Hadoop概述
Hadoop是进行数据存储以及数据计算的,具有高可用(副本)、高扩展(节点增加)、高等特性
组成(2.X版本)
- Common(辅助工具包)
- HDFS(数据存储)
- Yarn(资源调度)
-
HDFS架构
NameNode(nn):存储文件元数据(文件名,文件目录结构,文件属性(生成时间、副本数、文件权限))以及每个文件的块列表和块所在DataNode
- DataNode(dn):存储文件块数据,以及块数据的校验和
Secondary NameNode(2nn):监控HDFS状态的辅助后台程序,定时获取HDFS元数据快照
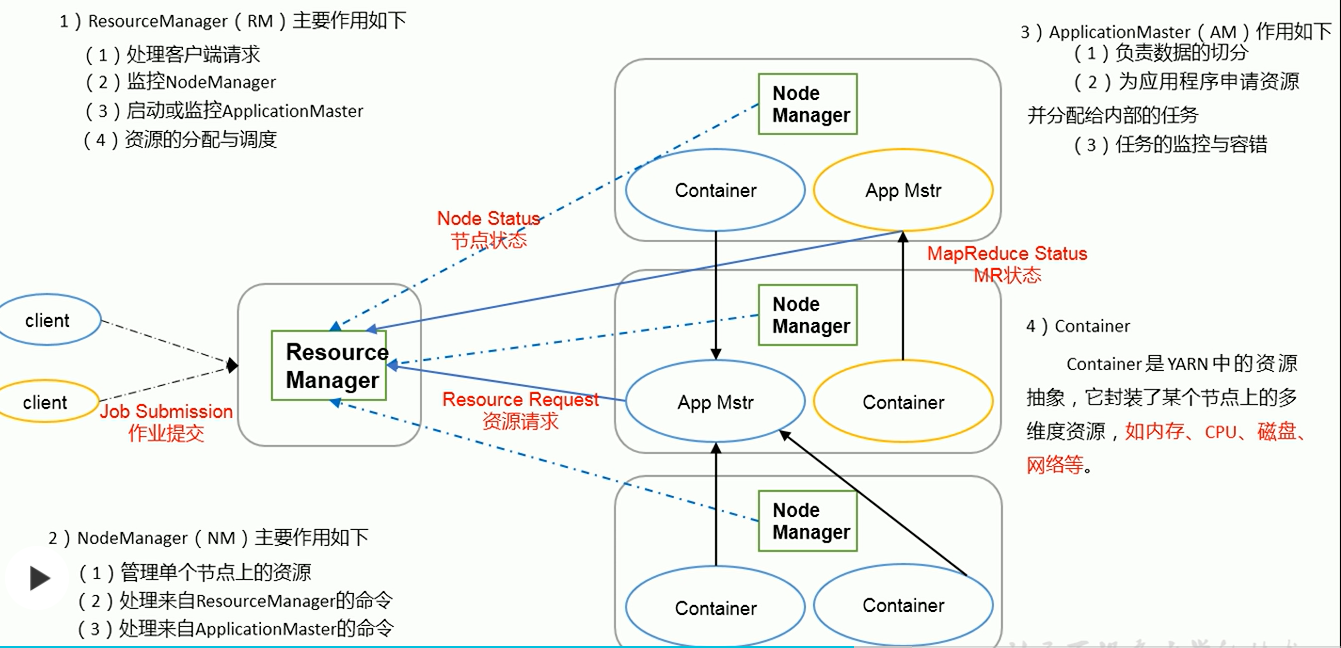
Yarn架构
MapReduce架构
Map:负责并行处理输入数据
- Reduce:负责汇总Map处理数据结果
hadoop伪分布式安装体验
JDK安装
- Oracle JDK 下载Linux版本的tar.gz文件压缩包 Oracle账号密码
- 上传至服务器(服务器联网可直接下载至服务器)
- 解压文件至指定目录
tar -zxvf jdk-8u202-linux-x64.tar.gz -C /opt/jdk 配置环境变量
# 编辑文本vim /etc/profile# 设置环境变量export JAVA_HOME=/opt/jdk/jdk1.8.0_202export CLASSPATH=${JAVA_HOME}/libexport PATH=$PATH:${JAVA_HOME}/bin!wq# 保证设置环境变量生效source /etc/profile
hadoop安装(伪分布式/单机)
下载hadoop版本 ,进入hadoop官网下载对应版本(本次为3.3.1版本);可以根据官网文档进行安装 hadoop3.3.1文档
hadoop解压文件,解压后可以设置HADOOP_HOME变量
修改hadoop-env.sh,打开文件并设置
**JAVA_HOME=/opt/jdk/jdk1.8.0_202**
- 进入解压文件夹,修改配置文件 (hadoop-env.sh, core-site.xml; yarn-env.sh, yarn-site.xml; mapred-env.sh, mapred-site.xml)
vim core-site.xml在文件中增加属性值,配置可以参考文档的core-default.xml文档,有配置值描述信息<property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property><property><name>hadoop.tmp.dir</name><value>/home/module/hadoop/tmp</value></property>
fs.defaultFS:namenode(nn)hdfs地址
hadoop.tmp.dir:hadoop文件路径地址,指定是防止默认值/tmp文件夹过小或重启数据消失
hdfs-site.xml
<property><name>dfs.replication</name><value>1</value></property>
dfs.replication:数据副本数量,伪分布式配置一个用于了解即可
- 启动namenode & datanode
# 此处不按照文档启动, 文档为分布式命令/sbin/hadoop-daemon.sh start namenode/sbin/hadoop-daemon.sh start datanode# 通过jps查看namenode和datanode进程是否存在 jps# 通过网页查看hadoop的web地址, 之前版本可能为50070http://ip:9870
yarn启动
- 修改yarn-env.sh,旧版本可能需要跟hadoop-env.sh一样设置JAVA_HOME,3.3.1版本不需要
- 修改mapred-env.sh ,旧版本可能需要跟hadoop-env.sh一样设置JAVA_HOME,3.3.1版本不需要
yarn-site.xml
```xml
- yarn.nodemanager.aux-services:指定节点数据交换方法,示例为mapreduce洗牌- yarn.nodemanager.env-whitelist:yarn的nodemanager环境表名单- yarn.resourcemanager.hostname:指定yarn的resourcemanager的节点<a name="la1AY"></a>##### mapred-site.xml```xml<property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.application.classpath</name><value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value></property>
- mapreduce.framework.name:指定mapreduce资源管理的形式,默认为local
- mapreduce.application.classpath:应用的类路径
- 启动yarn以及mapreduce
/sbin/yarn-daemon.sh start resourcemanager/sbin/yarn-daemon.sh start nodeemanager- 打开web网页ip:8088可以查看yarn管理的应用界面
- 测试:
./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /user/test.xml /user/out- /user/test.xml以及/user/out均为hdfs上路径
历史服务器配置(2.7.2,3.3.1版本配置可能不同)
mapred-site.xml增加配置
启动命令:<property><name>mapreduce.jobhistory.address</name><value>192.168.233.128:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>192.168.233.128:19888</value></property>
/sbin/mr-jobhistory-daemon.sh start historyserver
测试:点击yarn的web页面上显示的mapreduce任务的History即可查看到任务运行历史配置日志聚集
yarn-site.xml增加配置
WARN 配置日志聚集功能需要先停止nn,dn,rm,nm,jobhistoryserver等服务,配置完成后重新启动<property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 日至保留时间秒 --><property><name>yarn.log-aggregation-retain-seconds</name><value>604800</value></property>
安装服务使用端口统计
- /user/test.xml以及/user/out均为hdfs上路径
- 9078(50070):hadoop的web服务页面
- 8088:yarn的web页面
- proxy(19088):mapreduce的history统计界面
hadoop分布式安装
分布式安装与伪分布式安装只是配置文件以及启动命令的差异:
- 分布式安装应该注意集群的namenode,secondarynamenode, resourcemanager尽量分布在不同服务器上,因为这些服务占用内存较多,建议不要在一个服务器上挤占资源
在hdfs-site.xml中增加secondarynamenode的配置
<property><name>dfs.namenode.secondary.http-address</name><value>ip:50090</value></property>
启动命令和停止命令:start/stop-dfs.sh,start/stop-yarn.sh,注意服务器之间配置免密登录以及集群时间同步

若有收获,就点个赞吧
0 人点赞
