- mysql索引用的是B+Tree存储
MyISAM存储引擎
- 叶子结点存储的是data的磁盘文件地址,根据该地址去存储data的文件查数据
- 有2个文件,一个存储data(MYD),一个存储index(MYI)
InnoDB存储引擎
因为mysql的文件页的大小是16kb, B+Tree的非叶子节点是存储的索引(冗余),不存储data, 这样每一页文件页能存储的节点就很多,树的深度就不会很深(树深度越深,从磁盘load节点到内存对比的次数就会很多,磁盘I/O费时)
查看mysql文件页大小(16K):SHOW GLOBAL STATUS like ‘Innodb_page_size’
各种数据结构的对比:
二叉树:
- 不会平衡树节点,如果插入一组递增的数值,会导致树的深度很深,查询起来非常耗时
假设{1,2,3,4,5,6 } 一组数据需要存储,那么他的树的深度就为6
- 不会平衡树节点,如果插入一组递增的数值,会导致树的深度很深,查询起来非常耗时
红黑树:
- 虽然实现了平衡节点,但是其结构上还是会导致树的深度很深,不如B树和B+树的索引文件页的方式存储
- B树:
- 每个节点都会存储 data数据(每个节点存储容量就大了),这样每个文件页能存储的索引数就相对来说少了很多
B + Tree:
非叶子节点存储的是冗余的索引字段,只有叶子节点才存储data数据
这样每一页文件页能存储的索引就大大的提升了,对应的树的深度也得到了优化
叶子节点用指针连接,提高区间访问的效率
Mysql是怎么查找数据的?
- load一个文件页的索引节点数据到内存,然后二分查找的方式比对(在mysql版本比较高的情况,会把索引节点全部存储在内存里)
- 两个索引节点之间存储了下一个文件页的磁盘地址
- 查内存里比对查找其实是不那么耗时的,真正耗时的是一次一次load索引节点到内存(磁盘I/O),所以树的高度在这个层面上也会影响效率
为什么建议InnoDB表必须建主键?
- 如果不建主键的话,会从该表的第一列开始,选择一列每一行都不重复的列,来组织B+Tree,如果没有满足这个条件的列,那么mysql就会建立一个隐藏列来组织B+Tree
注意:mysql的数据库资源是很宝贵的,这种事增加了mysql的工作量
为什么推荐使用自增的主键?
自增主键:
- 新插入的行一定会在原有的最大数据行下一行,mysql定位和寻址很快,不会为计算新行的位置而做出额外的消耗
- 对于高并发的负载,innodb在按主键进行插入的时候会造成明显的锁争用,主键的上界会成为争抢的热点,因为所有的插入都发生在这里,并发插入会导致间隙锁竞争
- Auto_Increment锁机制会造成自增锁的抢夺,有一定的性能损失
附:Auto_increment的锁争抢问题,如果要改善需要调优innodb_autoinc_lock_mode的配置
非自增主键:
- 可能导致节点分裂,还可能引起树需要重新平衡一下
- uuid这种一长串字符串的,在索引比较大小的时候,要根据ASSIC码,一个一个字符进行比较(还可能会有前面字符都一样,最后一个不一样的情况)
- 当往一个快满或已满的数据页中插入数据时,新插入的数据会将数据页写满,mysql 就需要申请新的数据页,并且把上个数据页中的部分数据移动到新的数据页上。这就造成了页分裂,这个大量移动数据的过程是会严重影响插入效率的。
聚集索引和非聚集索引,那个查找数据快?
聚集索引的叶子节点存储的是该数据的其他列的数据,可以直接拿到,但是非聚集索引存储的是这个数据集的磁盘文件地址,还需要跨文件去查找需要的数据(类似回表查询),所以聚集索引快\
为什么InnoDB存储引擎非主键索引结构叶子节点存储的是主键值?
-
InnoDb的二级索引的结构是什么样的?
叶子结点,存储的是主键索引,如果没有主键索引的话,存储的是mysql设置的隐藏列的rowid
- 二级索引,查数据时,先要去存储这个二级索引的ibd文件,快速查到叶子结点的主键,然后这个值,再去ibd文件的主键索引处查数据
索引的生效 - 最左前缀原理
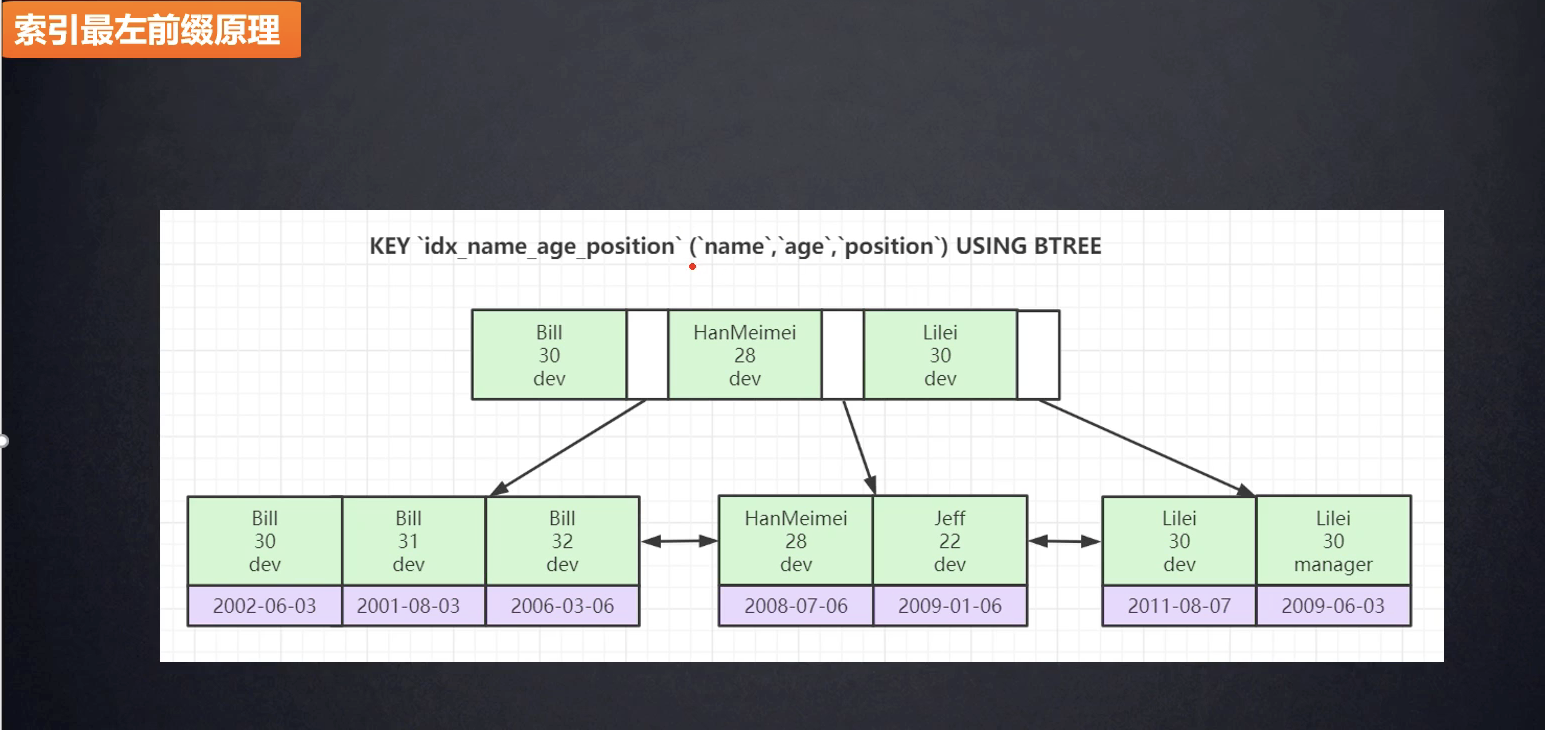
- 联和索引存储的索引是会和创建索引的顺序一致的,左右到又递增的,name -> age -> 逐一对比递增存储

上面的三条语句哪个会走索引?
- 第一条顺序符合索引建立的顺序,会走索引索引
- 第二条,跳过name,直接查的话,不符合最左前缀原理,age不是从左到又有序的;
没有where查询的情况下,如果要查找的列在二级索引都能拿到,则会优先查询二级索引
- 因为去查找主键索引的话,要查找的数据量很大,浪费了资源
示例:
1.表存在一个 name 列的二级索引 "index_name"select id,name from temp;
索引下推(Index Condition Pushdown,ICP)
like KK%其实就是用到了索引下推优化
什么是索引下推了?
SELECT * FROM employees WHERE name like 'LiLei%' AND age = 22 AND position ='manager'
对于辅助的联合索引(name,age,position),正常情况按照最左前缀原则,这种情况只会走name字段索引,因为根据name字段过滤完,得到的索引行里的age和position是无序的,无法很好的利用索引。
在MySQL5.6之前的版本,这个查询只能在联合索引里匹配到名字是 ‘LiLei’ 开头的索引,然后拿这些索引对应的主键逐个回表,到主键索引上找出相应的记录,再比对age和position这两个字段的值是否符合。
MySQL 5.6引入了索引下推优化,可以在索引遍历过程中,对索引中包含的所有字段先做判断,过滤掉不符合条件的记录之后再回表,可以有效的减少回表次数。使用了索引下推优化后,上面那个查询在联合索引里匹配到名字是 ‘LiLei’ 开头的索引之后,同时还会在索引里过滤age和position这两个字段,拿着过滤完剩下的索引对应的主键id再回表查整行数据。
注意:
索引下推会减少回表次数,对于innodb引擎的表索引下推只能用于二级索引,innodb的主键索引(聚簇索引)树叶子节点上保存的是全行数据,所以这个时候索引下推并不会起到减少查询全行数据的效果。
Mysql如何定位寻址

若有收获,就点个赞吧
0 人点赞
