一、实验目的
- 使用蛋白质摄取的数据集protein.txt,说明蛋白质摄取的聚类分析操作。
- 数据导入操作,使用输入函数open()与csv.reader()的操作。
- 数据转化为numpy array操作,使用函数np.array()的操作。
- 数据聚类建立模型操作,使用函数KMeans()的操作。
- 列出实验结果包含绘图或截图以及完整代码包含注解。
二、实验内容
说明 1: 举一个蛋白质摄取的档案protein.txt进行聚类说明,共有25个欧洲国家,即25笔纪录,字段有country、Redmeat、Whitemeat、Eggs、Milk、Fish、Cereals、Starch、Nuts和Frozen Vegetable,档案内容如下:
说明 2: 使用函数输入函数open()与csv.reader()将原始数据集protein.txt,导入Python工作空间。
说明 3: 使用函数np.array() 将数据转化为数值。
说明 4: 使用函数KMeans() 建立数据聚类模型,并列出实验结果包含绘图或截图以及完整代码包含注解。三、实验报告
1. 实验环境:
Win102. 实验内容与完成情况:
1)实验参考代码
import csv
import numpy as np
from sklearn.cluster import KMeans
datapath01=”Add your working path/protein.txt”
with open(data_path01,”r”) as rd:
input01=csv.reader(rd,delimiter=’ ‘) #default ,
fields=next(input01) #skip header
X=[]
for row in input01:
X.append(row)
X = np.array(X)
print(X)
X1=X[:,1:9]
print(X1)
n_clusters = 5
cls = KMeans(n_clusters).fit(X1)
print(cls.labels)
for i in range(nclusters):
print(“聚类”,i+1)
members = cls.labels == i
print(“Country:”,X[members,0])2)完整代码及注释展示
完整代码及注释展示,整体代码分为两部分,一部分是数据集聚类部分,另一部分是聚类可视化图形的绘制部分。首先是数据集聚类部分的展示: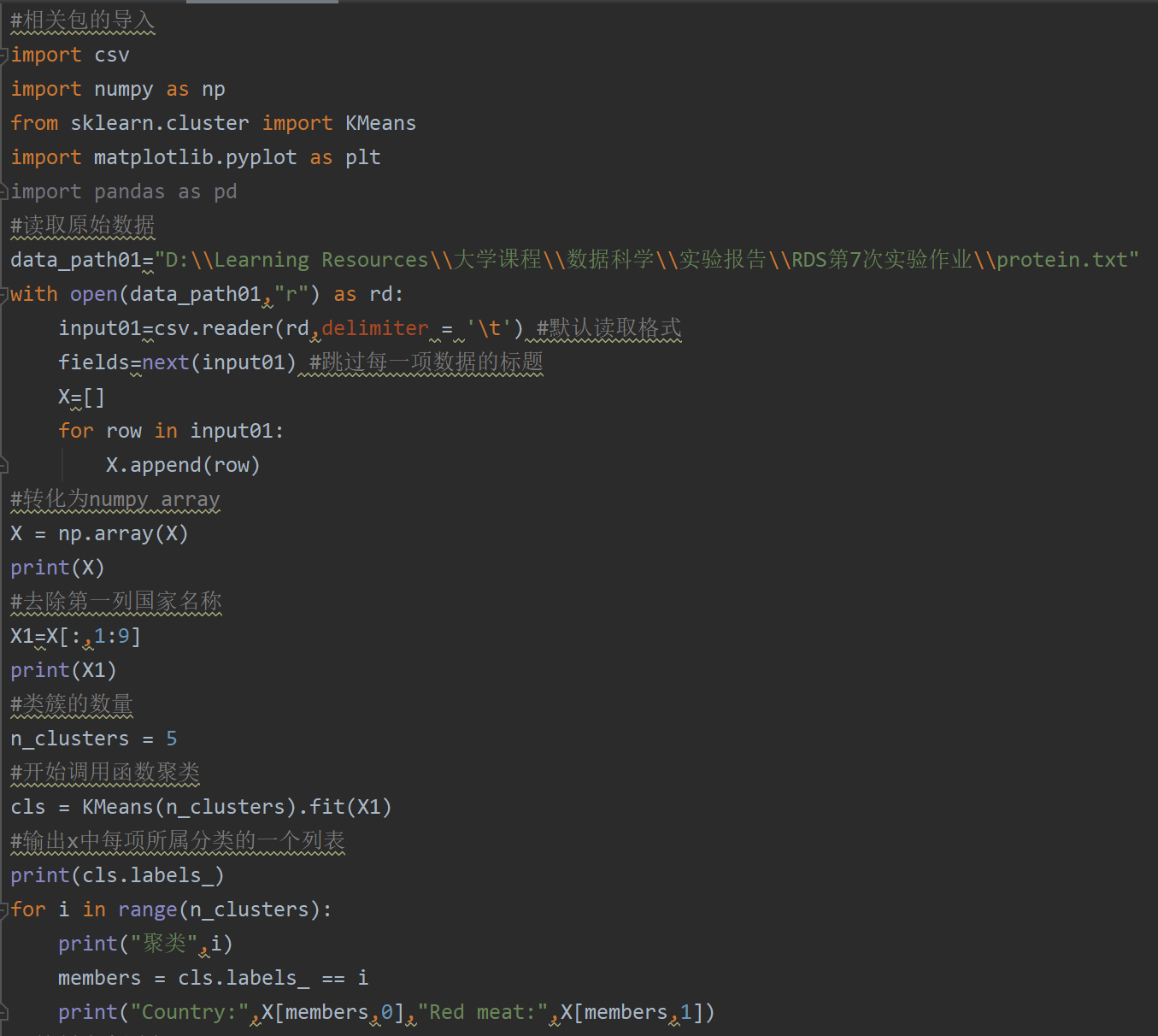
其次聚类可视化图形绘制部分: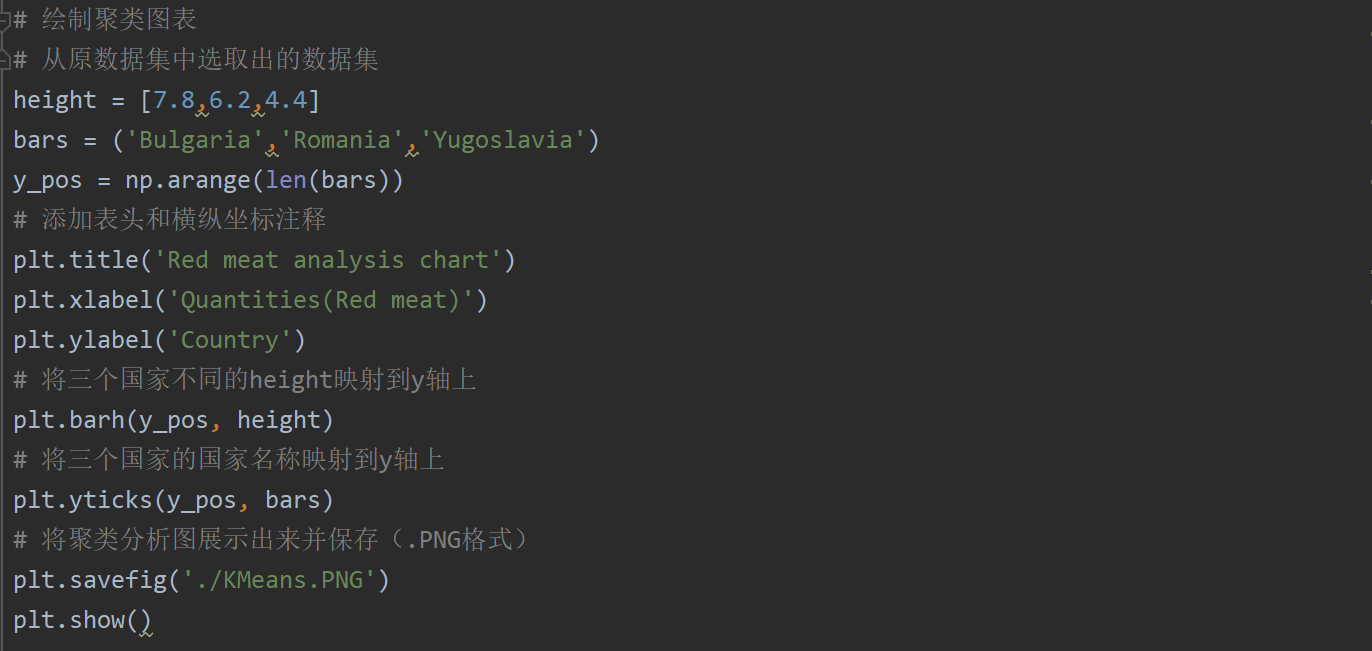
3)原始数据集导入
接下来进行详细的解析,首先是使用函数输入函数open()与csv.reader()将原始数据集protein.txt,导入Python工作空间。源代码展示:
数据集读取成功如下所示: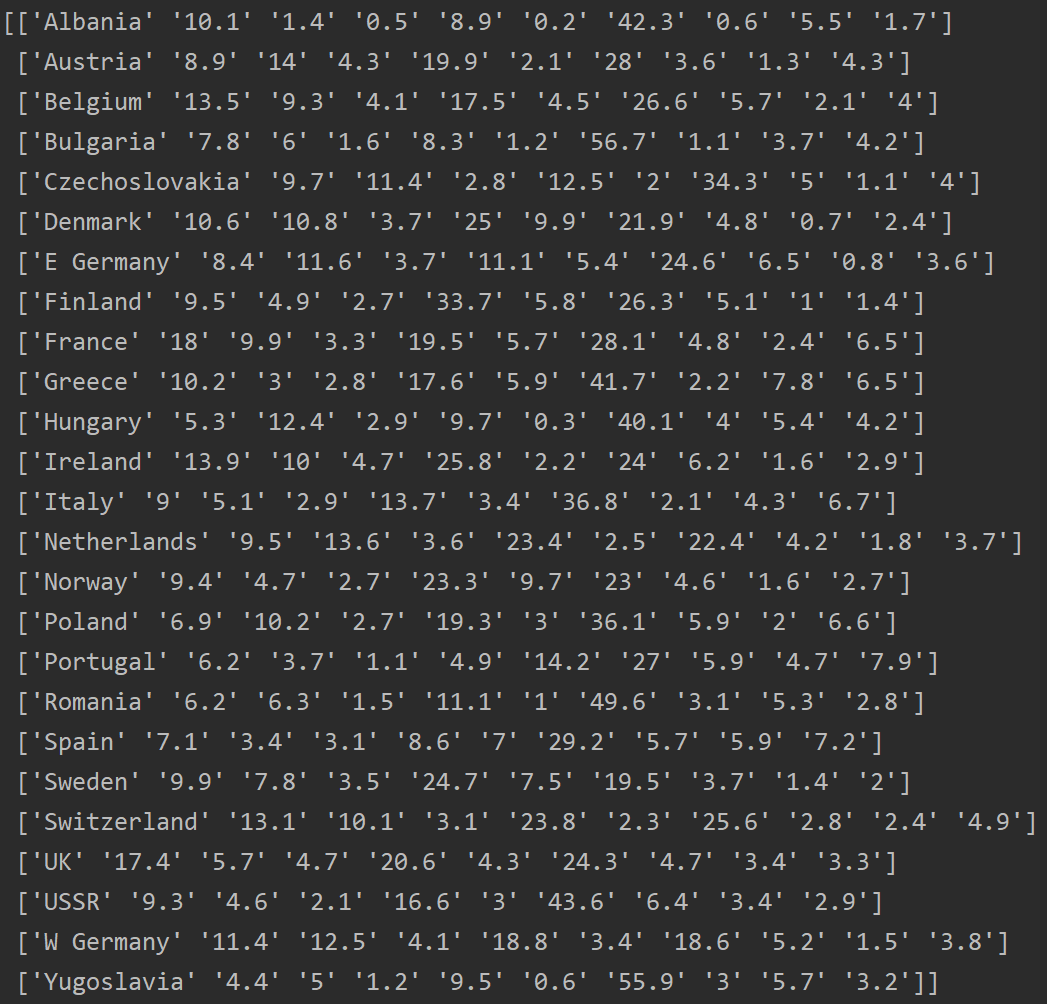
4)转换数据维度
接下来是使用函数np.array() 转换数据维度,并且去除掉第一列国家名称。源代码及注释展示:
成功转换为数值并去除第一列国家名称,结果如下所示: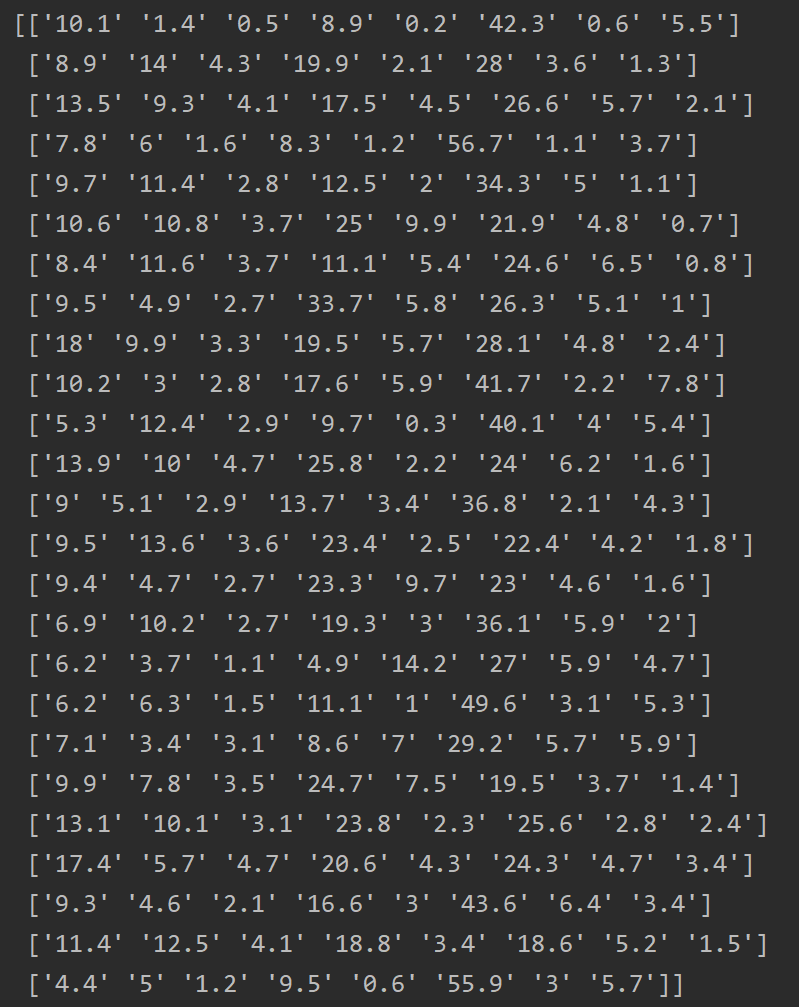
5)聚类分析
使用函数KMeans() 建立数据聚类模型,设置类簇数量,并调用函数KMeans(),最终输出每个国家所属类群,源代码如以下所示:
所对应结果如以下所示:
注:该列表所表示的含义为:第一个4表示第一个国家所属的类群为4。6)聚类详细结果输出
数据集分类的最终,是使用循环将每个类群所对应的国家逐个输出。并且输出该国家所对应红肉蛋白质的含量。
源代码展示:
运行结果如以下所示:
7)聚类可视化
最终是聚类可视化图形的绘制,在此我们选取三个国家,分别为Bulgaria,Romania,Yugoslavia,根据三个国家红肉蛋白质含量的不同值绘制图形,源代码及注释展示: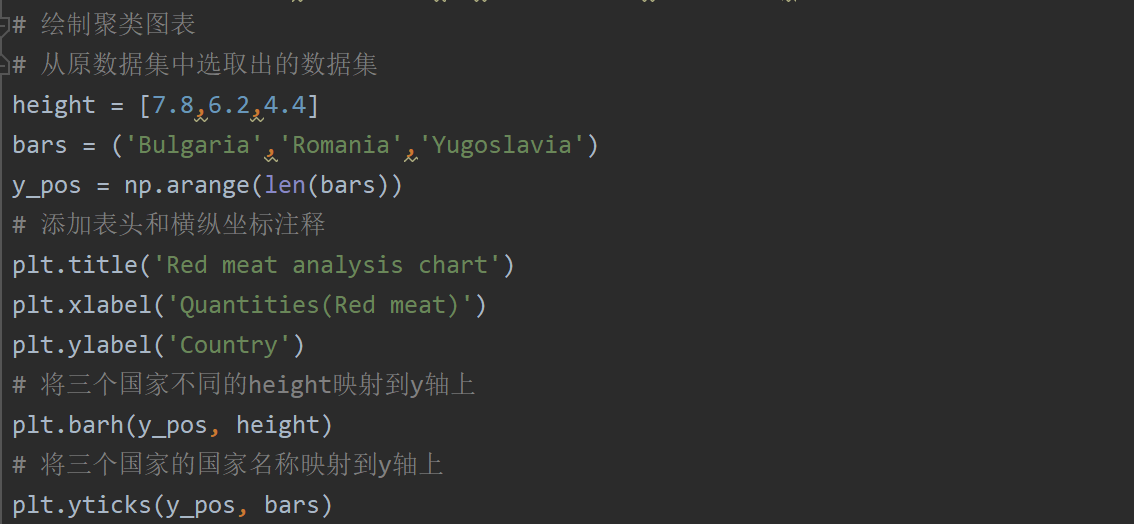
成功绘制后呈现出以下图形: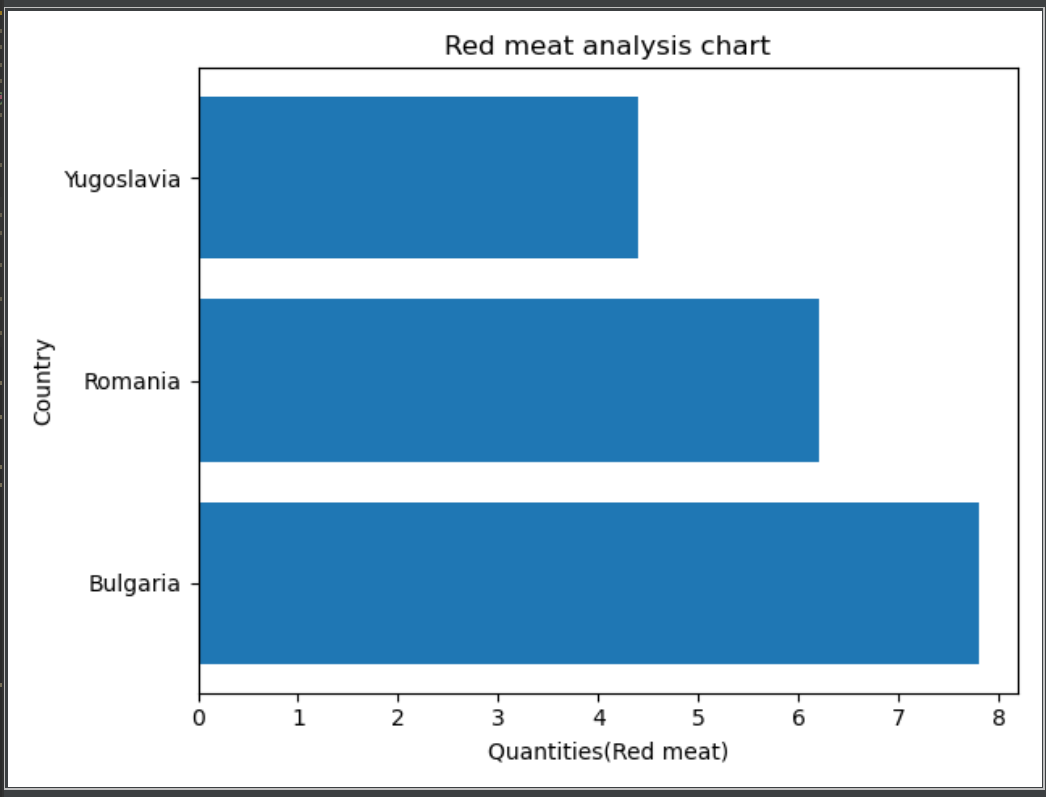
8)可视化图片保存
最终我们将图片将图片保存(命名为:KMeans)至工作目录下,成功后返回工作目录下查看是否顺利保存: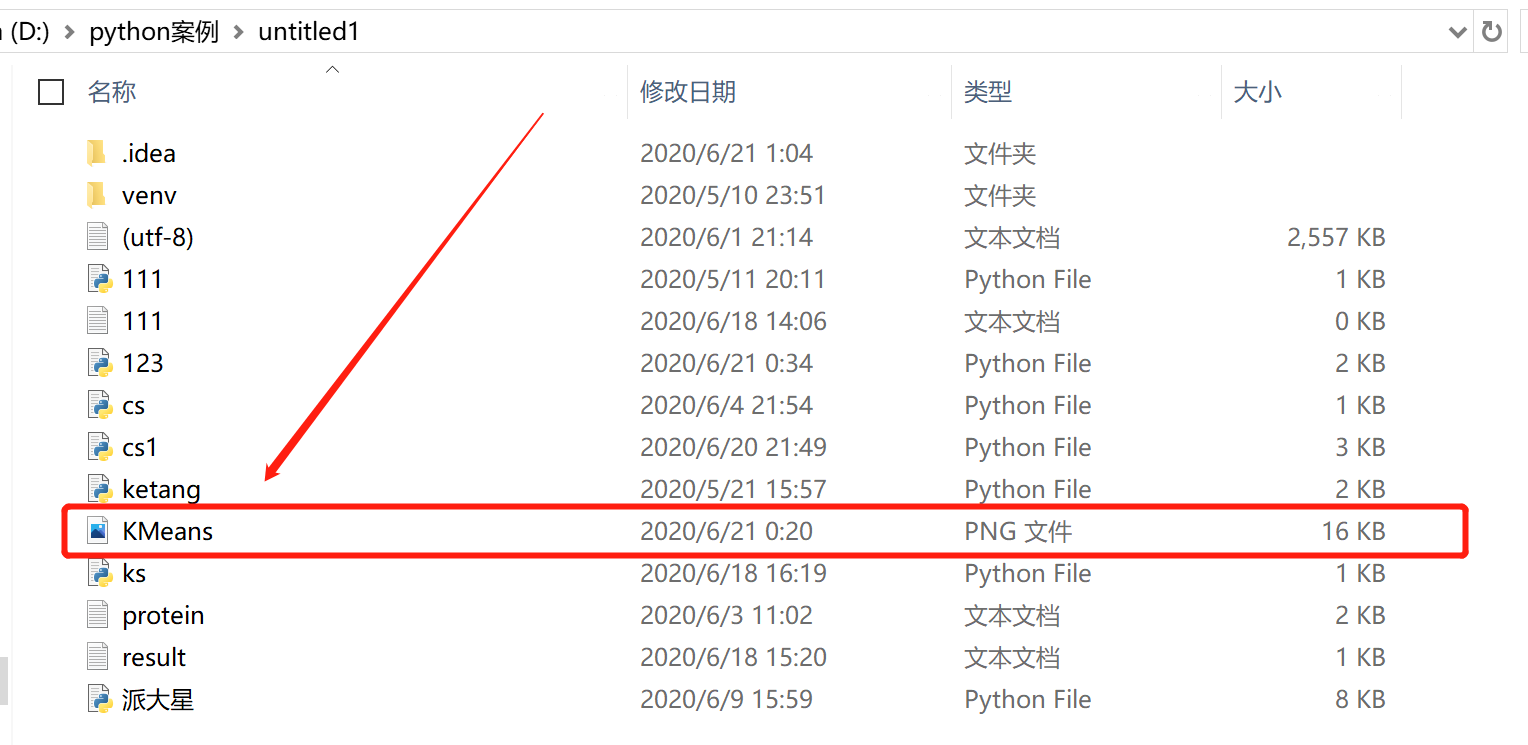
8)绘制聚类可视化3D图形(进阶)
绘制3D聚类分析图的关键在于数据集的选取和点的定义。可视化维度取决于你变量的选取,例如选取了两个变量,我们绘制出的可视化图形即为二维,而如果我们选取出三个变量,我们绘制出的可视化图形即为三维。从目前人体肉眼所能接受的最大维度出发,我们选取了RedMeat,Fish和Fr&Veg三个变量绘制三维可视化图形,而坐标轴的含义也就对应着三个不同的数据项。
选取出三项数据集后,我们根据聚类结果,用点来表示不同的国家,而呈现聚类的关键在于不同类之间的国家用不同颜色的点表示。以下将展示出关键代码,具体完整代码将存放在文末附录中。
关键代码展示: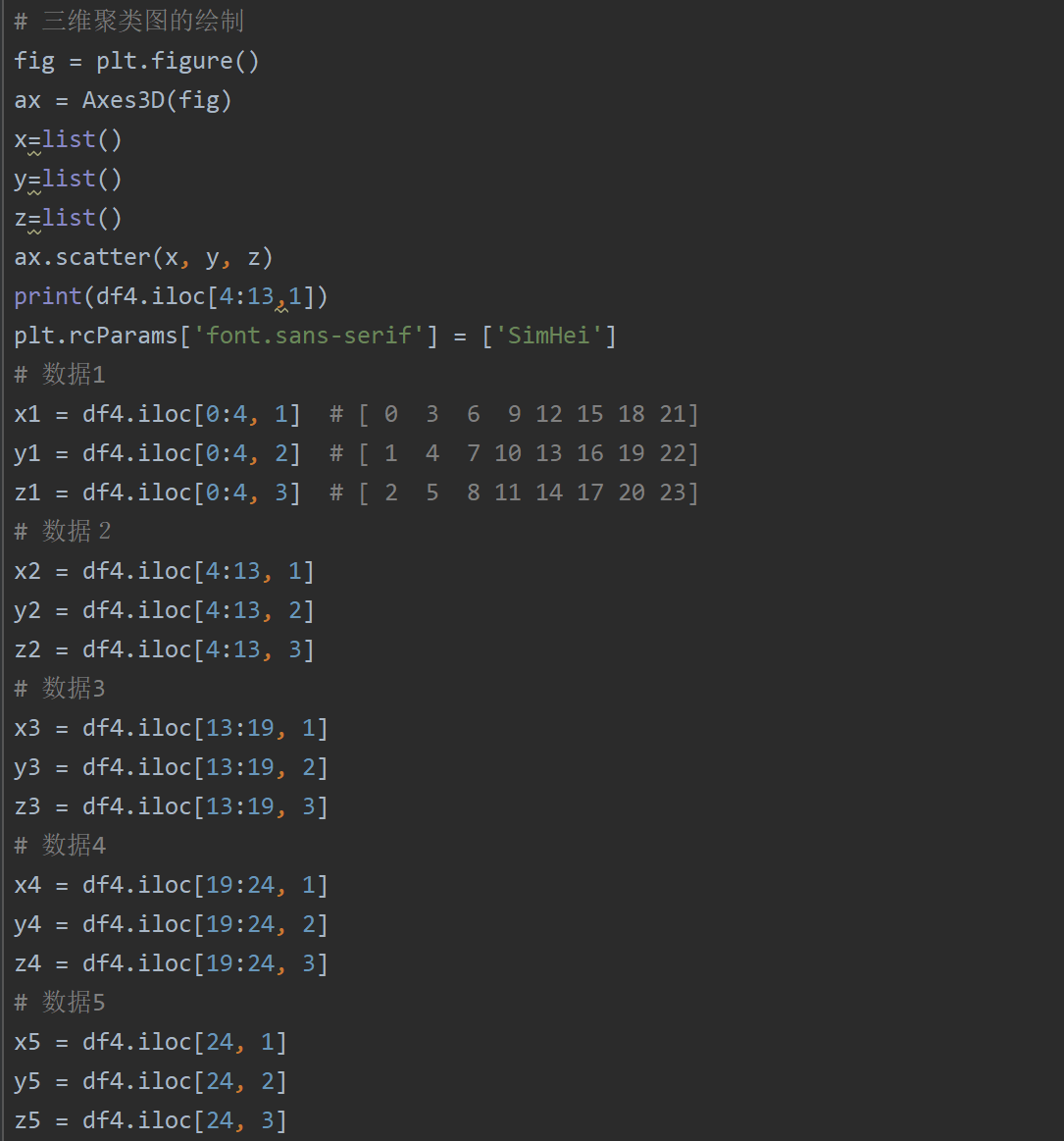
程序运行结果展示: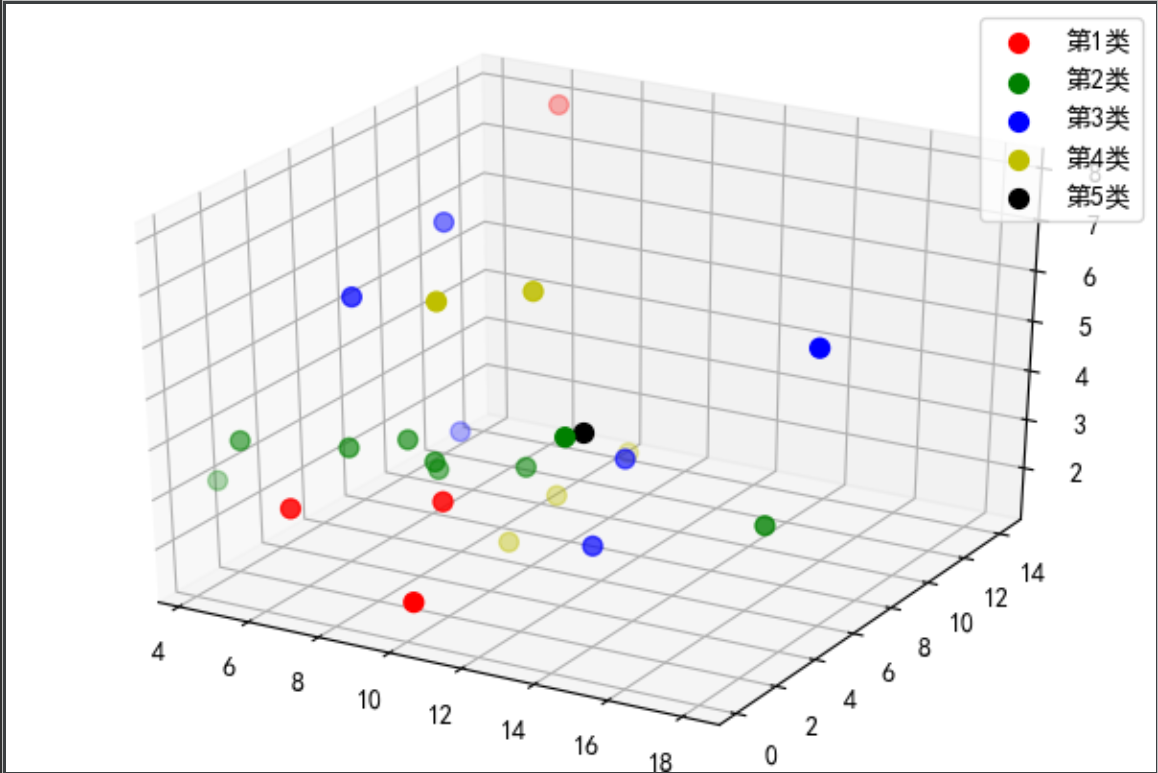
3. 出现的问题
1)对python聚类分析可视化图形种类有点模糊。
2)对三维聚类可视化图形的绘制有点困难。4. 解决方案
1)查阅相关资料才明白,聚类可视化不一定是散点图,它还有很多表达形式,如条形图,树状图等等。
2)通过Google查找相关视频学习Axes3D包的使用,最后成功绘制出三维图形。
四,附录
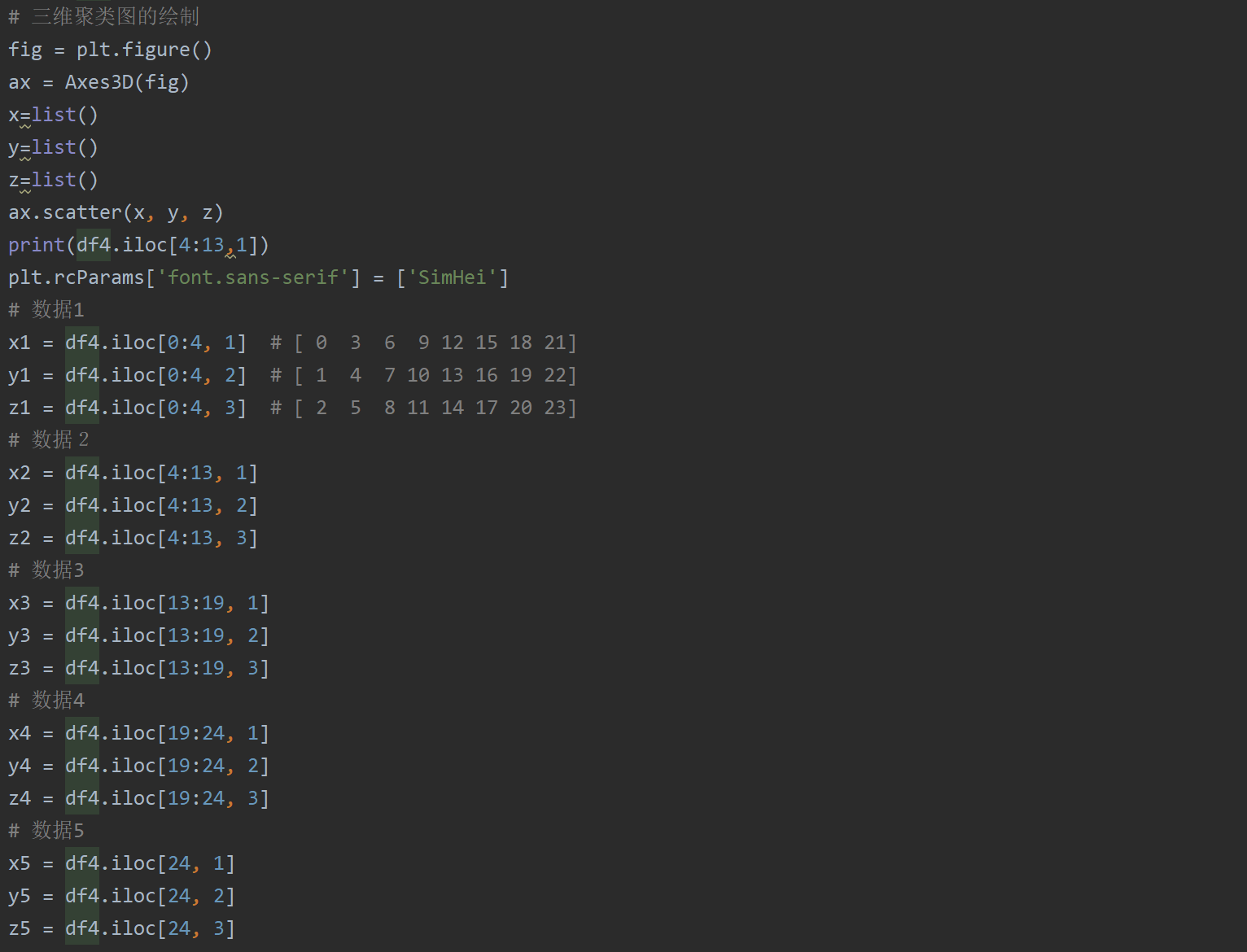
自我创新方法,绘制三维聚类可视化图形完整代码及注释: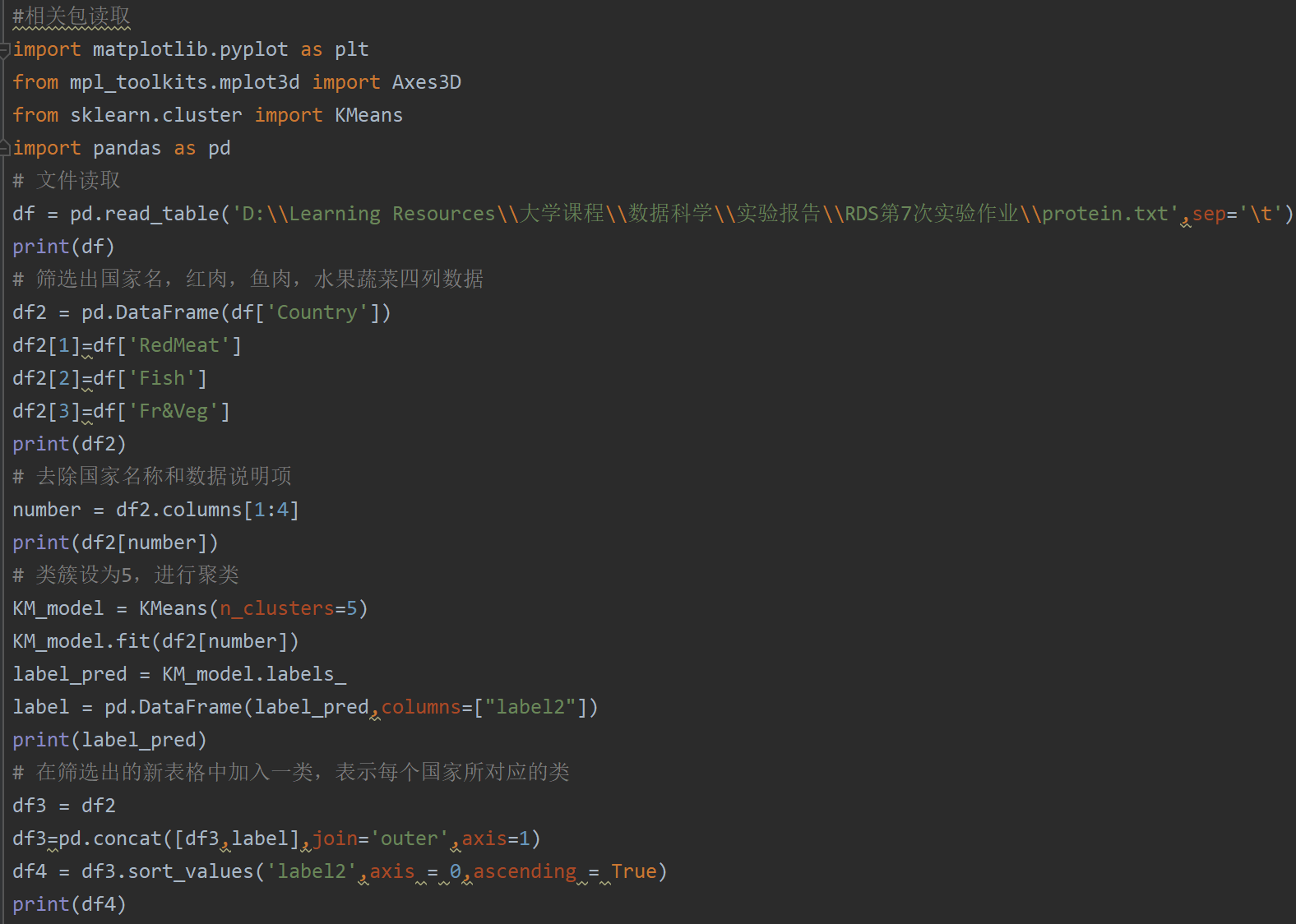

若有收获,就点个赞吧
0 人点赞
