- 目录
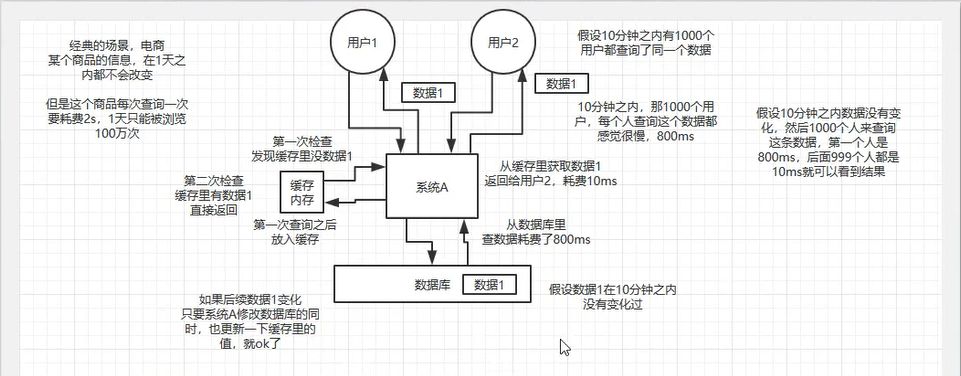
- 1. 缓存是如何实现高性能的
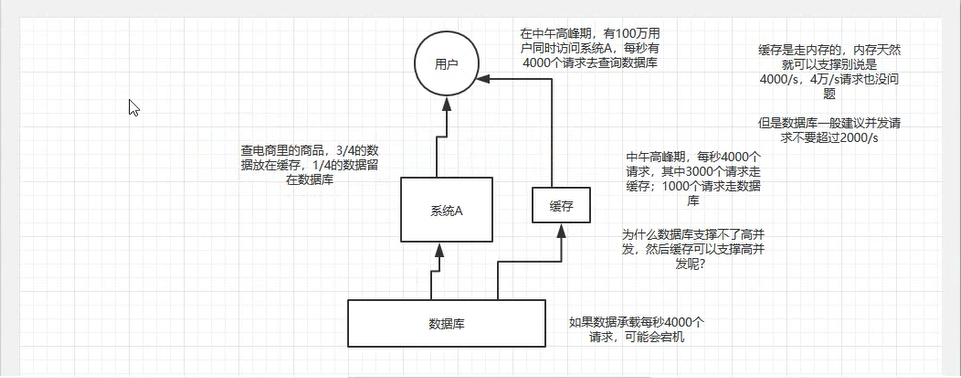
- 2. 缓存是如何实现高并发的
- 3. 常见缓存问题
- 4.
redis 和 memcached 有什么区别(redis工作原理,为什么redis是单线程的但是还可以支持高并发) - 5. redis 的单线程模型
- 6. redis都有哪些数据类型?分别在哪些场景下使用比较合适(基础)
- 7. redis 的过期策略有哪些?内存淘汰机制都有哪些?手写一下 LRU 代码实现?
- Redis 有哪几种数据淘汰策略?
- 8. 怎么保证redis是高并发以及高可用的?
- 哨兵的多个底层原理(包括slave选举算法)
- redis高并发,高可用总结
- redis持久化(类高可用)
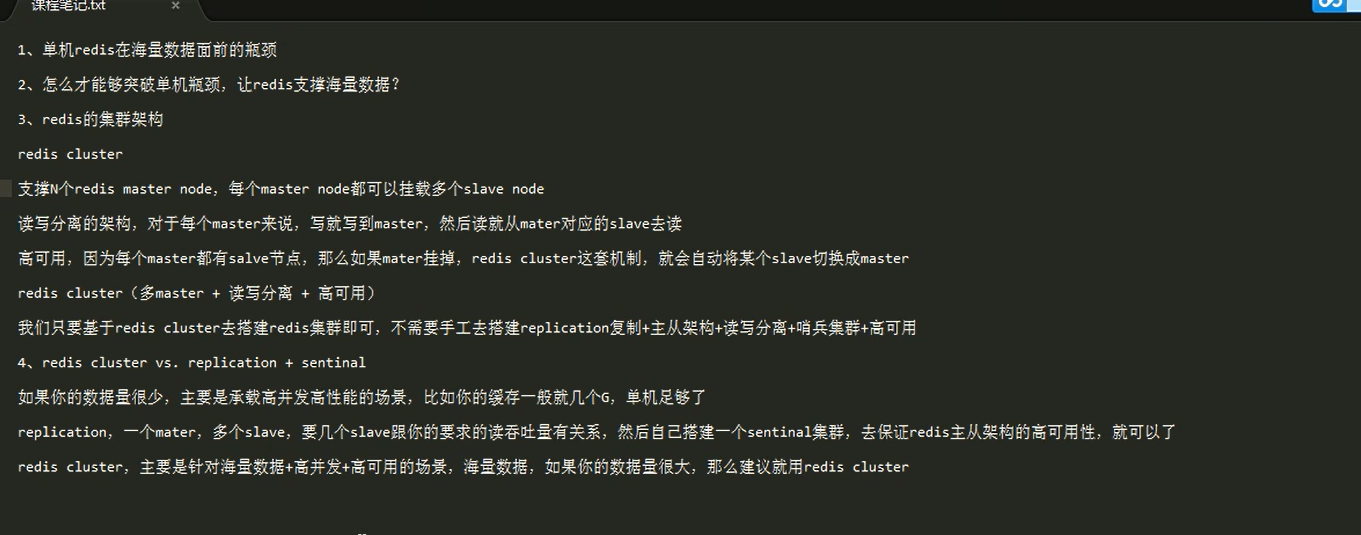
- redis集群(cluster)模式 【未学习,有需要再学】
- redis缓存雪崩和缓存穿透
- 缓存雪崩
- 缓存穿透
- 解决redis缓存击穿问题
- 方案一、定时任务主动刷新缓存设计
- 方案二、使用redis的分布式锁
- jvm的锁查询缓存">方案三、普通加jvm的锁查询缓存
- 方案四、jvm缓存+redis缓存的多级缓存
- 如何保证缓存和数据库的双写一致
- redis并发竞争问题
- 生产环境redis的部署
目录


1. 缓存是如何实现高性能的
2. 缓存是如何实现高并发的
3. 常见缓存问题
- 缓存与数据库双写不一致
- 缓存雪崩
- 缓存穿透
- 缓存并发竞争
4.redis 和 memcached 有什么区别(redis工作原理,为什么redis是单线程的但是还可以支持高并发)

5. redis 的单线程模型

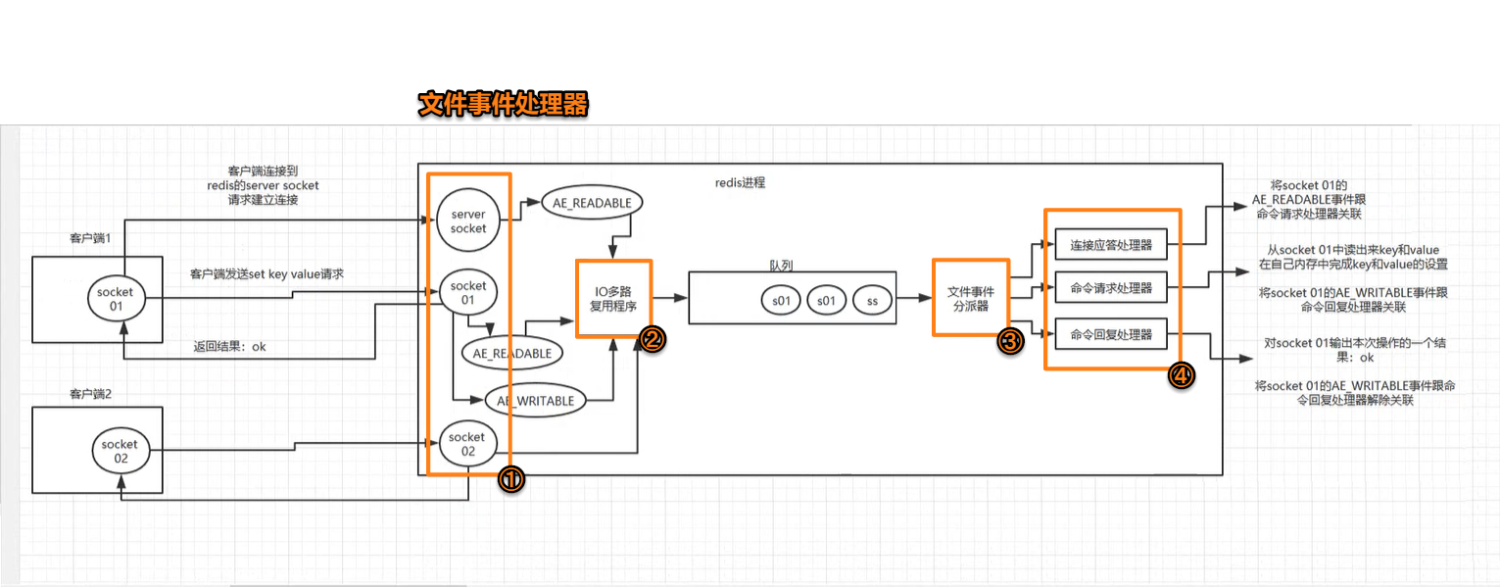
单线程为什么还支持高并发 : 左侧非阻塞IO多路复用监听socket不做事件处理,只把事件压到队列中,右侧文件分派器基于内存(微秒级)快速处理事件
6. redis都有哪些数据类型?分别在哪些场景下使用比较合适(基础)

7. redis 的过期策略有哪些?内存淘汰机制都有哪些?手写一下 LRU 代码实现?


Redis 有哪几种数据淘汰策略?
1.noeviction:返回错误当内存限制达到,并且客户端尝试执行会让更多内存被使用的命令。
2.allkeys-lru: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
3.volatile-lru: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存
放。
4.allkeys-random: 回收随机的键使得新添加的数据有空间存放。
5.volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
6.volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间
存放
8. 怎么保证redis是高并发以及高可用的?

8.1 redis 如何通过读写分离来承载读请求 QPS 超过10万+?(高并发)
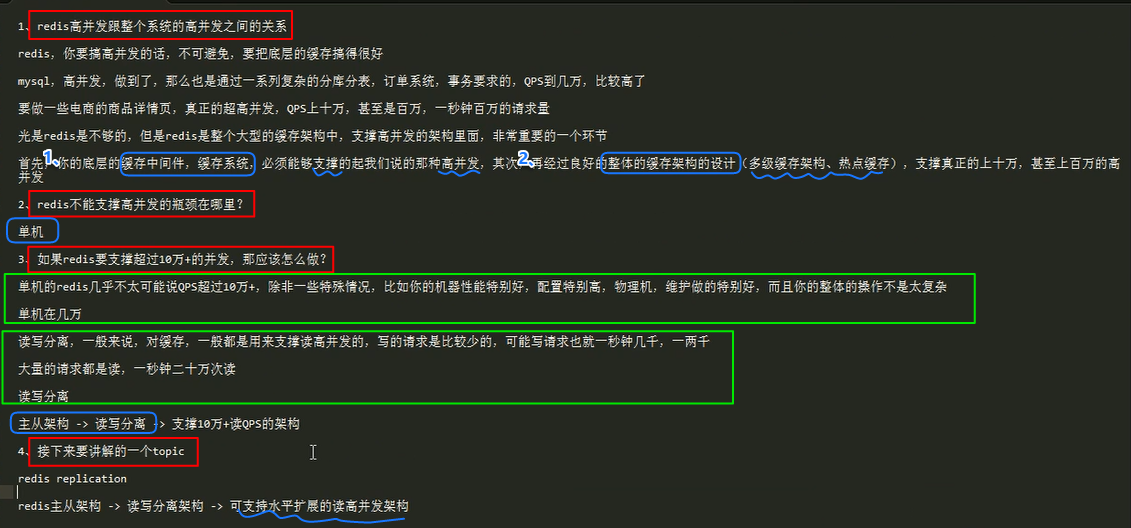
redis单机的瓶颈
单机redis,能够承载的QPS大概就在上万到几万不等,
所以单机redis,10万+的请求,redis就被打死了,系统不能支持高并发就卡死在redis单机这个问题上
解决方案 : redis 读写分离
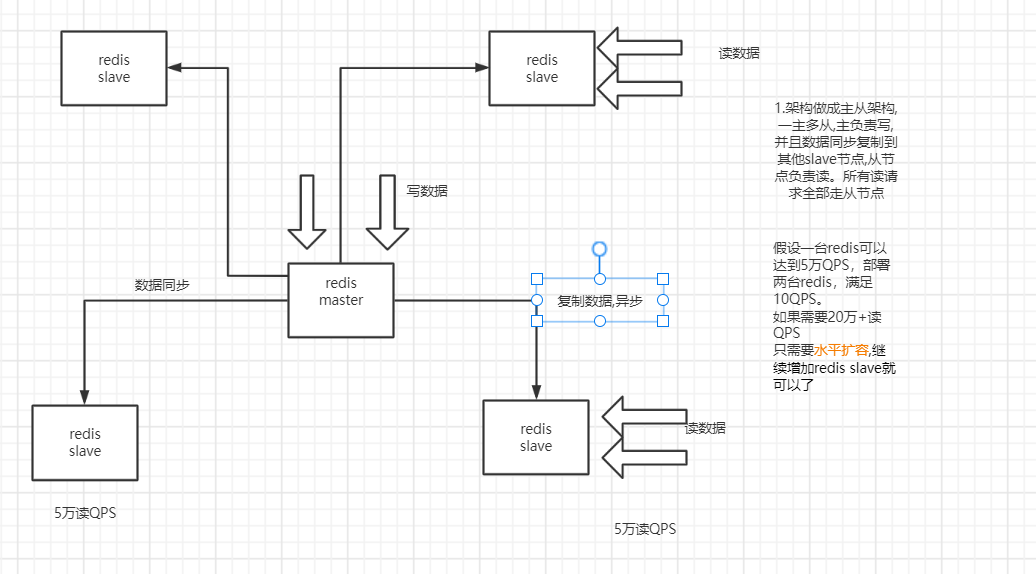
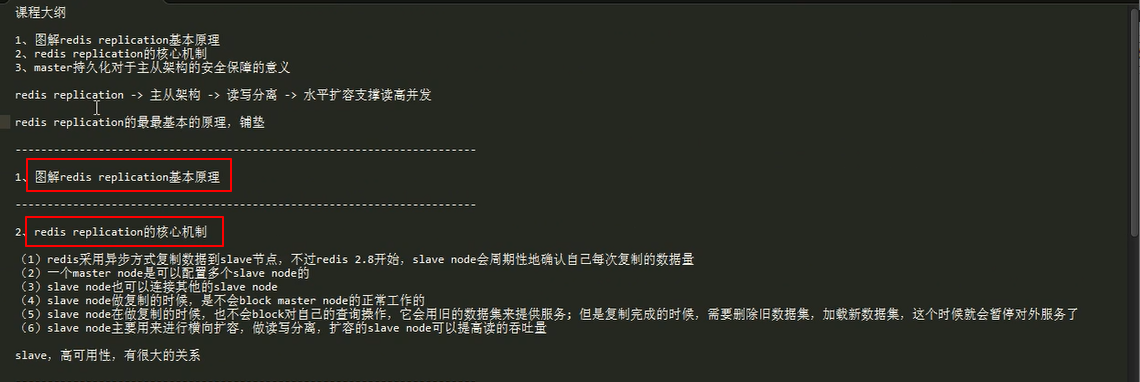
8.2 redis replication 以及 master 持久化对主从架构的安全意义
8.3 redis主从复制原理
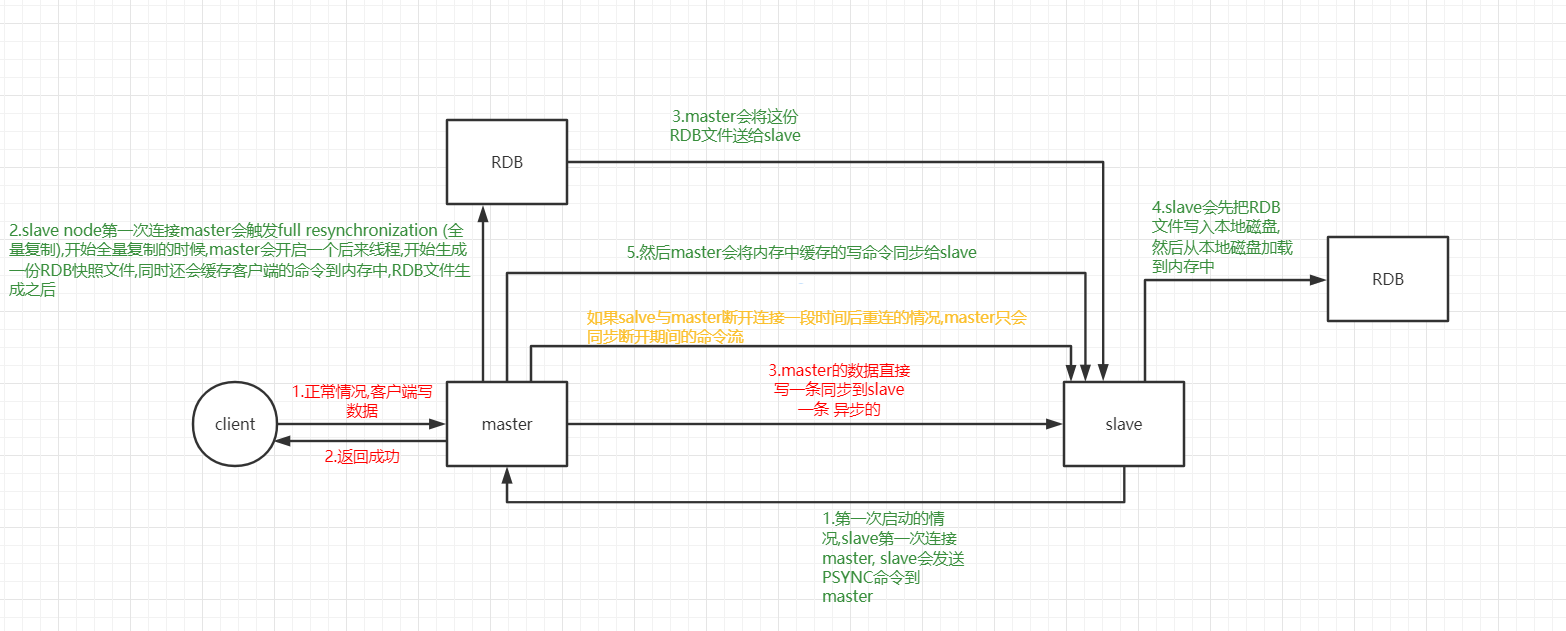
主从完整流程https://www.bilibili.com/video/BV1gE411M7cs?p=41&spm_id_from=pageDriver
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下:
- 从服务器连接主服务器,发送SYNC命令;
- 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
- 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
8.4 redis基于哨兵的高可用
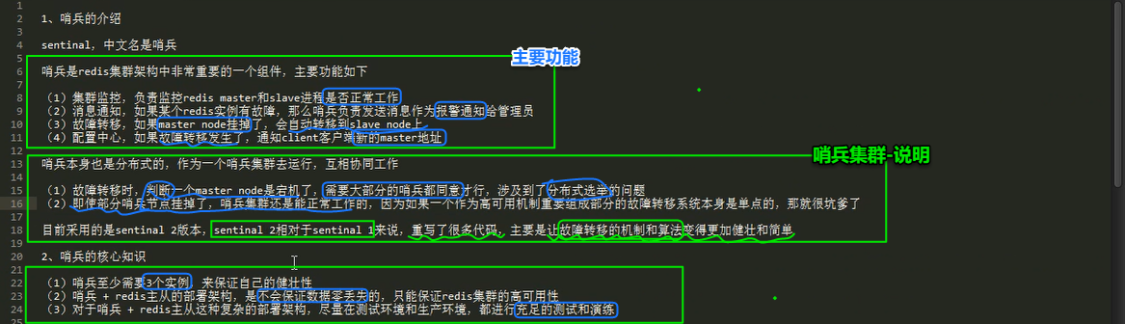

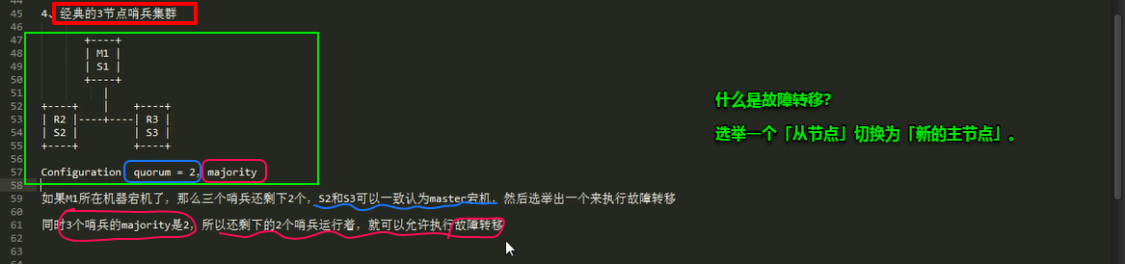
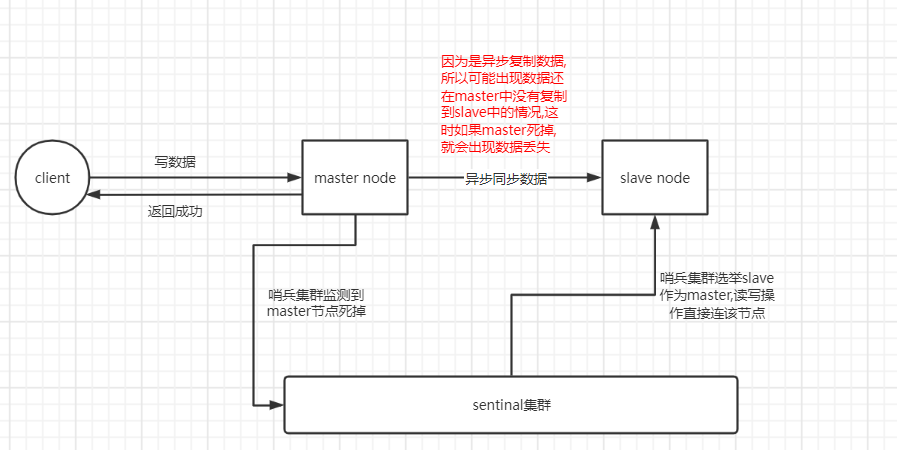
8.5 redis 哨兵主备切换的数据丢失问题:异步复制、集群脑裂
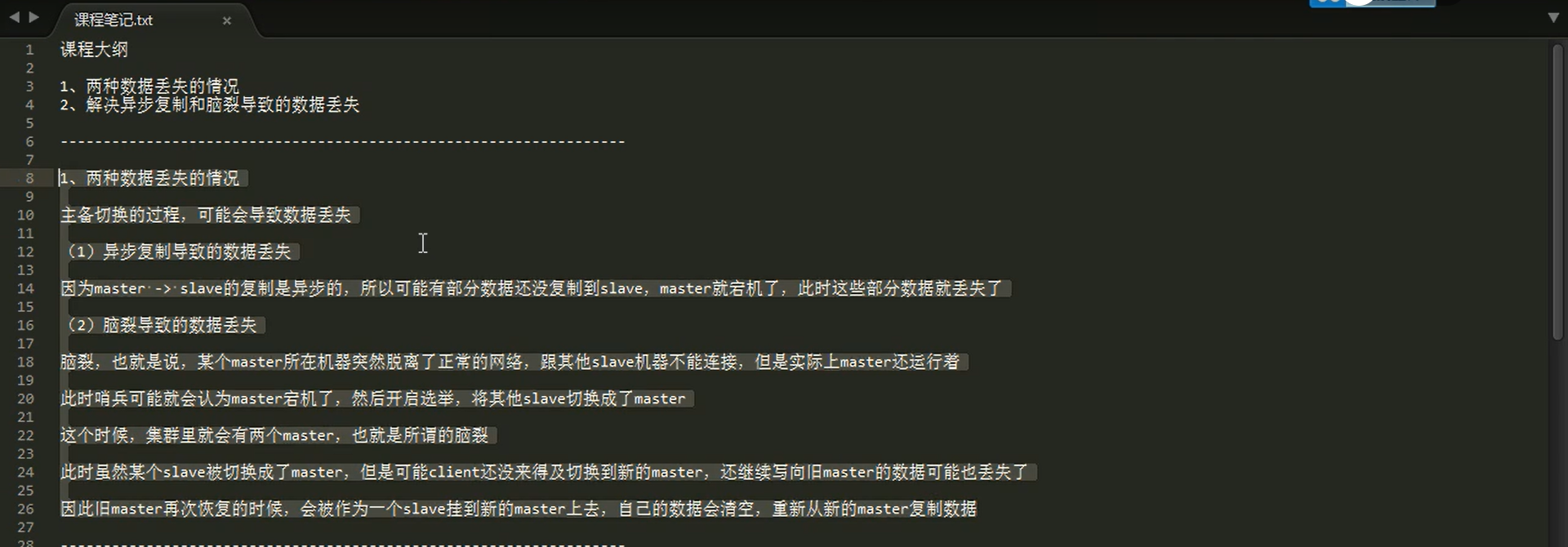
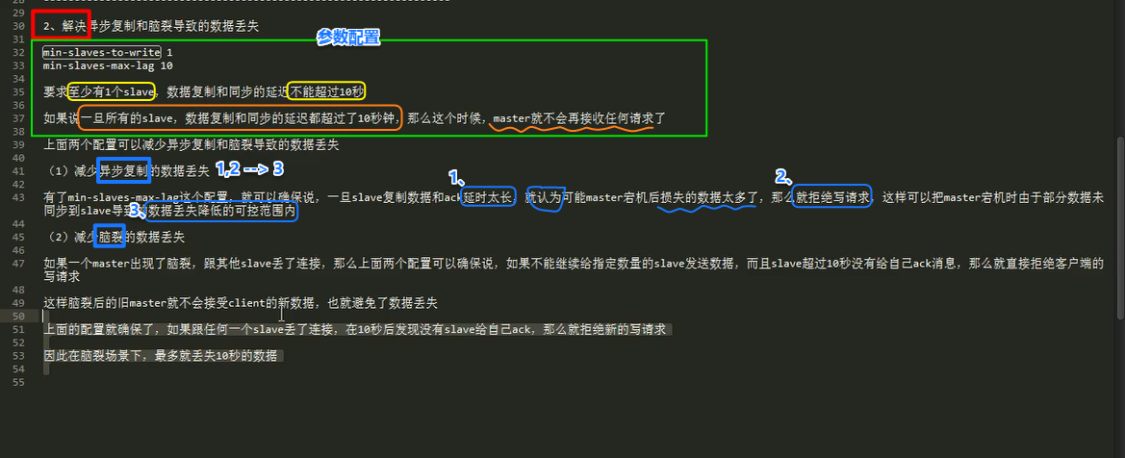
(1)异步复制导致数据丢失
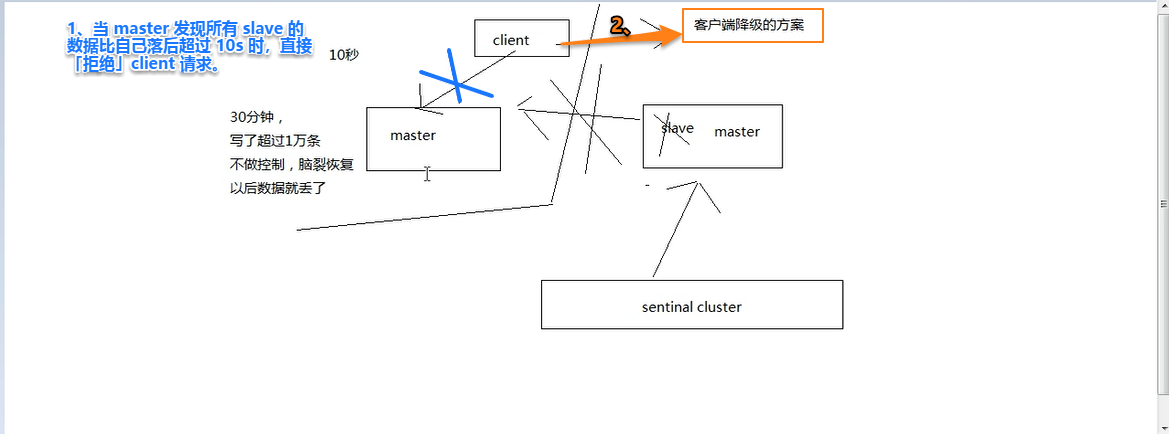
解决方案
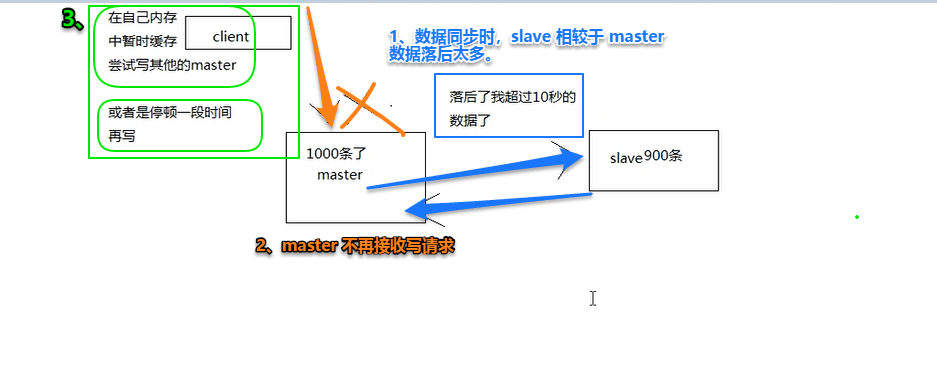
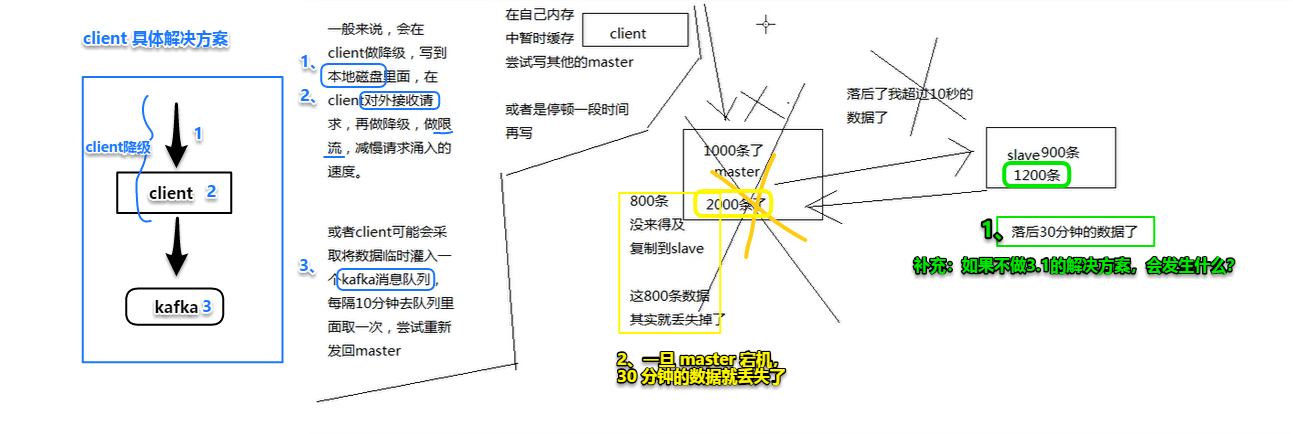
(2)集群脑裂导致数据丢失
2.1 什么是集群脑裂?
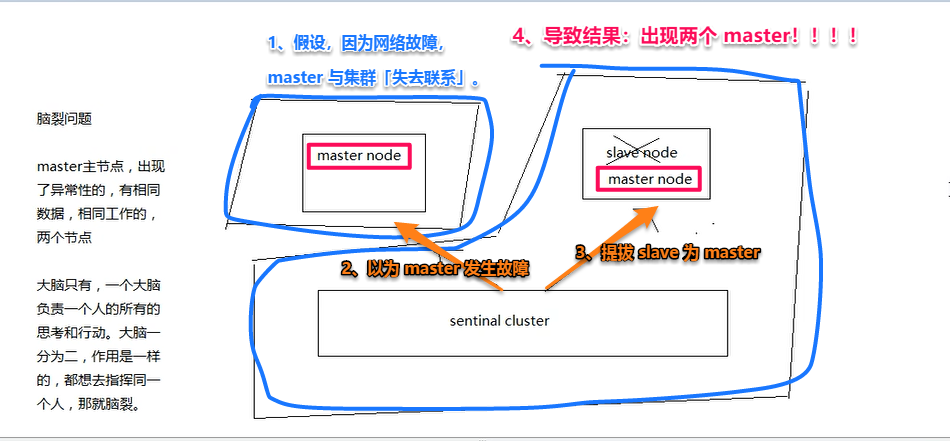
2.2 集群脑裂会导致什么问题?
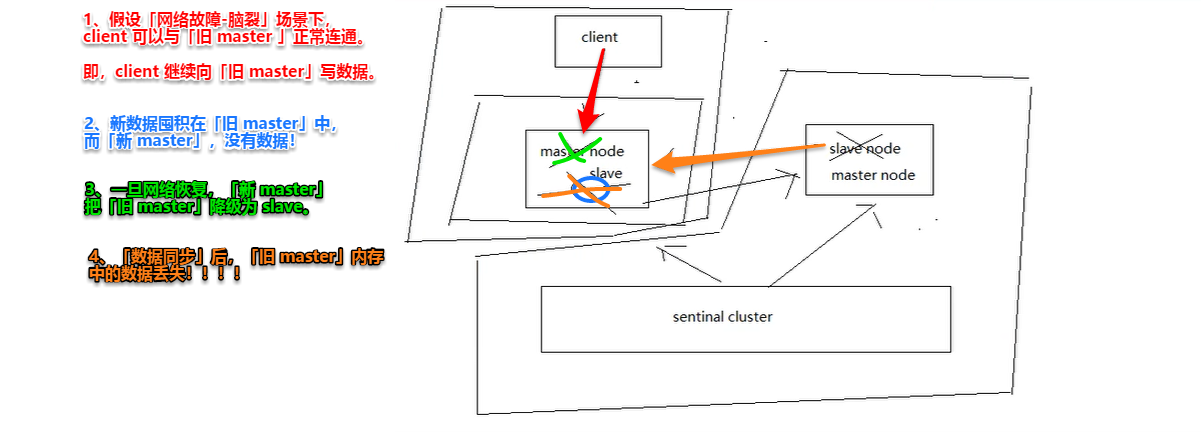
解决方案
哨兵的多个底层原理(包括slave选举算法)



redis高并发,高可用总结

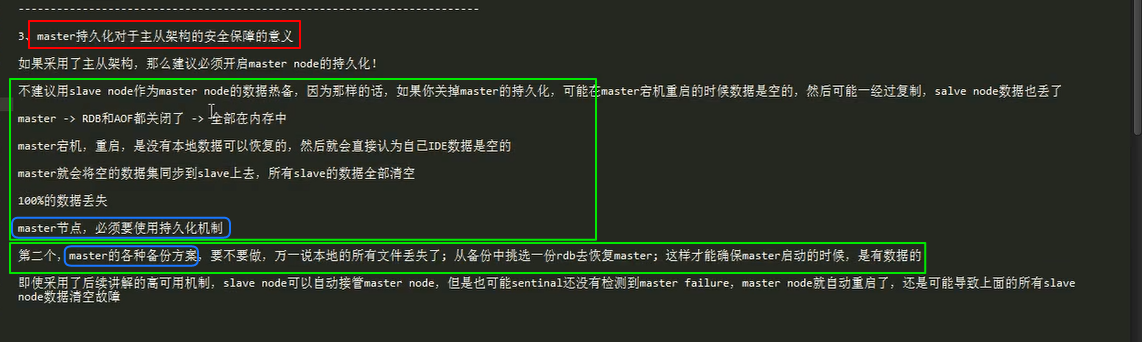
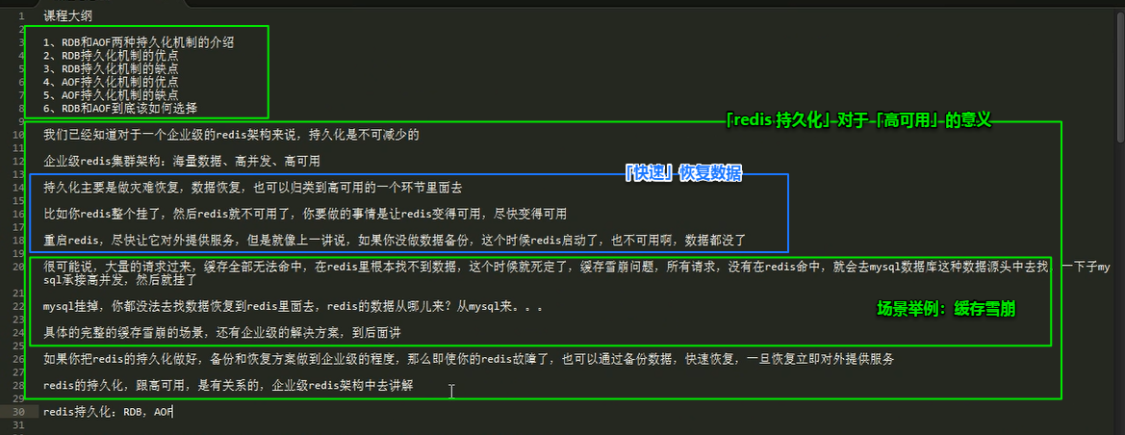
redis持久化(类高可用)

redis 持久化机制对于生产环境中的灾难恢复的意义
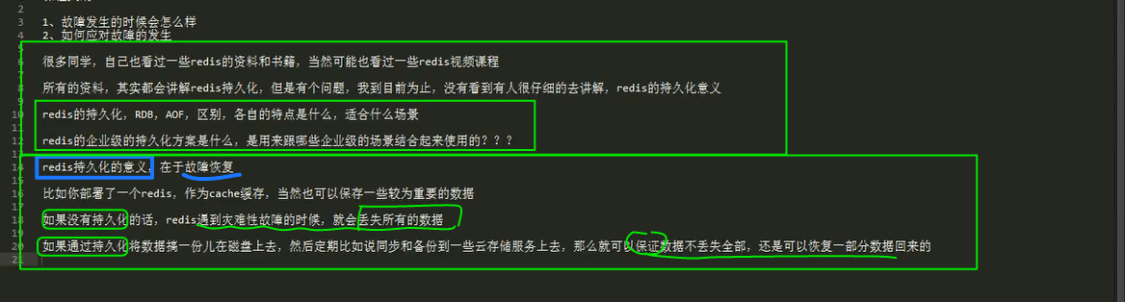
解决方案: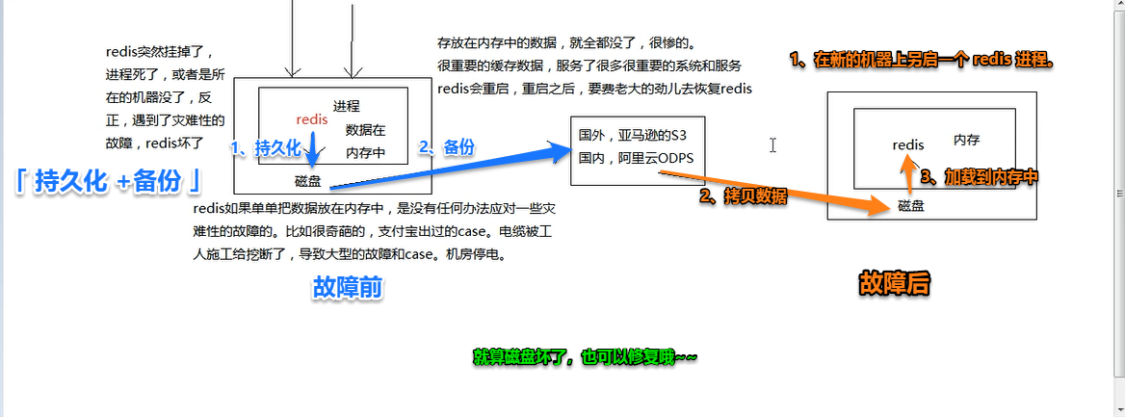
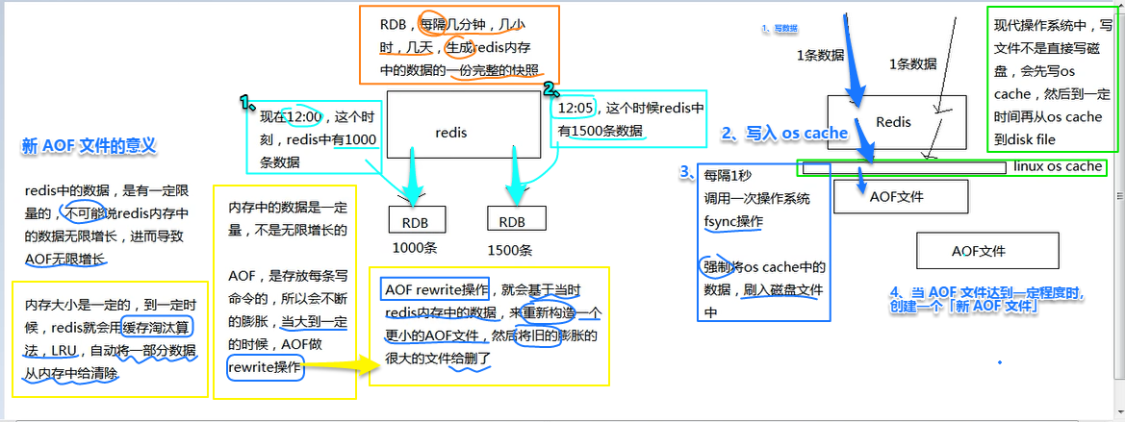
redis 的 RDB 和 AOF 两种持久化机制的工作原理
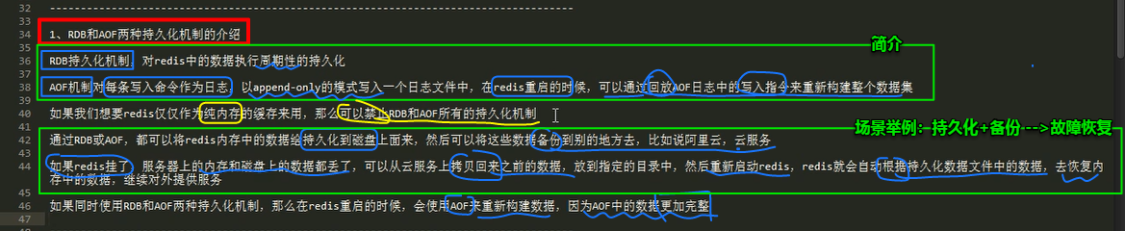
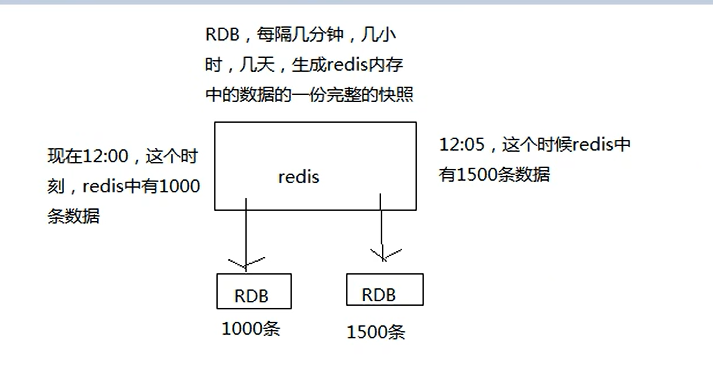
RDB
AOF rewrite 原理剖析
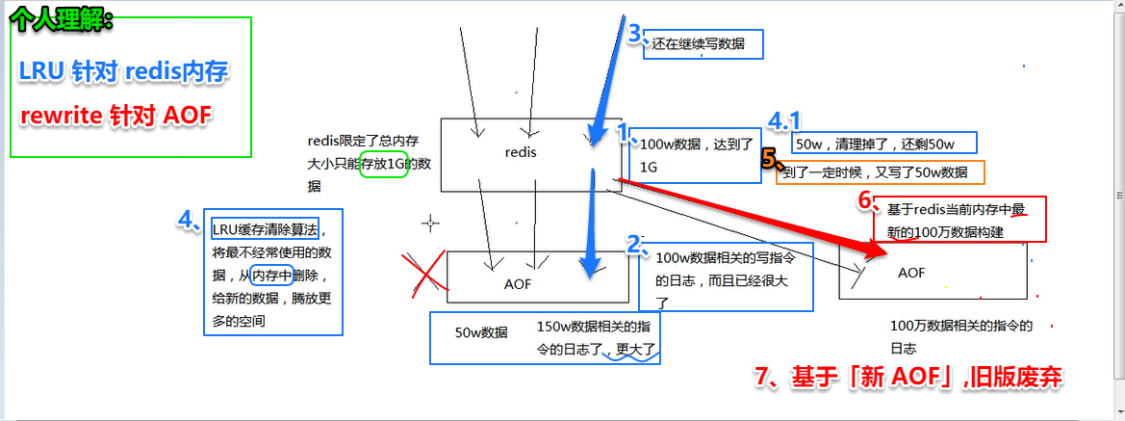
redis 的 RDB 和 AOF 两种持久化机制的优劣势对比
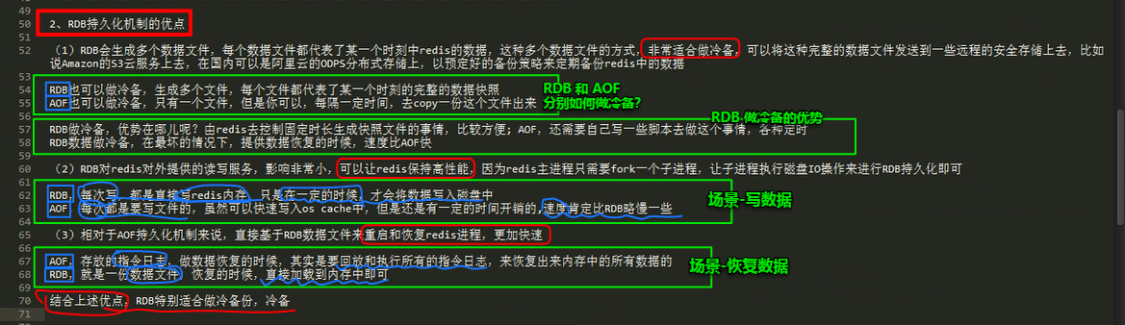

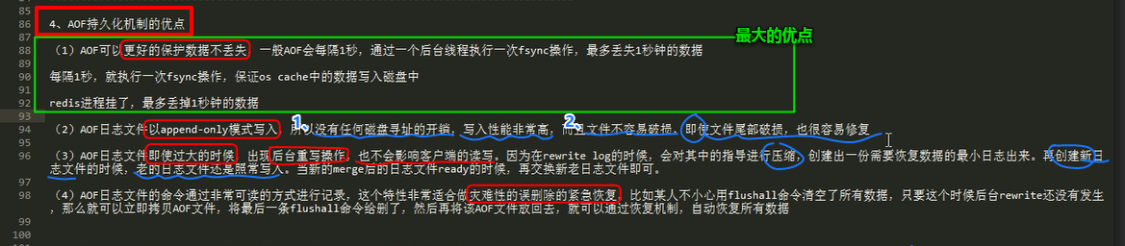
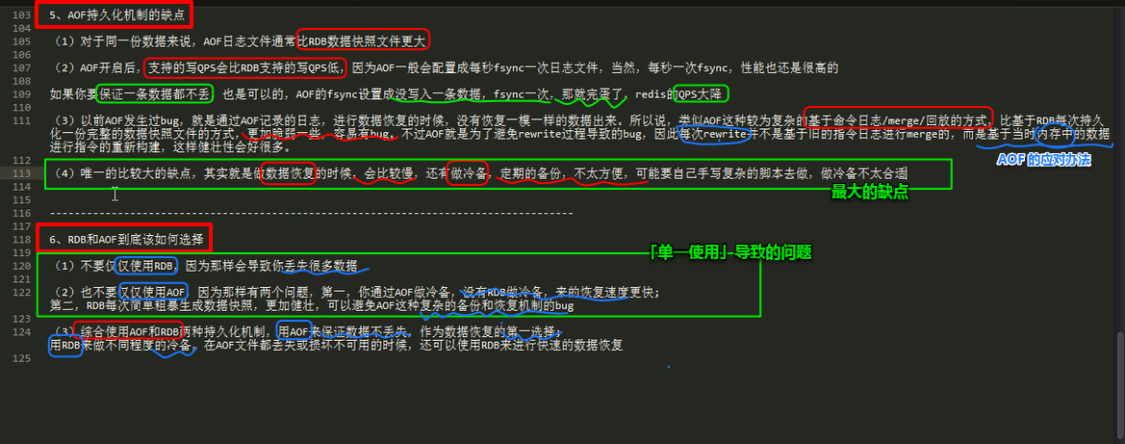
RDB 丢失数据的问题
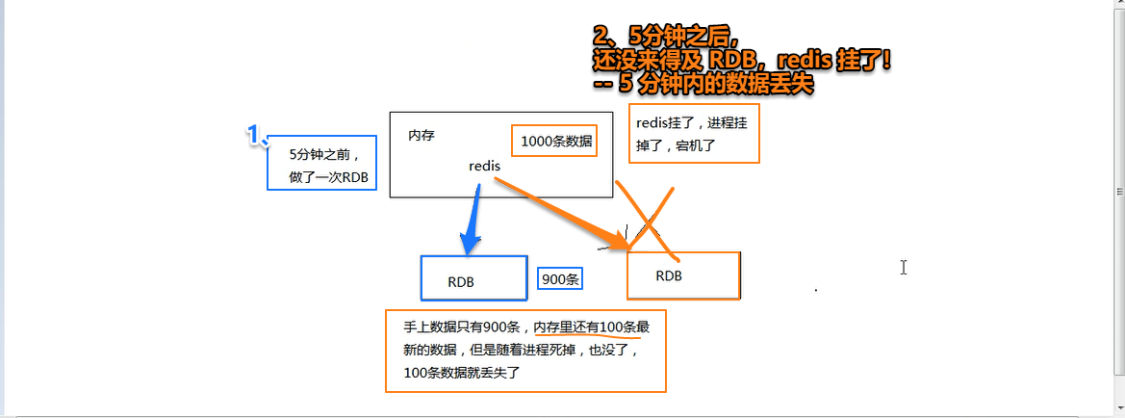
redis集群(cluster)模式 【未学习,有需要再学】

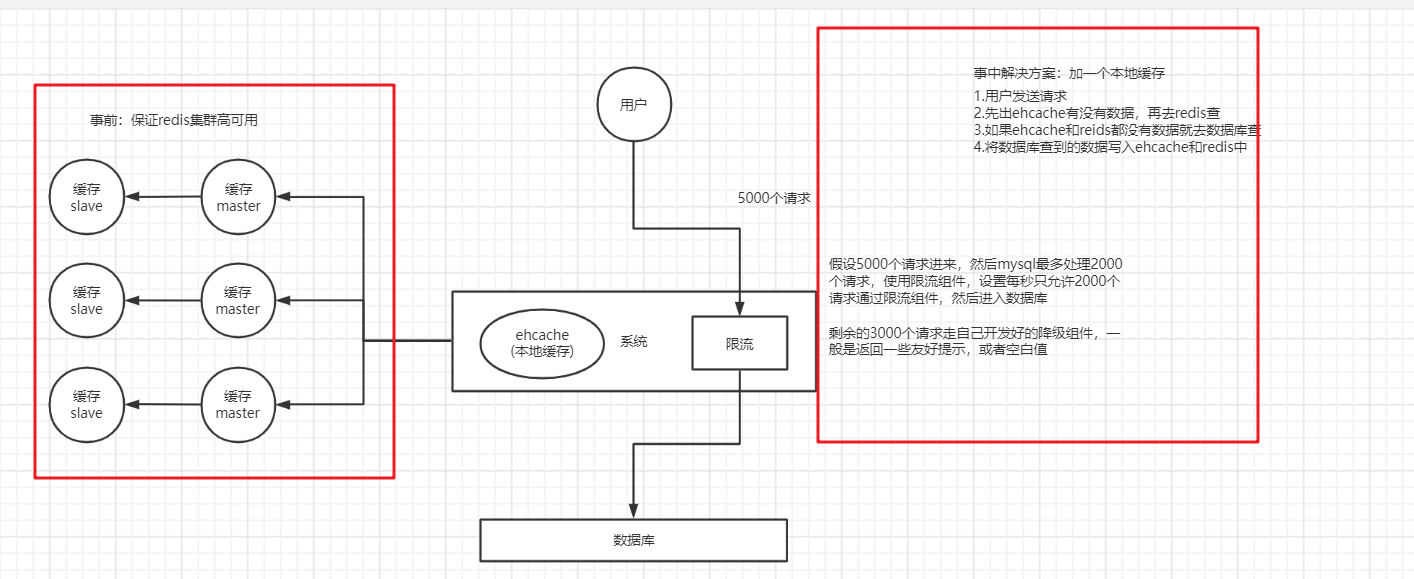
redis缓存雪崩和缓存穿透
缓存雪崩
场景:缓存挂掉(或大量缓存失效),大量数据直接打在数据库上,将数据库打死,重启数据库仍然会被大量请求打死,就造成了缓存雪崩
解决方案:
- 事前:redis高可用,要不然是主从+哨兵,要不然用redis cluster保证redis的高可用
- 事中:本地缓存ehcache+hystrix限流&降级,避免mysql被打死
- 事后:redis持久化,尽快恢复缓存集群,一旦重启自动从磁盘上加载数据,恢复内存中的数据
缓存穿透
场景:多个请求redis中没有数据,数据库中也没有数据,多次请求,导致redis不能帮助数据库分担请求压力,可能将数据库打死
解决方案:数据库中没有查到的数据,就set一个unknown到redis中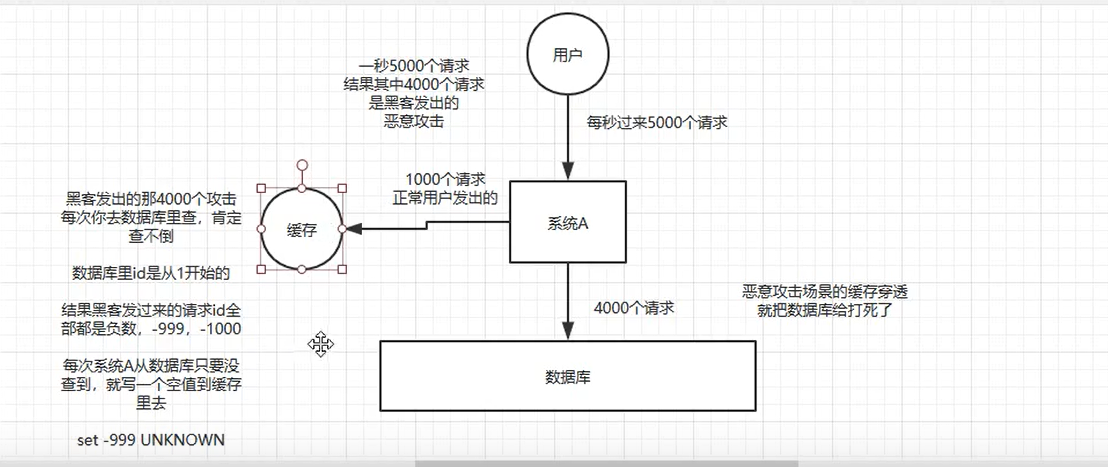
解决redis缓存击穿问题
缓存击穿:数据库的压力瞬时增大,且redis中并无大量的key过期,redis正常运行的情况下,数据库奔溃了。(他跟缓存穿透的区别是缓存穿透是因为没有key导致的数据库奔溃,而缓存击穿是因为热门key过期的时候该key被大量访问导致数据库奔溃。)
方案一、定时任务主动刷新缓存设计
方案二、使用redis的分布式锁
方案三、普通加jvm的锁查询缓存
方案四、jvm缓存+redis缓存的多级缓存
如何保证缓存和数据库的双写一致


读写并发的时候数据库+缓存双写不一致场景

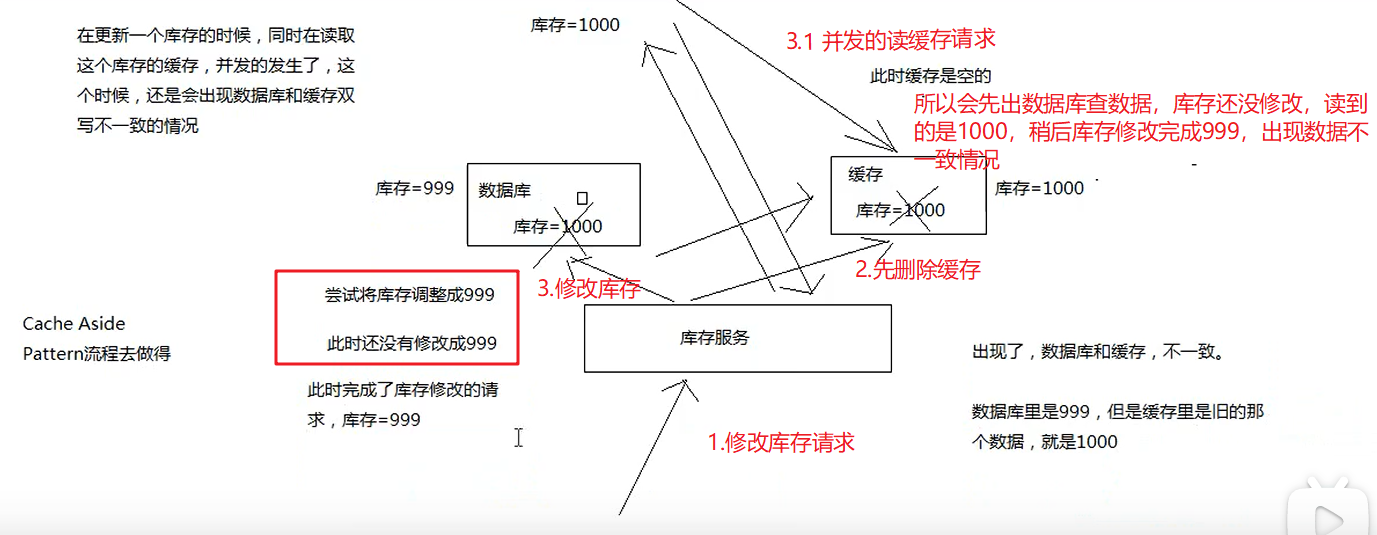

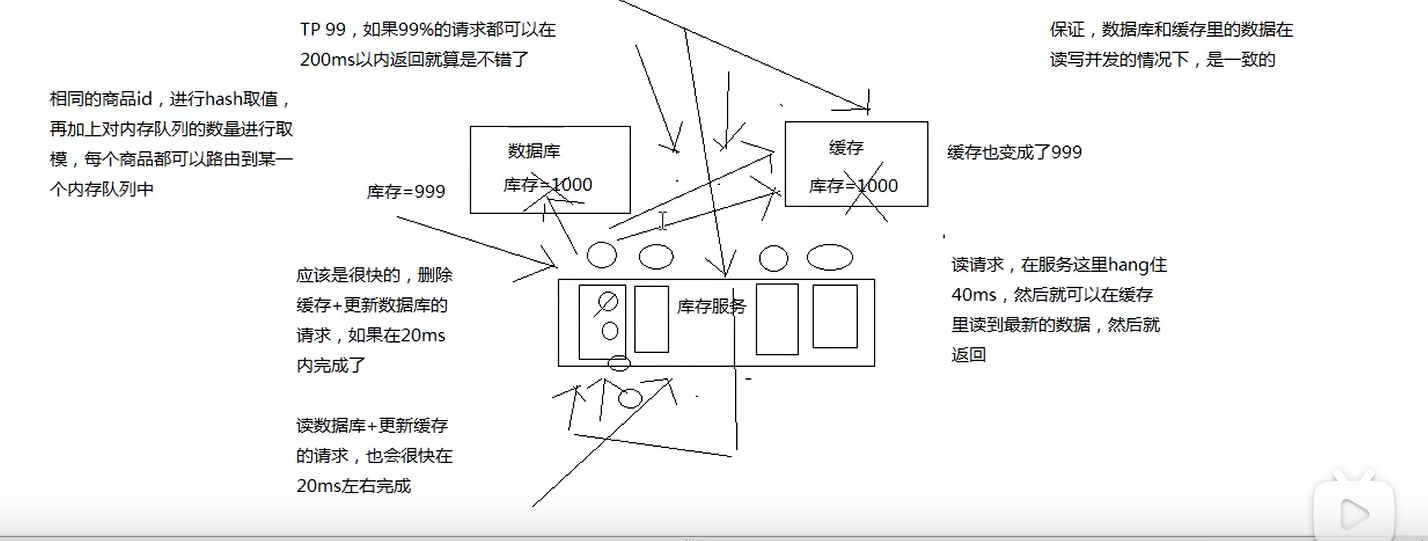



redis并发竞争问题

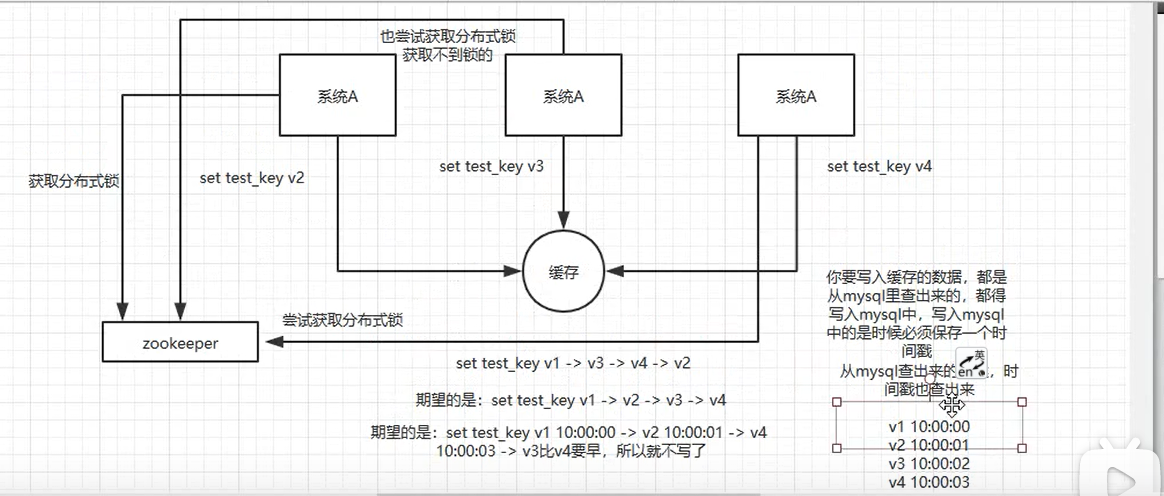
解决方案:使用分布式锁,redis有自带的分布式锁
生产环境redis的部署



若有收获,就点个赞吧
0 人点赞
