一、实验目的
- 主要分析VIM包自带的数据集sleep中的缺失数据处理问题。
- 数据导入操作包括输入VIM包数据集sleep的函数data()操作。
- 使用函数na.omit(),除去缺失数据(NA)。
- 数据导出操作包括导出Excel数据文件。
- 列出完整代码包含注解。
二、实验内容
说明 1: 在VIM包数据集sleep中的变量说明:
睡眠变量,包括睡眠中做梦时长(Dream)、不做梦的时长(NonD)以及二者的和(sleep);
体质变量,包括体重(BodyWgt,单位为千克)、脑重(BrainWgt,单位为克)、寿命(Span,单位为 年)和妊娠期(Gest,单位为天);
生态学变量,包括物种被捕食的程度(Pred)、睡眠时暴露的程度(Exp)和面临的总危险程度 (Danger)。
说明 2: 使用函数read.xlsx()将原始数据集sleep(脏数据),导出Excel文件。
说明 4: 再使用函数read.xlsx()将已处理的数据集sleep(清洁数据),导出Excel文件。三、实验报告
1. 实验环境:
Win102. 实验内容与完成情况:
1)R语言源代码
install.packages(“VIM”)
data(sleep,package=”VIM”)
sleep
summary(sleep)
sleep[!complete.cases(sleep),]
mean(!complete.cases(sleep))
sum(is.na(sleep$Span))
cleanedsleep <- na.omit(sleep)
cleanedsleep2)在RStudio中键入命令:
3)执行命令1,2
设置工作目录,执行命令3安装R包“VIM”,安装成功如下所示:
4)执行命令4,5
从“VIM”包中读取sleep数据集,并且将其显示出来,结果如下所示: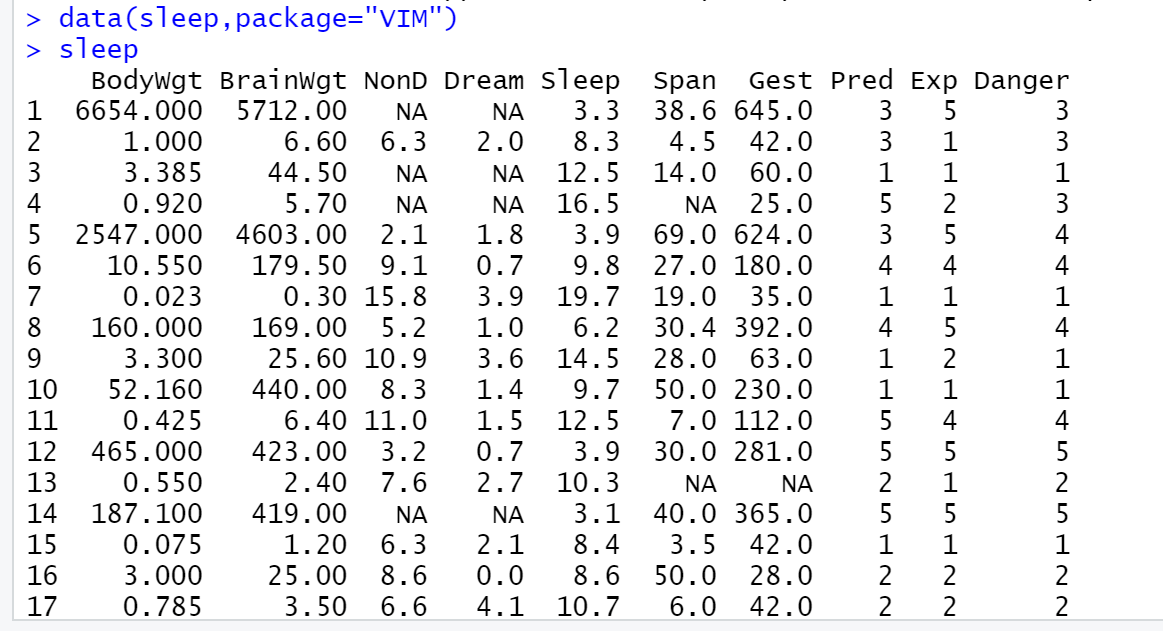
5)执行命令6
将原始数据集sleep(脏数据)导出到Excel文件中,结果如下图所示(具体文件见压缩包):
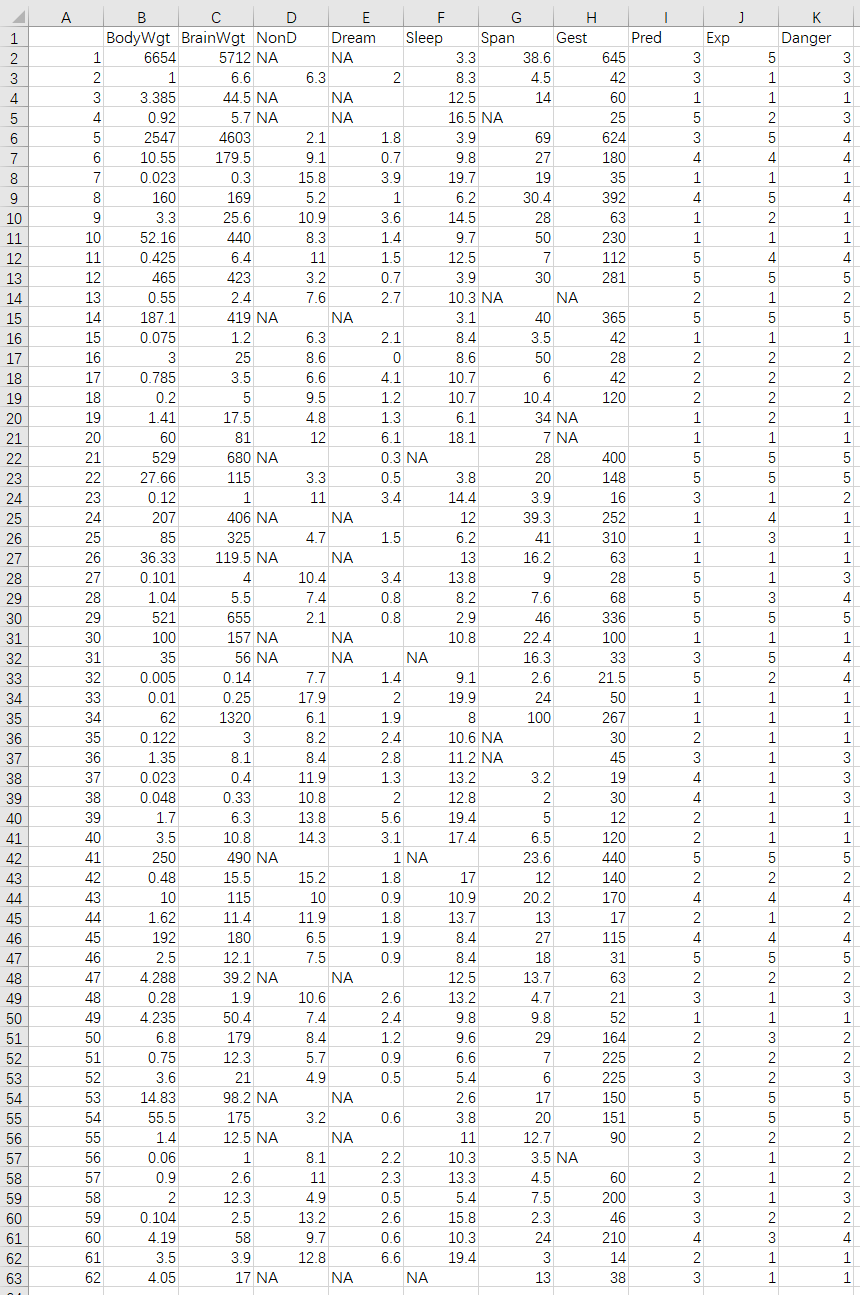
6)执行命令7
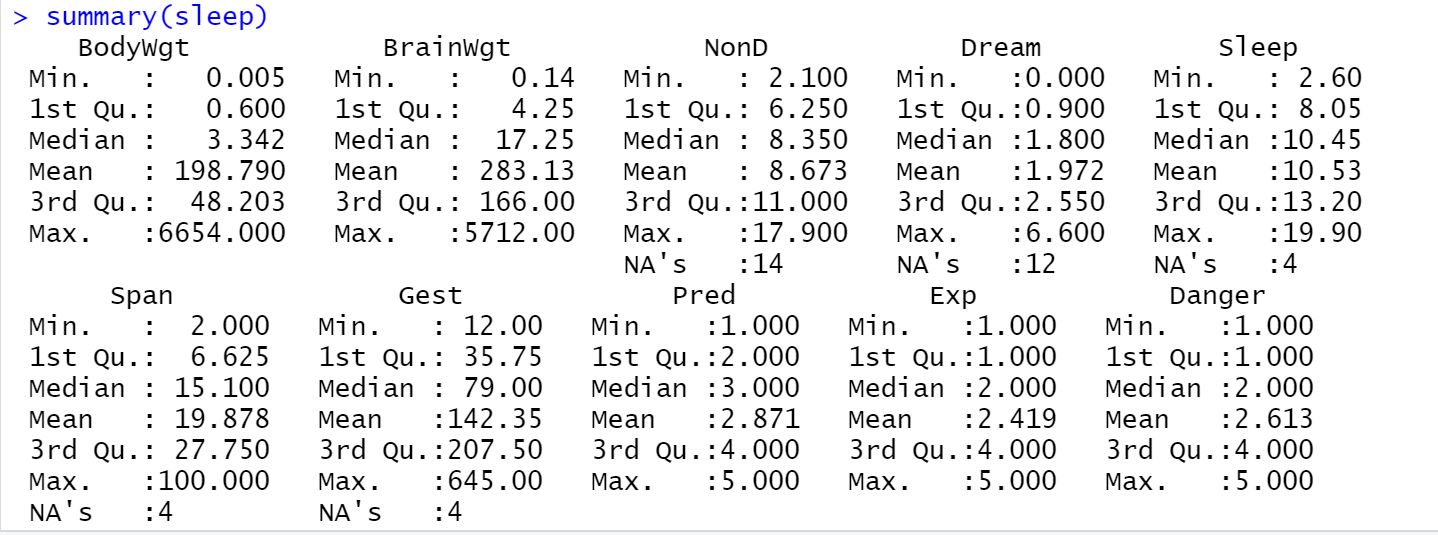
7)执行命令8
列出所有缺失值的行,执行命令9,计算缺失行占整体的比例,执行命令10,计算sleep数据集中span列缺失值的个数。结果如下所示: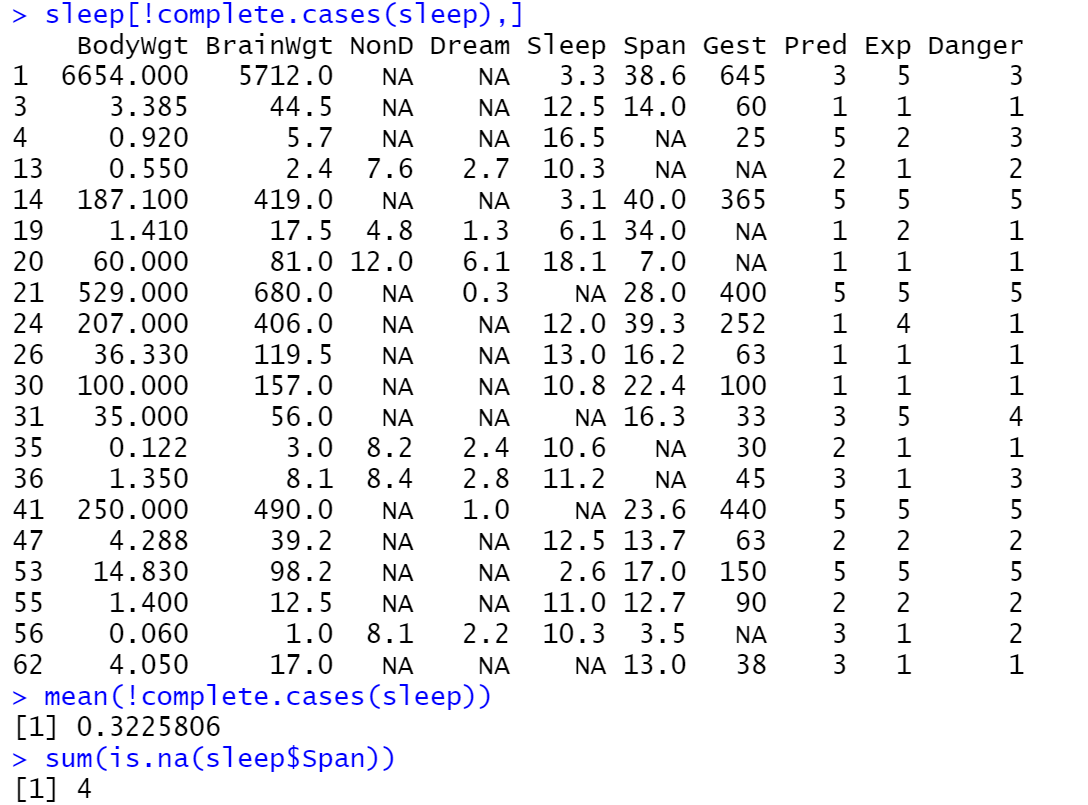
8)执行命令11,12
将数据集中有缺失值的行剔除掉,并且将完整的数据集放入到cleanedsleep中,结果如下图所示: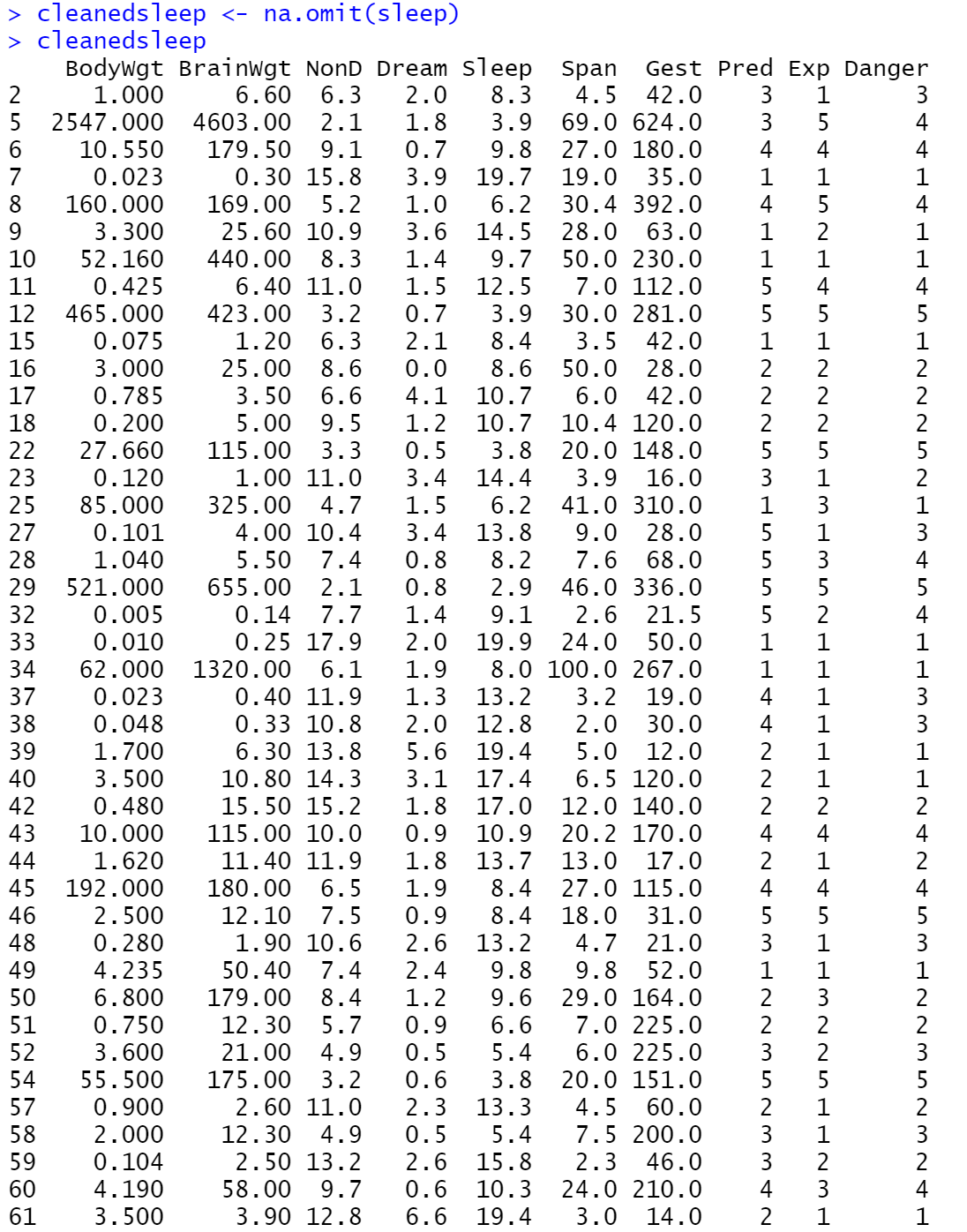
9)执行命令13
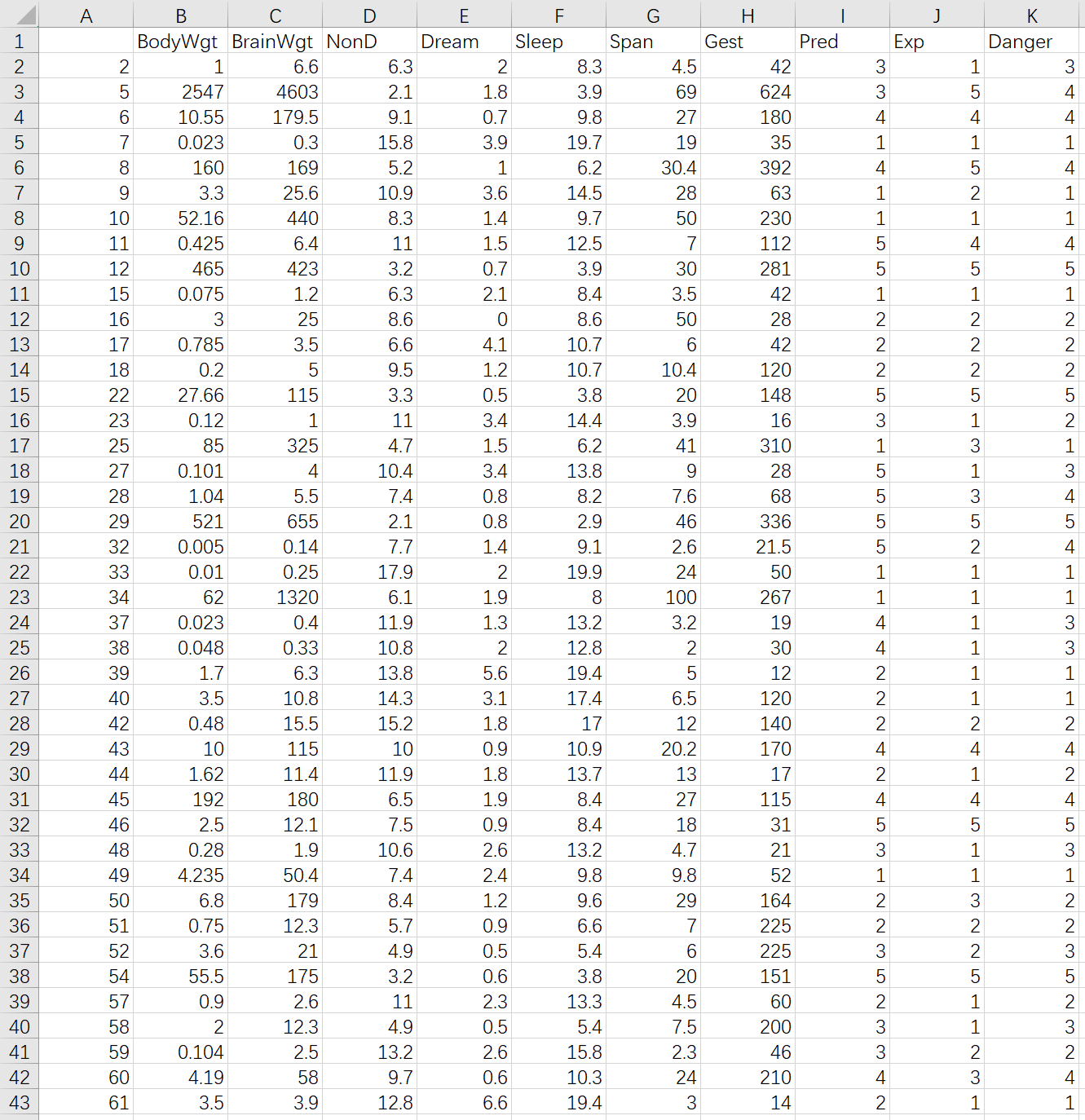
将清洗后的数据集cleanedsleep导出到Excel文件中,结果如下图所示:
3. 出现的问题:
1) 在导出数据集时没有注意数据集名称的拼写导致了以下错误: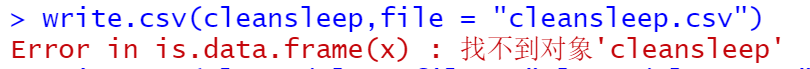
4. 解决方案:

四,附录
附件一
附件二

若有收获,就点个赞吧
0 人点赞
