BeautufulSouo4基本概念
BeautifulSoup是一个可以从HTML或XML文件中提取数据的网页信息提取库
学习bs4的作用?
- 用来解析和提取数据 网页种类的增加,选择最合适的解析方式
- 对比学习不同的解析方式:
- 正则表达式:复杂
- xpath:找路径 记语法
- bs4 有多个方法find() find_all()
源码分析:
点pycharm下面的structure,出现视图导航
源码中的小图标
- c class 类
- m method 方法
- f filed 字段
- p property 装饰器
-
bs4入门
bs4的对象种类
tag:标签
- NavigableString:可导航的字符串
- BeautifulSoup:bs对象
- Comment:注释
遍历文档树 遍历子节点
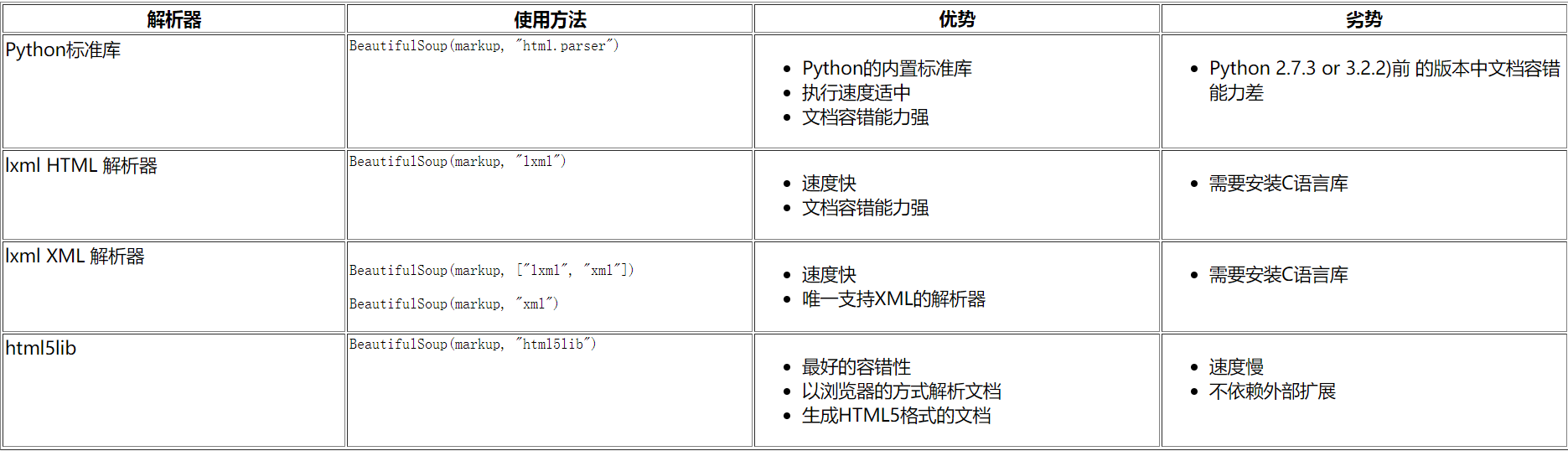
bs里面有三种情况,遍历、查找、修改
contents children descendants
- contents 返回的是 一个所有子节点的列表
- children 返回的是一个子节点的迭代器 可以通过遍历取出
- descendants 返回的是一个生成器遍历子子孙孙
string strings stripped_strings
parent和parents
- parent直接获得父节点
- parents 获取所有的父节点
遍历文档树 遍历兄弟结点
- next_sibling 下一个兄弟结点
- previous_sibling 上一个兄弟结点
- next_siblings 下一个所有兄弟结点
previous_siblings 上一个所有兄弟结点
s=soup.spanprint(s)print(s.next_sibling) #结果为空,换行也会被视为一个节点
搜索树
字符串过滤器
- 正则表达式过滤器(用正则表达式里面的compile方法编译一个正则表达式传给find或者findall这个方法,可以实现一个正则表达式的一个过滤器的搜索)
列表过滤器
#列表过滤器result=soup.find_all(['title','b'])print(result)
-
find_all()
find_all以列表形式返回所有的搜索到的标签数据
- find()方法返回搜索到的第一条数据
find_all()方法参数
def find_all(self, name=None, attrs={}, recursive=True, text=None,limit=None, **kwargs):
- name:tag名称
- attr:标签的属性
- recursive:是否递归搜索
- text:文本内容
- limit:限制返回条数
- kwargs:关键字参数
select()方法
我们也可以通过css选择器的方式来提取数据。但是需要注意的是这里面需要我们掌握css语法
https://www.w3school.com.cn/cssref/css_selectors.asp修改文档树
修改tag的名称和属性
- 修改string 属性赋值 就相当于用当前的内容替代了原来的内容
- append() 像tag中添加内容,及好像用python的列表的.append()方法
decompose()修改删除段落,对于一些没有必要的文章段落我们可以给它删除掉
bs4案例
需求:爬取所有城市的最低温 保存至csv文件
目标url:http://www.weather.com.cn/textFC/hb.shtml
页面分析:第一步class=”conMidtab”的div标签,存放当天的天气数据 用find
- 第二步 找到table标签 一个table标签对应一个表格,一个省或直辖市的天气数据
- 第三步 找到tr标签 过滤掉前两个tr标签(表头)
- 第四步 找到tr标签下的td标签 第一个td标签是城市名和倒数第二个td标签是最低温度
- 第五步 保存至csv
拓展
迭代器 生成器 可迭代对象
生成器是特殊的迭代器 next()
- 列表的推导式
- 函数的生成方式 yield
能够通过next()函数拿到下一个元素的就是迭代器
列表 元组 可迭代对象
通过iter把可迭代对象变成迭代器

若有收获,就点个赞吧
0 人点赞
