1.LSTM的简单介绍
LSTM(long short-term memory),长短时记忆网络,是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,相比普通的(Naive)RNN,LSTM能够在更长的序列中有更好的表现。在结构上,LSTM和RNN有所不同,多了一个输入c,多的这个c相比到底优势在哪呢?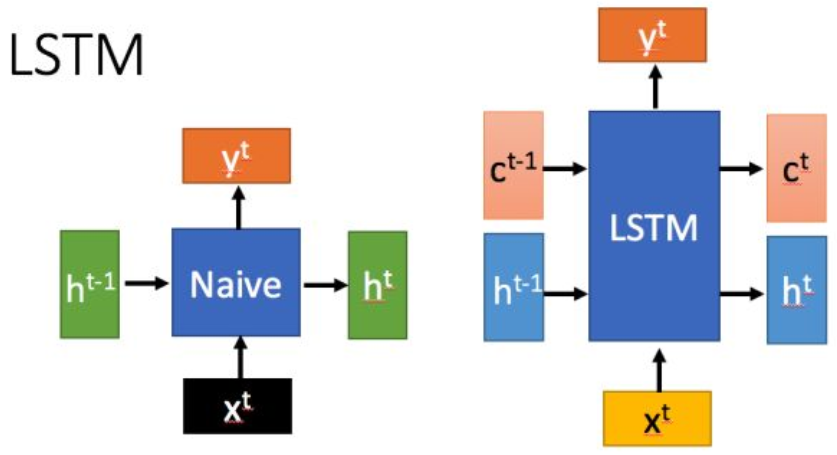
这里的ct (cell state,暂时不深究什么是cell state)改变得很慢,通常输出的 ct 是上一个状态传过来的c加上一些数值,而 h则在不同节点下往往会有很大的区别。另外关于LSTM还需要注意两点,以下面的图片来说明,图片选自台大李宏毅的视频:
(1)h、h、h…都是同一纬度的
(2)不管RNN的长度有多长,只需要一个函数f即可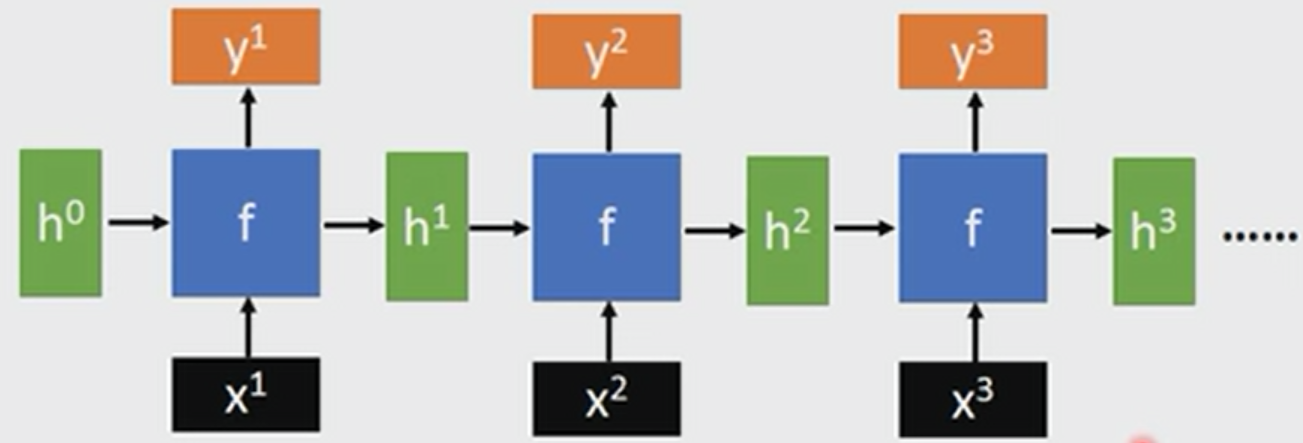
2.LSTM的运算
在LSTM中,相当于有三个输入,分别为c,h和xt,有了这些输入后,怎么操作呢?在LSTM中,它的操作是使用LSTM的当前输入 xt 和上一个状态传递下来的 h拼接,并进行四次操作,得到四个状态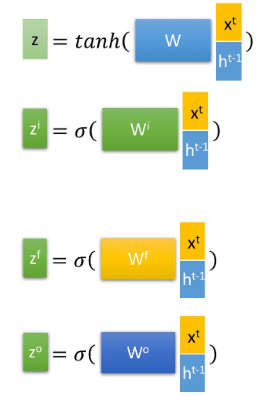
其中, z ,z ,z 分别表示忘记(forget),输入(input),输出(output),这里另外一个输入c的作用是什么呢?它有两个作用,第一在某些时候,会将c作为一个输入和xt 和h一起拼接,如下所示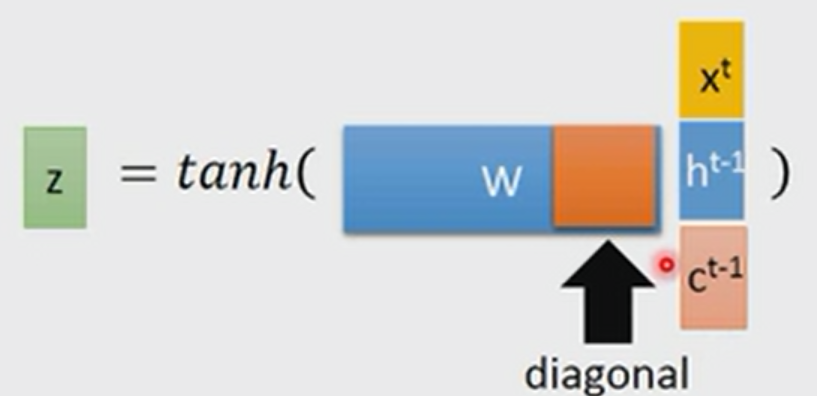
另外一个是更常见更重要的作用,就是和状态z一起参与运算,输出ct 就是由c得到的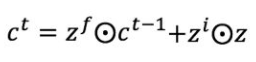
⊙是矩阵乘法,也就是操作矩阵中对应的元素相乘,因此要求两个相乘矩阵是同型的。另外一个输出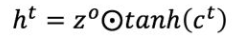
最终的输出y表示为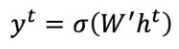
3.LSTM的逻辑
(1)遗忘门
LSTM的第一步是决定扔掉什么信息,例如前面说到的预测单词下一句是什么,“某地原来是碧水蓝天,后来被污染了”,看到“污染了”之后,LSTM应该忘记“碧水蓝天”。LSTM靠一些门让信息有选择性地影响每个时刻的状态,第一个门就是“遗忘门”,“遗忘门”z的表达式在前面写过,它等于
f=sigmoid(Wf[ht-1,xt])
由于sigmoid函数的输出值在[0,1]之间,当f的取值接近1的时候,纬度上的信息会被保留,当取值接近于0,纬度上的信息被忘记
(2)输入门
信息被忘记后,还需要补充最新的记忆,这个过程就是“输入门”完成的,例如前面提到的“被污染了”,就应该加入到最新的状态中,“输入门”的表达式和“遗忘门”几乎一样,只是参数不一样,一个是Wf,另外一个是Wi
f=sigmoid(Wi[ht-1,xt])
(3)输出门
LSTM在得到最新状态c后还需要产生当前时刻的输出,这个过程是通过“输出门”来完成的,“输出门”会根据最新的状态(c),上一时刻的输出(h)和当前时刻的输入(x)来决定该时刻的输出h,例如当前的状态为“被污染”,那么“天空的颜色”后面的单词很可能就是“灰色的”。LSTM的结构如下图所示。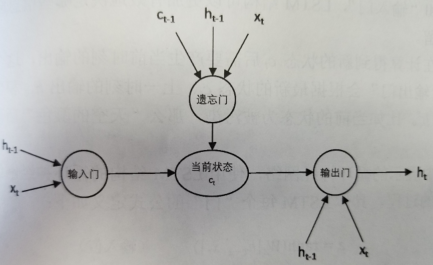
4.LSTM实战代码
(1)预测比特币价格
# -*- coding: utf-8 -*-"""@author: Haojie Shu@time:@description:"""import gcimport datetimeimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport timefrom keras.models import Sequentialfrom keras.layers import Activation, Densefrom keras.layers import LSTMfrom keras.layers import Dropoutbatch_size = 128epochs = 53windows = 7def get_market_data(market, tag=True):# pd.read_html:返回dataframe, 可能是list形式的dataframemarket_data = pd.read_html("https://coinmarketcap.com/currencies/" + market +"/historical-data/?start=20130428&end="+time.strftime("%Y%m%d"), flavor='html5lib')[0]market_data = market_data.assign(Date=pd.to_datetime(market_data['Date'])) # df.assign:创建或修改列# pd.to_numeric:转化为数据, errors='coerce'表示如果是数据有误,则用NaN来代替# fillna(0):对所有的NaN值用0来替代market_data['Volume'] = (pd.to_numeric(market_data['Volume'], errors='coerce').fillna(0))if tag: # tag非空,执行# df.columns:取df的列,返回一个list,第一列(时间)不动,其他列都加上BTC和ETH字段market_data.columns = [market_data.columns[0]] + [tag + '_' + i for i in market_data.columns[1:]]return market_datadef merge_data(a, b, from_date='2016-01-01'): # 将BTC和ETH的数据mergemerged_data = pd.merge(a, b, on=['Date'])merged_data = merged_data[merged_data['Date'] >= from_date]return merged_datadef create_model_data(data): # 取merge后的数据中的5列,其他的舍弃data = data[['Date']+[coin+metric for coin in ['BTC_', 'ETH_'] for metric in ['Close**', 'Volume']]]data = data.sort_values(by='Date')return datadef split_data(data, training_size=0.8): # 取df数据的前80%作为训练数据,后面的20%为测试数据return data[:int(training_size*len(data))], data[int(training_size*len(data)):]def create_inputs(data, coins=['BTC', 'ETH'], window_len=7):norm_cols = [coin + metric for coin in coins for metric in ['_Close**', '_Volume']]inputs = []for i in range(len(data) - window_len):# df[0:7],取第1到第7行; df.copy(deep=True):当deep为true时,copy值发生改变,不会影响原值.deep为false原值改变副本也改变temp_set = data[i:(i + window_len)].copy()inputs.append(temp_set)for col in norm_cols:# ------------------------------------# 这行代码看着比较复杂,一步步来# 1.inputs[i]就是一个df# 2.loc[:, col]取列名col的这一列,loc[:, col].iloc[0]取列的第一个元素,除完之后对所有的元素都减1# 3.做除法时,0/0为NaN,1/0为inf(无穷大)# 4.最后一步将运算后的值赋给这一列# ------------------------------------inputs[i].loc[:, col] = inputs[i].loc[:, col] / inputs[i].loc[:, col].iloc[0] - 1return inputsdef create_outputs(data, coin, window_len=7):# -----# df['A'][1:].values 取A这一列的1到后面行的值,以numpy.ndarray的形式返回[0. 0.]# -----return (data[coin + '_Close**'][window_len:].values / data[coin + '_Close**'][:-window_len].values) - 1def to_array(data):x = [np.array(data[i]) for i in range(len(data))]return np.array(x)def build_model(inputs, output_size=1, neurons=512, activation_function='tanh',dropout=0.25, loss='mse', optimizer='adam'): # 这个函数的作用只是建模,搭一个空架子,而不是训练# Keras Sequential:顺序模型,既可以将网络层实例的列表传递给Sequential()的构造器,也可以使用add()方法将各层添加到模型中,# 本文就是这样的方式来实现的.本代码的模型是一个包含Dropout的三层循环神经网络, 最后再加了一个Dense层model = Sequential()# ===============================================================================================================# keras.layers.LSTM(units, activation='tanh', recurrent_activation='hard_sigmoid', use_bias=True,# kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal', bias_initializer='zeros',# unit_forget_bias=True, kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None,# activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None,# dropout=0.0, recurrent_dropout=0.0, implementation=1, return_sequences=False, return_state=False,# go_backwards=False, stateful=False, unroll=False)# 用Keras来实现LSTM,包含以下参数:# units:输出空间的维数;activation:激活函数;recurrent_activation:用于循环步骤的激活函数;use_bias:是否采用偏执函数# return_sequences:是返回输出序列中的最后一个输出,还是返回完整序列# input_shape:指定输入数据的尺寸,这里的inputs是一个numpy.ndarray, shape[0]表示行数,shape[1]列数,shape[2]是最后一维的数# 在第一层必须要制定尺寸# ===============================================================================================================model.add(LSTM(neurons, return_sequences=True, input_shape=(inputs.shape[1], inputs.shape[2]),activation=activation_function))model.add(Dropout(dropout)) # 加入Dropout提高模型的健壮性,第一层model.add(LSTM(neurons, return_sequences=True, activation=activation_function))model.add(Dropout(dropout)) # 第二层model.add(LSTM(neurons, activation=activation_function))model.add(Dropout(dropout)) # 第三层model.add(Dense(units=output_size)) # Dense:用于输出预测的全连接层.model.add(Activation(activation_function))model.compile(loss=loss, optimizer=optimizer, metrics=['mae']) # 在训练模型之前需要配置学习过程,通过compile方法完成# model.summary() # 总结一下模型有什么,在打印的时候可以看到,非建模必需环节return modeldef show_plot(data, tag):fig, (ax1, ax2) = plt.subplots(2, 1, gridspec_kw={'height_ratios': [3, 1]})ax1.set_ylabel('Closing Price ($)', fontsize=12)ax2.set_ylabel('Volume ($ bn)', fontsize=12)ax2.set_yticks([int('%d000000000' % i) for i in range(10)])ax2.set_yticklabels(range(10))ax1.set_xticks([datetime.date(i, j, 1) for i in range(2013, 2019) for j in [1, 7]])ax1.set_xticklabels('')ax2.set_xticks([datetime.date(i, j, 1) for i in range(2013, 2019) for j in [1, 7]])ax2.set_xticklabels([datetime.date(i, j, 1).strftime('%b %Y') for i in range(2013, 2019) for j in [1, 7]])ax1.plot(data['Date'].astype(datetime.datetime), data[tag + '_Open*'])ax2.bar(data['Date'].astype(datetime.datetime).values, data[tag + '_Volume'].values)fig.tight_layout()plt.show()def date_labels():last_date = market_data.iloc[0, 0]date_list = [last_date - datetime.timedelta(days=x) for x in range(len(X_test))]return [date.strftime('%m/%d/%Y') for date in date_list][::-1]def plot_results(history, model, Y_target, coin):plt.figure(figsize=(25, 20))plt.subplot(311)plt.plot(history.epoch, history.history['loss'], )plt.plot(history.epoch, history.history['val_loss'])plt.xlabel('Number of Epochs')plt.ylabel('Loss')plt.title(coin + ' Model Loss')plt.legend(['Training', 'Test'])plt.subplot(312)plt.plot(Y_target)plt.plot(model.predict(X_train))plt.xlabel('Dates')plt.ylabel('Price')plt.title(coin + ' Single Point Price Prediction on Training Set')plt.legend(['Actual', 'Predicted'])ax1 = plt.subplot(313)plt.plot(test_set[coin + '_Close**'][windows:].values.tolist())plt.plot(((np.transpose(model.predict(X_test)) + 1) * test_set[coin + '_Close**'].values[:-windows])[0])plt.xlabel('Dates')plt.ylabel('Price')plt.title(coin + ' Single Point Price Prediction on Test Set')plt.legend(['Actual', 'Predicted'])date_list = date_labels()ax1.set_xticks([x for x in range(len(date_list))])for label in ax1.set_xticklabels([date for date in date_list], rotation='vertical')[::2]:label.set_visible(False)plt.show()btc_data = get_market_data("bitcoin", tag='BTC')eth_data = get_market_data("ethereum", tag='ETH')market_data = merge_data(btc_data, eth_data)model_data = create_model_data(market_data)train_set, test_set = split_data(model_data)train_set = train_set.drop('Date', 1) # 删除Data这列test_set = test_set.drop('Date', 1)X_train = create_inputs(train_set) # 返回的是listY_train_btc = create_outputs(train_set, coin='BTC')Y_train_eth = create_outputs(train_set, coin='ETH')X_test = create_inputs(test_set)Y_test_btc = create_outputs(test_set, coin='BTC')Y_test_eth = create_outputs(test_set, coin='ETH')X_train, X_test = to_array(X_train), to_array(X_test) # 将list转化为数组gc.collect() # 清理内存np.random.seed(202)btc_model = build_model(X_train)# ==================================================================================================================# 1.fit:模型训练# 2.epoch:迭代次数,1个epoch等于使用训练集中的全部样本训练一次# 3.batch_size: 每次训练中取batchsize个样本训练# 4.verbose:日志显示,verbose=0为不在标准输出流输出日志信息,verbose=1为输出进度条记录# 5.validation_data:用于评估每个epoch结束时的损失# 6.shuffle:是否在每个epoch调整训练数据# ==================================================================================================================btc_history = btc_model.fit(X_train, Y_train_btc, epochs=epochs, batch_size=batch_size, verbose=1,validation_data=(X_test, Y_test_btc), shuffle=False)plot_results(btc_history, btc_model, Y_train_btc, coin='BTC')gc.collect()np.random.seed(202)eth_model = build_model(X_train)eth_history = eth_model.fit(X_train, Y_train_eth, epochs=epochs, batch_size=batch_size, verbose=1,validation_data=(X_test, Y_test_eth), shuffle=False)plot_results(eth_history, eth_model, Y_train_eth, coin='ETH')
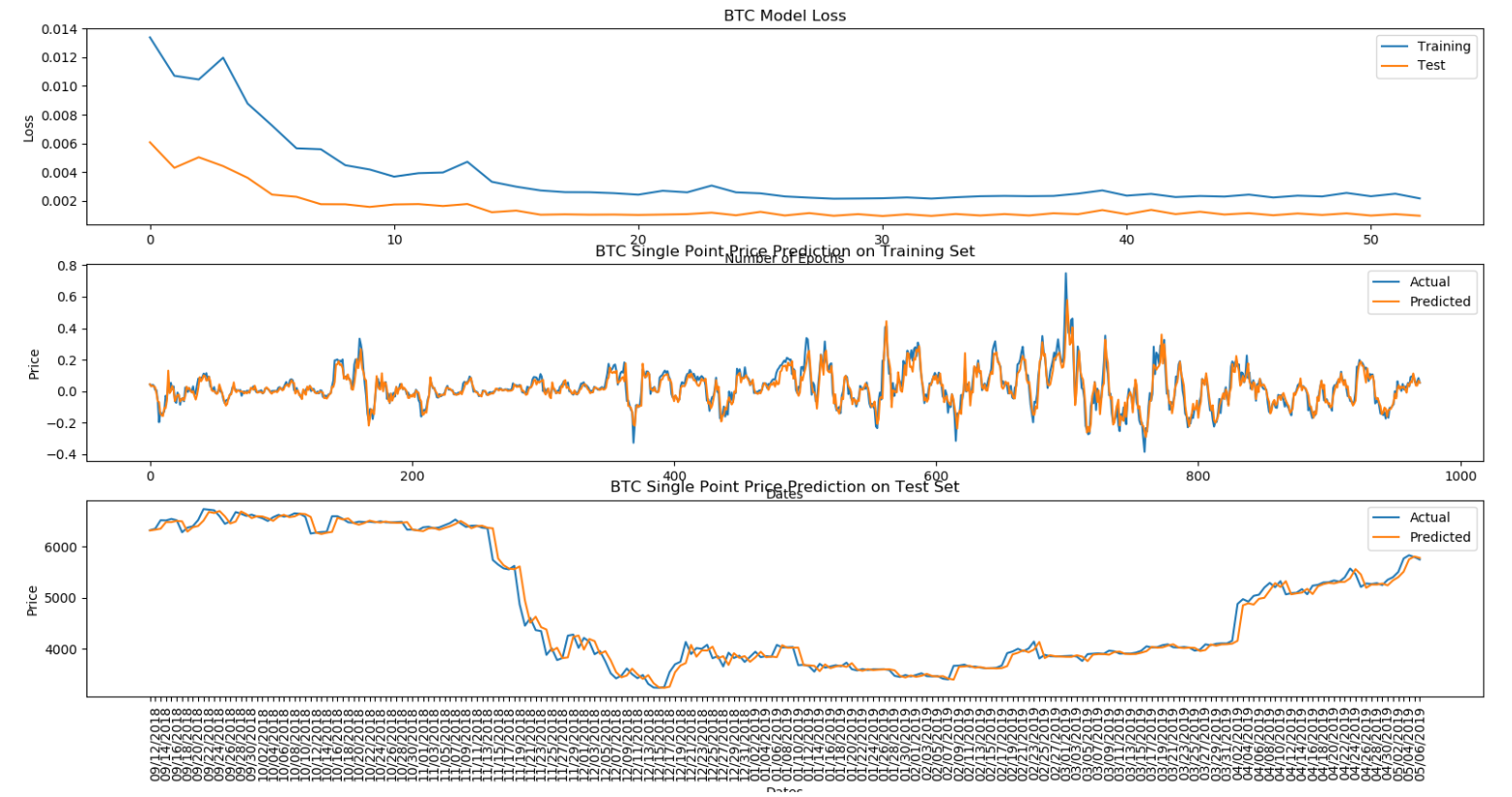
注1:本文选自这里
注2:由于是直接从比特币官网取的数据,跟着作者的代码顺序进行数据预处理花费了一整天的时间,有点划不来,后面在学习其他算法的时候最好还是减少这种代码,最好是在官网直接找到代码示例
注3:本文的代码注释并不好,之前对LSTM的理解不够深刻,如果想参考代码,重点看循环神经网络中的代码。
(2)Keras官网示例
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
data_dim = 16
timesteps = 8
num_classes = 10
# expected input data shape: (batch_size, timesteps, data_dim)
model = Sequential()
model.add(LSTM(32, return_sequences=True,
input_shape=(timesteps, data_dim))) # returns a sequence of vectors of dimension 32
model.add(LSTM(32, return_sequences=True)) # returns a sequence of vectors of dimension 32
model.add(LSTM(32)) # return a single vector of dimension 32
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# Generate dummy training data
x_train = np.random.random((1000, timesteps, data_dim))
y_train = np.random.random((1000, num_classes))
# Generate dummy validation data
x_val = np.random.random((100, timesteps, data_dim))
y_val = np.random.random((100, num_classes))
model.fit(x_train, y_train,
batch_size=64, epochs=5,
validation_data=(x_val, y_val))

若有收获,就点个赞吧
0 人点赞
