1.TensorFlow简介
TensorFlow是由谷歌公司开发的深度学习框架。为什么要用TensorFlow呢?TensorFlow被认定为神经网络中最好用的库之一,它擅长的任务就是训练深度神经网络,通过使用TensorFlow我们就可以快速的入门神经网络,大大降低了深度学习的开发成本和开发难度。此外,TensorFlow还有以下的这些优势。
(1)Python API
(2)可移植性:仅仅使用一个API就可以将计算任务部署到服务器或者PC的CPU或者GPU上
(3)灵活性:适用于诸如Linux,Cent OS,Windows等操作系统
(4)可视化(TensorBoard是一个黑科技)
(5)支持存储和恢复模型与图
(6)拥有庞大的社区支持
(7)现在很多有用的工作都是基于TensorFlow
2. 其他深度学习框架
(1)Theano
也是深度学习的一种框架,和TensorFlow完全是一种并列关系,目前由于TensorFlow发展迅速,Theano已停止更新
(2)PyTorch
PyTorch是Torch框架的表亲,Torch是基于lua语言开发的,PyTorch的出现并不是为了支持流行语言而对Torch进行简单的包装,它被重写和定制出来是为了得到更快的速度和本地化。
(3)Caffe
Caffe是一个清晰而高效的深度学习框架,Tensorflow出现之前一直是深度学习领域Github star最多的项目,主要优势为:上手容易,网络结构都是以配置文件形式定义,不需要用代码设计网络。训练速度快,组件模块化,可以方便的拓展到新的模型和学习任务上。但是Caffe最开始设计时的目标只针对于图像,没有考虑文本、语音或者时间序列的数据,因此Caffe对卷积神经网络的支持非常好,但是对于时间序列RNN,LSTM等支持的不是特别充分。
3.TensorFlow开发的库
(1)Keras
Keras其实就是和Keras的接口(Keras作为前端,TensorFlow或theano作为后端),Keras 已经被添加到TensorFlow 中,成为其默认的框架,为TensorFlow 提供更高级的API。如果不想了解TensorFlow 的细节,只需要模块化,那么Keras 是一个不错的选择。如果将TensorFlow比喻为编程界的Java ,那么Keras 就是编程界的Python。Keras作为TensorFlow 的高层封装,可以与TensorFlow 联合使用,用它很快速搭建原型。另外,Keras 兼容两种后端,即Theano 和TensorFlow,并且其接口形式和Torch 有几分相像。
(2)TFLearn
(3)TensorLayer
包含了 TensorFlow 官方所有深度学习教程的模块化实现,它的优点是速度最快,速度和完全用 TensorFlow 写的代码一样。
TensorLayer、TFLearn和Kerase在处理相同大小的MNIST时所花费的时间对比,TensorLayer速度比Keras快一倍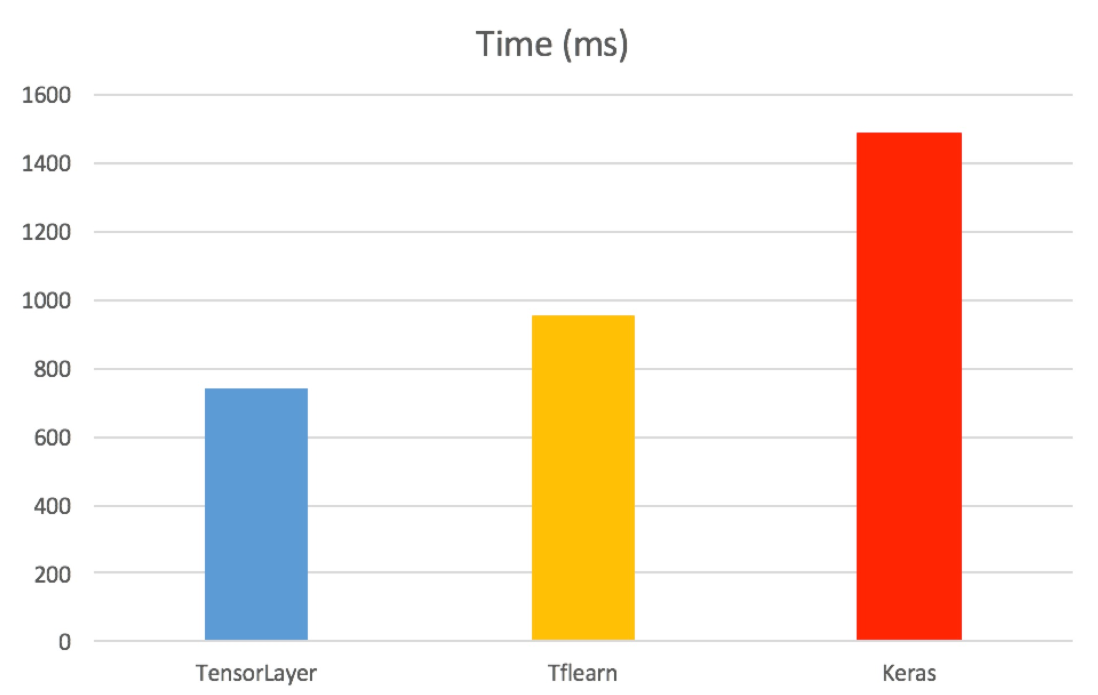
4.Tensorflow和Keras的安装
(1)安装Tensorflow:conda install tensorflow,用的是Anaconda3 5.0.0,对应的python是python3.6.2
(2)安装keras:conda install -c conda-forge keras tensorflow
碰到的问题
(1)安装keras出现的问题,ERROR conda.core.link:_execute_actions(337): An error occurred while installing package ‘,解决方法:这个博客下的评论
(2)安装了tensorflow和keras,但是不能调用tf.keras,原因是tensorflow的版本太低,pip install —upgrade —ignore-installed tensorflow
(3)更新tensorflow,出现的问题:TypeError: parse() got an unexpected keyword argument ‘transport_encoding’,解决方法:https://blog.csdn.net/lzw17750614592/article/details/85019330
4.由代码来了解tensorflow
# -*- coding: utf-8 -*-"""@author: Haojie Shu@time: 2019/04/28@description: tensorflow实现神经网络"""import tensorflow as tffrom numpy.random import RandomStatebatch_size = 8"""1.tf.random_normal([2, 3]生成一个2*3的矩阵,矩阵的标准差为1,均值为0(默认),seed=1表示每次生成的随机数都一样2.tf.Variable:变量的声明函数,通过创建Variable类的实例向graph中添加变量Variable()需要初始值,一旦初始值确定,那么该变量的类型和形状都确定了3.w1和w2都是神经网络的参数"""w1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))w2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))"""1.tf.placeholder:定义一个位置,这个位置中的数据在程序运行时再指定,这样程序就不需要生成大量的常量来输入数据,而只需要将数据通过placeholder传入tensorflow计算图2.placeholder的类型和其他张量一样,定义好了就不能修改"""x = tf.placeholder(tf.float32, shape=(None, 2), name="x-input")y_ = tf.placeholder(tf.float32, shape=(None, 1), name='y-input') # y_是真实值a = tf.matmul(x, w1)y = tf.matmul(a, w2) # tf.matmul:将矩阵a乘以矩阵b,生成a*b,前向传播的过程y = tf.sigmoid(y) # 这个地方其实就是一个神经网络的形式了,y是预测值# ===============================================================================================# 1.tf.log:计算TensorFlow的自然对数# 2.tf.clip_by_value(A, min, max):输入一个张量A,把A中的每一个元素的值都压缩在min和max之间# 小于min的让它等于min,大于max的元素的值等于max# 3.tf.reduce_mean:用于计算张量tensor沿着指定的数轴上的的平均值,主要用作降维或者计算tensor(图像)的平均值# 4.这句用来定义损失函数,这个损失函数叫交叉熵,是tensorflow中一种常见的损失函数,和神经网络中的损失函数# def mse_loss(y_true, y_pre):# return ((y_true - y_pre) ** 2).mean()# 不太一样# ===============================================================================================cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0))+ (1 - y_) * tf.log(tf.clip_by_value(1 - y, 1e-10, 1.0)))print('cross_entropy:', cross_entropy) # >>>cross_entropy: Tensor("Neg:0", shape=(), dtype=float32)# ===============================================================================================# 1. tf.train.AdamOptimizer:此函数是Adam优化算法,是一个寻找全局最优点的优化算法# 2. tf.train.Optimizer.minimize(loss), loss:最小化的目标# ===============================================================================================train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)rdm = RandomState(1) # 这里的1为随机数种子,只要随机数种子seed相同,产生的随机数系列就相同dataset_size = 128X = rdm.rand(128, 2)# ===============================================================================================# 1. 注意在算法中一般用Y来表示标签# 2. 这里所有的x1+x2 < 1视为正样本(比如零件合格),其他视为负样本(零件不合格),解决分类问题# ===============================================================================================Y = [[int(x1+x2 < 1)] for (x1, x2) in X]with tf.Session() as sess: # 创建一个回话init_op = tf.global_variables_initializer() # 初始化变量sess.run(init_op) # 使用创建号的回话来得到关心的运算的结果print('w1:', sess.run(w1))print('w2:', sess.run(w2))print("\n")STEPS = 5000for i in range(STEPS):start = (i * batch_size) % dataset_size # batch_size=8,dataset_size = 128,%表示取模,返回除法的余数end = (i * batch_size) % dataset_size + batch_size# ===============================================================================================# 1. sess.run()参数可以是list# 2. feed_dict:给使用placeholder创建出来的tensor赋值# ===============================================================================================sess.run([train_step, y, y_], feed_dict={x: X[start:end], y_: Y[start:end]})if i % 1000 == 0:total_cross_entropy = sess.run(cross_entropy, feed_dict={x: X, y_: Y})print("After %d training step(s), cross entropy on all data is %g" % (i, total_cross_entropy))print("\n")print(sess.run(w1))print(sess.run(w2))

若有收获,就点个赞吧
0 人点赞
