摘要
随着大数据时代的到来,文本信息量日益增长。如何对文本信息进行准确的分类成为了研究关注的焦点。本文以kaggle竞赛平台的新闻数据为基础,通过卷积神经网络实现文本的自动识别与分类。<br /> 全文研究脉络可以简述为:首先通过kaggle竞赛平台,获取得到文本数据集。紧接着是对文本进行数据清洗及特征提取等操作。进一步在得到文本特征向量后,构造出训练集和测试集,同时根据文本特征向量和二分类任务各自的特点,搭建一维卷积神经网络。通过设置合适的层数、激活函数及损失函数等参数,训练出文本分类模型,并通过混淆矩阵,召回率及F-score等方式,对模型进行客观的评价,最终得出模型能够实现文本准确分类的结论。同时根据模型特点,与实际生产生活联系起来,进行适当的推广。<br /> <br />关键词:自然语言处理、特征向量、一维卷积、F-score
一、引言
1.1背景
随着互联网技术的发展,新闻资讯也在我们的生活中刷起了屏。在这海量的新闻咨询中包含了各种类型的数据和信息,而新闻的种类又可划分为生活,政治,体育等等。面对海量的新闻,每个人的偏好不一样,如何将这些海量的新闻进行准确的分类,并推送给感兴趣的用户,成为了提升用户体验感的一大关键。然而依靠传统的人工分类,明显无法达到快速且准确的分类效果。至此,如何利用人工智能相关知识进行研究和实现,成为了人们关注的热点。
1.2 研究现状
在2013年,Google 团队发布了word2vec工具。通过word2vec工具可以较好地表达不同词之间的相似和类比关系。紧接着在2014年,Mikilov和Le在word2vec的基础上,提出了doc2vec方法,将不同长度的文本向量化。该算法用于预测一个向量来表示不同的文本,该模型克服了词袋模型的缺点。到了2016 年,Facebook的AI Research将Fasttext技术开源,这一技术不仅在保持分类效果的同时,大大缩短了模型训练时间。<br /> 由此可见,近年来,随着人工智能的发展,在文本挖掘方面的技术也逐渐成熟了起来。而这些技术理论,为文本挖掘与深度学习相结合的研究方式提供了大量的理论基础。
1.3研究思路
本文以区分政治新闻和世界新闻为例,首先通过文本挖掘技术,将文本转化为统一维度的特征向量,进一步运用深度学习的知识,搭建一维卷积神经网络,实现文本分类。<br />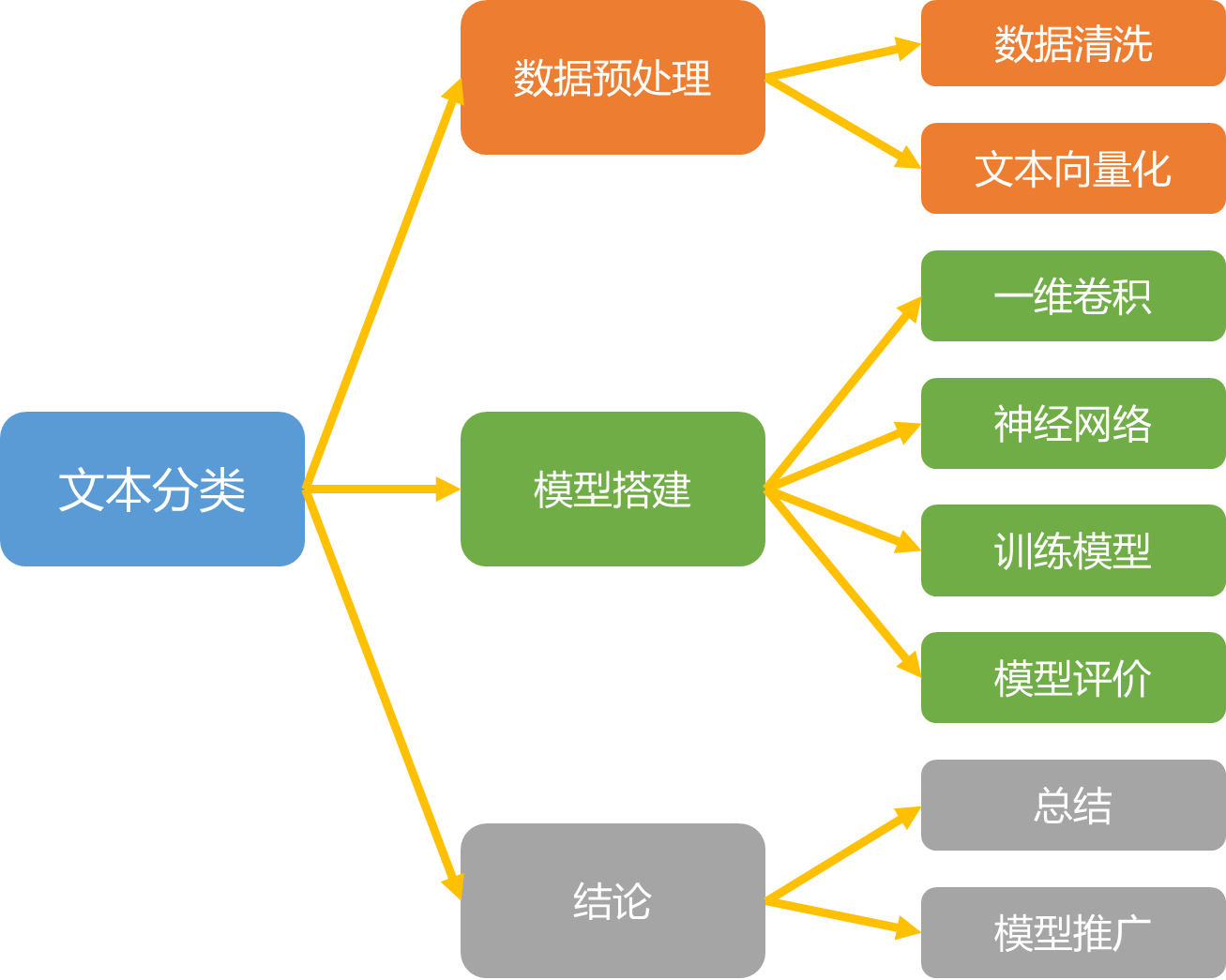<br />图 1研究思路图
二、数据预处理
2.1、数据集描述
通过kaggle平台,得到关于政治新闻和世界新闻的英文数据集。里面共包含21417条数据集。其中11272条为政治新闻,10145条为世界新闻。<br /> 对于我们的数据,共包含标题,文本,主题和日期四方面的信息。为了构造出合适的特征向量,实现文本的正确分类,我们将文章的内容作为数据集,进行向量化的操作。
2.2、数据清洗
考虑到英文文本存在大小写的差异,差异虽然并不影响训练集的主旨大意,但是却会影响特征向量的生成,因此我们统一将大写字母转换为小写字母。然后是标点符号的处理,标点符号并不会太大影响文本的实际意义与内容,所以我们可以对其进行剔除处理。完成这两项处理后,即可对英文文本进行分词处理。这里我们使用nltk.word_tokenize进行分词。<br /> 分词后,我们需要去除停用词。在英语中,会有很多的词语不表达实际的意思,比如in、on、for等介词。这类词语在文本中非常的常见,去除掉通用词并不会影响文章的主旨大意,所以我们通过建立停用词表,将其进行剔除处理。<br /> 最后我们需要提取文本的主干,英文单词会有很多变形。以英语单词clean为例,其还有进行时态的动词一种分词形式cleaning、复数形式cleans和过去式cleaned等等,类似的这些词语和clean一样,不同的形式对于文章的主旨大意并不存在任何影响,所以为了降低数据维度,我们可以进行提取词干的处理。这一过程可以通过stem函数完成。<br /><br />图 2数据清洗流程图
2.3、文本向量化
因为计算机并不能直接对文本信息进行处理,即需要对文本进行向量化,同时保留它们的信息,因此,我们采用词袋模型与N-gram相结合的方法,将文本转化为向量。<br /> 首先我们在前面的分词结果基础上,将相邻的2个词组进行组合。接着将所有组合与分词结果构建词袋模型,最后将留言进行向量化。这种结合的方法不仅弥补了许多文本向量化没有考虑语序的问题,而且还能得到词组在句子中的权重。<br /> 紧接着,由于句子与句子之间长度并不相同,我们需要将句子长度统一化。这里我们搭建神经网络模型,将文本向量输入至模型进行无监督的向量,即可映射出同一维度的文本向量。同时利用第三方库Fasttext,将所有文本映射为256*1的向量。<br />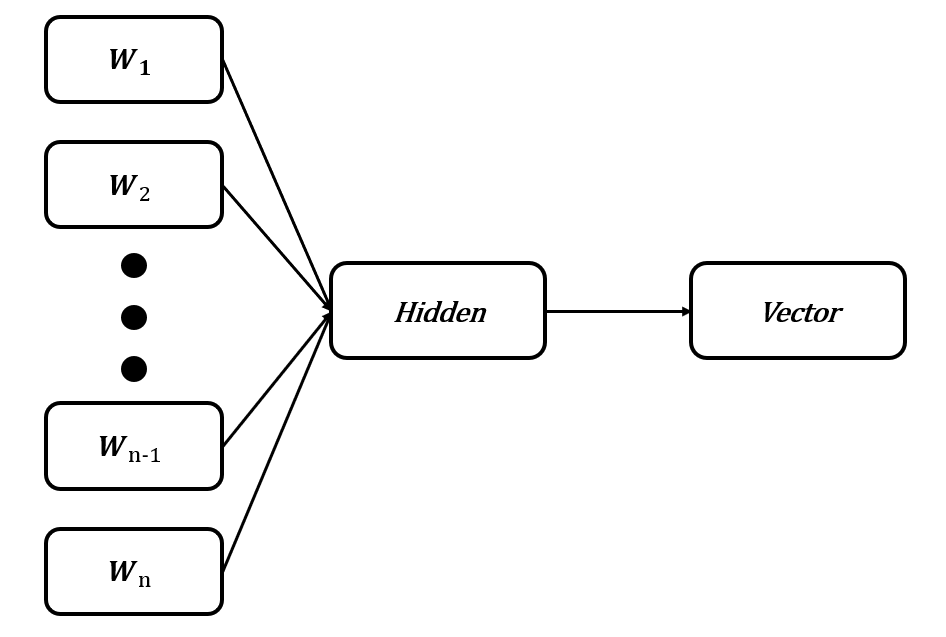<br />图 3文本向量化示意图
三、模型建立
得到文本的数字化特征后,我们根据向量的维度,搭建一维卷积神经网络进行文本分类。
3.1、卷积层与池化层
首先是建立Sequential层,Sequential模型可以通过堆叠许多层,构建出深度神经网络。接着是第一个一维卷积层:第一层定义了卷积核大小为57,卷积核数量为64。这样我们就在网络的第一层中训练得到64个不同的特性,且输出是一个200*64的矩阵。输出矩阵的每一列都包含一个滤波器的权值。在定义内核大小并考虑输入矩阵长度的情况下,每个过滤器将包含200个权重值。<br /> 其次是第一个池化层:为了减少输出的复杂度,在CNN层之后通常会使用池化层。这里我们选择了大小为2的池化层,即矩阵将进行倍数为2的缩减采样。之后输出矩阵将由200*64变成100*64。在池化层后,我们再把Dropout加入模型中,这里我们选择每次训练迭代都会随机地在神经网络中放弃40%的神经元,以避免过拟合想象的出现。<br /> 紧接着是第二个一维卷积层,为了学习更高层次的特征,我们再次使用了卷积层。这里定义卷积核大小为51,卷积核数量为128。即这层之后的输出矩阵是为100*128的矩阵。最后我们再增加一个池化层进行缩减采样,其中倍数依旧为2。这层之后输出矩阵为50*128的矩阵。至此,我们完成了卷积层与池化层的搭建。
3.2、神经网络
搭建完卷积层与池化层后我们需要建立神经网络分类器。首先是建立平坦层,Flatten层能够将多维数据的变为一维,因此需要放在神经网络的第一层,用以从卷积层到全连接层的过渡。接着是隐藏层,因为我们的分类属于二分类,因此为了降低模型的复杂度,我们只搭建一层隐藏层,神经元个数为1024个。最后是输出层,因为只要两个类别所以只需要两个输出神经元,同时激活函数设置为用于二分类的"sigmoid"函数。<br /> 至此,我们完成了整个一维卷积神经网络的搭建。模型示意图如下;<br />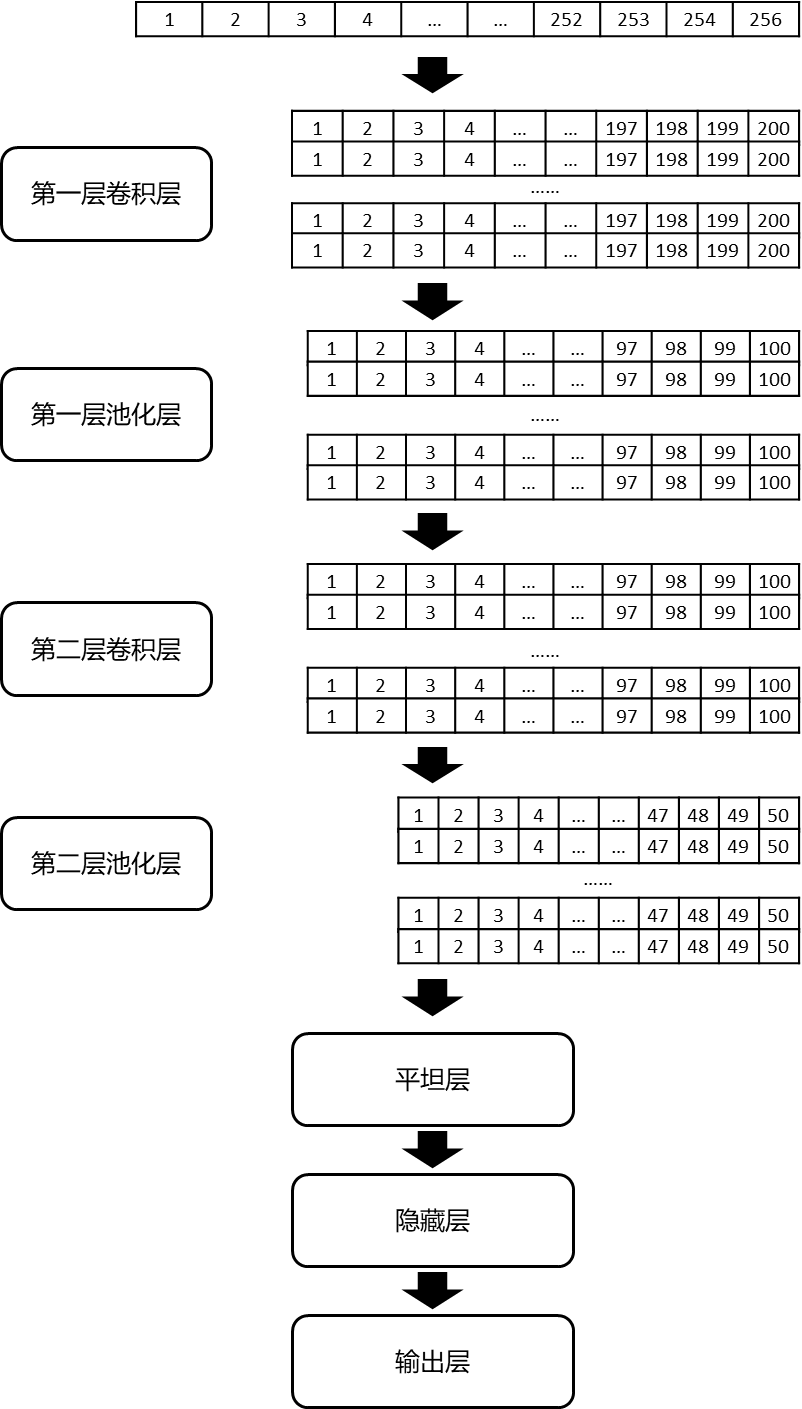<br />图 4模型结构图
3.3、训练模型
训练之前我们需要先将数据集转为Float数,接着将标签进行One-Hot Encoding的转换,并与数据集一一对应。进一步为了增加模型的准确率,我们将数据集进行打乱,并按照7:3的比例将数据集拆分为训练集和测试集。<br /> 紧接着我们利用compile对模型的训练方式进行设置,设置损失函数为categorical_crossentropy,优化器设置为adam,评估模型的方式为准确率。<br /> 由于我们是二分类,可能会产生损失函数始终在0.69徘徊的情况。因此在构建训练集与设置模型训练方法时,需要留意标签与训练集是否对应,损失函数的选择是否正确等问题。
3.4、模型评价
定义完训练方式后,我们开始进行训练,最终得到如下结果:
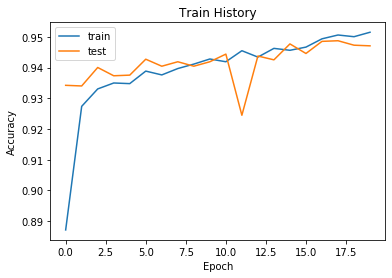 图 5准确率变化图 |
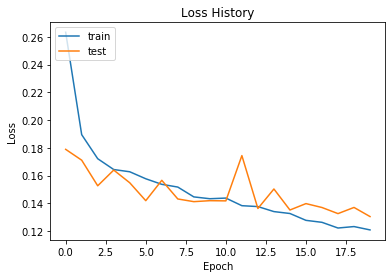 图 6损失函数变化图 |
|---|---|
通过误差变化图可以知道,随着迭代次数的增加,准确率与损失函数减小的速度变缓,说明模型已经达到最优状态。紧接着我们对测试集进行分类,得到测试集的分类准确率高达94.68%。接着我们查看模型的混淆矩阵,结果如下<br />表格 1混淆矩阵
| 新闻种类 | 政治新闻 | 世界新闻 |
|---|---|---|
| 政治新闻 | 9664 | 463 |
| 世界新闻 | 481 | 10809 |
根据混淆矩阵,我们计算得到模型的准确率为95.59%,精确率为95.43%,召回率为95.26%,F-score值为95.34%。
四、结论
通过训练并搭建一维卷积神经网络模型,我们得到了能够将政治新闻与世界新闻准确分类的模型。
4.1、总结
本文核心分为两部分,一部分在于如何提取文本特征,并将其向量化,这里我们通过第三方库Fasttext,训练得到能够将文本输出为同一维度的文本向量化模型。文本特征提取,作为分类的基础,直接关系到我们分类模型的结果。而另外一部分核心重点在于卷积神经网络模型的搭建,通过结合二分类的特点,搭建合理的卷积层与池化层,用以提取向量的特征,提高模型的准确率。
4.2、模型推广
对于该模型,可以很好的运用于某些新闻客户端,进行新闻的智能分类,便于用户对相关新闻的检索,同时还可以结合推荐系统,根据用户的喜好,对新闻进行推送。对于文本清洗与向量化的过程和思路,同样可以运用到其他关于文本清洗与提取文本特征向量的过程中去。对于一维卷积神经网络,还可以运用于信号处理问题和自然语言处理等问题。
五、参考文献
[1]朝乐门编著,数据科学,清华大学出版社,2016.08(推荐教科书)
[2]朝乐门编著,Python编程:从数据分析到数据科学,电子工业出版社,2019.01
[3]嵩天,礼天,黄天羽著.Python语言程序设计基础(第二版),高等教育出版社,2020.01
[4]代令令,蒋侃.基于fastText的中文文本分类[J].计算机与现代化,2018
[5]https://juejin.im/post/5beb7432f265da61524cf27c
[6]林大贵,TensorFlow+Keras深度学习人工智能实践应用,清华大学出版社,2018
[7]刘顺祥,从零开始学Python(数据分析与挖掘),清华大学出版社 [M] 2019.05
六、附录(源程序及注释)
import pandas as pd
import random
import nltk
import string
from nltk.corpus import stopwords
import nltk.stem
import numpy as np
catedic = {‘politicsNews’:1, ‘worldnews’:0}
dftrue = pd.readcsv(“D:/论文/True.csv”, encoding=’utf-8’)
stopwords=pd.readcsv(“D:/论文/stopword_word.txt”,index_col=False,quoting=3,sep=”\t”,names=[‘stopword’], encoding=’utf-8’)
stopwords=stopwords[‘stopword’].values
s = nltk.stem.SnowballStemmer(‘english’)
remove = str.maketrans(‘’,’’,string.punctuation)
text = []
for i in range(len(df_true.iloc[:,0])):
a = df_true.iloc[i,1].lower()
a = a.translate(remove)
a = nltk.word_tokenize(a)
a = [s.stem(ws) for ws in a]
a = list(filter(lambda x:x not in stopwords, a))
text2.append(“__label“+str(cate_dic[df_true.iloc[i,2]])+” , “+” “.join(a))
text_an = text
text_an
y_train = []
for i in range(len(df_true.iloc[:,0])):
a = str(cate_dic[df_true.iloc[i,2]])
y_train.append(a)
import tensorflow as tf
#打乱数据集
random.shuffle(text)
text
print (“writing data to fasttext format…”)
out = open(‘train_data.txt’, ‘wb’)
for sentence in text2:
out.write(sentence.encode(‘utf8’)+b”\n”)
print( “done!”)
import fasttext
#训练文本向量化模型
modelw = fasttext.train_unsupervised(“train_data.txt”, model=”skipgram”, lr=0.05, dim=256,
ws=5, epoch=5, minCount=5,
minCountLabel=0, minn=3,
maxn=6, neg=5, wordNgrams=1,
loss=”ns”, bucket=2000000,
thread=12, lrUpdateRate=100,
t=1e-4, label=”__label“,
verbose=2, pretrainedVectors=””)
#构造文本向量
vector = []
for i in range(df_true.shape[0]):
vector.append(modelw[text_an[i]])
x_train =np.array(vector)
from keras.utils import np_utils
y_train = []
for i in range(len(df_true.iloc[:,0])):
a = str(cate_dic[df_true.iloc[i,2]])
y_train.append(a)
y_label_train2 = np_utils.to_categorical(y_train)
x_train_vec = np.expand_dims(x_train, 2)
from sklearn.model_selection import train_test_split
x_train, x_test, y_label_train, y_label_test = train_test_split(x_train_vec,y_label_train, test_size=0.9, random_state=234)
from keras.models import Sequential
from keras.layers import Conv1D, MaxPooling1D, GlobalMaxPooling1D, Dense
from keras.optimizers import RMSprop
from keras.preprocessing import sequence
from keras.layers import Dense, Dropout, Activation, Flatten, MaxPool1D, Conv1D
from keras.layers import Convolution1D
import matplotlib.pyplot as plt
import keras
#建立一维卷积神经网络
model = Sequential()
model.add(keras.layers.convolutional.Conv1D(64, 57,
input_shape=(256, 1),
activation=”relu”,
name=”convolution_1d_layer”))
model.add(MaxPool1D(2,padding=’same’))
model.add(Dropout(0.4))
model.add(Conv1D(128, 51, padding=’same’, activation=’relu’))
model.add(MaxPool1D(2,padding=’same’))
model.add(Flatten())
model.add(Dropout(0.5))
model.add(Dense(1024,activation=’sigmoid’,kernel_initializer=’he_normal’))
model.add(Dense(units = 2,
activation = “sigmoid”))
print(model.summary())
#训练模型
batch_size = 32
epochs = 20
learning_rate=1
model.compile(loss = “categorical_crossentropy”,
optimizer = “adam”,
metrics = [‘accuracy’])
history = model.fit(
x_test,
y_label_test,
batch_size=batch_size,
epochs=epochs,
validation_split = 0.25)
#可视化准确率
import matplotlib.pyplot as plt
def show_train_history(train_acc,test_acc):
plt.plot(history.history[train_acc])
plt.plot(history.history[test_acc])
plt.title(‘Train History’)
plt.ylabel(‘Accuracy’)
plt.xlabel(‘Epoch’)
plt.legend([‘train’, ‘test’], loc=’upper left’)
plt.show()
#可视化损失函数
import matplotlib.pyplot as plt
def show_loss_history(train_acc,test_acc):
plt.plot(history.history[train_acc])
plt.plot(history.history[test_acc])
plt.title(‘Loss History’)
plt.ylabel(‘Loss’)
plt.xlabel(‘Epoch’)
plt.legend([‘train’, ‘test’], loc=’upper left’)
plt.show()
show_train_history(‘accuracy’,’val_accuracy’) #准确率执行结果
show_loss_history(‘loss’,’val_loss’)
scores = model.evaluate(x_train2,y_label_train, verbose=1)
scores[1]
from sklearn.metrics import confusion_matrix
from sklearn.metrics import recall_score
prediction = model.predict(x_trainz)
prediction=np.argmax(prediction,axis=1)
prediction
pre = list(prediction)
real = list(y_train)
tru =[eval(i) for i in real]
a = confusion_matrix(pre,tru)
print(a)

若有收获,就点个赞吧
0 人点赞
