一:ODS
二:DWD
1:构建过程
(1):选择业务过程
例如:下单业务,支付业务,退款业务,物流业务等,一条业务对应一张事实表
(2):声明粒度
数据粒度指的仓库的数据中保存数据的细化程度的级别,声明粒度意味着精确定义事实表中一行数据是什么,应尽可能选择最小粒度,以此应付各种需求,
例如:典型的粒度声明如下
订单事实表一行数据表示的是一个订单详细表中的一个商品项,也可以是订单表中的一条订单信息,包含下单时间,订单状态等
(3):确定维度
描述业务事实,主要表示“谁,何处,何时”信息,确定维度的原则:后续需求中是否要分析相关维度的指标,例如,需要统计,什么时间下的订单多,哪个地区下的订单,哪个用户下的订单,需要确定的维度包括:时间维度,地区维度,用户维度
(4):确认事实
此处的事实一次,指的是业务中度量值(次数,个数,件数,金额,可以进行累加),例如订单金额,下单次数等。
在DWD层,以业务过程为建模驱动,基于每个具体业务过程的特点,构建最细粒度的明细层事实表,事实表可做适当的宽表处理。事实表和维度表关联比较灵活,但是为了应对更复杂的业务需求,可以将能关联上的表尽量关联上。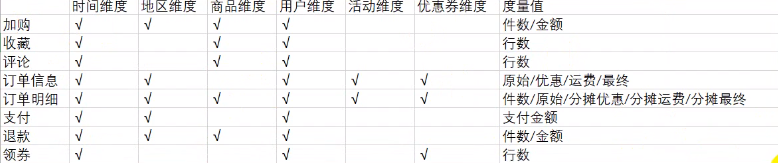
2:事实表
订单事实表:
create external table ‘dwd_fact_order_info’ (
订单编号,
订单状态,
用户id,
支付流水号,
创建时间,
支付时间,
取消时间,
退款时间,
退款完成时间,
省份id,
活动id,
原价金额,
优惠金额,
运费,
订单金额
)
其中原价金额,优惠金额,运费,订单金额是度量值 、省份id,活动id为维度外键
3:维度表
商品维度表:和商品关联的表全部关联到商品维度表里
create external table ‘dwd_dim_sku_info’ (
商品id,
spuid,
商品价格,
商品名称,
商品描述,
重量,
品牌id,
品牌名称,
三级分类id,
二级分类id,
一级分类id,
三级分类名称,
二级分类名称,
一级分类名称,
spu名称,
创建时间
)
三:DWS和DWT
1:问题
2:处理
将省份表和订单表join,group by然后计算,数据被计算了两次如何避免重复计算?
3:设计宽表
设计一张地区宽表,主键为地区id,字段包含:下单次数,下单金额,支付次数,支付金额等,依据上述指标统一计算,将结果保存在宽表中,能避免有效重复计算
4:总结
(1):需要建哪些宽表:以维度为基准
(2):宽表的字段是站在不同维度的角度去看事实表,重点关注事实表聚合后的度量值
(3):DWS和DWT的区别
DWS层存放所有主题对象为当天的汇总行为,例如每个地区当天的下单次数,下单金额,DWT存放所有主题对象的累计行为,例如每个地区近7天(15,30,60天)的下单次数和金额等

若有收获,就点个赞吧
0 人点赞
