xpath的概念
x 不确定 path路径,就是一种可以根据路径找数据的技术
Xml Path Language,即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。可以说xpath是在xml文档中搜索内容的一门语言。
html vs xml vs lxml html 超文本标记语言 xml 可扩展标记语言,html是xml的子集 lxml 是python的第三方库。桥梁,它包含了将html文本转成xml对象,和对对象执行xpath的功能。
xml_content = '''<bookstore><book><title lang='eng'>Harry Potter</title><author>JK.Rowing</author><year>2005</year><price>29<price></book></bookstore>'''
xpath的应用场景(为什么学习?)
xpath入门
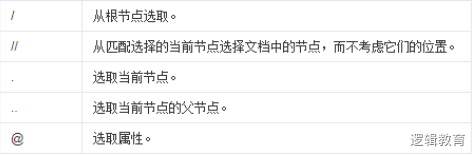
查找某个特定的节点或者包含某个指定的值的节点: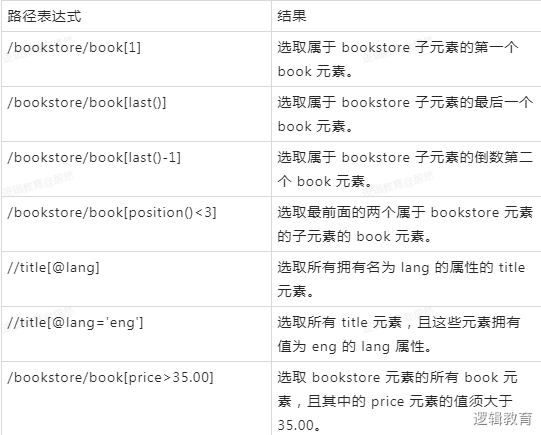
总结:
1、导入库 from lxml import etree 2、发请求 获响应 拿到网页源码(html) 3、tree = etree.HTML(html) 4、tree.xpath(‘’)
xpath案例—豆瓣
目标:熟悉xpath解析数据的方式
需求:标题、评分、评价人数、引言、详情页面url
目标url:https://movie.douban.com/top250
翻页处理
第一页:https://movie.douban.com/top250 025
第二页:https://movie.douban.com/top250?start=25&filter= 125
第三页:https://movie.douban.com/top250?start=50&filter= 225
第四页:https://movie.douban.com/top250?start=75&filter= 325
猜想第一页:https://movie.douban.com/top250?start=0&filter=
第i页:(i-1)25
start=(page-1)25
页面分析
静态加载每一条数据都放在li标签的class=”info”的div标签里面,再去class=”info”的div标签中解析数据
保存数据:[{‘title’:’xxx’,’score’:xxx’,’com_num’:’xxx’,’quote’:’xxx’,’link_url’:’xxx’}]
需要用到的工具:requests lxml csv
自己整理:
标题: //div[@class=”info”]/div[@class=”hd”]/a/span
评分://div[@class=”info”]//span[@class=”rating_num”]
评价人数://div[@class=”star”]//span[1] #暂定 修改(//div[@class=”bd”]/div[@class=”star”]/span[last()])
引言://span[@class=”inq”]
详情页面url: //div[@class=”hd”]/a/@href

若有收获,就点个赞吧
0 人点赞
