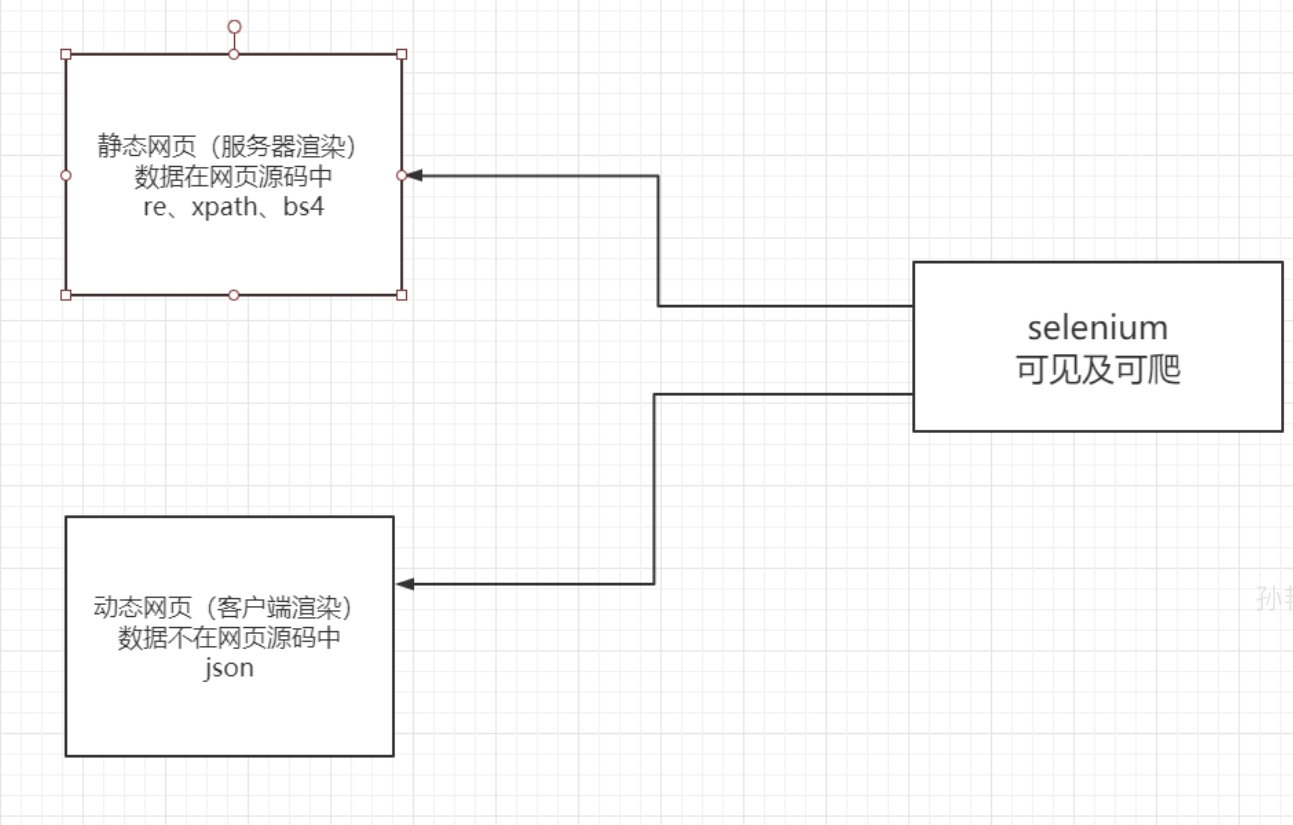
正则表达式的概述
在线正则表达式测试 https://tool.oschina.net/regex
概念
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个 “ 规则字符串”, 这个“ 规则字符串”用来表达对字符串的一种过滤逻辑。
为什么要学习正则?
正则的应用场景
- 表单验证(例如:手机号、邮箱、身份证)
- 爬虫
正则表达式入门
普通字符
字母、数字、汉字、下划线、以及没有特殊定义的符号,都是“普通字符”。正则表达式中的普通字符,在匹配的时候,只匹配与自身相同的一个字符。
例如:表达式c,在匹配字符串abcde时,匹配结果是成功。匹配的内容是c。匹配的位置开始于2,结束于3。(下标从0还是从1开始,因当前编程语言的不同而有所不同)
match()函数
re.match(pattern, string, flags=0):
- pattern: 正则表达式 也就是匹配模型
- string:待匹配的数据(网页源代码)
- flags=0 默认是0 标志位 用来控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
match会从头开始匹配,一旦匹配失败就直接结束了,匹配成功就返回第一个匹配的结果
元字符
正则表达式中使用了很多元字符,用来表示一些特殊的含义或功能
| 表达式 | 说明 |
|---|---|
| . | 匹配除换行符之外的任意一个字符 |
| | | 逻辑或操作符 |
| [] | 匹配字符集中的一个字符 |
| [^] | 对字符集求反,也就是上面操作的反操作。尖号必须在方括号里的最前面。 |
| \ | 对紧跟其后的一个字符进行转义 |
| - | 定义[]里的一个字符区间,例如[a-z] |
| () | 对表达式进行分组,将圆括号内的内容当做一个整体,并获得匹配的值 |
一些无法书写或者具有特殊功能的字符,采用在前面加斜杠””进行转义的方法: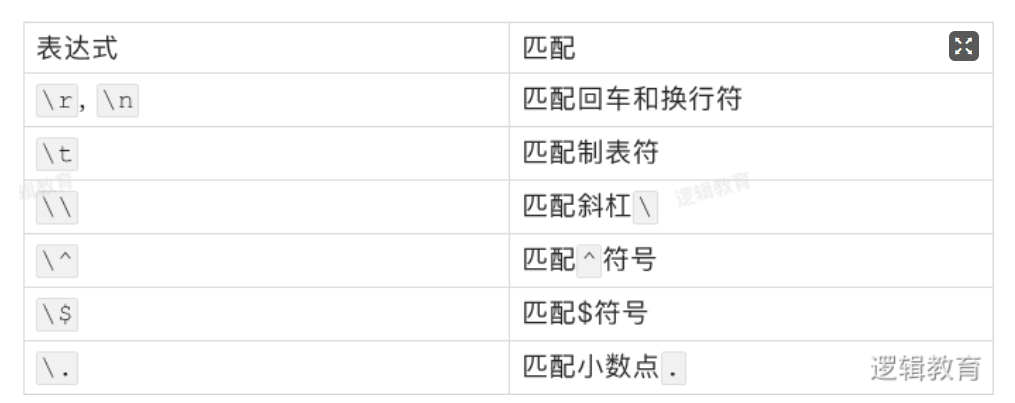
尚未列出的还有问号?、星号*和括号等其他的符号。所有正则表达式中具有特殊含义的字符在匹配自身的时候,都要使用斜杠进行转义。这些转义字符的匹配用法与普通字符类似,也是匹配与之相同的一个字符。
【拓展】r与转义 告诉python解释器不用再转义
r rawstring 原生字符串
- python解释器转义

- 正则转义
预定义匹配字符集
事先定义好的匹配字符的集合
正则表达式中的一些表示方法,可以同时匹配某个预定义字符集中的任意一个字符。比如,表达式\d可以匹配任意一个数字。虽然可以匹配其中任意字符,但是只能是一个,不是多个。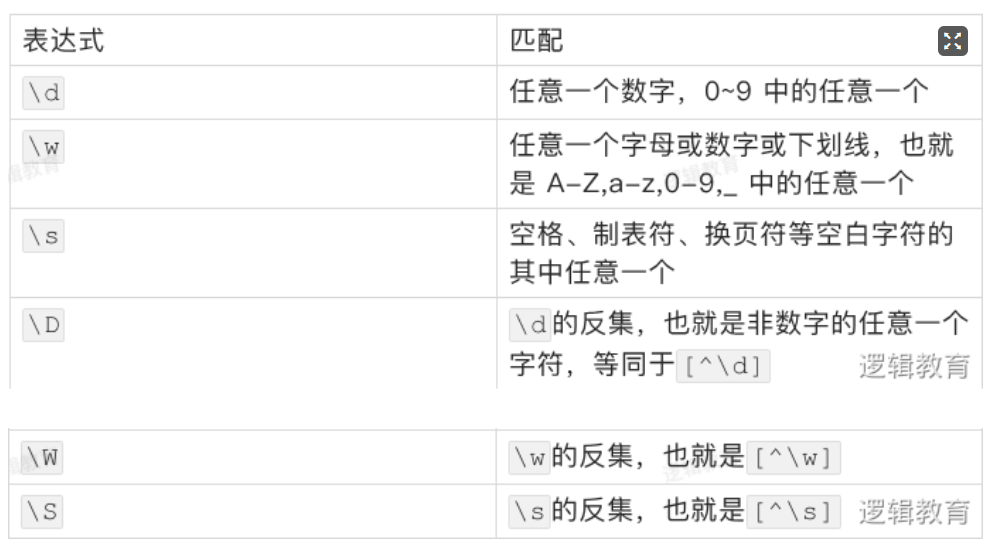
重复匹配
前面的表达式,无论是只能匹配一种字符的表达式,还是可以匹配多种字符其中任意一个的表达式,都只能匹配一次。但是有时候我们需要对某个字段进行重复匹配,例如手机号码136666666,一般的新手可能会写成\d\d\d\d\d\d\d\d\d\d\d(注意,这不是一个恰当的表达式),不但写着费劲,还不一定能准确恰当。这种情况可以使用表达式再加上修饰匹配次数的特殊符号{},不但重复书写表达式就可以重复匹配。例如[abcd][abcd]可以写成[abcd]{2}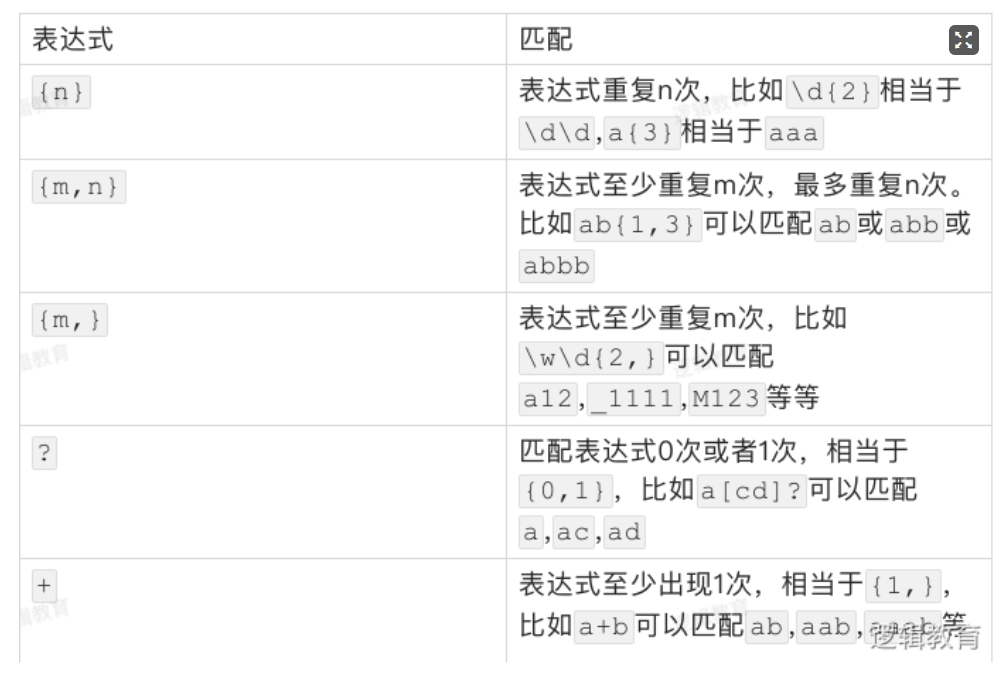

位置匹配和非贪婪匹配
位置匹配
有时候,我们对匹配出现的位置有要求,比如开头、结尾、单词之间等等。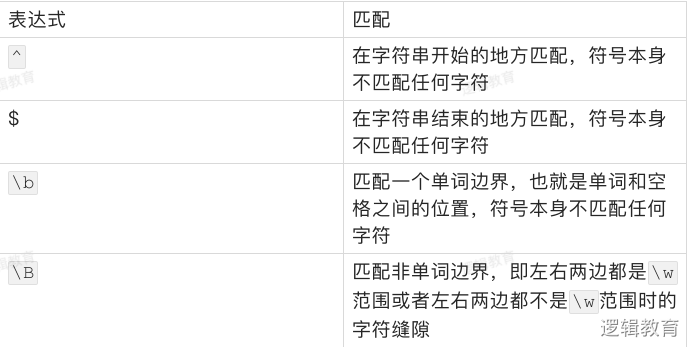
贪婪匹配与非贪婪匹配
在重复匹配时,正则表达式默认总是尽可能多的匹配,这被称为贪婪匹配。例如,针对文本dxxdxxxd,表达式(d)(\w+)(d)中的\w+将匹配第一个d和最后一个d之间的所有字符xxdxxxd。可见,\w在匹配的时候,总是尽可能多得匹配符合它规则的字符。同理,带有?、和{m,n}的重复匹配表达式都是尽可能地多匹配。
校验数字的相关表达式: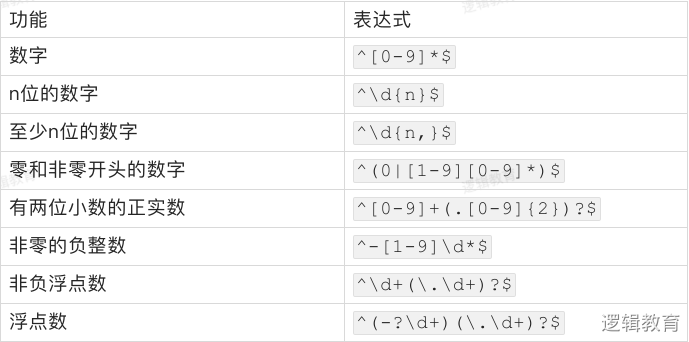
*特殊场景的表达式: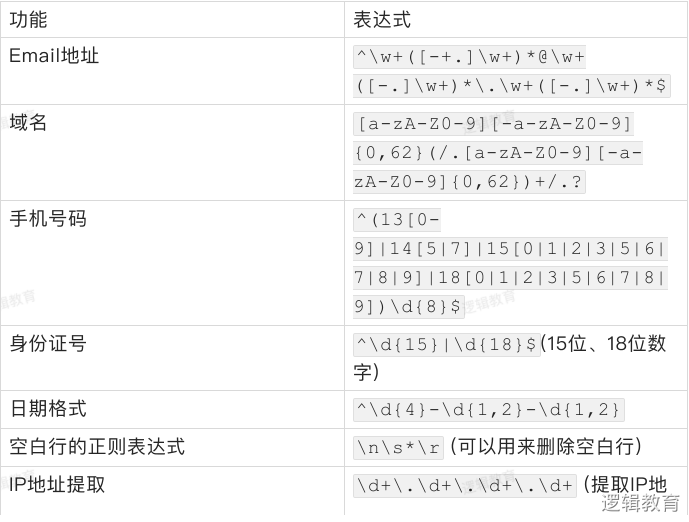
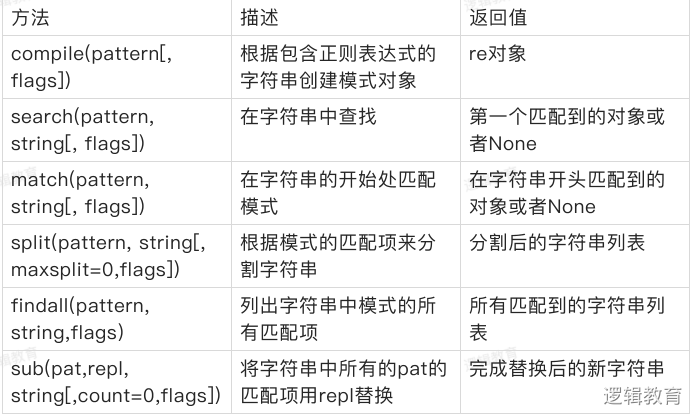
re模块常用方法
高阶函数:以函数对象作为返回值;以函数对象作为参数传递
闭包 数据更加的安全
complie(pattern,flag=0)
这个方法是re模块的工厂法,用于将字符串形式的正则表达式编译为Pattern模式对象,可以实现更加效率的匹配。第二个参数flag是匹配模式,使用complie()完成一次转换后,再次使用该匹配模式的时候就不能进行转换了。经过complie()转换的正则表达式对象也能使用普通的re方法。result=re.compile(r'abc')result.match('abc123').group()
flag匹配模式
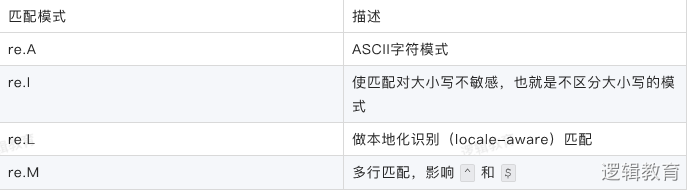
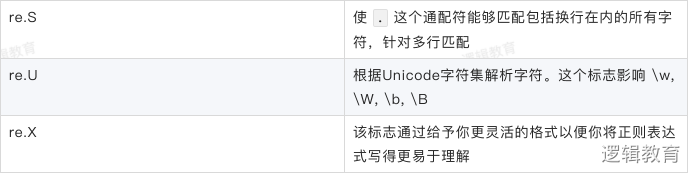
search(pattern,string,flag=0)
在文本内查找,返回第一个匹配到的字符串。它的返回值类型和使用方法与match()是一样的,唯一的区别就是查找的位置不用固定在文本的开头。
findall(pattern,string,flag=0)
作为re模块的三大搜索函数之一,findall()和match()、search()的不同之处,前两者都是单值匹配。找到一个就忽略后面,直接返回不再查找。findall是全文查找,它的返回值是一个匹配到的字符串的列表。这个列表没有group()方法,没有start、end、span、更不是一个匹配对象,仅仅是一个列表,如果一项没有匹配到那么久返回一个空列表。
split(pattern,string,,maxsplit=0,flag=0)
re模块的split()方法和字符串的split()方法很相似,都是利用特定的字符去分隔字符串。但是re模块的split()可以使用正则表达式,因此更灵活,更强大。
split有个参数maxsplit,用于指定分割的次数。
sub(pattern,repl,string,count=0,flag=0)
sub()方法类似字符串的replace()方法,用指定的内容替换匹配到的字符,可以指定替换次数。
s="i can't stand my poor python, i like python"
re.sub(r'i','I',s)
#输出结果"I can't stand my poor python, I lIke python"
分组功能
python的re模块有一个分组功能。所谓的分组就是将已经匹配的内容再筛选出需要的内容,相当于二次过滤。实现分组靠圆括号(),而获得分组的内容靠的是group()、groups()。re模块的几个重要方法在分组上,有不同的表现形式,需要区别对待。
import re
result=re.search(r'.*(\$\d+).*(\$\d+)',s)
print(result.group())
print(result.group(0))
print(result.group(1))
print(result.group(2))
print(result.groups())
'''
result.group()/result.group(0) 匹配整个分组
result.group(1) $22匹配第一个分组
result.group(2) $33匹配第二个分组
result.groups()/result.groups(0)('$22','$33')
'''

若有收获,就点个赞吧
0 人点赞
