博客HW,LEO,AR,ISR
https://blog.csdn.net/u013289115/article/details/106349384
1. 为什么要用消息队列
常见使用场景:
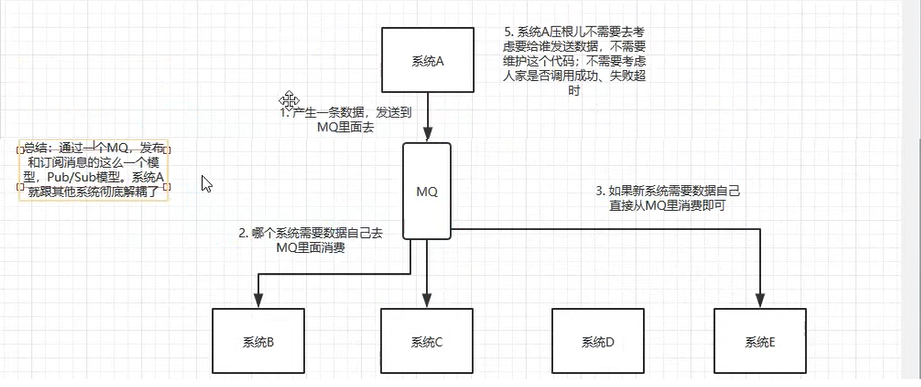
解耦,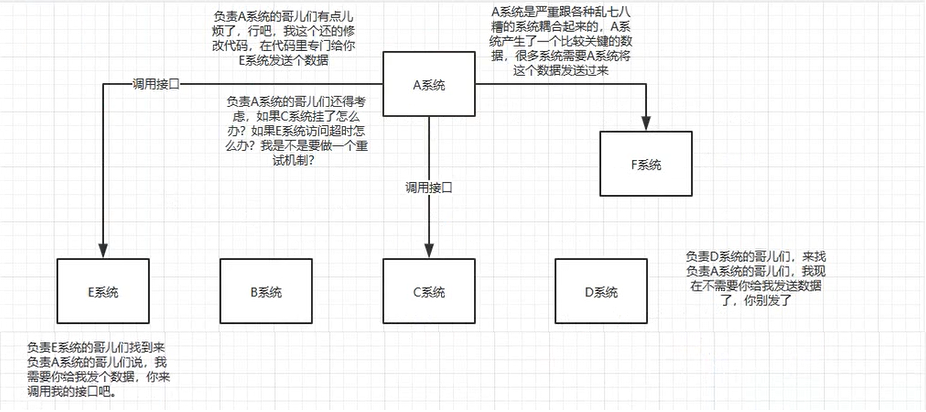
异步,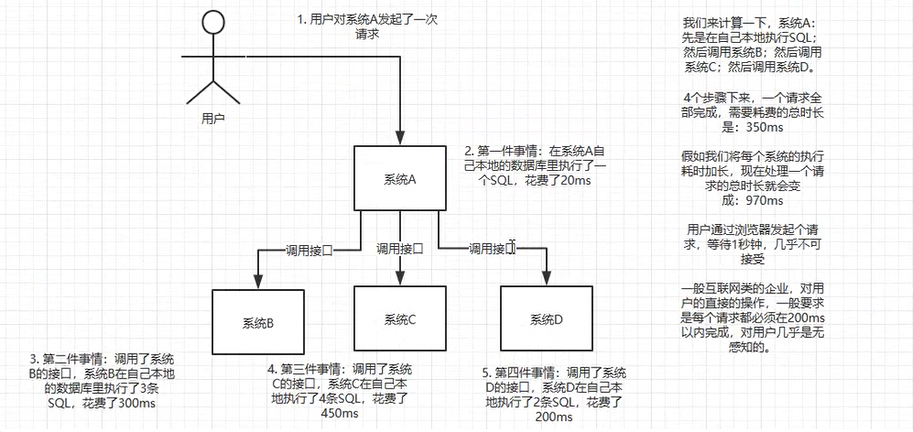
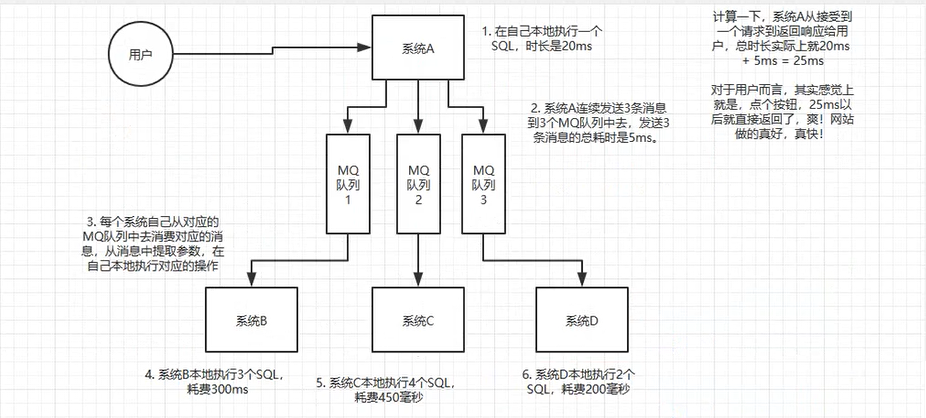
消峰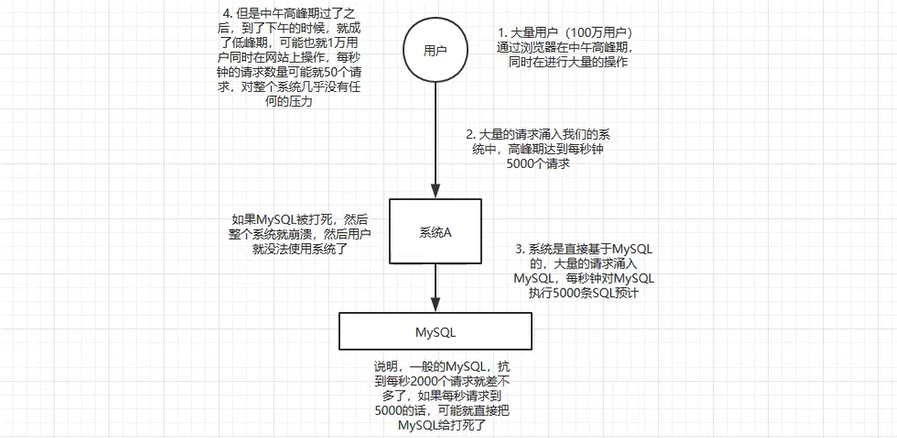
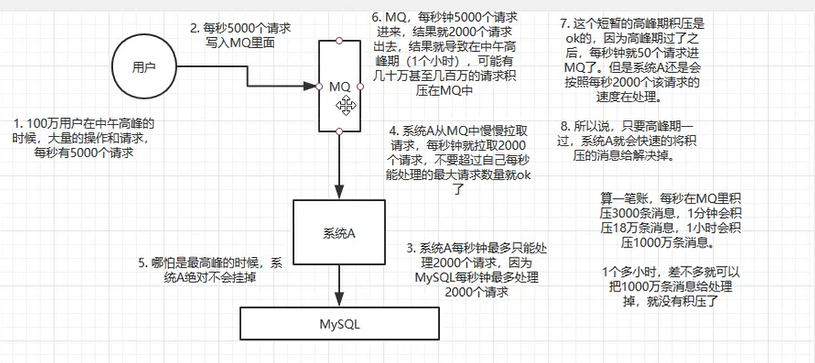
在导入白名单中用到了消息队列1.做了异步接口,因为导入白名单之后有其他对白名单的操作,异步可以提高系统响应时间2.多家行社可能同时批量导入白名单数据量较大,2000的并发mysql就可能崩溃,所以采取使用MQ来进行消峰(消息先保存在MQ中然后再消费)
2. 使用MQ的缺点?
- 系统可能性降低 : 系统引入MQ,如果MQ挂掉,整个系统会不崩溃
- 系统复杂性提高 : 如何保证系统没有重复消费?怎么处理消息丢失?怎么保证消息传递顺序
- 一致性问题 : 例如,A系统产生消息直接返回成功,BCD系统消费,BC系统写库成功,D系统写库失败导致数据不一致
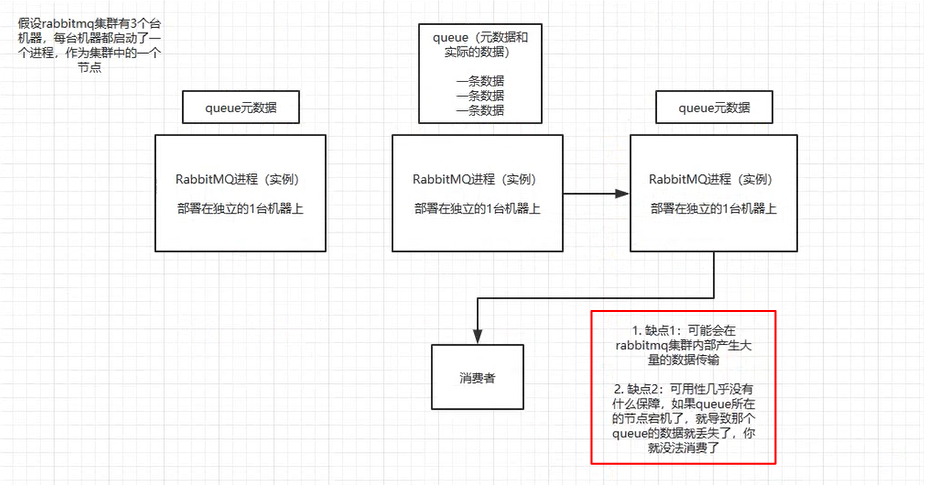
- rabbit镜像集群模式

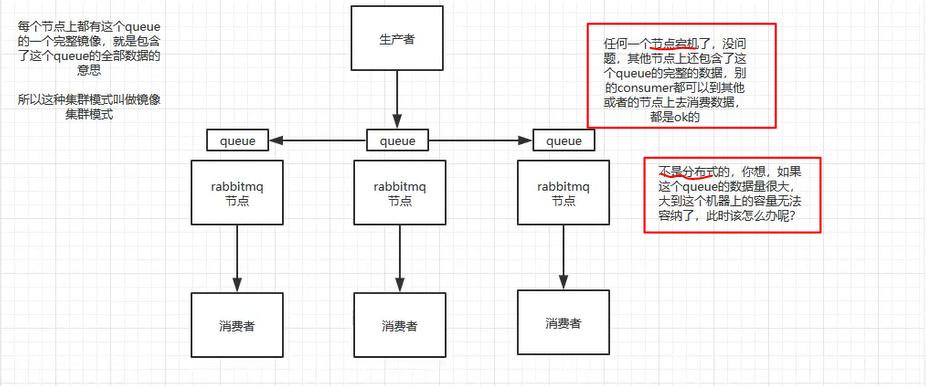
- kafka的高可用

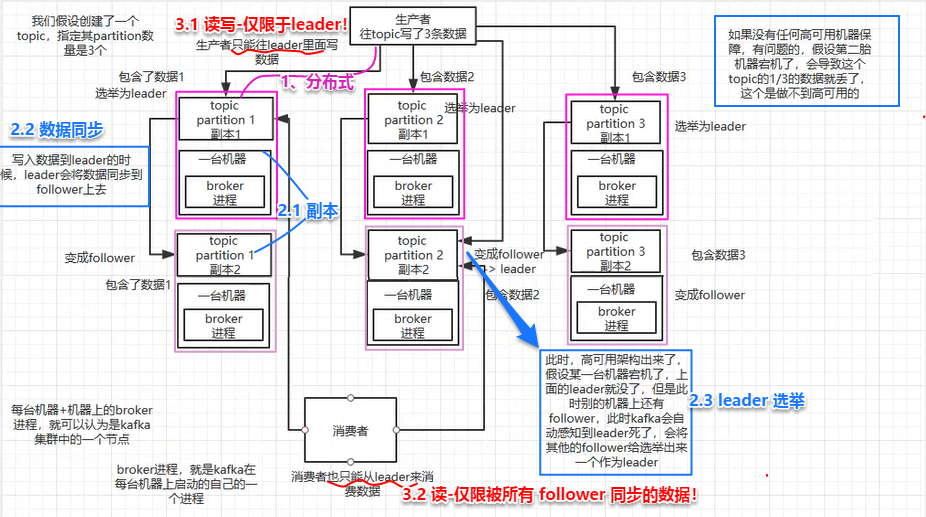
读写操作:只能对 leader 进行读写!其他 follower 主动从 leader 处 pull 数据(保证一致性)写,一个消息只能等所有的 follower 都同步成功,都成功返回 ack 给 leader ,才会返回写成功的消息给生产者!读,一个消息只能等所有的 follower 都同步成功,都成功返回 ack 给 leader ,才能被读取!
4. 如何保证消息不被重复消费?(如何保证消息的幂等性?)
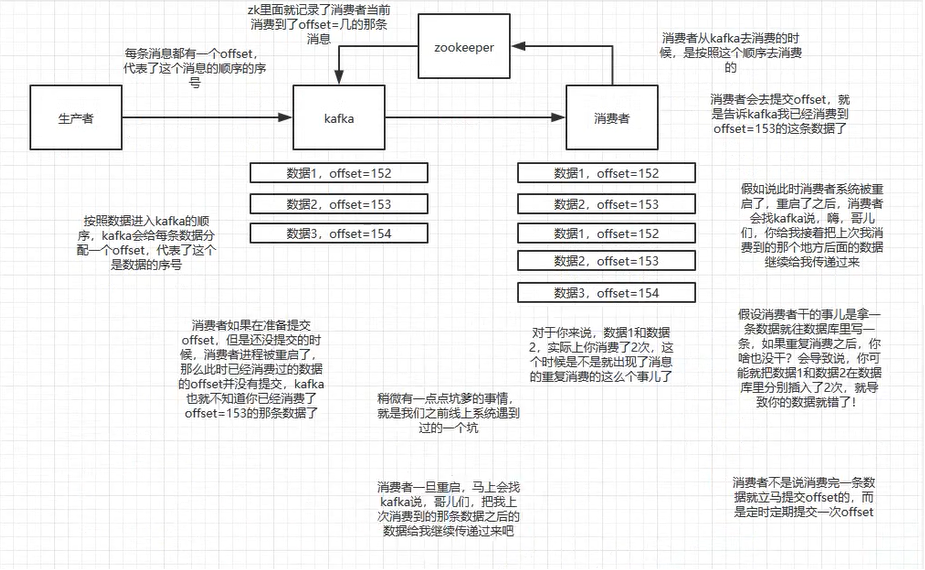

参考博客:https://cloud.tencent.com/developer/article/1664494
5. 如何保证消息的可靠性传输?(如何处理消息丢失的问题?)

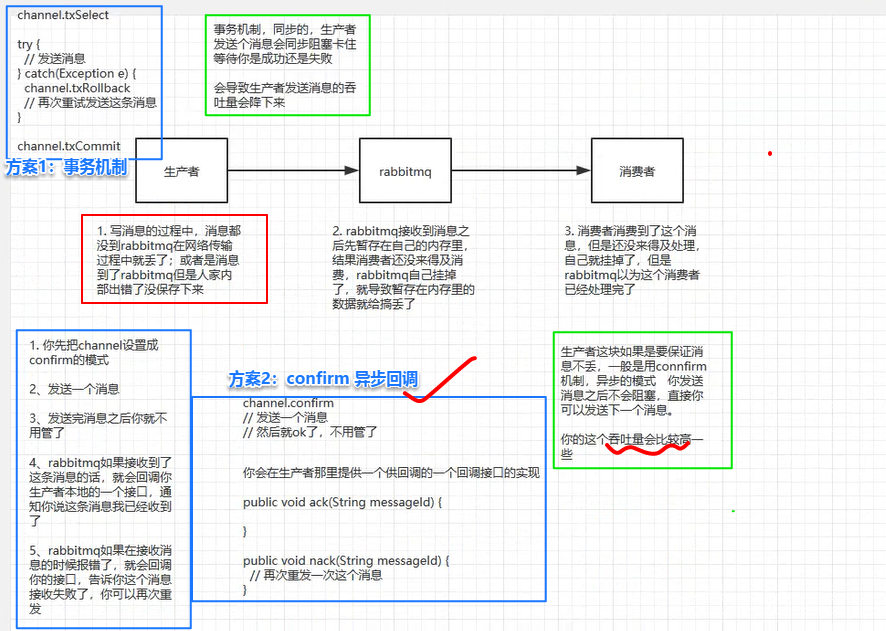
rabbitMQ数据丢失问题和解决方案
kafka可能存在数据丢失和解决方案

- 消费者丢失数据
- 场景 : kafka的消费者有一个offsize的概念(可以当做消息的序号),如果消费者自动提交offsize,kafka就会认为消息消息已经被消费了,其实消息刚准备处理,这时消费者挂了,消息就丢失了
- 解放方案 : 设置auto.commit.enable=false,每次处理完手动提交。确保消息真的被消费并处理完成。
- kafka自己丢失数据
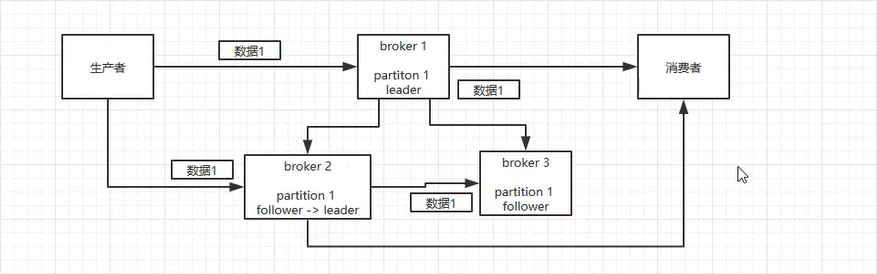
- 解决方案 : 设置参数
- 主题的副本数 replication-factor
- 最少同步副本数 min.insync.replias
- 生产者丢失数据
- 如果按照上述思路设置ack=all,一定不会丢,要求是,你的leader接收到消息,所以的follower都同步到了消息之后,才认定为本次写成功。如果没满足这个条件,生产者会自动不断的重试,重试无限次。
参数参考
min.insync.replias&ack=all
6. 如何完全保证消息顺序性

1. RabbitMQ可能存在顺序错乱问题
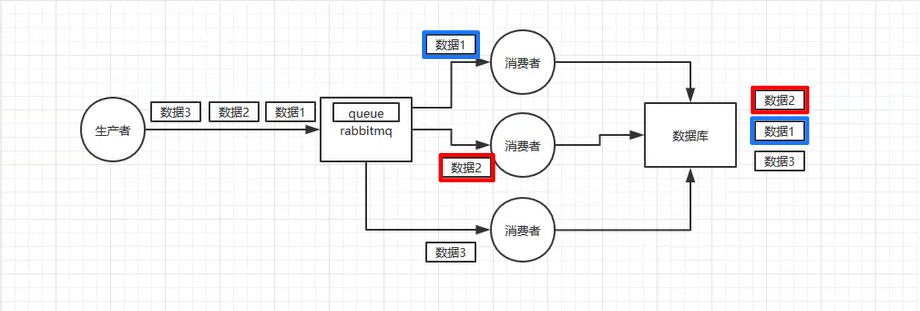
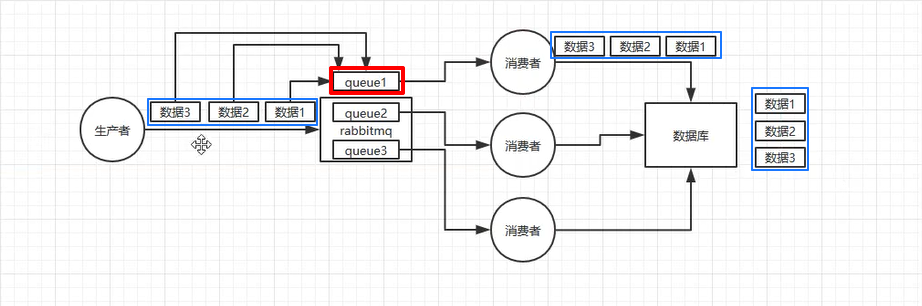
2. RabbitMQ 如何完全保证消息顺序性
1、 kafka 可能存在的顺序错乱的问题
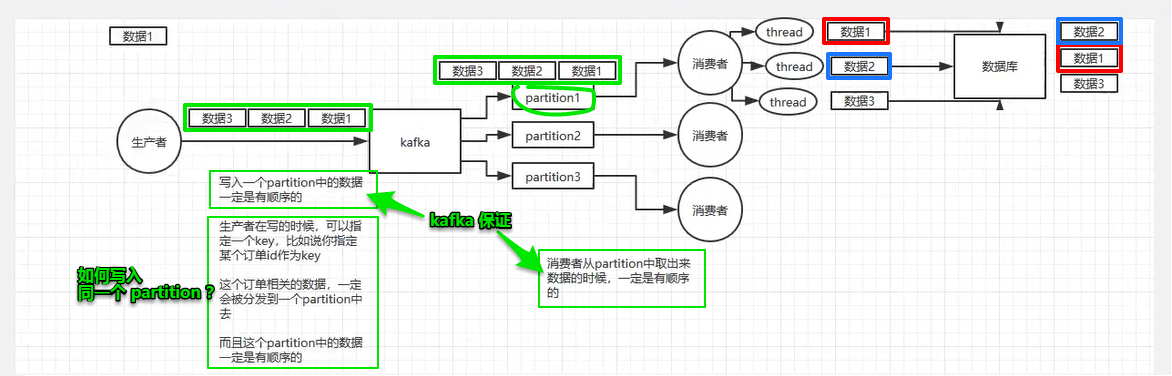
2、 kafka 如何完全保证消息顺序性
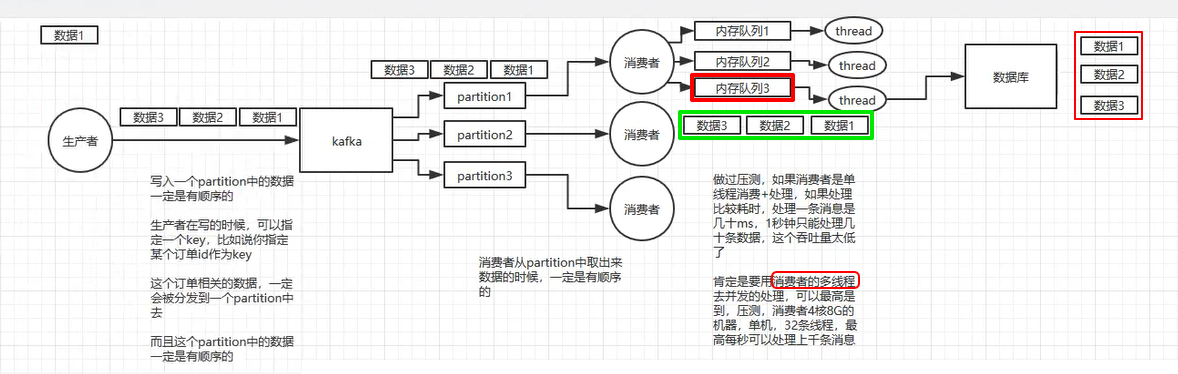
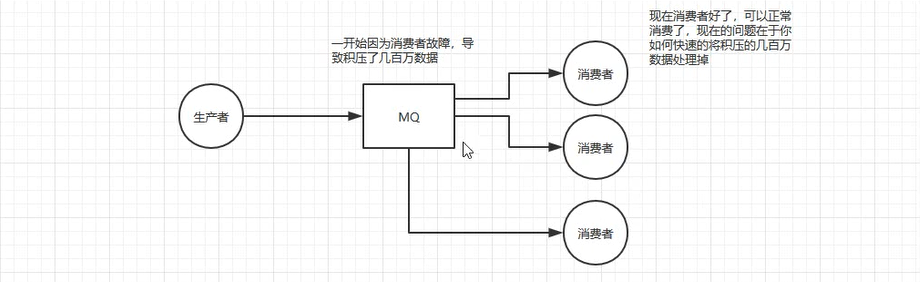
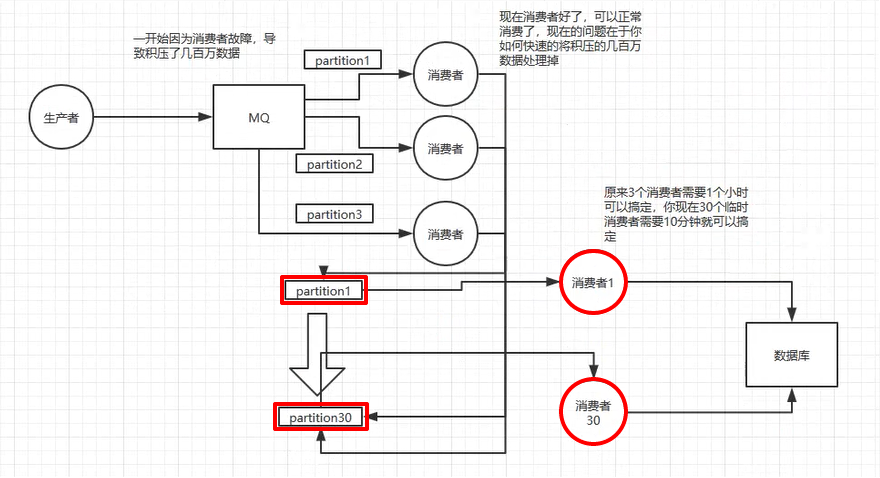
7. 几百万消息在消息队列里积压了几个小时!

快速处理积压的消息
- 解决方案:临时紧急扩容
2、设置了过期清理 -> 数据丢失 -> 如何恢复?
8. 如果让你写一个消息队列,该如何进行架构设计啊?说一下你的思路。


若有收获,就点个赞吧
0 人点赞
