注意引入mapreduce包导入相关类会发现两个类:
- org.apache.hadoop.mapreduce:新版本API,请采用该包下类
- org.apache.hadoop.mapred:旧版本API
-
MapReduce进程
MrAppMaster:负责整个程序的过程调度及状态协调
- MapTask:负责Map阶段的整个数据处理流程
- ReduceTask:负责Reduce阶段的整个数据处理流程
MapReduce编程规范
Map阶段
- 自定义Mapper继承父类并实现map()方法
- 输入为KV数据,输出也为KV数据(类型均可自定义)
-
Reduce阶段
自定义Reducer继承父类并实现reduce方法
- 输入数据为Map输出的KV类型
-
Driver阶段
相当于yarn客户端,提交整个程序到yarn集群,提交的是封装mapReduce程序后的Job对象
序列化
hadoop序列化特点
紧凑:高效实用存储空间
- 快速:读写数据额外开销小
- 可扩展:可随通信协议升级而升级
-
自定义序列化步骤
讨论 Java有了Serializable序列化接口,hadoop还需实现自己的序列化Writable接口?
Java的Serializable接口序列化会加入很多无用的头等信息,序列化数据比较重!而hadoop序列化具有紧凑,快速,可扩展,互操作等特性 实现Writable接口
- 必须有空参构造函数
- 重写序列化方法write()
- 重写反序列化readFields()
- 反序列化顺序和序列化顺序完全一致(hadoop序列化为一个先进先出队列)
- 结果显示在文件需要重写toString(),可用\t分隔
自定义bean放在key中传输,需要实现Comparaable接口
InputFormat
MapTask并行度
数据块:物理上世纪存储的数据块block
数据切片:逻辑上对数据进行分块Job的map阶段并行度由客户端在提交Job时切片数决定
- 每一个Split切片分配一个MapTask进行实例处理
- 默认情况下,切片大小=BlockSize
- 切片时不考虑整体存储,针对每一个文件单独切片
FileInputFormat切片计算
- mapreduce.input.fileinputformat.split.minsize(默认值为1)
- mapreduce.input.fileinputformat.split.maxsize(默认值为Long.MAXValue)
计算公式:Math.max(minSize, Math.min(maxSize, blockSize))
TextInputFormat:键为起始行的字节偏移量,值为字符串
- KeyValueTextInputFormat:每一行为一条记录,分隔符分割为key,value,按照分隔符分隔,默认分隔符为tab(\t);在Job的conf中配置分隔符,
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, "") - CombineTextInputFormat:切片方式进行了修改,将多个小文件划分到一个切分中,读取数据格式与Text一致,Key为偏移量,value为内容:
CombineFileInputFormat.setMaxInputSplitSize(job, 100);切分逻辑为:- 判断虚拟存储文件大小是否>=maxSize,是的话单独形成一个切片
- 不大于的话跟下一个虚拟存储文件合并,共同形成切分
- 每一个切片文件大小为 > maxSIze & < 2*MaxSize
- 虚拟存储:将目录下文件切分为小于maxSize的小文件,称之为虚拟存储(逻辑切分)
- NLineInoutFormat:map进程处理的InputSplit不再按照ock块划分,按照NLineInputFormat指定的行数N划分,输出文件的总行数/N=切片数, 不整除则切片数=商+1,其键值与TextInputFormat一致,Driver阶段指定行数:
NlineInputFormat.setNumLinesPerSplit(job, n) - 自定义:继承FileInputFormat ```java package mapreduce;
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.BytesWritable; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.RecordReader; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
/**
- @description:
自定义FileInputFormat, 实现功能是合并小文件合并为Sequence文件;
- Sequence文件为hadoop存储KV的二进制文件格式, key为路径+key,
- value为value
- @project: learn
- @author: Admin
@date: 2022/1/8 15:31 */ public class SelfFileInputFormat extends FileInputFormat
@Override public RecordReader
return new RecordReader<Text, BytesWritable>() {FileSplit fileSplit;Configuration configuration;Text key = new Text();BytesWritable value = new BytesWritable();boolean isProgress = true;@Overridepublic void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {this.fileSplit = (FileSplit) inputSplit;this.configuration = taskAttemptContext.getConfiguration();}@Overridepublic boolean nextKeyValue() throws IOException, InterruptedException {if (isProgress) {// 1. 获取文件Fs对象Path path = fileSplit.getPath();FileSystem fileSystem = path.getFileSystem(configuration);// 2. 获取输入流FSDataInputStream in = fileSystem.open(path);// 3. 读取到缓存数据byte[] buffer = new byte[(int) fileSplit.getLength()];IOUtils.readFully(in, buffer, 0, buffer.length);// 封装vvalue.set(buffer, 0, buffer.length);key.set(path.toString());IOUtils.closeStream(in);isProgress = false;return true;}return false;}@Overridepublic Text getCurrentKey() throws IOException, InterruptedException {return key;}@Overridepublic BytesWritable getCurrentValue() throws IOException, InterruptedException {return value;}@Overridepublic float getProgress() throws IOException, InterruptedException {return 0;}@Overridepublic void close() throws IOException {}};
} }
<a name="nTnXi"></a>## MapReduce工作流程1. 指定待处理文件,配置Job1. 客户端进行sumbit,sumbit之前,会对输入数据处理分片生成实际运行Job信息1. 客户端提交分隔的切片信息,Jar包(集群需要提交),配置参数(Job.split, *.jar, Job.xml)1. 资源管理(yarn生成Ma appmaster,本地为Local)根据切片计算MapTask数量并运行】1. 每个独立的MapTask去实际读取文件并进行定义的数据处理逻辑1. 每个独立的MapTask将处理后数据发往一个数据环形缓冲区- 数据环形缓冲区默认100M大小,左半部分写入数据的元数据(索引,分区,键值的位置)- 数据环形缓冲区默认使用到80%以后会将数据缓冲到磁盘,并反向继续写数据7. 对数据分区并在分区内对数据排序(字典,快排),使得分区内有序7. 将分区内有序数据缓冲到文件7. 对各个分区内文件进行Merge并归并排序7. MapTask完成后,MrappMaster启动ReduceTask(reduce数量与分区数量一致)7. 下载各个MapTask的对应分区数据放到内存或者磁盘7. 对数据文件合并并进行归并排序,读取数据进行处理7. 将数据按照定义逻辑输出至文件(一个分区一个文件)<a name="Lwl8q"></a>### MapTaskMap阶段对应上述工作流程的5-9阶段<br />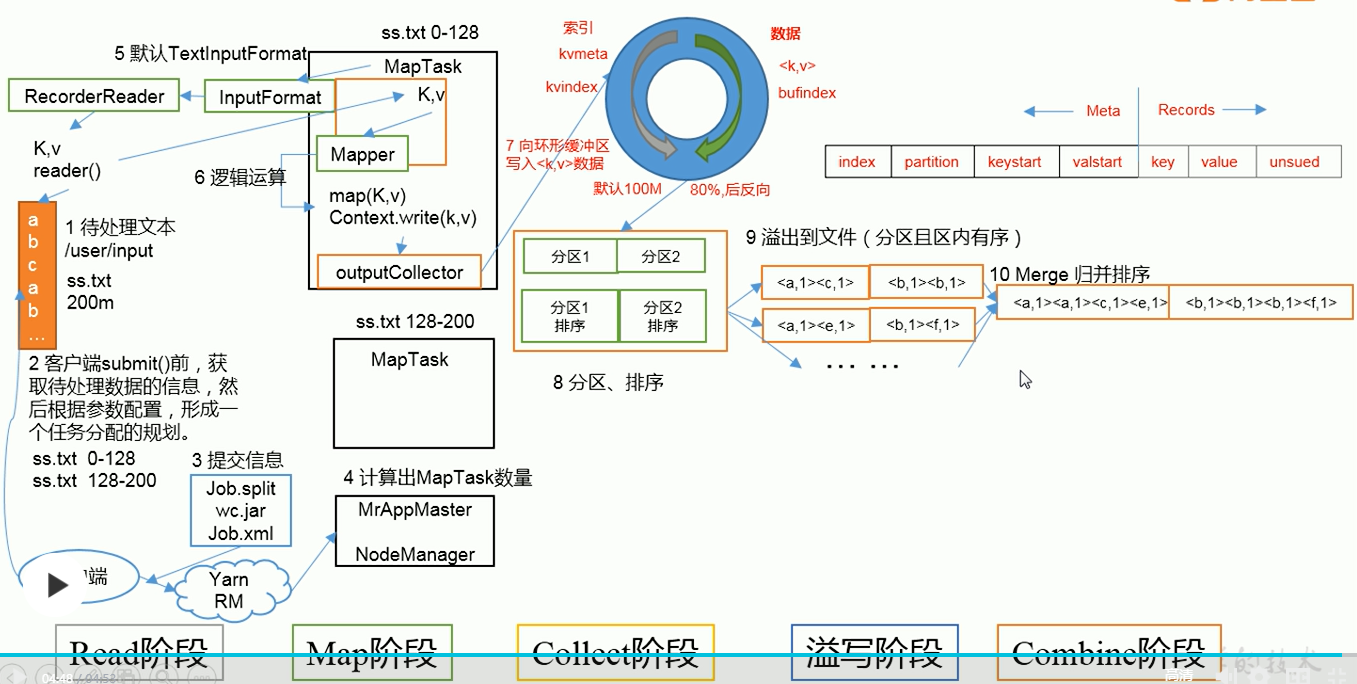<a name="Va2jF"></a>### ReduceTaskReduce阶段对应上述工作流程的11-13阶段<br />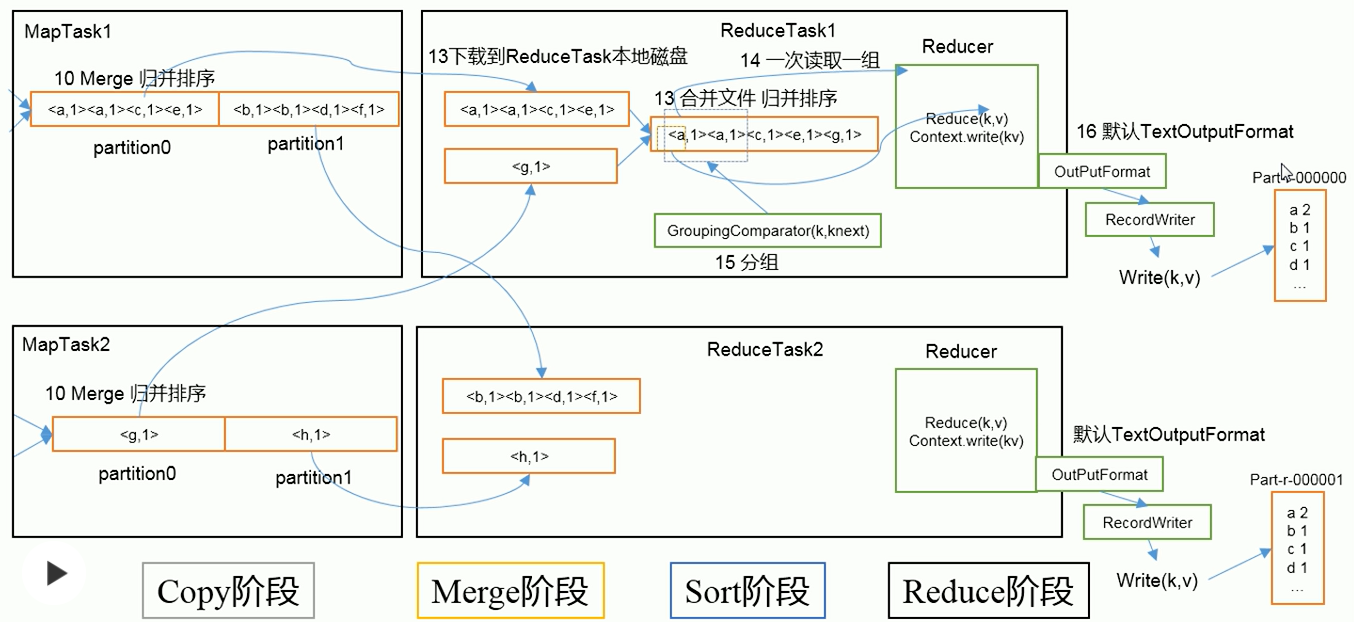<a name="EiufF"></a>### ReduceTask任务个数**_Job.getInstance_**_**()**_**_.setNumReduceTasks_**_**(**_**_1_**_**)**_**_;_**1. 设置为0表示没有Reduce阶段,输出文件个数和Map个数一致1. ReduceTask个数默认为1,输出文件为11. 数据分布不均匀可能在Reduce阶段产生数据倾斜1. 如果ReduceTask设置为1,但分布数大于1,则不执行分区<a name="Z4k89"></a>### shuffle**Map方法**之后,**Reduce方法**之前的数据处理过程称为**shuffle**<br />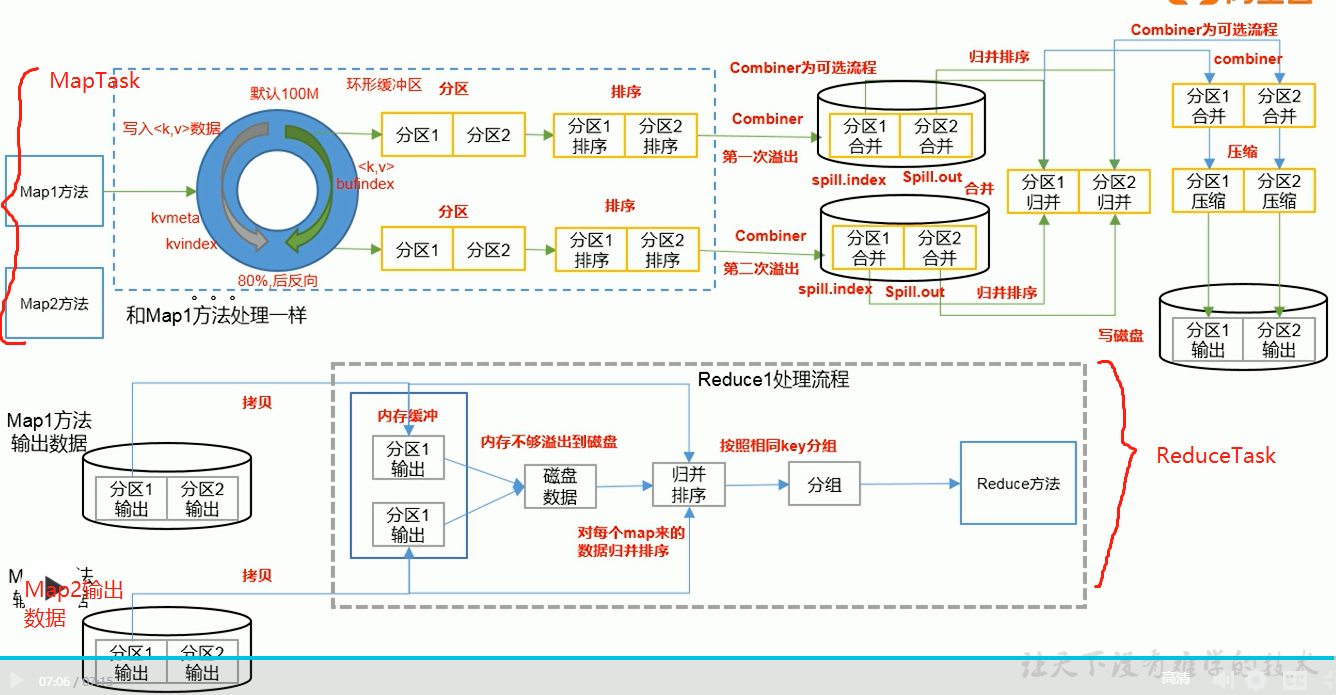<a name="QKpW5"></a>## Partition分区默认分区:HashPartitioner```javapublic class HashPartitioner<K, V> extends Partitioner<K, V> {/** Use {@link Object#hashCode()} to partition. */public int getPartition(K key, V value,int numReduceTasks) {return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;}}
- ReduceTask数量大于自定义partition的结果数量,会有空输出文件
- ReduceTask数量小于自定义partition的结果数量,报错,有数据无法映射到分区
- ReduceTask数量=1,不管是否自定义partitioner,正常运行并输出一个文件
- 分区号从0开始累加
排序
map和reduce过程均会对数据按照key进行排序,默认排序为字典顺序排序,为快速排序算法
- map过程,在数据放置到数据缓冲区,缓冲区使用率达到阈值(80%)后,对缓冲区数据进行快速排序,并将排序数据缓冲到磁盘,数据处理完毕后,会对磁盘上文件进行归并排序
reduce过程,从mapTask上远程拷贝对应的数据文件,文件大小超过一定阈值,则缓冲至磁盘,否则存储在内存,如果磁盘上文件数量达到一定阈值,进行归并排序生成大文件,如果内存中文件大小或数量超过一定阈值,进行合并后数据缓冲到磁盘,所有数据拷贝完成后,reduceTask对统一内存和磁盘数据进行归并排序
排序分类
部分排序:MapReduce根据输入记录的键对数据及排序,保证输出的每个文件内部有序
- 全排序:MapReduce最终输出结果只有一个文件,且文件内部有序
- 辅助排序(GroupingComparator分组):Reduce端对key进行分组,应用于在接收的key为对象时,想让一个或几个字段相同的key进入到同一个reduce方法可以采用分组排序
- 二次排序:自定义排序过程,compareTo的判断条件为两个位二次排序
自定义排序只需要实现WritableComparable接口
分组排序(分组排序)
- 自定义类继承WritableComparator,重写compare(a,b)方法 ```java package mapreduce;
import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; import org.apache.hadoop.mapreduce.Job;
import java.io.IOException;
/**
- @description:
- @project: learn
- @author: Admin
@date: 2022/1/8 21:32 */ public class SelfGroupComparator extends WritableComparator {
/ 使用方式 / public static void main(String[] args) throws IOException {
Job.getInstance().setGroupingComparatorClass(SelfGroupComparator.class);}
protected SelfGroupComparator() {
// 必须实现, 且传true值 super(SelfBean.class, true);}
@Override public int compare(WritableComparable a, WritableComparable b) {
SelfBean aBean = (SelfBean) a; SelfBean bBean = (SelfBean) b; // aBean和bBean的比较逻辑, 比如如何判断相同的key return super.compare(a, b);Combiner
- Combiner的父类即Reducer;与Reducer区别在于运行的位置,Combiner在每一个MapTask运行的节点运行,意义是对一个MapTask的输出进行局部汇总(减少网络传输);运用前提的是不能影响最终业务,即Combiner输出KV与Reducer的输入KV应该对应
- 自定义Combiner继承Reducer类,并在Job中指定,Job.setCombinerClass()
OutputFormat
- TextOutputFormat:每条记录写为文本行,键和值可以是任意类型
- SequenceFileOutFormat:可作为后续其它mapReduce的输入,一种较好的输入格式,因为其格式紧凑,易被压缩
- 自定义OutputFormat:控制文件输出路径和输出格式,继承FileOutputFormat ```java package mapreduce;
import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
- @description: 判断key值是否包含,写入不同文件
- @project: learn
- @author: Admin
@date: 2022/1/8 22:38 */ public class SelfOutputFormat extends FileOutputFormat
public static void main(String[] args) throws IOException {
Job.getInstance().setOutputFormatClass(SelfOutputFormat.class);}
@Override public RecordWriter
return new SelfRecordWriter(job);}
class SelfRecordWriter extends RecordWriter
private FSDataOutputStream one; private FSDataOutputStream two; public SelfRecordWriter(TaskAttemptContext job) { try { FileSystem fileSystem = FileSystem.get(job.getConfiguration()); one = fileSystem.create(new Path(FileOutputFormat.getOutputPath(job).getName() + "/1")); two = fileSystem.create(new Path(FileOutputFormat.getOutputPath(job).getName() + "/2")); } catch (IOException e) { e.printStackTrace(); } } @Override public void write(Text key, NullWritable value) throws IOException, InterruptedException { String keyStr = key.toString(); if (keyStr.contains("1")) { one.writeBytes(keyStr); } else { two.writeBytes(keyStr); } } @Override public void close(TaskAttemptContext context) throws IOException, InterruptedException { IOUtils.closeStream(one); IOUtils.closeStream(two); }} }
<a name="CMHci"></a>
## Join
<a name="ho7Rk"></a>
### ReduceJoin
- Map端将不同来源的key/value对,使用连接字段作为key,其余数据部分加标记来源作为value进行数据输出
- Reduce端拷贝来自同一个key的数据,包括多种来源的数据,在同一个key中进行标记数据分开合并操作
<a name="cGNhM"></a>
### MapJoin
- 适应于一张表比较小,另外一张比较大场景
- MapJoin是因为Reduce端处理过多表容易发生数据倾斜,所以在Map端缓存多张表,提前处理业务逻辑,减少数据传输以及reduce端占用
- 具体实现是**Distributedcashe**:在Mapper逻辑的setup阶段,将文件读取到缓存集合中,并在驱动函数中加载缓存:_job.addCacheFile(new URI(file://xx))_
<a name="BxQ5N"></a>
### 计数器
Hadoop为每个作业维护若干内置计数器,以描述多项指标。例如,某些计数器记录已处理的字节数和记录数,使用户可监控已处理的输入数据量和已产生的输出数据量。
<a name="O2Oae"></a>
#### API
```java
/**
* 自定义枚举方式
*/
enum SelfCounter {NORMARL, FAILED}
// 自定义计数器+1
context.getCounter(SelfCounter.NORMARL).increment(1);
/**
* 计数器组名和名称
*/
context.getCounter( "counterGroup", "counter" ).increment(1);
压缩
减少底层存储系统HDFS读写字节数,压缩提高网络带宽和磁盘空间的效率
压缩基本原则:
- 运算密集型Job,少用压缩
- IO密集型Job,多用压缩
常见压缩方式
| 压缩格式 | hadoop自带 | 算法 | 文件扩展名 | 是否可切分 | 切换压缩格式,程序是否需要修改 | | —- | —- | —- | —- | —- | —- | | DEFLATE | 是 | DEFLATE | .deflate | 否 | 不需,和文本处理一致 | | Gzip | 是 | DEFLATE | .gz | 否 | 不需,和文本处理一致 | | bzip2 | 是 | bzip2 | .bz2 | 是 | 不需,和文本处理一致 | | LZO | 否,需要安装 | LZO | .lzo | 是 | 需要建立索引,指定输入格式 | | Snappy | 否,需要安装 | Snappy | .snappy | 否 | 不需,和文本处理一致 |
支持的压缩编码
| 压缩格式 | 对应编码/解码 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
压缩性能比较
| 压缩算法 | 原始大小 | 压缩大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9Gb | 49.3MB/s | 74.6MB/s |
| Snappy | http;://google.github.io/snappyl |
压缩参数配置
- 数据输入:[core-site.xml]中io.compresiom.codecs参数控制输入端(map之前)的压缩,默认解码器为DefaultCodec,GzipCodec, Bzip2Codec;hadoop判断文件扩展名来选择解码器
- Map数据输出:[mapred-site.xml]中mapreduce.map.output.compress(默认值false)控制是否启用输出压缩;mapreduce.map.output.compress.codec(默认值为DefaultCodec)控制输出的压缩编码
- Reduce阶段:[mapred-site.xml]中mapreduce.output.fileoutputformat.compress(默认值false)控制是否启用压缩;mapreduce.output.fileoutputformat.compress.codec(默认DefaultCodec)控制压缩算法;ma[reduce.output.fileoutputformat.compress.type(默认值RECORD)控制压缩方式(RECORD为针对行压缩,NONE不压缩,BLOCK针对数据块压缩)
示例
package mapreduce.compress;
import com.jcraft.jsch.IO;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.*;
import org.apache.hadoop.util.ReflectionUtils;
import java.io.*;
import java.util.Objects;
/**
* @description:
* @project: learn
* @author: Admin
* @date: 2022/1/9 16:30
*/
public class CompressDemo {
public static void main(String[] args) throws Exception {
String sourcePath = "F:\\font-end\\js\\3.js";
// GzipCodec, DefaultCodec
// Class.forName(compressName)
Class compressClass = BZip2Codec.class;
// compress(sourcePath, compressClass);
decompress("F:\\font-end\\js\\3.js.bz2");
}
private static void compress(String sourcePath, Class compressClass) throws IOException {
FileInputStream fis = new FileInputStream(new File(sourcePath));
CompressionCodec instance = (CompressionCodec) ReflectionUtils.newInstance(compressClass, new Configuration());
FileOutputStream fos = new FileOutputStream(new File(sourcePath + instance.getDefaultExtension()));
CompressionOutputStream cos = instance.createOutputStream(fos);
IOUtils.copyBytes(fis, cos, 1024 * 1024, false);
IOUtils.closeStream(cos);
IOUtils.closeStream(fos);
IOUtils.closeStream(fis);
}
private static void decompress(String sourcePath) throws Exception {
CompressionCodecFactory factory = new CompressionCodecFactory(new Configuration());
CompressionCodec codec = factory.getCodec(new Path(sourcePath));
if (Objects.isNull(codec)) {
throw new Exception("cant't support!");
}
FileInputStream fis = new FileInputStream(new File(sourcePath));
CompressionInputStream cis = codec.createInputStream(fis);
FileOutputStream fos = new FileOutputStream(new File(sourcePath + ".decode"));
IOUtils.copyBytes(cis, fos, 1024 * 1024, false);
IOUtils.closeStream(fos);
IOUtils.closeStream(cis);
IOUtils.closeStream(fis);
}
}
MapReduce优化
跑得慢原因
- 计算机性能(CPU,内存,磁盘,网络)
- IO操作优化
- 数据输入阶段:合并小文件(CombineTextInputFormat)
- Map阶段:
- 减少溢写/Spill(缓冲区队列写入至磁盘)次数:调整io.sort.mb(缓冲区大小,默认100M)以及sort.spill.precent(默认80%)参数,使得Spill次数减少;、
- 减少合并merge次数:调整io.sort.factor次数,增大merge的文件数目,使得merge次数减少
- Map之后不影响业务逻辑增加Combine处理,减少IO
- Reduce阶段:
- 设置合理Map和Reduce次数(不能过大或过小)
- 设置Map,Reduce共存:调整slowstart.completedmaps参数,使得Map运行到一定程序,Reduce开始运行,减少Reduce等待时间
- 规避使用Reduce,减少shuffle
- 合理设置Reduce端的Buffer,默认情况,Reduce端拉取数据达到一个阈值,buffer中数据写入磁盘,Reduce从磁盘读取数据;可以通过参数mapred.job.reduce.input.buffer.percent(默认0.0)值大于0,保留指定比例的内存读Buffer中数据直接到Reduce端使用
- IO传输:
- 数据压缩,减少网络IO时间
- 使用SequenceFile二进制文件
数据倾斜:
mapreduce.map.memory.mb:一个MapTask可用资源上限,默认1024MB,如果MapTask超过该值,任务将被杀死
- mapreduce.reduce.memory.mb:一个ReduceTask可用资源上限,默认1024MB,如果ReduceTask超过该值,任务将被杀死
- mapreduce.map.cpu.vcores:每个MapTask可使用的最多cpu core数目,默认值为1
- mapreduce.reduce.cpu.vcores:每个ReduceTask可使用的最多cpu core数目,默认值为1
- mapreduce.reduce.shuffle.parllelcopies:每个Reduce去Map中取数据的并行数,米认知是5
- mapreduce.reduce.shuffle.merge.percent:Buffer中数据达到多少比例开始写入磁盘,默认0.66
- mapreduce.reduce.shuffle.input.buffer.percent:Buffer大小占Reduce可用内存的比例,默认0.7
- mapreduce.reduce.input.buffer.percent:指定多少比例内存用来存放Buffer中数据,默认值0.0
[yarn-default.xml] 应该在yarn启动之前配置:
- yarn.schdeuler.minimum-allocation-mb:给应用程序Container分配的最小内存,默认1024
- yarn.scheduler.maximum-allocation-mb:给应用程序Container分配的最大内存,默认8192
- yarn.scheduler.minimum-allocation-vcores:给应用程序Container申请的最小CPU核数,默认1
- yarn.scheduler.maximum-allocation-vcores:给应用程序Container申请的最大CPU核数,默认32
[mapred-default.xml] shuffle优化参数,在yarn启动前配置好
- mapreduce.task.io.sort.mb:shuffle环形缓冲区大小,默认100M
- mapreduce.map.sort.spill.percent:环形缓冲区溢出的阈值,默认80%
容错相关参数:
- mapreduce.map.maxattemps:MapTask最大重试次数,默认值4,超过认为任务失败
- mapreduce.reduce.maxattempts:ReduceTask最大重试次数,默认值4,超过认为任务失败
- mapreduce.task.timeout:Task超时时间,一个Task在一定时间内没有任何进入,即不会读取新数据,也没有输出数据,则认为Task处于Block状态,防止一个Task一直处于Block状态,超时时间设置该值,默认600000毫秒

若有收获,就点个赞吧
0 人点赞
