一、实验目的
- 使用蛋白质摄取的数据集protein.txt,说明蛋白质摄取的聚类分析操作。
- 数据导入操作,使用输入函数read.table()的操作。
- 数据标准化操作,使用函数scale()的操作。
- 数据聚类建立模型操作,使用函数kmeans()的操作。
- 列出实验结果包含绘图以及完整代码包含注解。
二、实验内容
说明 1: 举一个蛋白质摄取的档案protein.txt进行聚类说明,共有25个欧洲国家,即25笔纪录,字段有country、 Redmeat、Whitemeat、Eggs、Milk、Fish、Cereals、Starch、Nuts和Frozen Vegetable,档案内容如下: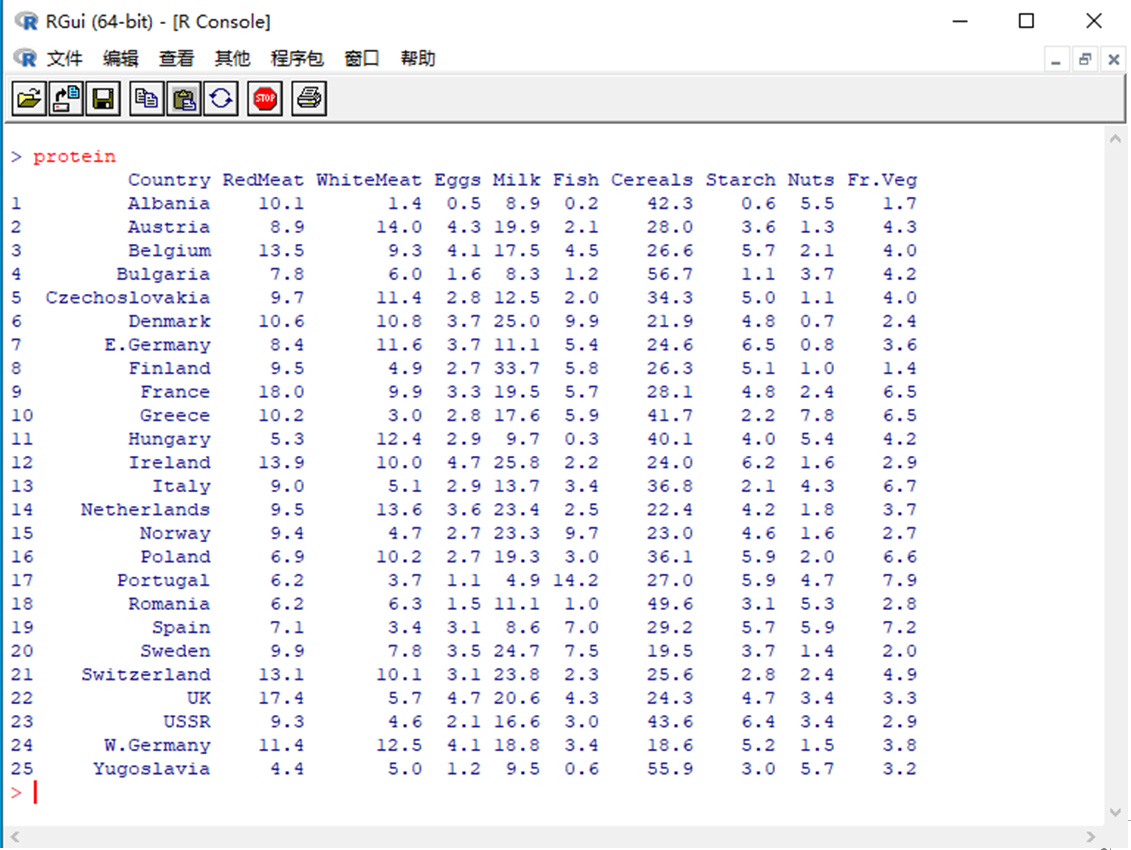
说明 2: 使用函数read.table()将原始数据集protein.txt,导入R工作空间。
说明 3: 使用函数scale() 将数据标准化。
说明 4: 使用函数kmeans() 建立数据聚类模型,并列出实验结果包含绘图以及完整代码包含注解。
三、实验报告
1. 实验环境:
2. 实验内容与完成情况:
1)实验参考源代码
url<-“Add your working path.”
setwd(url)
protein<-read.table(“protein.txt”, sep=” “, header=TRUE)
summary(protein)
#Data preprocessing
v<-colnames(protein)[-1]
pmatrix<-scale(protein[,v])
#Clustering
k<-5
pclusters<-kmeans(pmatrix, k, nstart=10, iter.max=10)
summary(pclusters)
#Resaults
groups<-pclusters$cluster
print_clusters <- function(labels,k)
{
for(i in 1:k)
{
print(paste(“聚类”,i))
print(protein[labels==i,
c(“Country”,”RedMeat”,”Fish”,”Fr.Veg”)])
}
}
print_clusters(groups,k)
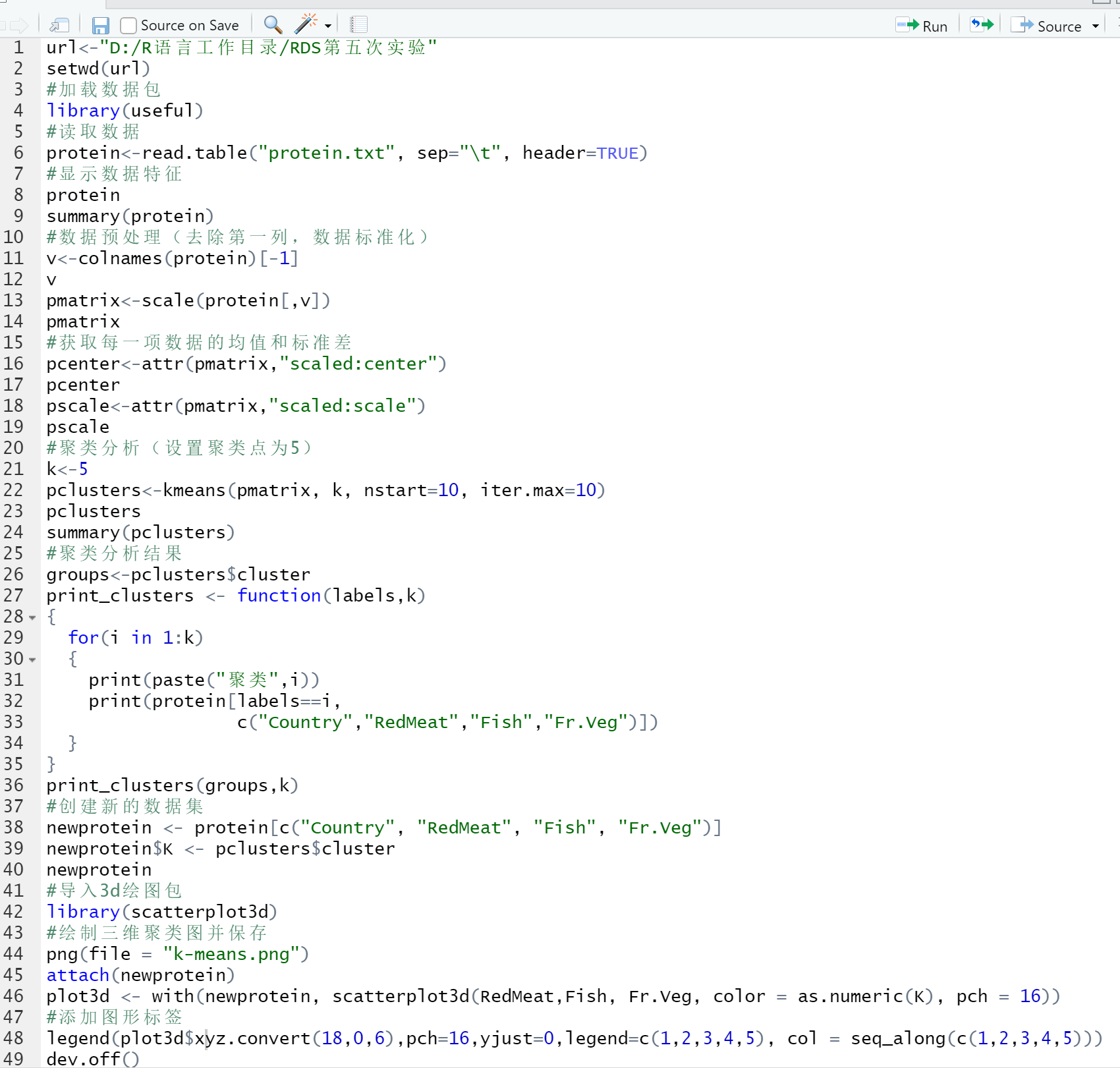
2)实验完整代码(含注释)
3)数据集导入
使用函数read.table()将原始数据集protein.txt导入并显示: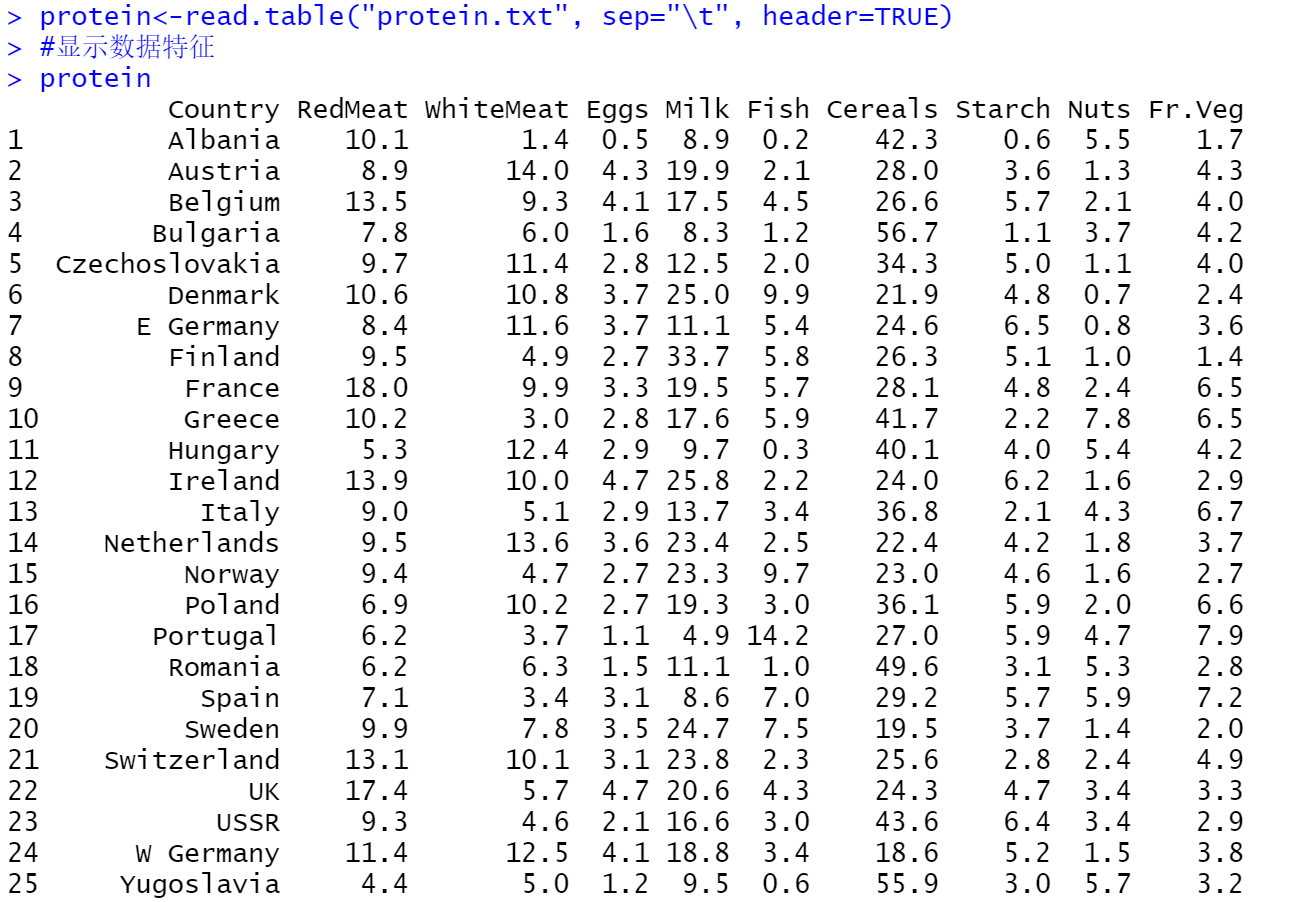
3)数据标准化
使用函数scale() 将数据标准化,去除第一列国家名: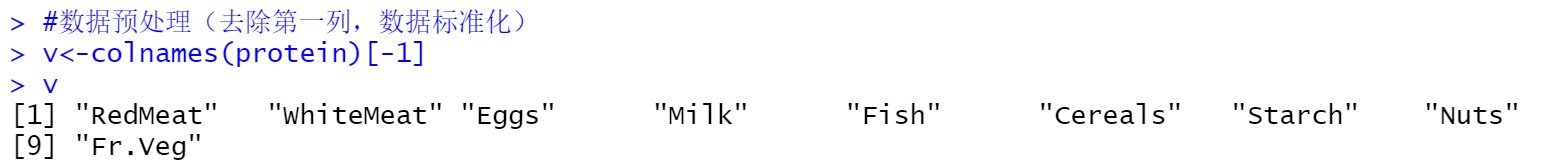
对数据进行标准化处理(显示部分):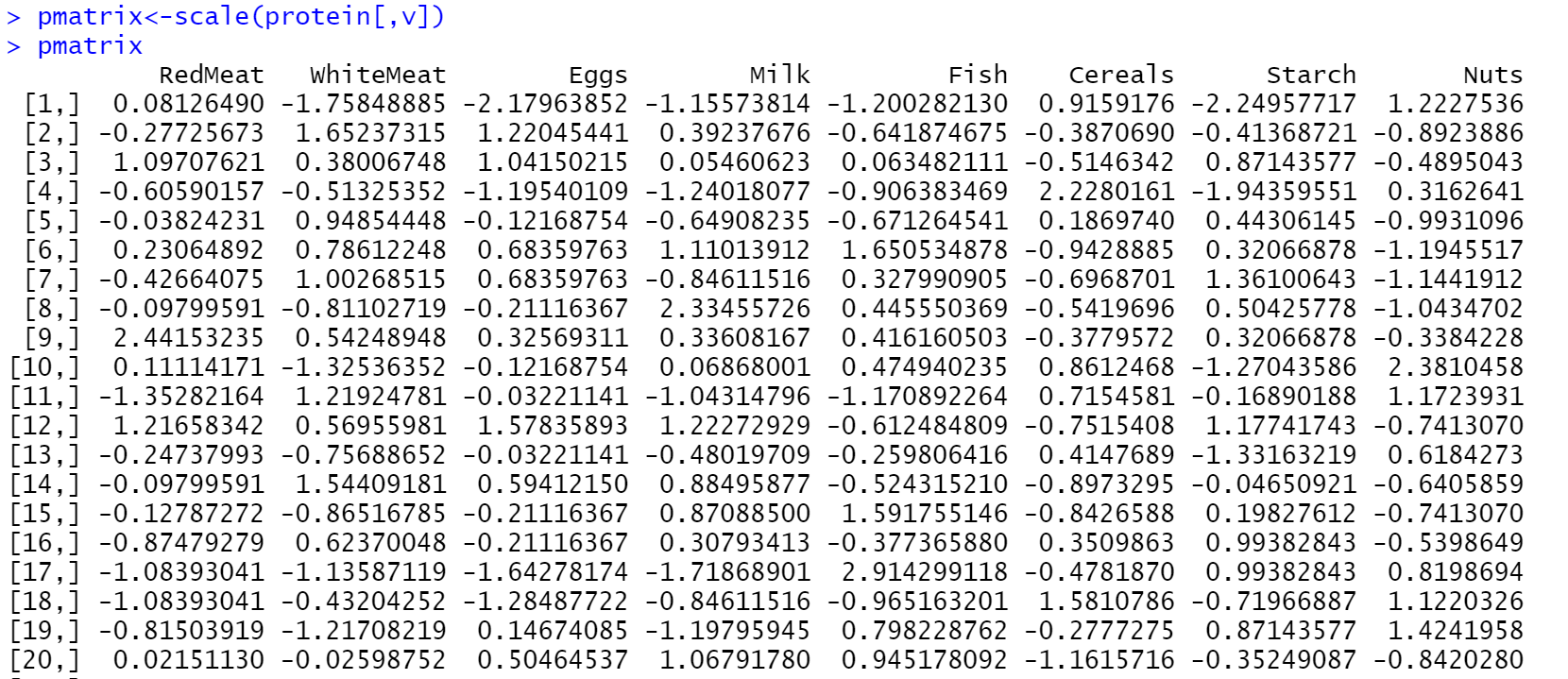
上图数据可以明显看出数据间的差距明显缩小。
4)聚类分析
对数据集进行聚类分析,k设置为5(分为五类),结果如下图所示: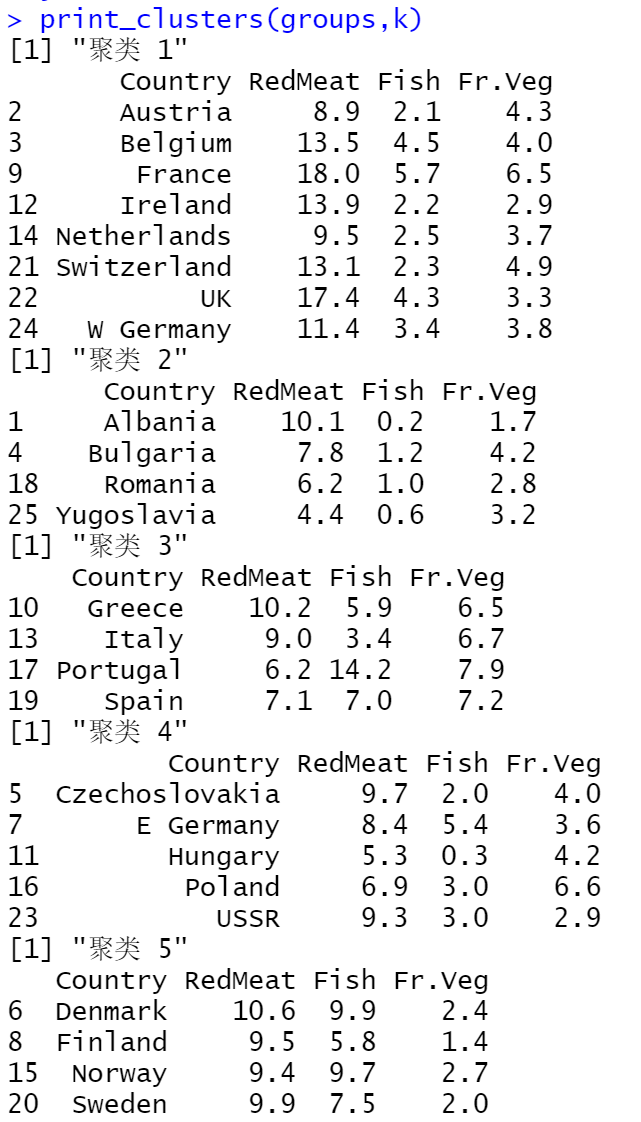
5)建立新的数据集
建立新的数据集(五列:Country,RedMeat,Fish,Fr.Veg,k),其中k表示国家所对应的类,结果如下所示: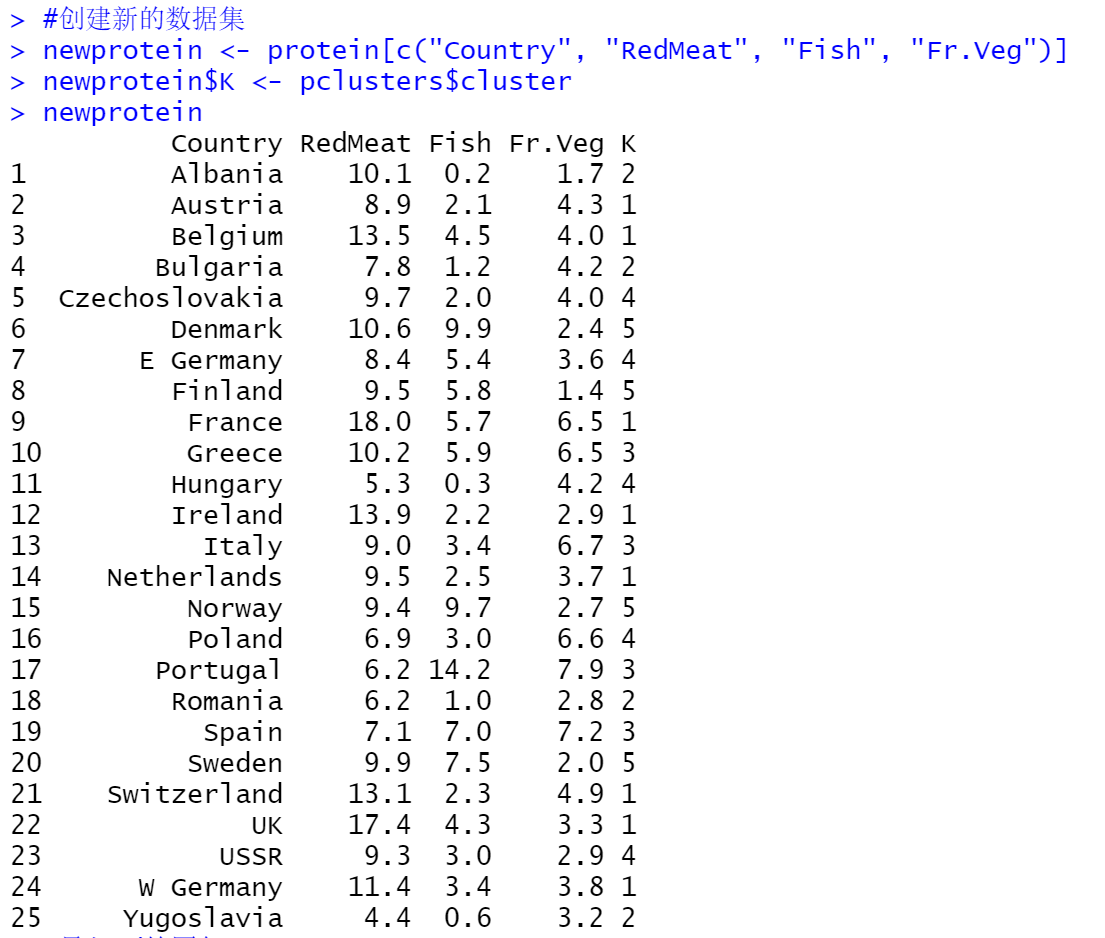
6)绘制三维聚类图
通过新建立的数据集绘制三维聚类图并保存:
结果如下图所示: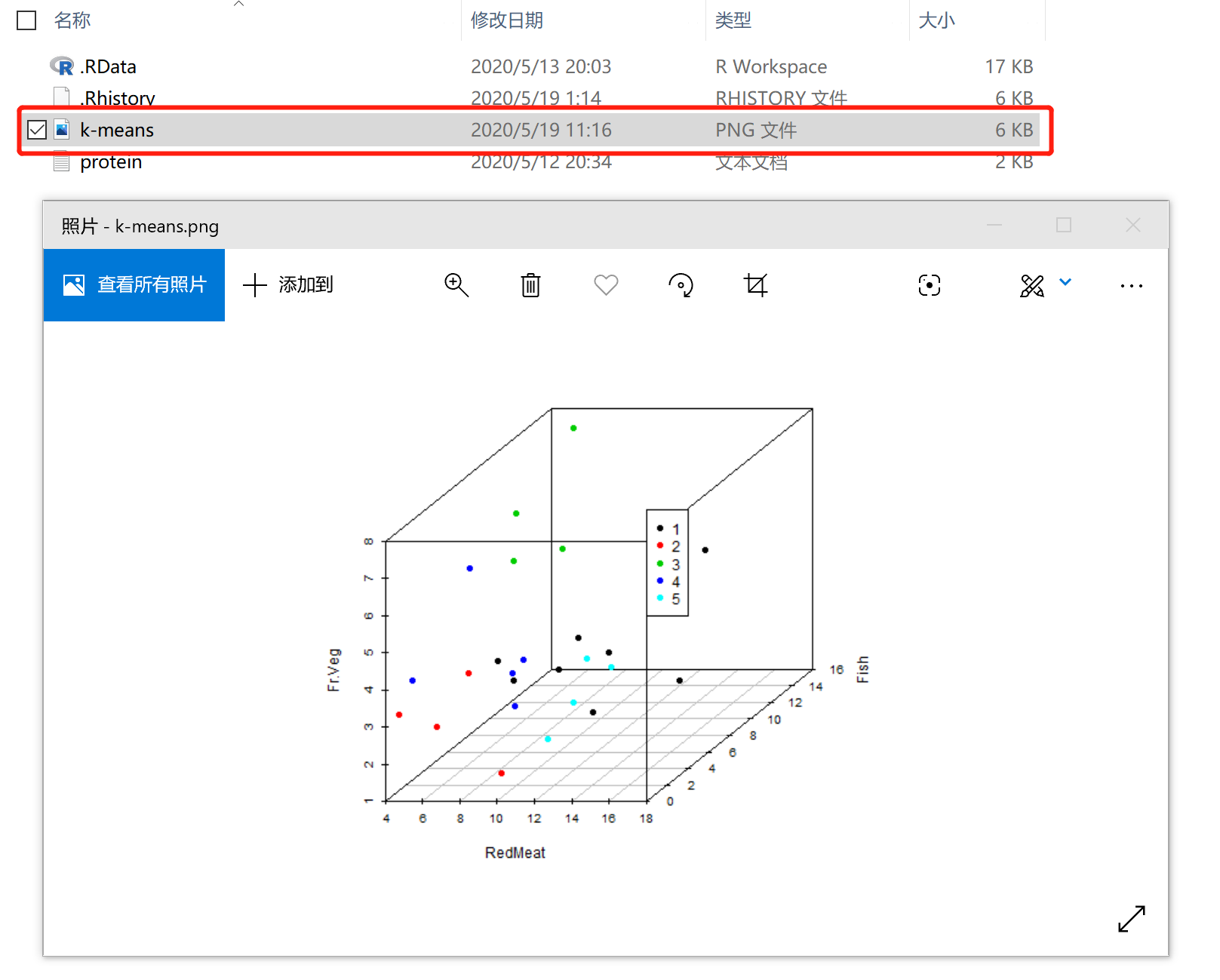
3. 出现的问题:
4. 解决方案:
1)导入scatterplot3d包辅助画图。

若有收获,就点个赞吧
0 人点赞
