1.从最简单的实例开始
神经网络(Convolutional Neural Networks, CNN),现在要训练一个最简单的CNN,用来识别一张 
貌似很简单,但并不是所有的X都长这样,比如

图片在计算机内部以像素值的方式被存储,也就是说两张X在计算机看来,其实是这样子的
对比这两种图片,它们有共同点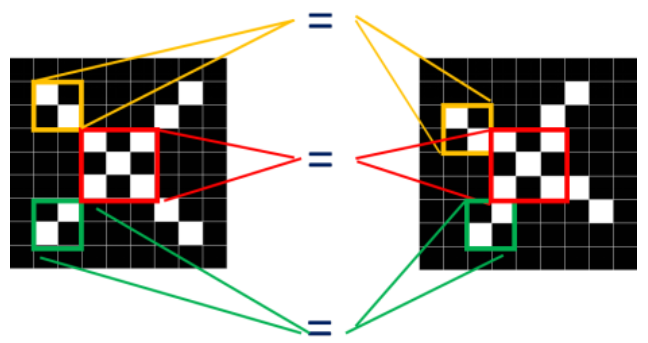
两张图中三个同色区域的结构完全一致,因此我们可以考虑将这两张图联系起来进行局部匹配,相当于要用CNN找一张人脸,只需要让CNN知道人脸的三个特征:眼睛、鼻子和嘴巴是什么样的,让它用这三个特征去找人脸。
2.卷积神经网络的运算过程
(1)从标准图中提取出特征
从上面的标准X中提取出是哪个特征,分别是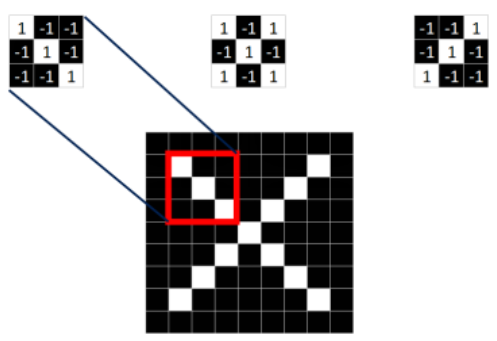
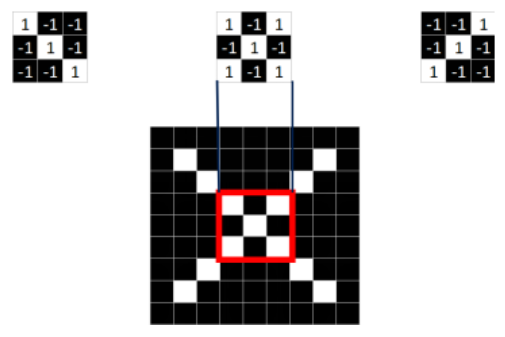
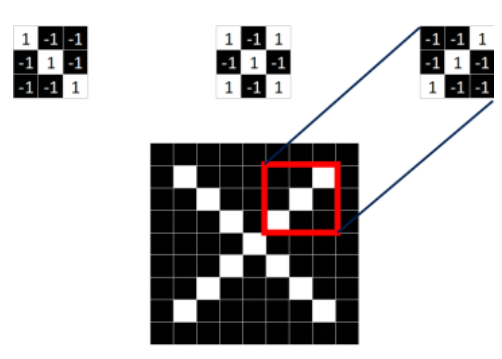
这三个feature可定位到X的某个局部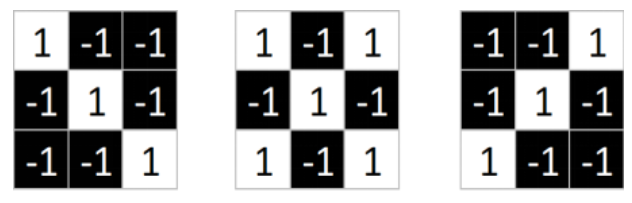
(2)计算特征图
拿第一个特征来说,它和标准的X图分别示意如下
然后对应位置相乘,首先来计算左上角的9个点,相乘的结果为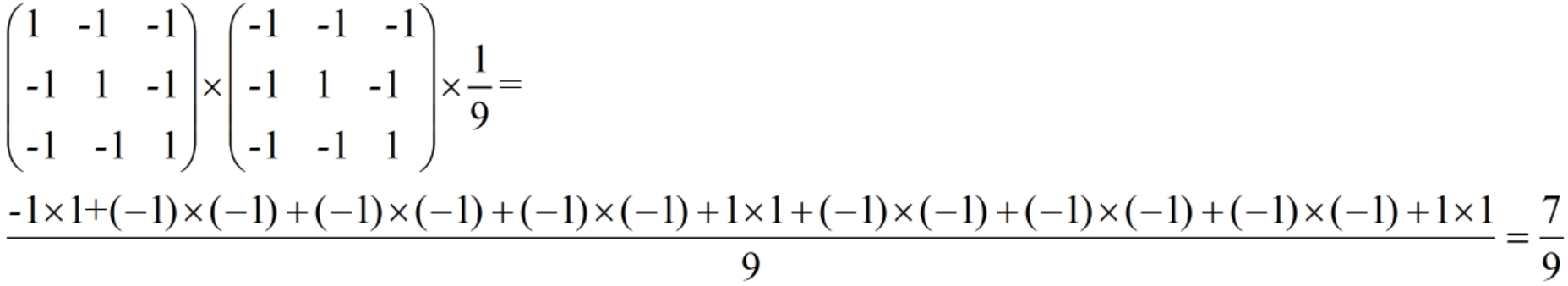
将这个值写在左上角,然后向右滑动一格,计算下一个值…..第一行全部计算完之后,就转到第二行,这样可以计算全部所有的结果,结果如下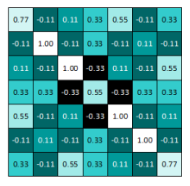
同理我们可以计算第二个特征和第三个特征的全部结果,结果如下

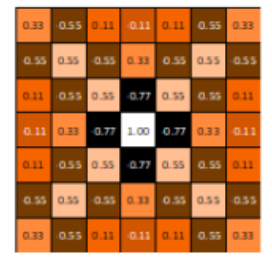
这三张图称之为特征图(feature map),它是每一个feature从原始图像中提取出来的“特征”。其中的值,越接近为1表示对应位置和feature的匹配越完整,越是接近-1,表示对应位置和feature的反面匹配越完整,而值接近0的表示对应位置没有任何匹配或者说没有什么关联。
(3)非线性激活层
非线性激活层比较简单,采用的是Relu函数,它的公式为f(x)=max(0,x),即保留大于等于0的值,其余所有小于0的数值直接改写为0。以第一个为例,得到的结果为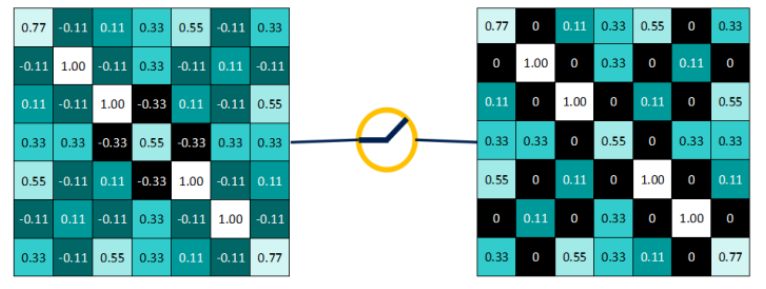
(4)pooling池化层
卷积操作后的feature map ,尽管数据量比原图少了很多,接下来就需要池化操作来减少数据量了。池化分为两种,Max Pooling 最大池化、Average Pooling平均池化。顾名思义,最大池化就是取最大值,平均池化就是取平均值。拿最大池化举例:选择池化尺寸为2x2,因为选定一个2x2的窗口,在其内选出最大值更新进新的feature map。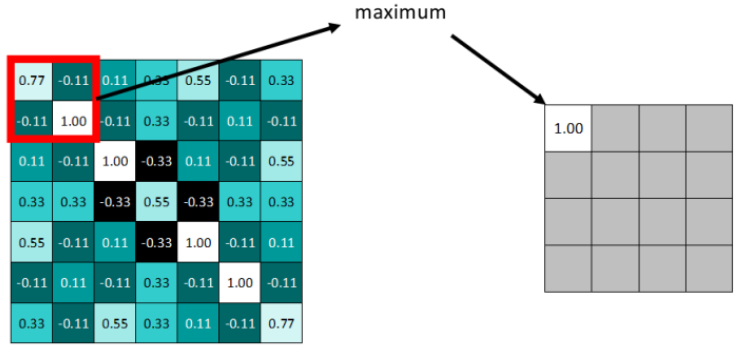
向右依据步长滑动窗口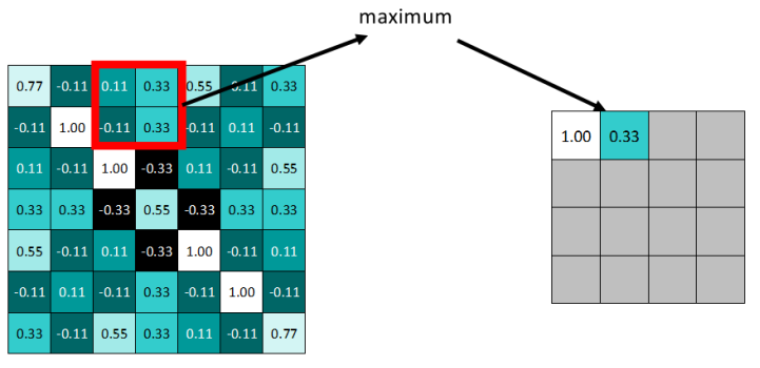

池化操作后数据量减少了很多,最大池化保留了每一个小块内的最大值,所以它相当于保留了这一块最佳匹配结果。值得注意的是,在卷积神经网络中,卷积层、Relu层、池化层这三个是交替使用的,将前一层的输入作为后一层的输出。比如: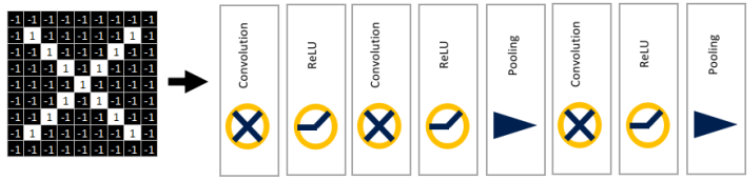
这样一顿操作之后,原始的9×9图片被压缩为2X2的三张特征图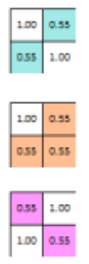
以上,选自卷积神经网络CNN完全指南终极版(一)
(5)全连接层
这一层稍微有点麻烦,看的是另外一篇文章。在这篇文章中,经过卷积、ReLU和max pooling 一顿操作后,有了如下的一个3×3×5的输出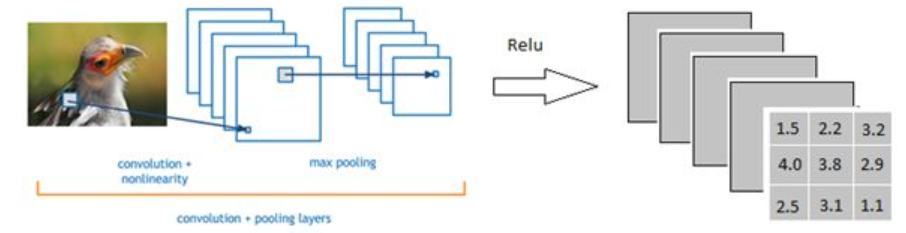
全连接层要做的是,将这个3×3×5的输出转换成1x4096的形式,全连接层到底是怎么样的呢?
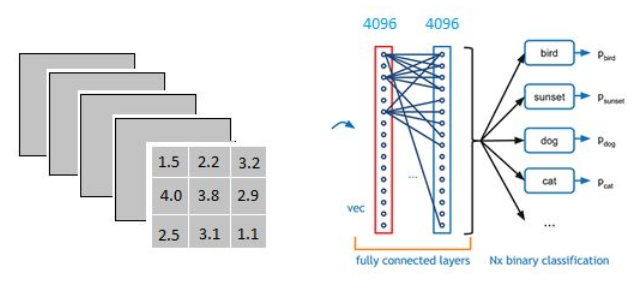
全连接层中的每一层是由许多神经元组成的(1x 4096)的平铺结构,上图不明显,我们看下图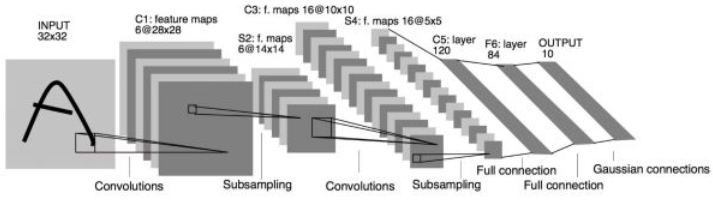
在这里的全连接层可以看做是一个3x3x5x4096的filter,首先对一个3x3x5的filter去卷积激活函数的输出,得到的结果就是一个神经元的输出,这个输出就是一个值。注意这个值和下图中右上角的值还需要经过一个Softmax函数来对应,右上角第一个值=Softmax(sum)
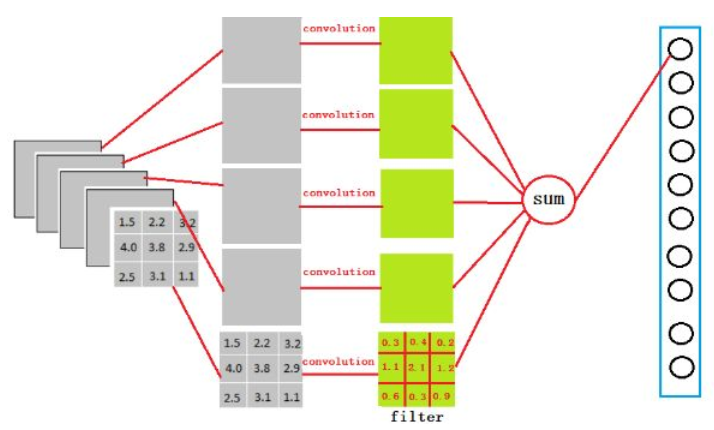<br />由于全连接层共有4096个神经元,因此可以得到4096个输出。怎么理解这里的filter呢?它相当于是一个初始化参数,后面经过计算loss之后,会对这个初始化参数进行更新。经过前面一系列的操作之后,得到了1x4096这个输出,它的作用是什么呢?假设我们现在要对一个位置的图片进行分类,它要么是X,要么是O,在下图中的这一列数字表示图片是X的概率,在第一个是X的概率为0.9,那么是O的概率就是0.1,对应到X的黄色线条比对应到O的绿色线条要粗很多很多。<br />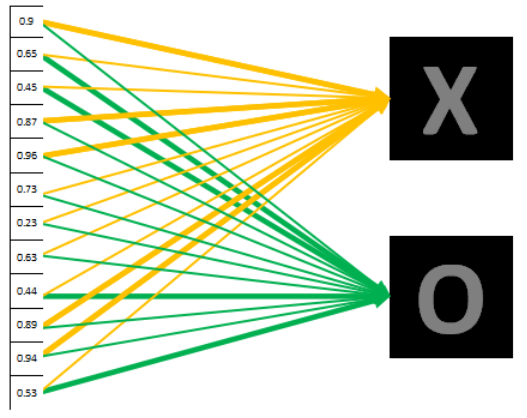<br />我们可以得到这个图是X和是O的概率,分别如下<br /> 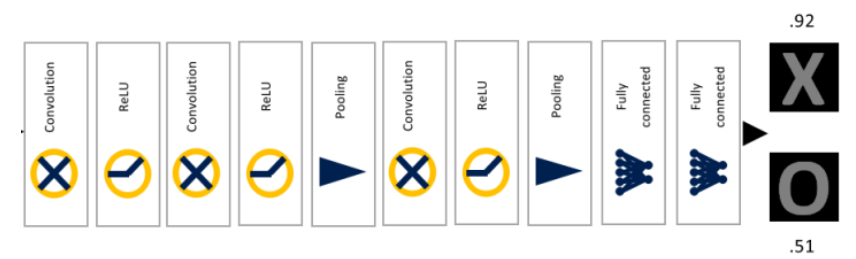<br />是X的概率为0.92,是O的概率为0.52,将其判定为X.
3.用pytorch实现CNN
(1)MNIST手写数据
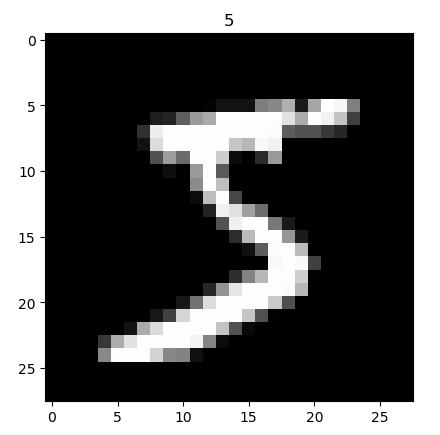
MNIST是深度学习的经典入门demo,它是由6万张训练图片和1万张测试图片构成的,每张图片都是28*28大小(如下图),而且都是黑白色构成(这里的黑色是一个0-1的浮点数,黑色越深表示数值越靠近1),这些图片是采集的不同的人手写从0到9的数字。
(2)pytorch简介
PyTorch 是一个基于 Python 的科学计算包,基于torch,PyTorch主要有两大特征:(1)如NumPy的张量计算,但使用GPU加速 (2)基于带基自动微分系统的深度神经网络。pytorch的一些资源
1.pytorch讨论的论坛
2.知乎pytorch讨论页
3.知乎:新手如何入门pytorch?
(3)代码部分
import osimport torchimport torch.nn as nnfrom torch.utils.data import DataLoaderimport torchvisionimport matplotlib.pyplot as pltfrom matplotlib import cmEPOCH = 1 # 1个epoch等于使用训练集中的全部样本训练一次,通俗的讲epoch的值就是整个数据集被轮几次BATCH_SIZE = 50 # 可以理解为批处理参数,它的极限值为训练集样本总数,当数据量比较少时,可以将batch_size值设置为全数据集LR = 0.001 # learning rate"""MNIST是深度学习的入门demo,由6万张训练图片和1万张测试图片构成,每张图片都是28*28大小而且都是黑白色构成(这里的黑色是一个0-1的浮点数,黑色越深表示数值越靠近1),这些图片是采集的不同的人手写从0到9的数字"""DOWNLOAD_MNIST = False # 下载MNIST的默认值是不下载,当检测到没有/mnist路径时,开始下载if not(os.path.exists('./mnist/')) or not os.listdir('./mnist/'):DOWNLOAD_MNIST = Truetrain_data = torchvision.datasets.MNIST( # 官方文档:https://pypi.org/project/torchvision/0.1.8/#mnistroot='./mnist/', # 保存或者提取位置train=True, # train参数为True时,取训练数据,False取预测数据transform=torchvision.transforms.ToTensor(), # 对图片格式进行转换download=DOWNLOAD_MNIST, # 是否下载MNIST数据集)print(train_data.train_data.size()) # (60000, 28, 28)print(train_data.train_labels.size()) # 600, train_label就是这些图写的数字,一共600张图plt.imshow(train_data.train_data[0].numpy(), cmap='gray') # 将第一张图显示出来,plt.imshow():将一个image显示在二维坐标轴上plt.title('%i' % train_data.train_labels[0]) # title为这个图的数字plt.show()
train_loader = DataLoader(dataset=train_data, # 要导入的数据集batch_size=BATCH_SIZE, # 每次导入的batch数量shuffle=True # 如果是True的话,数据每次都重新洗牌)test_data = torchvision.datasets.MNIST(root='./mnist/',train=False # 前面介绍过, 为False的时候取测试数据)"""1.这个地方test_data.test_data和train_data.test_data有什么不同,暂时不纠结,知道这是测试数据就行2.unsqueeze()在dim维插入一个维度为1的维,例如原来x是n×m维的,torch.unqueeze(x,0)返回1×n×m的tensor"""unsqueezed_test_data = torch.unsqueeze(test_data.test_data, dim=1)# print(type(unsqueezed_test_data)) >>> torch.Tensortest_x = unsqueezed_test_data.type(torch.FloatTensor)[:2000]/255. # 测试前2000个数据# print(test_x.size()) >>> torch.Size([2000, 1, 28, 28])test_y = test_data.test_labels[:2000]class CNN(nn.Module): # 所有神经网络模块的基类,你的模型也应该继承这个类def __init__(self):super(CNN, self).__init__() # 调用CNN父类的__init__方法,它的父类就是括号里面的nn.Module"""torch.nn.Sequential是一个Sequential容器,模块将按照构造函数中传递的顺序添加到模块中一个简单理解就是卷积神经网络里的卷积层、激活层、池化层按照顺序传递"""self.conv1 = nn.Sequential(nn.Conv2d( # 对由多个输入平面组成的输入信号进行二维卷积,输入的size是1*28*28# in_channels和out_channels看https://blog.csdn.net/sscc_learning/article/details/79814146#commentseditin_channels=1,out_channels=16,kernel_size=5, # 卷积内核的大小,数字只有一个长宽相等, 5*5;数字有两个则表示长宽,比如kernel_size=(3,2)stride=1, # 卷积核滑动的步长# padding用来对输入进行补0,数字只有一个时,上下各补同样的个数,有两个参数时分别表示高度和宽度上面的padding# 具体可以看https://blog.csdn.net/g11d111/article/details/82665265padding=2,), # 由于out_channels是16,这里的输出是16*28*28# 值得注意的是kernel_size由于是5*5,但是后面有padding补0的操作,所以不影响nn.ReLU(), # 非线性激活层不影响size,仍旧是16*28*28nn.MaxPool2d(kernel_size=2), # 卷积内核的大小,数字只有一个长宽相等,2*2.# 由于kernel_size是2*2的,操作完成后会减少一半,此时的size是16*14*14)self.conv2 = nn.Sequential( # 输入是第一层的输入,size是16*14*14nn.Conv2d(16, 32, 5, 1, 2), # out_channels=32,size是32*14*14nn.ReLU(),nn.MaxPool2d(2), # 同上,size是32*7*7)"""1.全连接函数为线性函数:y = Wx + b,并将32*7*7个节点连接到120个节点上2.这里为什么是32*7*7呢?前面每一步都已经分析了3.10是因为0~9一共有10个数字"""self.out = nn.Linear(32 * 7 * 7, 10)"""1.forward起的作用相当于把conv1,conv2和全连接层给联系起来2.执行顺序:(1)在类外面实例化类CNN(2)执行类的__init__函数(3)实例对象(例如下面的cnn)传入参数x(4)执行forward函数"""def forward(self, x):x = self.conv1(x)x = self.conv2(x)"""a=torch.Tensor([[[1,2,3],[4,5,6]]])print(a.view(3,2))>>>tensor([[1., 2.],[3., 4.],[5., 6.]])当为-1时,就代表这个位置由其他位置的数字来推断"""x = x.view(x.size(0), -1)out_put = self.out(x)print(out_put.size())return out_put, xtry:from sklearn.manifold import TSNEHAS_SK = Trueexcept:HAS_SK = Falseprint('Please install sklearn for layer visualization')def plot_with_labels(low_weights, label):plt.cla()input_x, output_y = low_weights[:, 0], low_weights[:, 1]for x, y, s in zip(input_x, output_y, label):c = cm.rainbow(int(255 * s / 9))plt.text(x, y, s, backgroundcolor=c, fontsize=9)plt.xlim(input_x.min(), input_x.max())plt.ylim(output_y.min(), output_y.max())plt.title('Visualize last layer')plt.show()plt.pause(0.01)plt.ion()cnn = CNN() # 实例化,此时还没有传入参数,不执行forward函数"""1.torch.optim是一个实现了多种优化算法的包2.这个语句要表达的意义是cnn.parameters()是要优化的对象,LR是步长,Adam是采用随机梯度下降优化的算法"""optimizer = torch.optim.Adam(cnn.parameters(), lr=LR)loss_func = nn.CrossEntropyLoss() # 交叉熵损失函数,pytorch的一种损失函数,用于多分类for epoch in range(EPOCH): # range左开右闭,这里epoch的取值只有一个:0"""1.enumerate:将一个可遍历的数据对象组合为一个索引序列, 同时列出数据和数据下标.seq = ['one', 'two', 'three']for i, element in enumerate(seq):print i, element>>>0 one1 two2 three2.这里step就是索引0,1,2...而b_x和b_y分别表示输入和输出"""for step, (b_x, b_y) in enumerate(train_loader):"""1.训练之前,b_x的size是50*1*28*28, 暂时先不纠结这里为什么有个1, 前面in_channels的维度2.b_x这个输入经过conv1之后变成50*16*28*28,经过conv2之后变成50*32*7*73.经过x = x.view(x.size(0), -1)变为50*15684.比较重要的就是这里的nn.Linear,它是一个全连接层,将1568->10(没有很懂),这一步之后输出就size变成50*10"""output = cnn(b_x)[0]loss = loss_func(output, b_y) # 预测和真实值之间的差值optimizer.zero_grad()loss.backward()optimizer.step()if step % 50 == 0:test_output, last_layer = cnn(test_x)pred_y = torch.max(test_output, 1)[1].data.numpy()accuracy = float((pred_y == test_y.data.numpy()).astype(int).sum()) / float(test_y.size(0))print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)if HAS_SK:tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)plot_only = 500low_dim_embs = tsne.fit_transform(last_layer.data.numpy()[:plot_only, :])labels = test_y.numpy()[:plot_only]plot_with_labels(low_dim_embs, labels)plt.ioff()test_output, _ = cnn(test_x[:10])pred_y = torch.max(test_output, 1)[1].data.numpy()print(pred_y, 'prediction number')print(test_y[:10].numpy(), 'real number')
代码部分选自https://morvanzhou.github.io/tutorials/machine-learning/torch/4-01-CNN/

若有收获,就点个赞吧
0 人点赞
