HDFS基础
分布式文件系统的一种,用来分布式存储数据文件,通过目录树定位到文件;适合一次写入多次读出的场景,且不支持修改文件
- 优点:
- 高可用性
- 数据文件多个副本保存
- 某一节点数据文件丢失可以自动恢复
- 适合大数据处理
- 数据规模可以支持GB/TB/PB级别
- 文件规模可以支持百万规模的文件数量
- 构建在廉价服务器上
- 高可用性
缺点:
-
主从(master/slave)结构,包含HDFS Client、NameNode、DataNode和Secondary NameNode
- HDFS Client(HDFS客户端)
- 提供一些命令来管理、访问 HDFS,比如启动或者关闭HDFS。
- 与 DataNode 交互,读取或者写入数据;读取时,要与 NameNode 交互,获取文件的位置信息;写入 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储
- NameNode(Master)
- 管理 HDFS 的名称空间
- 管理数据块(Block)映射信息
- 配置副本策略
- 处理客户端读写请求
- DataNode(Slave):NameNode 下达命令,DataNode 执行实际的操作
- 存储实际的数据块
- 执行数据块的读/写操作。
- Secondary NameNode:并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
- 辅助 NameNode,分担其工作量
- 定期合并 fsimage和fsedits,并推送给NameNode
- 在紧急情况下,可辅助恢复 NameNode
- HDFS Client(HDFS客户端)
Block块大小设置
可以通过hdfs-site.xml中的dfs.blocksize来设置;HDFS块大小取决于磁盘速率
HDFS Shell操作
- bin/hadoop fs xxshell
- bin/hdfs dfs xxshell(dfs为fs的分布式实现类)
# 查看支持命令bin/hadoop fs# 查看指定命令使用bin/hadoop fs -help rm# 设置文件副本数量,副本数量超过datanode节点数量会等到datanode节点增加才会生成多余副本bin/hadoop fs -setrep 2 /xx
数据流操作

写数据流程
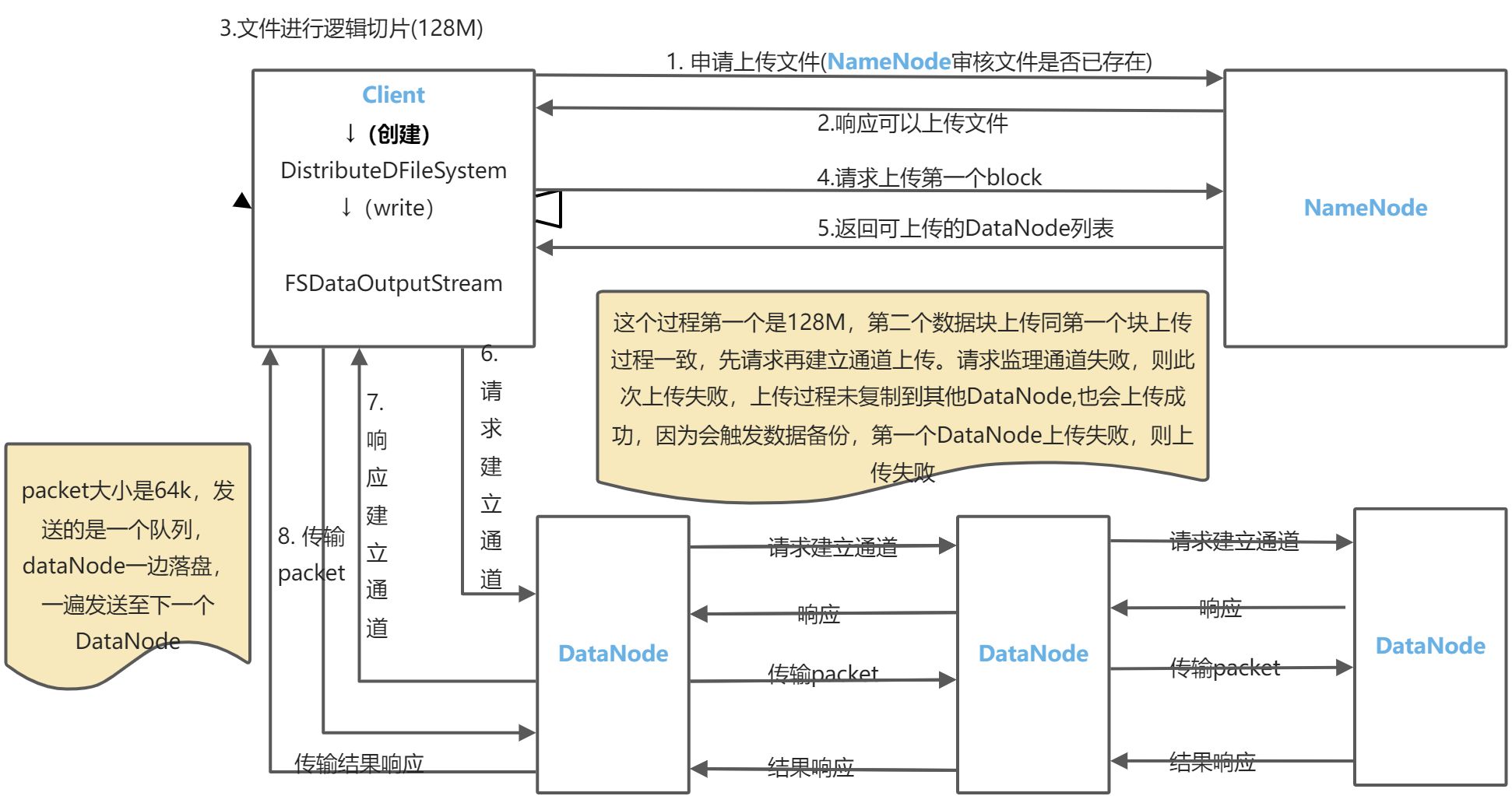
- Client向NameNode申请上传文件,NameNode审核文件是否存在
- NameNode向Client响应可以上传文件
- Client对文件进行逻辑切片(默认每片128M)
- Client向NameNode请求上传第一个block文件
- NameNode响应Client返回可上传的DataNode列表(设置的副本是几个,就返回几个DataNode)
- Client向DataNode请求建立上传通道
- DataNode向Client响应建立上传通道
- Client向DataNode传输packet(packet大小是64K,发送的是一个队列,DataNode一遍落盘,一遍发送到下一个DataNode)
节点距离
数据读取返回的dataNode列表为计算最短的节点距离的node列表;
节点距离定义:两个节点到达最近的共同祖先的距离总和
机架感知
- Data Replication
数据块的存储涉及到一个概念,叫做机架感知。意思是同一个数据的备份,会放到不同机架的不同节点上,防止数据的丢失。通常冗余的数据为3,放数据的策略如下:
- 第一个block放到与client同一个机器的DataNode节点上,如果Client不在集群范围,则随机选取一个DataNode存放
- 第二个随机选取同一个机架上的另外一个DataNode节点
- 第三个放到不同机架上的DataNode节点上
summary:这样做的目的是,如果第一个DataNode出现故障,可以从最近的节点上拿数据,就是同一个机架上的节点,这样肯定比跨机架快。如果整个机架挂了,别的机架上还有数据,不至于数据的丢失
读数据流程

- Client向NameNode请求下载文件
- NameNode向Client响应文件是否存在
- Client向NameNode请求下载第一个block文件
- NameNode响应Client返回DataNode列表
- Client向DataNode请求建立下载通道
- DataNode向Client响应建立下载通道
- DataNode向Client传输文件
- Client向NameNode请求下载第二个block文件,并重复4-7步骤
Nn & SecondaryNn
nn & 2nn工作机制
- FsImage:在磁盘中备份元数据
- Edits文件:只进行追加操作,元数据有更新或添加,修改内存中元数据并追加到Edits文件中
- SecondaryNameNode:定期合并FsImage和Edits文件
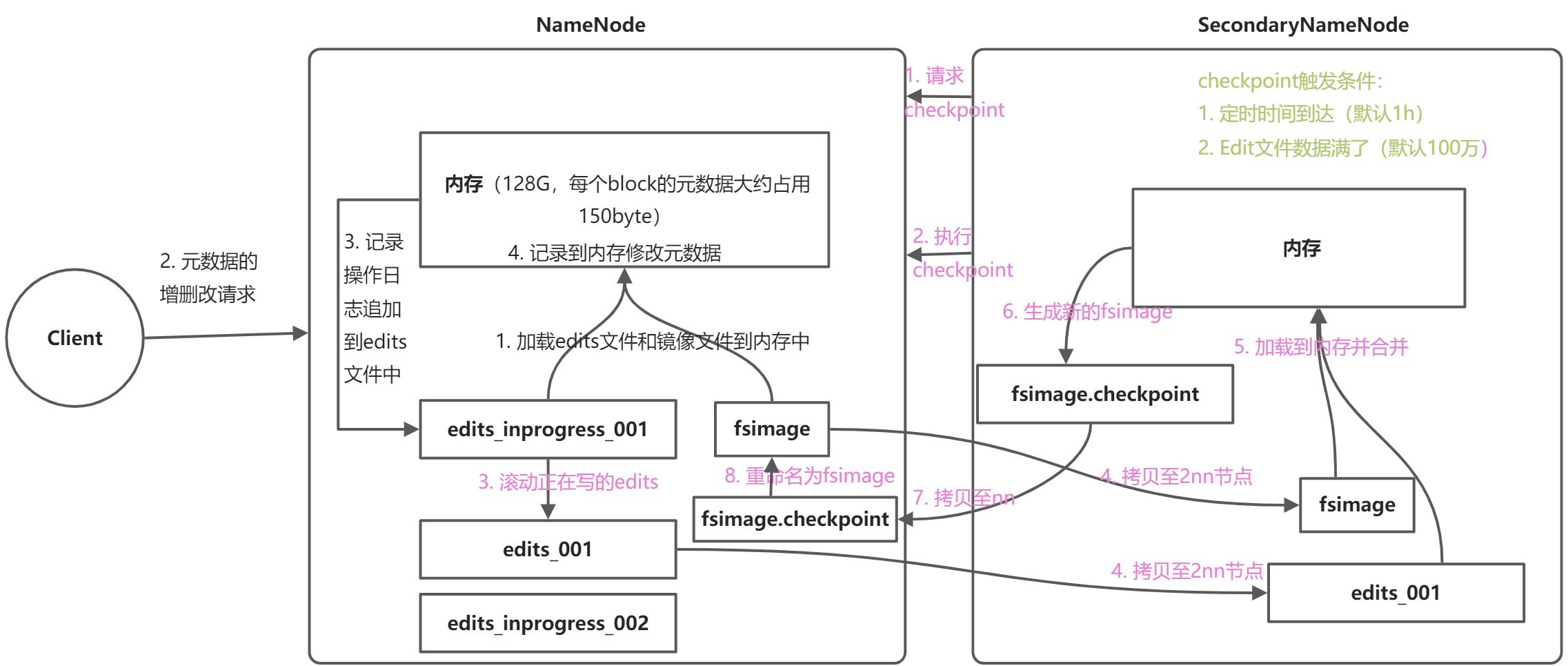
FsImage & Edits
fsimage & edits文件一般存放于/设置文件路径//tmp/dfs/name/current下存有edits文件以及fsimage文件
nn节点中相比2nn节点多了个seen_txid,文件中记录的为当前edits文件的序列号,图中为97,查看文件为乱码,可以通过hdfs命令查看
- /bin/hdfs oiv -p XML -i fsimage_0000000000000000 -o fsimage.xml
- oiv:查看离线fsimage文件
- -p XML:指定xml格式
- -i:输入文件
- -o:输出文件
/bin/hdfs oev -p XML -i edits_000000001-00000000001 -o edits.xml
checkpoint设置
时间设置:[hdfs-site.xml] dfs.name.checkpoint.period(单位为s秒,默认为3600s,即1小时)
- edits文件大小设置:
- 移动SecondaryNameNode中数据移动至NameNode节点中(SeocndaryNameNode与nn查了edit_inprogress_xx文件, scp xxx /xxx)
使用-importCheckpoint选项启动nn守护进程,将2nn数据拷贝至nn目录中
- 修改[hdfs.xml]文件值:
<!-- checkpoint时间设置短一点 --><property><name>dfs.namenode.checkpoint.period</name><value>120</value></property><!-- 设置namenode数据的位置 --><property><name>dfs.namenode.name.dir</name><value>/opt/hadoop3.3.1/data/tmp/dfs/name</value></property>
- 修改[hdfs.xml]文件值:
如果2nn与nn不在同一个节点,需要将2nn中存储数据目录拷贝至nn存储数据平级目录(name, data那一级目录),并删除in_use.lock文件
- 导入检查点数据执行命令: bin/hdfs namenode -importcheckpoint
启动nn:sbin/hadoop-daemon.sh start namenode
集群安全模式
nn启动,nn启动将Fsimage加载入内存,并执行edits文件的操作,一旦成功创建系统元数据映射,则创建一个新的Fsimage文件和一个空的edits文件;此时,nn开始监听dn请求,这个过程nn一直运行在安全模式下,即nn文件系统对于客户端只读
- dn启动,系统中数据块位置以块列表形式存储dn中,系统正常操作期间,nn会保存所有块位置映射信息在内存中;安全模式下,各个dn向nn发送最新的块列表信息,nn了解到足够多的块位置信息后,即可高效运行文件系统
- 安全模式退出判断:满足了最小副本条件,nn在30s之后退出安全模式;最小副本条件指的是文件系统中99.9%的块满足最小副本级别(dfs.replication.mon=1),在启动一个刚刚格式化的hdfs集群时,系统中没有任何块,所以nn不会进入安全模式
基本语法
- bin/hdfs dfsadmin -safemode get(查看安全模式状态)
- bin/hdfs dfsadmin -safemode enter(进入安全模式状态)
- bin/hdfs dfsadmin -safemode leave(离开安全模式状态)
bin/hdfs dfsadmin -safemode wait(等待安全模式状态)
nn多目录配置
[hdfs-site.xml]增加配置(多目录中文件内容一样,保证数据副本可靠):
<property><name>dfs.namenode.name.dir</name><value>file:///path1,file:///path2</value></property>
DN
DN工作机制
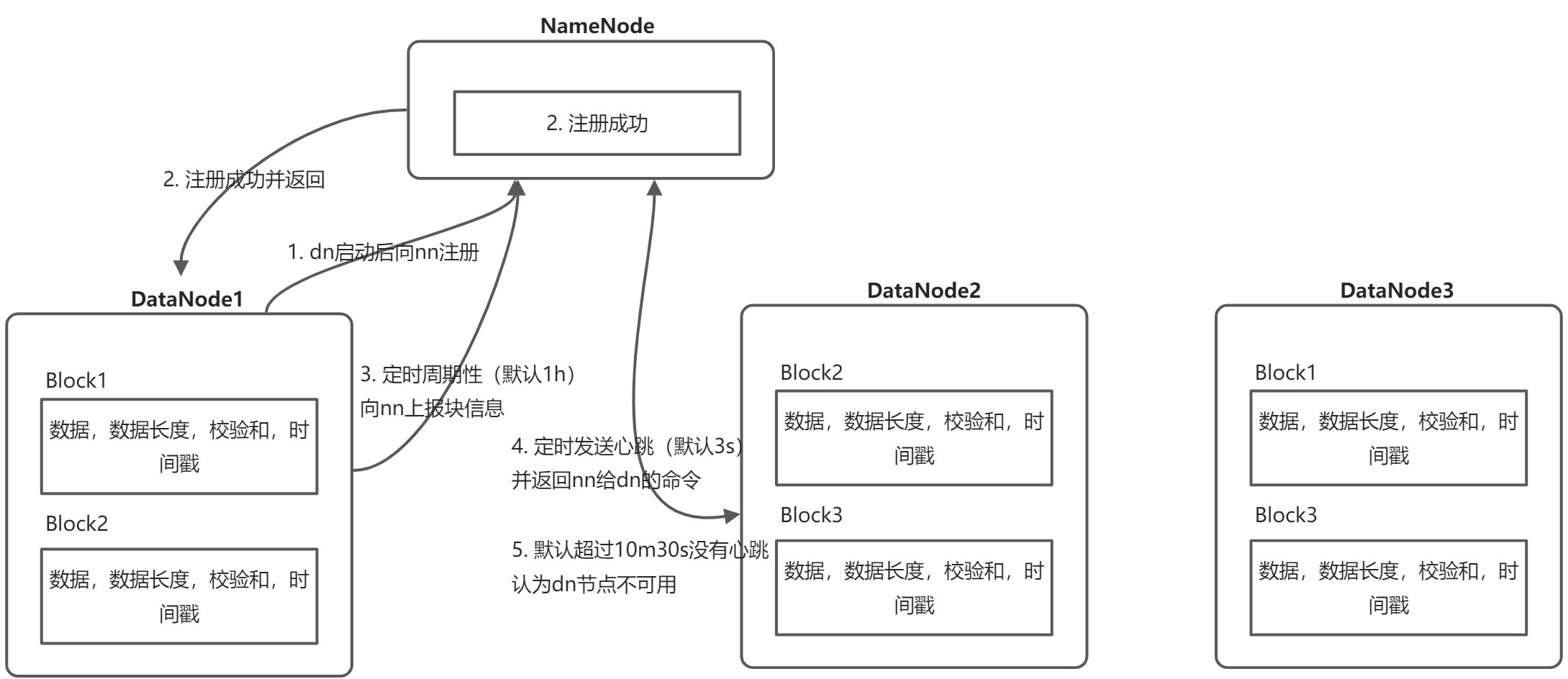
DataNode启动后向NameNode注册,表示该NameNode在线
- 注册成功后DataNode周期性(一个小时)的向NameNode发送块信息。 DateNode上存储的不只是数据块,每一个数据块对应一个文件代表每一个数据块的元信息(数据长度,检验和,时间戳等)。检验和的作用是,保证数据的完整性,有CRC校验,MD5校验等,元信息用的是MD5校验,block用的是CRC校验,当Client向DataNode读取数据块的时候,会重新计算校验和,如果和刚开始存的不一致,说明Block损坏,Client读取其他节点的block。
- DataNode扩展基于此,只需配置好启动就可以了,不要配置slaver,NameNode也不需要事先知道这个DataNode,因为启动之后会自动去NameNode注册
- DataNode会每隔三秒会向NameNode发送一次心跳,并且会带回NameNode的命令,比如复制数据到另一块机器,或者删除多余的数据等。如果NameNode超时没有收到DataNode心跳,并不会立即判定DataNode的死亡,要经过一段等待时间,这个时间是超时时长。
- 超时时长计算公式(dfs.namenode.heartbeat.recheck-interval这个参数根据字面意思是检查心跳的间隔,默认是5分钟;dfs.heartbeat.interval 这个就是心跳了,默认是3秒,所以超时时间是10分钟+30秒;这两个参数是可配置的,在hdfs-site.xml中配置,dfs.namenode.heartbeat.recheck-interval 这个参数的单位是毫秒,这个 dfs.heartbeat.interval参数单位是秒):

数据完整性
- dn读取block块的时候,计算block的checksum(校验和)
- 计算的校验和和创建时checksum对比
-
dn节点新增
拷贝配置到新服务器(记得清除掉源服务器带来的data以及logs文件)
- 启动datanode服务
白名单 & 黑名单
- 在nn节点的hadoop安装目录/etc/hadoop下创建dfs.hosts文件(名称可以自定义)
- dfs.hosts添加主机名称或者ip地址
[hdfs-site.xml]增加配置
<property><name>dfs.hosts</name><value>/opt/hadoop3.3.1/etc/hadoop/dfs.hosts</value></property>
配置分发到所有hdfs节点(nn和dn)
- 刷新nn节点:
bin/hdfs dfsadmin -refreshNodes 刷新yarn节点:
bin/yarn rmadmin -refreshNodes黑名单
在nn节点的hadoop安装目录/etc/hadoop下创建dfs.hosts.exclude文件(名称可以自定义)
- dfs.hosts添加主机名称或者ip地址
[hdfs-site.xml]增加配置
<property><name>dfs.hosts.exclude</name><value>/opt/hadoop3.3.1/etc/hadoop/dfs.hosts.exclude</value></property>
配置分发到所有hdfs节点(nn和dn)
- 刷新nn节点:
bin/hdfs dfsadmin -refreshNodes - 刷新yarn节点:
bin/yarn rmadmin -refreshNodesDN多目录
- hdfs-site.xml]增加配置(多目录中存储不同数据块):
<property><name>dfs.namenode.data.dir</name><value>file:///path1,file:///path2</value></property>
特性
集群数据拷贝
bin/hadoop distcp hdfs:node1:9000/txt.txt hdfs//:node1:9000/txt.txt hdfs//:node2:9000/txt.txt
小文件优化
- 数据采集,将小文件合并为大文件合并
- MapReduce阶段Combine逻辑切分为大文件
archive命令
大量小文件会消耗nn节点内存
解决方法:使用HDFS归档文件(HAR文件),即一个更高效的文件存档工具,它将文件存入HDFS块,减少nn内存使用并允许对文件进行透明访问(HDFS归档文件对内还是一个个独立文件,但是对nn而言是一个整体,减少nn占用)
归档命令(其实命令为一个mapreduce任务):bin/hadoop archive -archiveName xx.har -p srcPath targetPath
查看归档文件:使用har://协议查看路径har文件SequenceFile
SequenceFile由一系列二进制key/value组成,如果将key设置为文件名,value为文件内容,可将小文件合并为大文件CombineFileInputFormat
将多个小文件逻辑切分为大文件开启JVM重用
对于大量小文件Job,开启JVM重用较少45%运行时间;
JVM重用原理一个Map运行在JVM上,开启重用后,该Map在JVM上运行完毕,JVM继续运行其他Map;(将mapreduce.job.jvm.numtasks设置在10-20之间)回收站功能
回收站可以将删除的文件在不超时情况下进行文件恢复,起到防止误删除
- 回收站参数[core-site.xml]
- fs.trash.interval:默认值0表示关闭回收站,大于0表示文件存活时间
- fs.trash.checkpoint.interval:默认值0表示回收站间隔时间
- 要求:fs.trash.checkpoint.interval <= fs.trash.interval
- hadoop.http.staticuser.user:回收站用户名称
- 回收站路径为:/user/dr.who/.TRASH(dr.who为默认用户,文件为hdfs路径)
- 通过程序删除的文件不会进入回收站,需要手动调用 new Transh(conf).moveToTrash(path)
- 清空回收站:
bin/hadoop fs -expunge -
快照管理
快照即对目录进行备份,但执行快照不会立即复制所有文件,而是指向同一个文件,写入发生时,才会产生新文件
bin/hdfs dfsadmin in -allowSnapshot path:开启指定目录path的快照功能
- bin/hdfs dfsadmin in -disallowSnapshot path:禁止指定目录的快照,默认禁用
- bin/hdfs dfsadmin in -createSnapshot path:对目录path创建快照
- bin/hdfs dfsadmin in -createSnapshot path name:创建快照并指定名称
- bin/hdfs dfsadmin in -renameSnapshot path oldName newName:重命名快照
- bin/hdfs lsSnapshottableDir:列出当前用户快照目录
- bin/hdfs snapshotDiff path1 path2:比较path1和path2两个目录快照不同
- bin/hdfs dfs -deleteSnashot
:删除快照

若有收获,就点个赞吧
0 人点赞
