预备知识
端口
每一个应用程序都有自己独立的标识,这个标识我们称之为端口,也叫做“逻辑端口”,网线的端口是“物理端口”。
MongoDB 端口号 27017
通信协议
- 国际组织定义了通用的通信协议TCP/IP协议
- 协议:双方之间要共同遵守。计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则。
- HTTP又称超文本传输协议(是一种通信协议) 端口号80
-
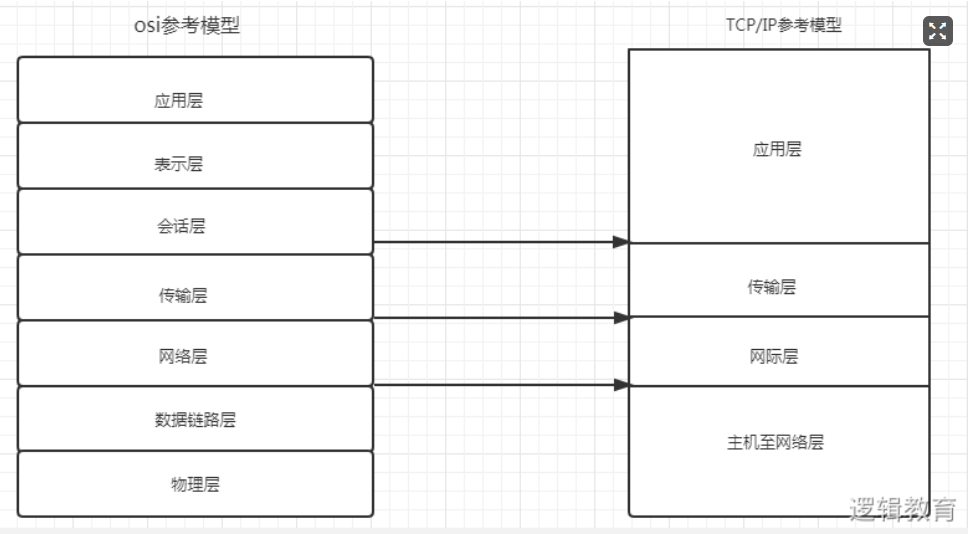
网络模型
TCP/IP参考模型
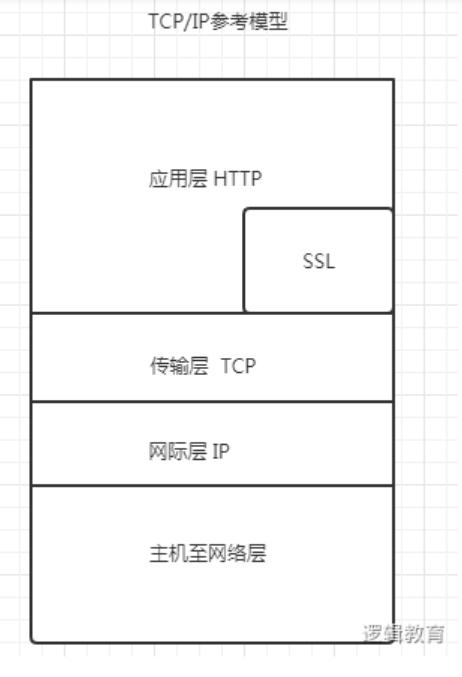
https=http+ssl,以安全为目标的http通道(是http的安全版本),是用于web的安全传输协议,端口443
https是http的安全版本 ssl是用于web的安全传输协议
http和ssl都是在应用层HTTP的请求与响应(很重要)
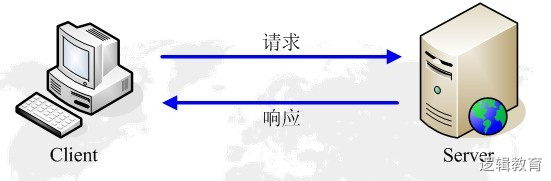
http通信由两部分组成:客户端请求消息与服务器响应消息
服务端渲染: 一次请求,服务器端整合,发送响应数据。能够在网页源码中看到数据
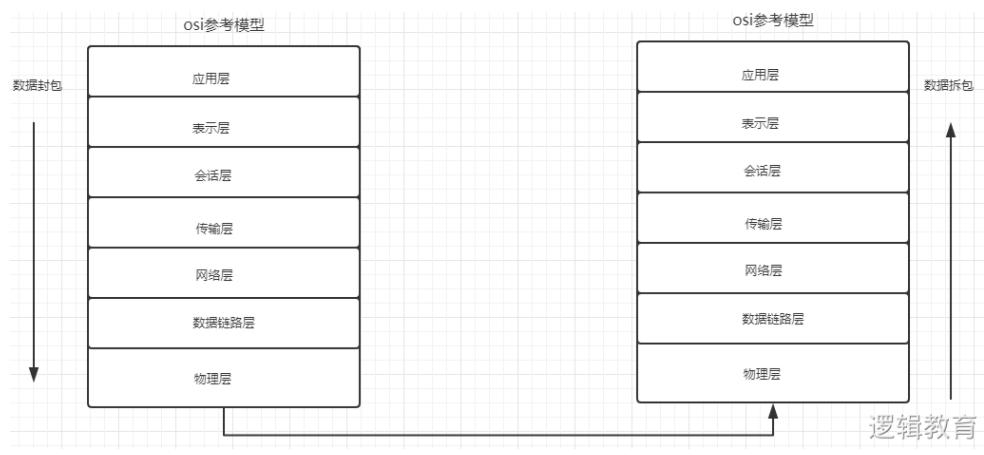
客户端渲染
二次请求,第一次只是响应框架,第二次需向服务器发送请求数据,服务器端再次响应
1.General
request url 请求的地址
- request method 请求的方式(一般我们看到是啥请求就是啥请求,get请求或post请求)
-
2.Request Headers(客户端请求头)
headers请求头={
请求方式 版本 (不加)
Host:www.baidu.com 域名(可加可不加)
Connection :keep-alive 长连接(不加)解决效率不高的问题
User-Agent:xxx 用户代理(操作系统、浏览器及版本等相关信息) 反反爬的第一步 加(重要)
Accept-Encoding:gzip, deflate, br(不加,加了数据可能会出现问题)
Cookie:xxx 记录了用户的相关信息(加不加看情况)一般是有时间限制的
Referer :页面跳转 你当前的页面是由哪个页面(url)跳转过来的 (加不加看情况)
}3.Response Headers(响应头)
4.Query String Parameters
爬虫简介
网络爬虫又叫网络蜘蛛,网络机器人
代替人模拟浏览器去访问和获取互联网信息的一个程序为什么需要爬虫?
为其他的程序提供数据源
- 数据分析
-
企业数据来源
企业自有数据
- 第三方数据平台(有免费也有收费的)
- 爬虫爬取的数据
python作爬虫的优势:
- python:支持模块多、代码简介、开发效率高(scrapy框架)
-
爬虫的分类
通用网络爬虫(各大搜索引擎 百度 谷歌。。。)
- 聚焦网络爬虫:在互联网上有选择有目的抓取特定的目标和相关主题内容
-
概念解析
1.get和post方法
get
特点:
一般情况下只从服务器获取数据,没有对服务器产生影响
-
post
特点:
对服务器产生影响
- 请求参数不会显示在url中,而是在form表单中,可以从Network-ALL-translate中找到
2.url(全球统一资源定位符)
https://new.qq.com/omn/TWF20200/TWF2020032502924000.html
https:网络协议
new.qq.com:理解为一台主机名叫new.qq.com,在qq.com域名下
omn/TWF20200/TWF2020032502924000.html 访问资源路径
3.User-Agent
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36
包含了操作系统和浏览器的版本
作用:记录操作系统和浏览器的相关信息,为了让用户更好地获取HTTP页面的效果,一般是反反爬的第一步(伪装)
4.Cookie
记录用户信息
在爬虫里面的作用:
- 反反爬(看情况)(referer记录了当前的页面是从哪个url过来的,也可作用于反反爬)
模拟登录(如果以VIP账户登录账号时,获取cookie信息,就可以模拟登录进而抓取视频)
5.状态码
当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含HTTP状态码的信息头(server header)用以响应浏览器的请求。
200—请求成功
- 301—资源(网页)被永久转移到其他url
- 403—被发现为爬虫程序(如果你的请求头都没有问题,但是请求不到数据或者说请求的数据有问题,这个时候你就去检查一下状态码)
- 404—请求的资源(网页)不存在
- 500—内部服务器错误
抓包工具(谷歌浏览器自带)
打开开发者工具:右击选中检查或者F12
- Elements 元素(网页源代码):用来提取和分析数据,可以用来分析页面结构(数据),不等于网页源码,只是作为辅助工具
- Console 控制台:后期分析js代码的时候,可以通过打印来找规律,
- Source 资源:信息的来源 整个网站加载的资源,分析js代码的时候使用,进行调试
- Network(很重要) 网络工作:数据抓包 服务器和客户端的交互记录都在network里面,客户端发起请求以及服务器返回响应在network里面都是可以找得到的
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36

若有收获,就点个赞吧
0 人点赞
