一、基础
京东二面:泛型中extends和super的区别?
- <? entend T>:表示包括T在内的任何T的子类
- <? super T>:表示包括T在内任何T的父类
二、集合
说⼀下ArrayList和LinkedList区别
- 底层数据结构不同,ArrayList底层是基于数组实现的,LinkedList底层是基于链表实现
- LinkedList 实现了
Deque,可以当做双端队列使用 - ArrayList 指定index查询比较快,LinkedLink查询需要遍历整个数组
- LinkedList 比较适合添加、删除多的场景,因为LinkedList的添加和删除时只需要修改
prev和next的指向,arraylist添加或删除时,可能涉及到扩容或数组移动,但使用尾插法并指定初始容量可以极大提升性能、甚至超过linkedList - 遍历LinkedList必须使用iterator不能使用for循环,因为每次for循环体内通过get(i)取得某一元素时都需 要对list重新进行遍历,性能消耗极大。
ArrayList的扩容
- 创建时不指定容量,默认为
空的Object类型数组 - 可以在创建时指定容量
- 在
add操作时进行判断是否需要扩容(每次扩容为当前数组长度的1.5倍)
// 第一次add操作private static int calculateCapacity(Object[] elementData, int minCapacity) {if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { //创建arrayList的时候未指定容量 elementData = []return Math.max(DEFAULT_CAPACITY, minCapacity); // DEFAULT_CAPACITY == 10}return minCapacity;}// 扩容代码private void grow(int minCapacity) {// overflow-conscious codeint oldCapacity = elementData.length;int newCapacity = oldCapacity + (oldCapacity >> 1); // 扩容if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win:elementData = Arrays.copyOf(elementData, newCapacity);}
HashMap扩容机制
- 创建的时候设置加载因子为0.75
- 第一次添加时,需要扩容table的容量为16,临界值为12(16*0.75),在以后的扩容则需要扩容为原来的2倍
jdk 1.8:
- 如果一条链表的元素个数超过的默认的8,且table的大小 >= MIN_TREEIFY_CAPACIT(默认64),就会转为红黑树
说⼀下HashMap的Put⽅法

ConcurrentHashMap原理,jdk7和jdk8版本的区别
jdk7:数据结构:ReentrantLock + Segment + HashEntry 一个Segment中包含一个HashEntry数组,每个 HashEntry又是一个链表结构
- 元素查询:二次hash,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部
- 锁:Segment分段锁 Segment继承了ReentrantLock,锁定操作的Segment,其他的Segment不受影响,并发度为segment个数,可以通过构造函数指定,数组扩容不会影响其他的segment
- get: 无需加锁,volatile保证
jdk8: 数据结构:synchronized + CAS + Node + 红黑树,Node的val和next都用volatile修饰,保证可见性
- 查找,替换,赋值操作都使用CAS
- 锁:锁链表的head节点,不影响其他元素的读写,锁粒度更细,效率更高,扩容时,阻塞所有的读写 操作、并发扩容
读操作无锁: Node的val和next使用volatile修饰,读写线程对该变量互相可见 数组用volatile修饰,保证扩容时被读线程感知
三、并发编程
volatile:(保证即时可见性)
保证可见性
- 禁止重排序(无法保证临界区的重排序)
- 无法保证原子性
volatile底层原理:
- 修饰的变量会被加上 “ACC_VOLATILE” 标识
- volatile修饰的变量,在执行时,底层的汇编指令,会加上一个lock前缀指令
- lock前缀指令作用:触发硬件缓存锁定机制
- 总线锁定
- EMSI(缓存一致性协议)
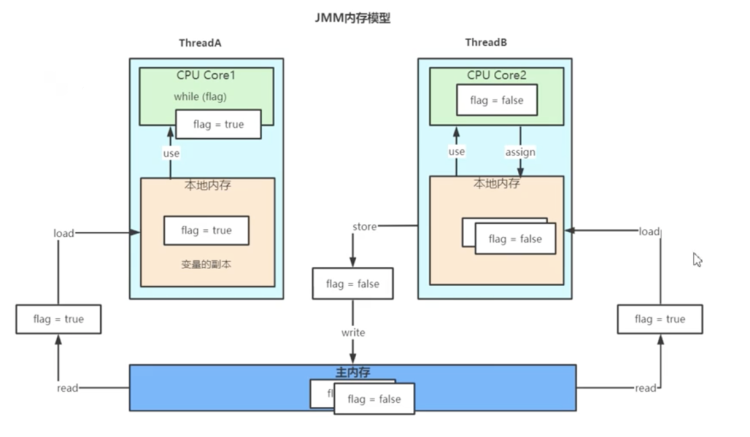
JMM
JMM(Java内存模型 Java Memory Model, 简称JMM)
由于JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(有些地方称为栈空间),工作内存是每个线程的私有数据区域,而Java内存模型中规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问,但线程对变量的操作(读取赋值等)必须在自己的工作内存中进行,读取主内存的值,到自己的的缓存区域(变量副本)
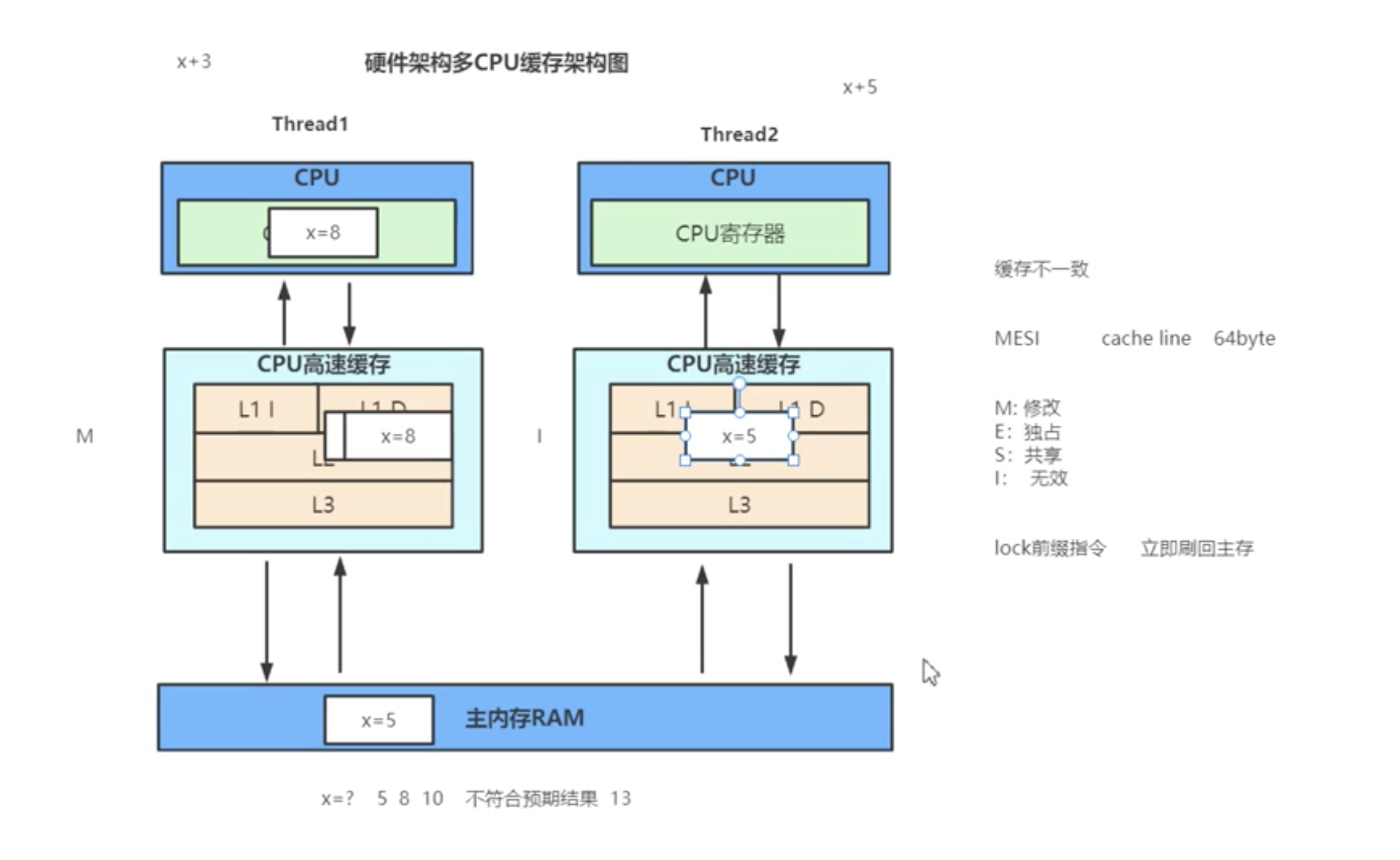
EMSI缓存一致性协议 - 总线窥探(Bus Snooping)
窥探协议类型:
- Write-invalidate
当处理器写入一个共享缓存块时,其他缓存中的所有共享副本都会通过总线窥探失效,MSI、EMSI、MOSI、MOESI和MESIF都属于该类型
- Write-update
当处理器写入一个共享缓存块时,其他缓存中的所有共享副本都会通过总线窥探更新
EMSI缓存一致性协议(Volatile 不支持原子性的原因)
- 当两个线程,都执行写操作时,最终由 “总线裁决” (速度非常快)决定哪个线程抢占资源继续执行,另一个则失效
- 缓存一致性协议的总线窥探什么情况会升级为总线锁?
- 当缓存行存储的对象大于64byte的时候,就会升级为使用总线锁
- 因为,两个缓存行之间无法保证原子操作
缓存行伪共享,什么是伪共享?
CPU缓存系统中是以缓存行(cache line)为单位存储的。目前主流的CPU Cache 的
Cache Line 大小都是64Bytes。在多线程情况下,如果需要修改“共享同一个缓存行的变
量”,就会无意中影响彼此的性能,这就是伪共享(False Sharing
举个例子: 现在有2个long 型变量 x 、y,如果有t1在访问x,t2在访问y,而x与y刚好在同一个
cache line中,此时t1先修改x,将导致y被刷新!
怎么解决伪共享?
Java8中新增了一个注解:@sun.misc.Contended。加上这个注解的类会自动补齐缓
存行,需要注意的是此注解默认是无效的,需要在jvm启动时设置才会生效。
总线锁定
- 回到单核
Synchronized
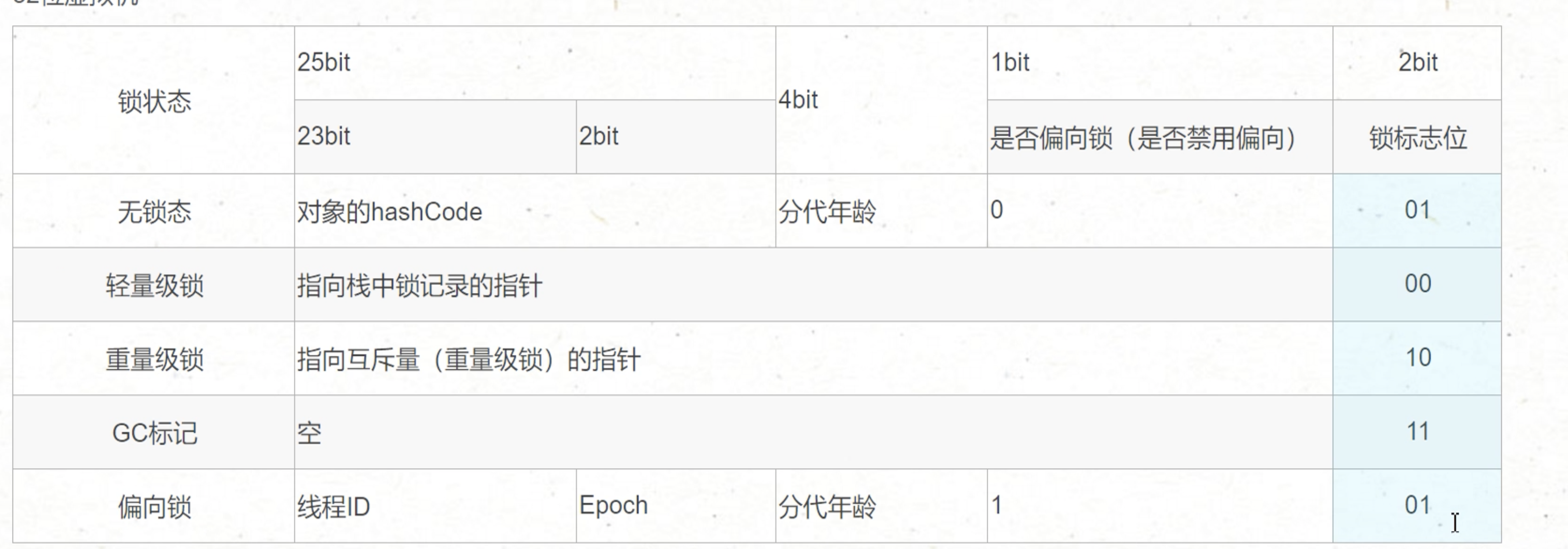
锁升级
Synchronized jdk 1.6 之前还是使用的重量级锁,没有锁升级机制
JDK 1.6后:
- 无锁:对象一开始就是无锁状态。
- 偏向锁:相当于给对象贴了一个标签(将自己的线程 id 存入对象头中(Mark word)),下次我再进来时,发现标签是我的,我就可以继续使用了。
- 自旋锁:想象一下有一个厕所,里面有一个人在,你很想上但是只有一个坑位,所以你只能徘徊等待,等那个人出来以后,你就可以使用了。 这个自旋是使用 cas 来保证原子性的
- 重量级锁:直接向 cpu 去申请申请锁,其他的线程都进入队列中等待,阻塞。
锁升级是什么时候发生的?
- 偏向锁:一个线程获取锁时会由无锁升级为偏向锁
- 自旋锁:当产生线程竞争时由偏向锁升级为自旋锁,想象一下 while(true)
- 重量级锁:当线程竞争到达一定数量或自旋超过一定时间时,晋升为重量级锁
为什么会有自旋锁?
- 因为执行业务代码耗时可能很快,不让出CPU资源自旋等待锁的释放,比阻塞线程,等待其他线程唤醒效率更高
为什么要升级重量级锁?
- 业务代码执行过长,一直未释放锁或者自旋获取锁的线程非常多,未获取锁的线程一直在自旋获取锁,会导致CPU占用大量资源
非公平锁和公平锁的区别
- 非公平锁容易出现 “锁饥饿”
- 公平锁需要先判断同步队列是否有前驱节点存在
为什么会有非公平锁
让我们考虑一种情况:
- 假设线程 A 持有一把锁
- 线程 B 请求这把锁,由于线程 A 已经持有这把锁了,所以线程 B 会陷入等待,在等待的时候线程 B 会被挂起,也就是进入阻塞状态
- 那么当线程 A 释放锁的时候,本该轮到线程 B 苏醒获取锁,但如果此时突然有一个线程 C 插队请求这把锁,那么根据非公平的策略,会把这把锁给线程 C,这是因为唤醒线程 B 是需要很大开销的,很有可能在唤醒之前,线程 C 已经拿到了这把锁并且执行完任务释放了这把锁。
- 相比于等待唤醒线程 B 的漫长过程,插队的行为会让线程 C 本身跳过陷入阻塞的过程,如果在锁代码中执行的内容不多的话,线程 C 就可以很快完成任务,并且在线程 B 被完全唤醒之前,就把这个锁交出去,这样是一个双赢的局面,对于线程 C 而言,不需要等待提高了它的效率,而对于线程 B 而言,它获得锁的时间并没有推迟,因为等它被唤醒的时候,线程 C 早就释放锁了,因为线程 C 的执行速度相比于线程 B 的唤醒速度,是很快的
- 所以 Java 设计非公平锁,是为了提高整体的运行效率
注意:针对 tryLock() 方法,它不遵守设定的公平原则
例如,当有线程执行 tryLock() 方法的时候,一旦有线程释放了锁,那么这个正在 tryLock 的线程就能获取到锁,即使设置的是公平锁模式,即使在它之前已经有其他正在等待队列中等待的线程,简单地说就是 tryLock 可以插队
看源码就会发现
public boolean tryLock() {return sync.nonfairTryAcquire(1);}
这里调用的就是 nonfairTryAcquire(),表明了是不公平的,和锁本身是否是公平锁无关
ReentrantLock
Synchronized和 ReentrantLock的区别
synchronized:
- 显示锁
- JVM层面的
- 公平锁
ReentrantLock:
- 隐式锁
- API 调用
CountDownLatch和Semaphore的区别和底层原理
CountDownLatch:计数器,可以给CountDownLatch设置一个数值,一个线程调用
Semaphore:信号量,可以设置许可的个数,表示同时允许最多多少个线程使用该信号量,通过 acquire() 方法来获取许可,如果没有许可可用则线程阻塞,并通过AQS来排队,可以通过 release() 方法来释放许可,当某个线程释放许可后,会从AQS中正在排队的第一个线程开始依次唤醒

若有收获,就点个赞吧
0 人点赞
