yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当月一个分布式操作系统平台,而MapReduce程序相当于运行在操作系统上的应用程序
基本架构
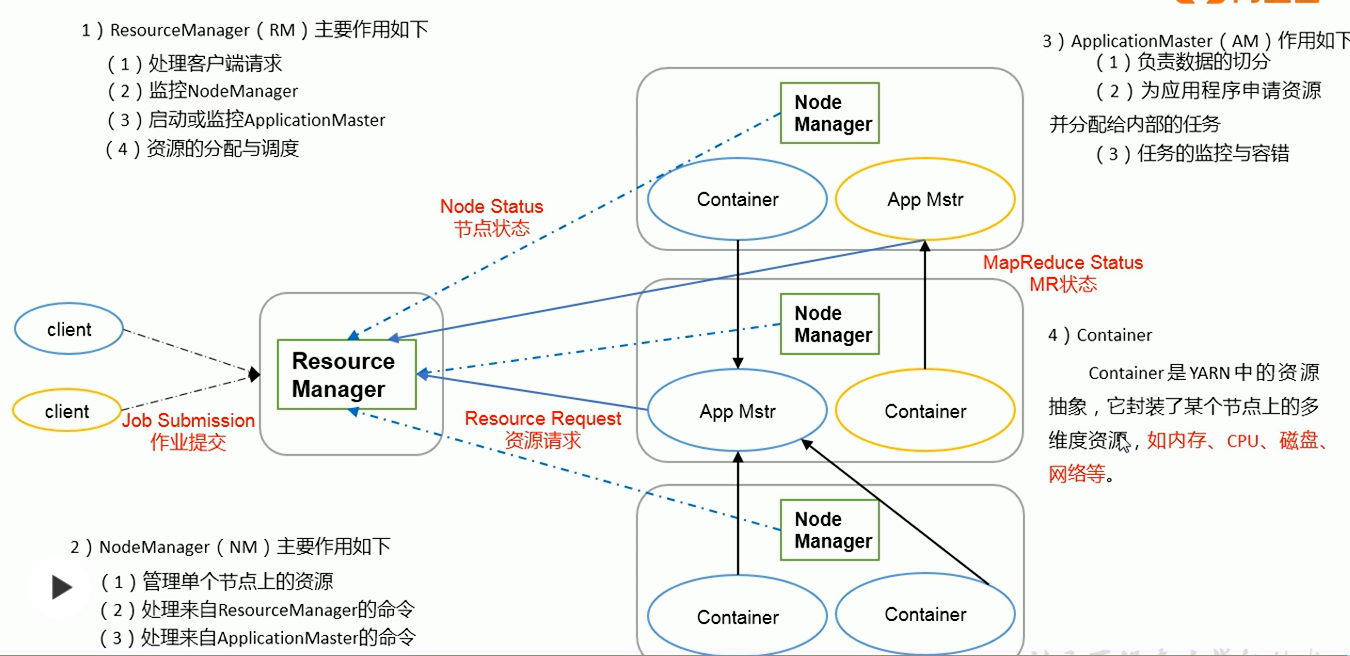
- ResourceManager:整个yarn集群资源管理
- NodeManager:单个节点资源管理
- ApplicationMaster:单个任务Job资源管理
- Container:资源抽象
工作机制
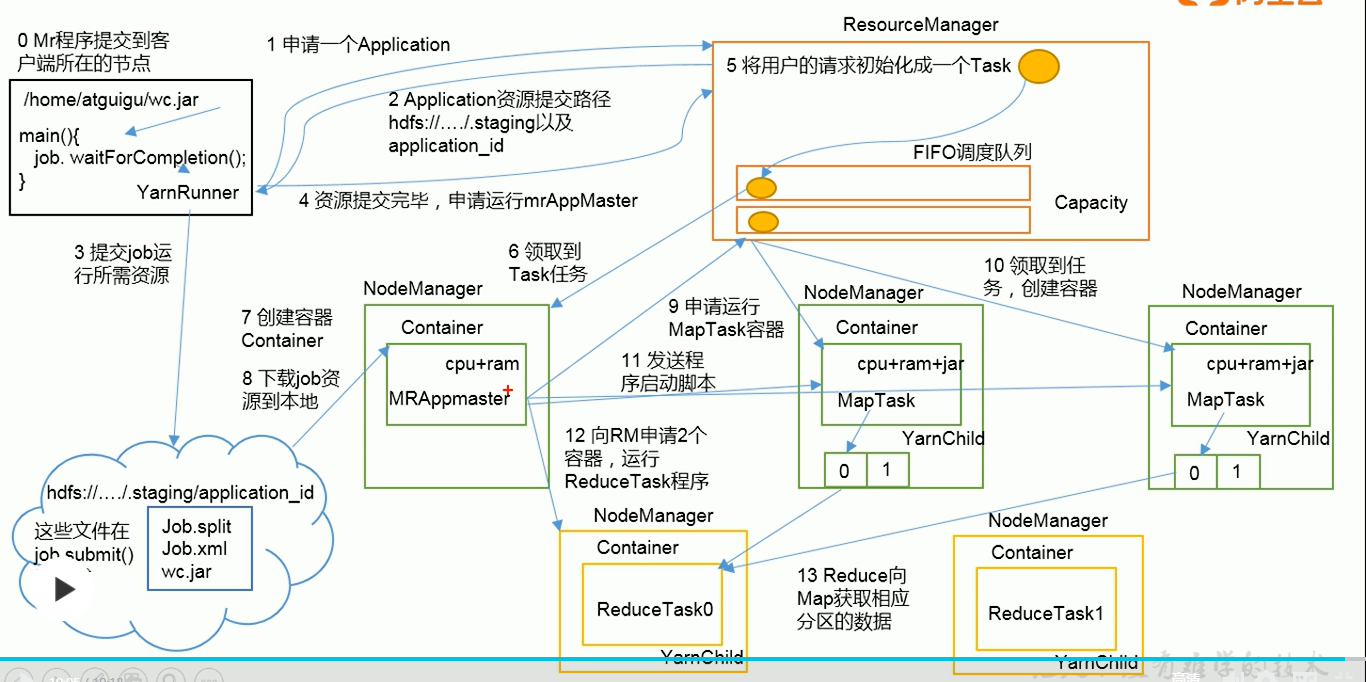
- 客户端编辑Job任务图生成Job所需信息以及运行资源容器(Yarnrunner)
- 资源容器向ResourceManager申请运行,一个Application
- ResourceManager给申请返回Application的资源提交路径以及一个任务application_id
- 客户端将生成的资源上传至返回的提交路径上
- 资源提交完毕,客户端yarnRunner向ResourceManager申请运行任务的mrAppMaster
- ResourceManager将申请生成一个Task任务并加入到任务队列
- 空闲NodeManager从resourceManager领取Task任务,并对资源进行抽象创建容器Container,同时将任务资源从下载至节点本地
- MrAppMaster根据任务资源生成多个MapTask,并将Task加入到ResourceManager任务队列
- 空闲NodeManager领取MapTask任务,创建资源Container容器,运行MapTask程序,读取文件生成分区数据缓冲至磁盘
- MrAppMaster判断MapTask运行完成,申请对应ReduceTask任务资源
- ReduceTask任务被NodeManager获取,创建Container资源抽象,运行ReduceTask
资源调度器
即任务放入队列中被拉取运行调度的容器;hadoop作业的调度器:
- FIFO:先进先出队列:一个队列,按照时间排序
- Capacity Scheduler:容量调度器
- 支持多个队列,每个队列配置一定资源量,每个队列为FIFO调度策略
- 为了防止同一个用户作业独占队列中资源,调度器会对同一个用户提交作业所占资源量进行限定
- 计算每个队列中正在运行任务数与其应该分得计算资源之间的比例,选择一个比值最小的队列(最闲的)
- 按照作业优先级和提交时间顺序,考虑用户资源量限制和内存限制对队列内任务排序
- Fair Scheduler:公平调度器,按照缺额排序,缺额大的优先
- 支持多队列用户,每个队列中资源量可配置,统一队列中作业公平共享队列中所有资源
- 每个队列中Job按照优先级排序,优先级高的分配资源多, 每个Job都会分配到资源以确保公平
- 资源有限下,每个Job理想情况计算资源与实际获得资源资源存在的差距称为缺额
- 同一队列中,Job缺额越大,越优先获得资源优先执行
yarm-default.xml
<property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value></property>
执行推测任务
执行推测任务的前提条件:
- 每个Task只能有一个备份任务
- Job已完成的Task必须不小于5%
- 推测执行参数配置开启(默认true开启)、
mapred-site.xml
<property><name>mapreduce.map.speculative</name><value>true</value></property><property><name>mapreduce.reduce.speculative</name><value>true</value></property>
不能启动执行推测机制:
- 任务间存在严重负载倾斜
-
推测执行算法原理
假设某一时刻,任务T执行进度为progress,通过一定算法推测出任务最终完成时刻estimateEndTime,另一方面,如果此刻为该任务启动一个备份任务,腿短可能完成时刻estimateEndTimeBack;于是:
运行总耗时:
运行完成时刻:
备份推测完成:
averageRunRime:其它已完成任务的平均运行时间 MR总是选择(estimateEndTimeBack - estimateEndTime)差值最大的任务
- 为了防止大量任务同时启动备份任务造成资源浪费,MR为每个作业设置了同时启动备份任务数目的上限
- 算法采用了以空间换时间的逻辑,启动多个相同任务处理相同数据,并让任务竞争以缩短数据处理时间

若有收获,就点个赞吧
0 人点赞
