Part I Introduction to a problem
Remember how in the last lesson we mentioned that in a digital camera, the light after passing through a lens gets transformed into long array of digits, which describes what was in front of the camera the moment picture was taken? It is just a part of the story - particularly, the part about capturing and storing an image. Sometimes that is exactly what we want and nothing else - to snap a picture and store it/share it with our friends online. But what if we want to alter the digital image (for example by adding fake mustache to our selfie) or extract information from an image to control a self-driving car or robot manipulator - or a robotic dog, for that matter. How can we do it?
Part II Explaining the knowledge
Enter Computer Vision
Computer vision is the field of computer science that focuses on replicating parts of the complexity of the human vision systems and enabling computers to identify and process objects in images and videos in the same way that humans (or other animals) do.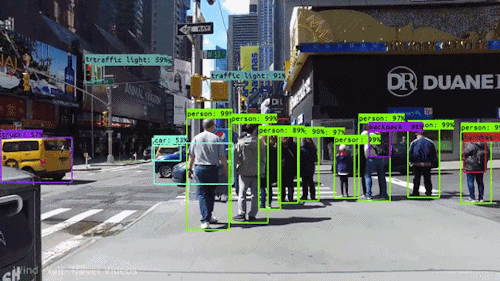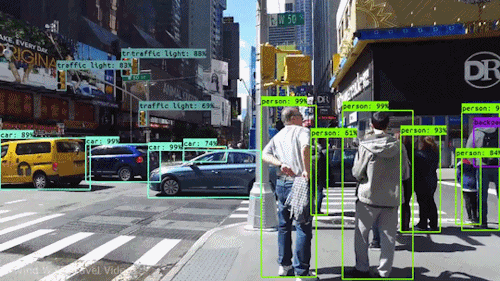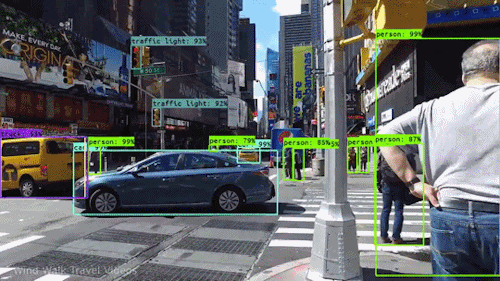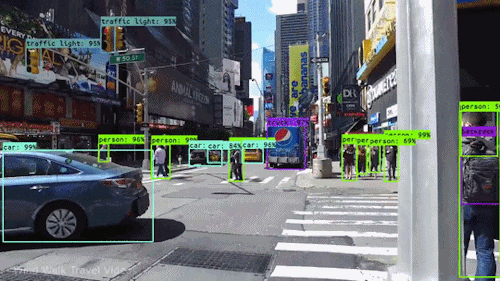
Early experiments in computer vision started in the 1950s and it was first put to use commercially to distinguish between typed and handwritten text by the1970s, today the applications for computer vision have grown exponentially.
Early computer vision application relied on hand-written algorithms to perform the tasks. Hand-written here means that the algorithm for each task must have been thought and implemented by a highly-skilled engineer. And even then, due to complexity of visual perception, many of these algorithms(examples include SIFT feature extractor, Haar cascades, Hough line transform and others) were fragile to environment changes. 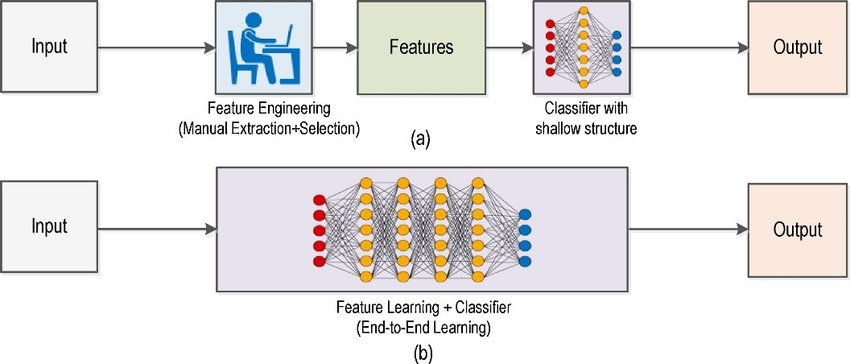
What really changed the field of Computer Vision is a technique that allowed machines to learn how to distinguish objects in the images by themselves from vast amounts of data. In above picture (a) corresponds to traditional computer vision approach and (b) is Deep Learning Computer Vision.
Machine Learning and Deep Learning
Until recently, computer vision only worked in limited capacity. In the 1980s, French computer scientist Yan LeCun introduced the convolutional neural network (CNN). A CNN comprises multiple layers of artificial neurons, mathematical components that roughly imitate the workings of their biological counterparts.
When a convolutional neural network processes an image, each of its layers extracts specific features from the pixels. The first layer detects very basic things, such as vertical and horizontal edges. As you move deeper into the neural network, the layers detect more-complex features, including corners and shapes. The final layers of the CNN detect specific things such as faces, doors, and cars. 
The output layer of the CNN provides a table of numerical values representing the probability that a specific object was discovered in the image. LeCun’s convolutional neural networks were brilliant and showed a lot of promise, but they were held back by a serious problem: Tuning and using them required huge amounts of data and computation resources that weren’t available at the time.
In 2012, AI researchers from Toronto developed AlexNet, a convolutional neural network that dominated in the popular ImageNet image-recognition competition. AlexNet’s victory showed that given the increasing availability of data and compute resources, maybe it was time to revisit CNNs. The event revived interest in CNNs and triggered a revolution in deep learning, the branch of machine learning that involves the use of multi-layered artificial neural networks.
Part III Solving a problem
Task 1: Detect a presence of a person
For the first task we’re going to use Vision sensor to detect presence of a person.The following code will make BIttle to joyfully step in place if it “sees” a person and return back to standing posture if the person is gone.  Connect Vision sensor to Bittle mainboard Grove I2c socket and upload the following code (you can find Vision sensor detected person block in Grove I2C category):
Connect Vision sensor to Bittle mainboard Grove I2c socket and upload the following code (you can find Vision sensor detected person block in Grove I2C category):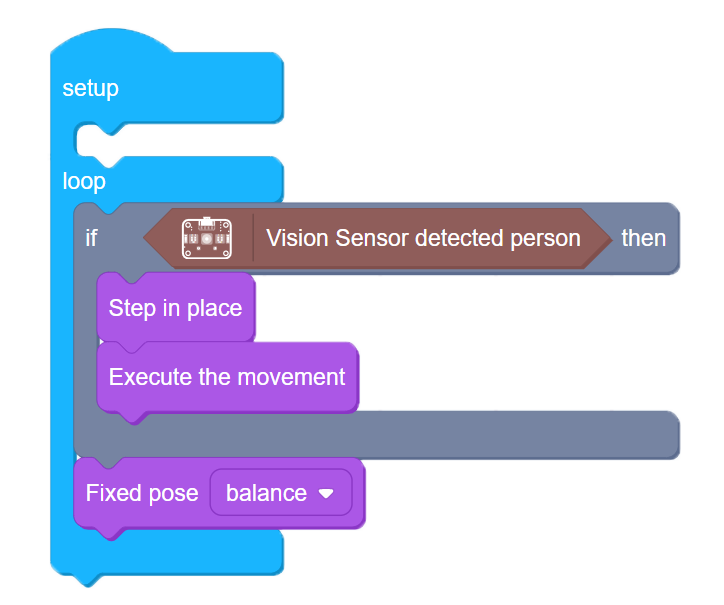
6-1

Task 2: Make Bittle follow a ball left and right with head servo
Let’s use Bittle’s pan head servo and Vision sensor to track an orange ping-pong ball left to right and back. First we determine ball’s center x-coordinate and save it into a variable. If coordinate returned is -1, it means no ball found, so our robot doesn’t need to do anything. If there is a ball detected, then we move Head servo to 40 - ball’s center x-coordinate degree. 40 is the center of our Vision sensor image, so if ball’s x-center x-coordinate is 40 we set servo angle to 0(dead center). Otherwise we move it in appropriate direction to offset angle.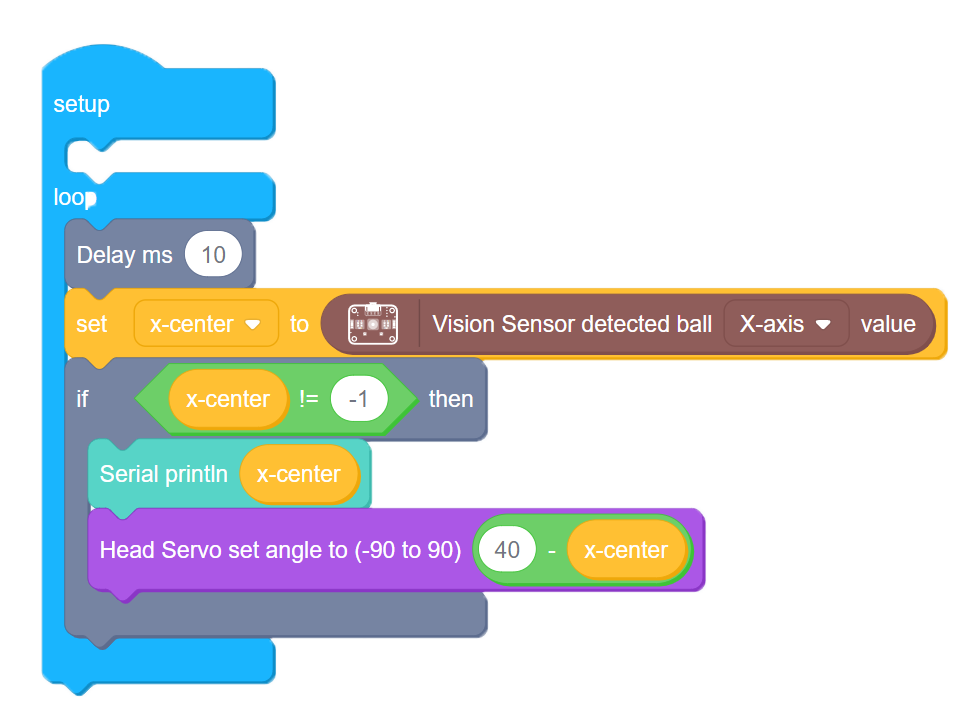
6-2
Use an orange ping-pong ball or other round object of orange color to test the above code:
Task 3: Make BIttle follow a ball up and down with front legs
Next task is going to be a big more challenging - make our robot follow ball up and down by changing the angle of front feet servos. You might have noticed that in previous code example servo movement can be too sudden - in order to improve this and smoothen the motion, we employ different algorithm here.
First we make BIttle go into sitting pose and straighten up front shoulder joints. Then we receive ball center y-axis value and if it is lower or equals 42, add 1 to leg_angle variable. If it is higher or equals than 48 we subtract 1 from leg_angle variable. Then we constrain leg_angle variable between 90 and -30 and finally move servos 12 and 13 (front feet) to leg_angle angle.
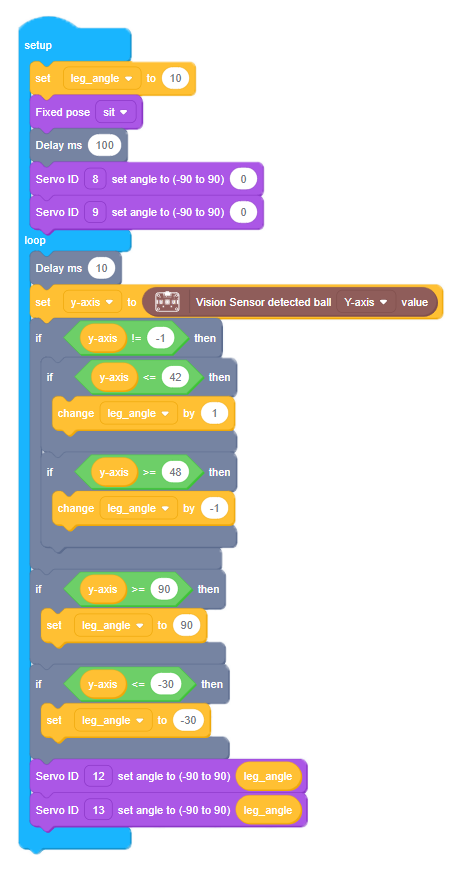
6-3
Part IV Expanding the knowledge
Combine code 2 and code 3 to make a program allowing Bittle follow ball left and right, up and down.

若有收获,就点个赞吧
0 人点赞
