一、Redis为什么比数据库快?
Redis(使用内存的非关系型数据库)采用的是基于内存的单进程单线程模型的 KV 数据库,由C语言编写
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用多路I/O复用模型,非阻塞IO;
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
6、C 语言实现,一般来说,C 语言实现的程序“距离”操作系统更近,执行速度相对会更快。
二、那么为什么Redis是单线程的?
因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了(毕竟采用多线程会有很多麻烦!)。
三、Redis的数据存储选项
四、Redis持久化的方式
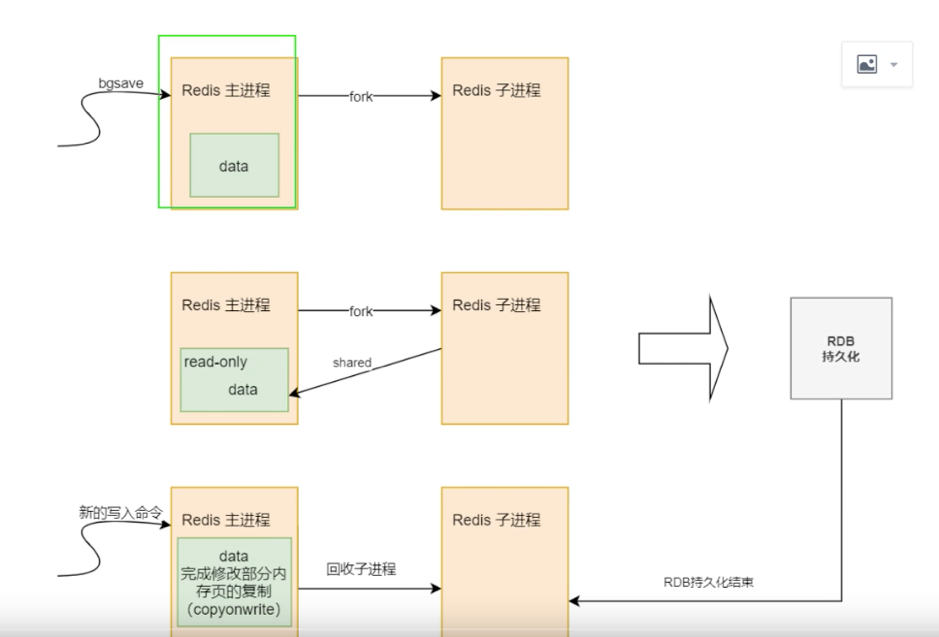
1.RDB
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。
1)RDB快照过程中Redis是否会停止对外提供服务?
2)备份是如何执行的?
Redis会单独创建(fork) 一个子进程,由该子进程来进行持久化,先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何操作的,就确保了极高的性能;如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
3)优点
- 性能最大化,fork子进程来完成持久化的操作,让主线程继续处理命令,保证了redis的高性能
重启恢复数据的时候,数据量比较大时,redis直接解析RDO二进制文件,生成对应的数据存储在内存中,比AOF的启动效率高
4)缺点
数据安全性低。RDB是间隔一段时间进行持久化的,如果持久化之间redis突然发生故障,会发生数据丢失。所以这种方式更适合数据要求不要严谨的时候
2.AOF
以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,Redis启动之初会读取该文件重新构建数据,换言之,Redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
1)优点

若有收获,就点个赞吧
0 人点赞
