一、List
1.ArrayList - 非线程安全
- 可以存储null
1)创建过程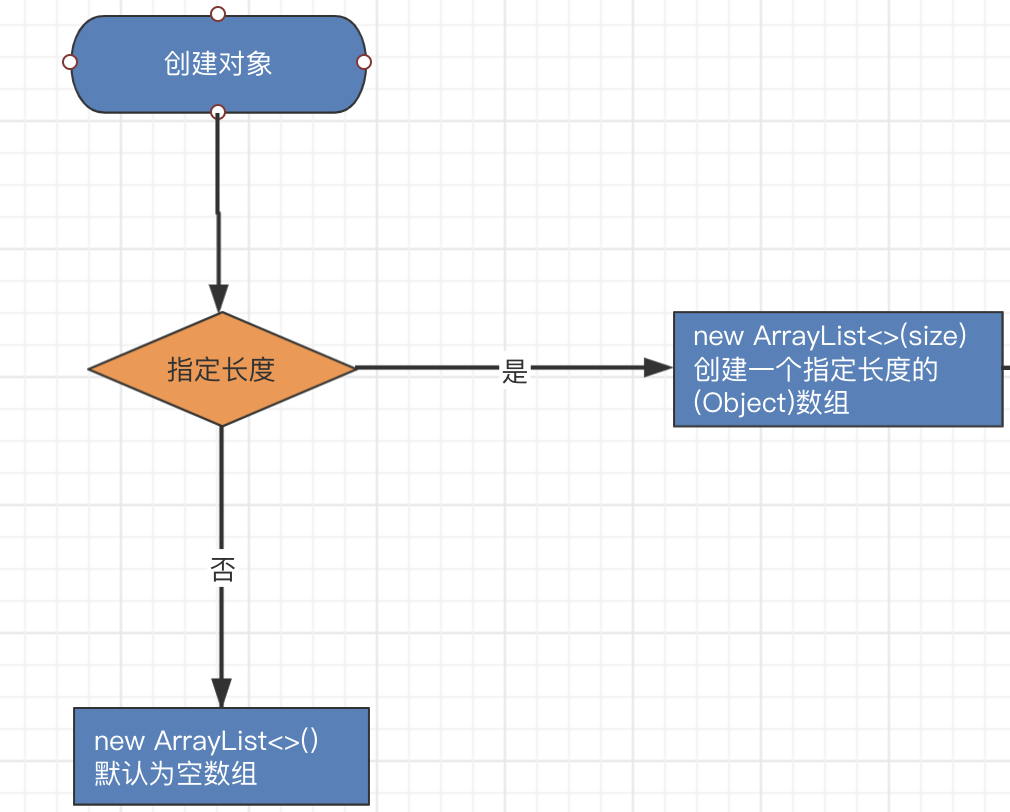
未指定初始化容量时 - 默认创建一个空数组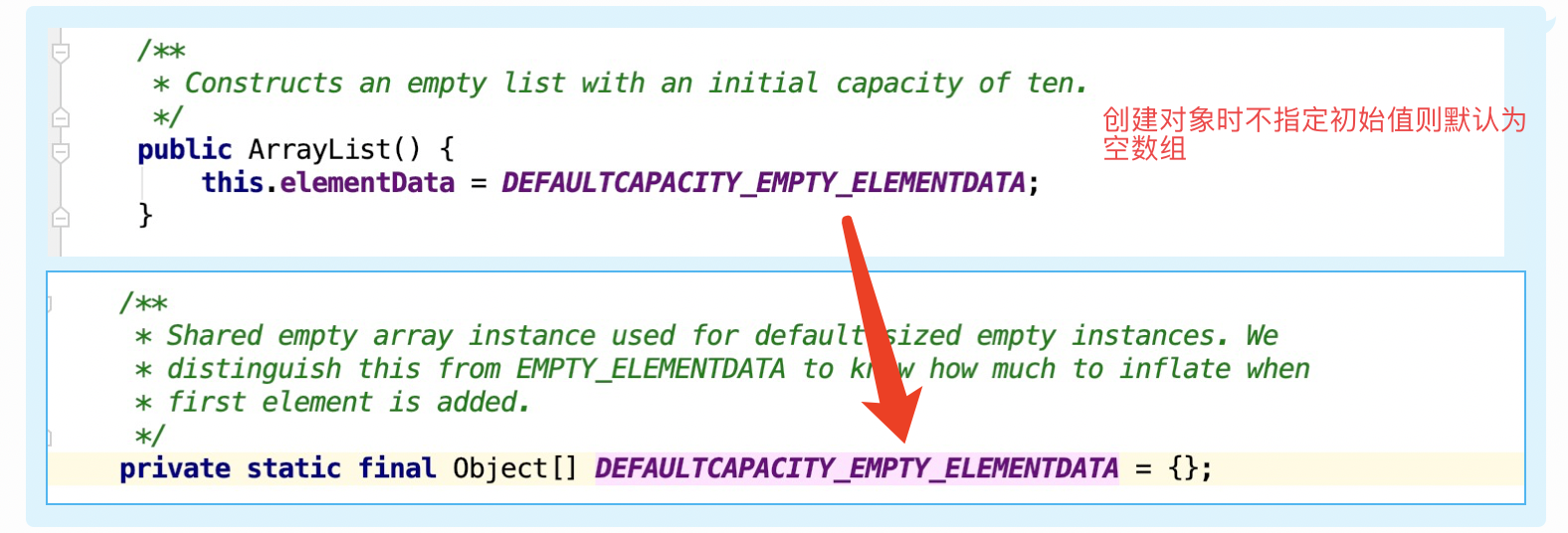
指定了初始化容量 - 创建一个指定容量大小的数组
2)ArrayList是如何进行扩容的?
在向集合添加数据调用list.add()方法时,判断是否需要扩容
注意:JDK1.7之前ArrayList默认⼤⼩是10,JDk1.7之后是0
1)未指定集合容量,默认是0,若已经指定⼤⼩则集合⼤⼩为指定的;
2)当集合第⼀次添加元素的时候,集合⼤⼩扩容为10
int newCapacity = oldCapacity + (oldCapacity >> 1);
ArrayList的元素个数⼤于其容量时,扩容的⼤⼩ = 原始⼤⼩ + (原始⼤⼩ >> 1)
3)如果需要保证线程安全,ArrayList应该怎么做,⽤有⼏种⽅式?
1)⾃⼰写个包装类,根据业务⼀般是add/update/remove加锁
2)Collections.synchronizedList(new ArrayList<>()); 使⽤synchronized加锁
3)CopyOnWriteArrayList<>() 使⽤ReentrantLock加锁 - 写时复制技术
4)CopyOnWriteList<> - 写时复制容器
public boolean add(E e) {final ReentrantLock lock = this.lock;lock.lock();try {Object[] elements = getArray();int len = elements.length;Object[] newElements = Arrays.copyOf(elements, len + 1);newElements[len] = e;setArray(newElements);return true;} finally {lock.unlock();}}
写时复制容器,在执行add()方法时,不是直接向Object[]容器添加元素,而是先将Object[]进行copy复制出一个新的容器Object[] newElements,然后往新的容器里添加元素,添加完之后再将原来容器的指向,指向新的元素 setArray(newElements);
这样的好处是,可以进行并发读,不需要加锁,因为当前元素不会直接执行添加操作,所以CopyOnWriteArrayList<>()是一种读写分离的思想,读和写不同的容器;
缺点:内存占⽤问题,写时复制机制,内存⾥会同时驻扎两个对象的内存,旧的对象和新写⼊的对象,如果对象⼤则容易发⽣Yong GC和Full GC
三、Set
1.HashSet - 非线程安全
1)底层原理
底层是HashMap<>
public HashSet() {map = new HashMap<>();}
2)为什么在add()方法的时候只有一个参数,不是键值对的方式?
因为这里的HashMap的value是一个Object类型的常量
四、Map
1.了解Map吗?⽤过哪些Map的实现?
HashMap、Hashtable、LinkedHashMap、TreeMap、ConcurrentHashMap
2.说一下HashMap和Hashtable有什么区别?
1)HashMap:底层是基于数组+链表(JDK7) 、**数组+链表+红黑树(JDK8),⾮线程安全的(效率高),默认容量是16、允许有空的健和值
2)Hashtable:基于哈希表实现,线程安全的(加了synchronized - 效率低),默认容量是11,不允许有null的健和值**
3.HashMap和TreeMap应该怎么选择,使⽤场景
hashMap: 散列桶(数组+链表),可以实现快速的存储和检索,⽆序的元素,适⽤于在map中插⼊删除和定位元素
treeMap:使⽤存储结构是红⿊树,可以⾃定义排序规则,要实现Comparator接口能便捷的实现内部元素的各种排序,但是⼀般性能⽐HashMap差
4.如果要求线程安全,且效率高的map,应该怎么做?
多线程环境下可以使用concurrent包下的ConcurrentHashMap,比HashTable的效率要高很多,或者用Collections.synchronizedMap()
3.HashMap - 非线程安全
1)为什么使用数组?
连续的存储单元存储数据,在指定下标查询时,其时间复杂度为0(1),但是对一般的插入和删除操作,需要移动数组元素,其时间复杂度为O(n)
2)为什么引入线性链表? (头插法、位运算)
链表在新增和删除操作时,只需要**修改前后节点的引用就可以了,时间复杂度为O(1),但是在查找操作的时候需要**所有结点逐一比较,时间复杂度为0(n)
3)为什么jdk1.8以后又引入了红黑树?
红黑树:是一种接近平衡的二叉树,确保没有一条路径会比其他路径长出2倍,从而接近平衡,支持查找、新增和删除的时间复杂度为O(nlogn)
4)初始化
1.没有指定初始容量,那么容量则为默认的16
2.指定了初始容量,则为指定的大小,这里指定容量时必须是2的指数次幂,如果不是则会强制转换成最接近的大于指定容量的2的指数次幂。例如:指定容量为13,会默认转换成14
5)为什么HashMap线程不安全?(JDK7)
在多线程下,HashMap在扩容时可能导致一个环,导致死锁
**
6)在JDK8的时候为什么不会出现线程不安全扩容导致死锁的问题?
在扩容的时候不再是reHash的方式,而是用位运算区计算出loHead与hiHead**,loHead在扩容的时候会直接转移到新数组的当前索引的位置,hiHead则会转移到当前索引+oldCap** 的位置
// 位运算判断loHead和hiHeadif ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}// 扩容的位置if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}
7)为什么负载因子设置为0.75?
通过牛顿二项式推到出一个大约等于 log2 = 0.698…的数,然后取了一个时间和空间折中的值0.75
如果 loadFactor >= 1 hash碰撞的可能性就越大,查找时间复杂度越高(时间换空间)
如果 loadFactor < 0.5 hash碰撞的可能性就越低,查找时间复杂度时间短(空间换时间)
8)HashMap中链表什么时候会转红黑树?
1)当数组的长度**小于**64时,链表的长度达到了8,也只会进行扩容操作
2)当数组的长度**大于**64时,链表的长度达到8,则进行链表转红黑树的操作

若有收获,就点个赞吧
0 人点赞
