在当前的事务中重新查询了一遍数据表记录:
SELECT * FROM heros_temp;
得到的结果如下:
他发现这一次查询多了一个英雄,原来只有 3 个,现在变成了 4 个。这种异常情况我们称之为“幻读”。
简单总结一下:在同一个事务中,多次读取相同查询条件的数据列表,返回的数据记录有所不同(其他事务插入了新的记录),让你误以为你上一次读错了,就这是幻读。
PS:也有另外一种解释,至少在 MySQL 中,幻读并不是说两次读取获取的结果集不同,幻读侧重的方面是某一次的 select 操作得到的结果所表征的数据状态无法支撑后续的业务操作。更为具体一些:select 某记录是否存在,不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读。
事务的隔离级别
脏读、不可重复读和幻读这三种异常情况,是在 SQL-92 标准中定义的,同时 SQL-92 标准还定义了 4 种隔离级别来解决这些异常情况。
解决异常数量从少到多的顺序决定了隔离级别的高低,这四种隔离级别从低到高分别是:
- 读未提交(READ UNCOMMITTED ),允许读到未提交的数据,这种情况下查询是不会使用锁的,可能会产生脏读、不可重复读、幻读等情况。
- 读已提交(READ COMMITTED),只能读到已经提交的内容,可以避免脏读的产生,属于 RDBMS 中常见的默认隔离级别(比如说 Oracle 和 SQL Server)
- 可重复读(REPEATABLE READ),保证一个事务在查询同一条记录结果是一致的,可以避免不可重复读和脏读,但无法避免幻读。MySQL 默认的隔离级别就是可重复读。
- 可串行化(SERIALIZABLE),将事务进行串行化,也就是在一个队列中按照顺序执行,可串行化是最高级别的隔离等级,可以解决事务读取中所有可能出现的异常情况,但是它牺牲了系统的并发性。
这些隔离级别能解决的异常情况如下表所示: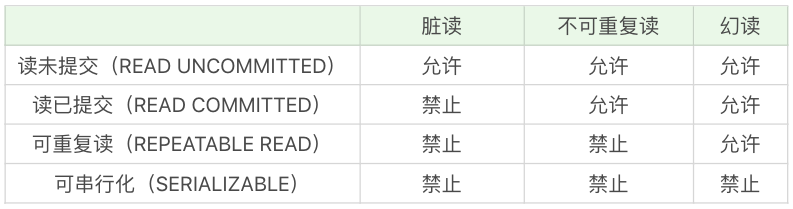
可以看到,可串行化能避免所有的异常情况,而读未提交则允许异常情况发生。
体验一下并发异常
准备工作
为了对事务隔离有一个更加清晰的认识,我们以一个英雄数据表 heros_temp 来体验一下各种类型的并发异常。其中,heros_temp 数据表结构和数据可以从 https://github.com/cystanford/sql_heros_data 下载 heros_temp.sql 文件并执行,实现数据表的创建和数据初始化。
下面,我们在 DataGrip 中分别建立两个连接:
可以两个 Console 连接中,我们可以分别查询一下当前会话的隔离级别,使用命令:
SHOW VARIABLES LIKE 'transaction_isolation';
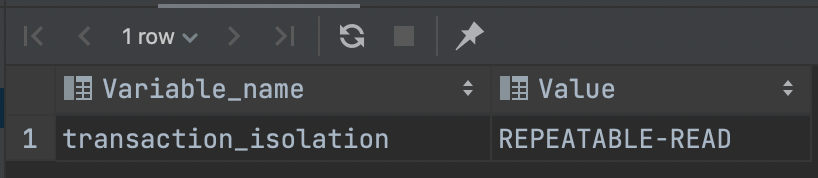
然后,我们可以把隔离级别降到最低,设置为 READ UNCOMMITTED(读未提交):
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;SHOW VARIABLES LIKE 'transaction_isolation';
再查看下当前会话(SESSION)下的隔离级别,结果如下: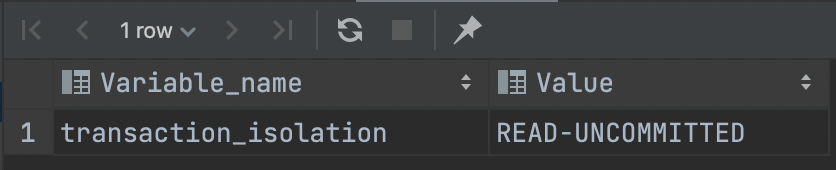
然后再另外一个 Console 中进行相同的会话隔离级别的配置即可。
脏读
我们在 Console 1 中在 heros_temp 表中写入一个新的英雄“吕布”,注意这个时候不要提交:
BEGIN;INSERT INTO heros_temp values (4, '吕布');
然后在 Console 2 中查询数据表:
SELECT * FROM heros_temp;

可以看到,Console 1中数据还没有提交,但是 Console 2 中就已经可以看到对应的数据了。
不可重复读
下面,我们用 Console 1 开启一个事务并查询 id=1 的英雄:
BEGIN;SELECT * FROM heros_temp WHERE id = 1;

然后,我们在 Console 2 中直接对 id = 1 的英雄进行修改:
UPDATE heros_temp SET name = '张翼德' WHERE id = 1;
这时,再用 Console 1 进行查询:
SELECT * FROM heros_temp WHERE id = 1;
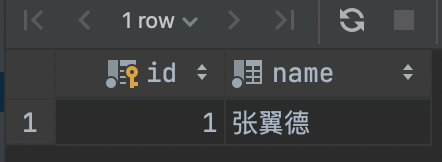
可以看到,在 Console 1 的同一个事务中,查询同一条记录的结果已经发生了变化。
幻读
为了更加明显的体验幻读,我们先在两个 Console 中都将 Session 的事务隔离级别调整一下,避免脏读和不可重复读:
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
然后,我们用 Console 1 开启一个事务并查询数据表中的记录:
BEGIN;SELECT * FROM heros_temp;

然后用 Console 2,开始插入新的英雄“吕布”:
INSERT INTO heros_temp values (4, '吕布');
这个时候,我们用 Console 1 再次查询一下数据表中的记录:
SELECT * FROM heros_temp;
可以看到,查询到的结果依然如下:
但是,我们想要再次在 Console 1 中插入一条 id = 4 的记录:
INSERT INTO heros_temp values (4, '吕布');
此时会直接提示主键 id 冲突,数据无法正常写入,这就是幻读,感觉读到的数据和实际的效果不一致,以为是数据读错了。
串行化
最后的最后,我们再来体验一下将事务级别设置为串行化之后,整体的效果:
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
下面,我们还是用 Console 1 开启一个事务并进行表查询:
BEGIN;SELECT * FROM heros_temp;
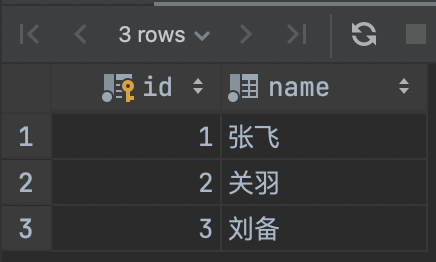
然后,这个时候我们在 Console 2 中一条数据写入:
INSERT INTO heros_temp values (4, '吕布');

可以看到,Console 2 中的数据写入操作会被 Block,直到 Console 1 中的事务 Commit 或者 Rollback 之后,Console 2 中的数据写入才能进行。

若有收获,就点个赞吧
0 人点赞
