Netty 权威指南 Netty实战 笔记
一、I/O 基础
1.1 基础概念
1、阻塞 & 非阻塞
- 阻塞调用是指调用结果返回之前,当前线程会被挂起,调用线程只有在得到结果之后才会返回;
- 非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
两者的最大区别在于被调用方在收到请求到返回结果之前的这段时间内,调用方是否一直在等待。阻塞是指调用方一直在等待而且别的事情什么都不做;非阻塞是指调用方先去忙别的事情。
2、同步 & 异步
- 同步处理是指被调用方得到最终结果之后才返回给调用方;
- 异步处理是指被调用方先返回应答,然后再计算调用结果,计算完最终结果后再通知并返回给调用方。
阻塞、非阻塞和同步、异步的区别(阻塞、非阻塞和同步、异步其实针对的对象是不一样的):
- 阻塞、非阻塞的讨论对象是调用者;
-
3、recvfrom
recvfrom 函数(经 Socket 接收数据),这里把它视为系统调用。
一个输入操作通常包括两个不同的阶段: 等待数据准备好;
- 从内核向进程复制数据。
对于一个套接字上的输入操作,第一步通常涉及等待数据从网络中到达。当所等待分组到达时,它被复制到内核中的某个缓冲区。第二步就是把数据从内核缓冲区复制到应用进程缓冲区。
4、File Descriptor
Linux 对文件的读写操作会调用内核提供的系统命令,返回一个 file descriptor (fd,文件描述符)。而对一个 socket 的读写也会有相应的描述符,称为 socketfd(socket 描述符)。
描述符就是一个数字,指向内核中的一个结构体(文件路径、数据区等一些属性)。
1.2 Linux 网络 I/O 模型
1、阻塞 I/O 模型
Blocking I/O,最常用的 I/O 模型,缺省情况下文件操作都是阻塞的。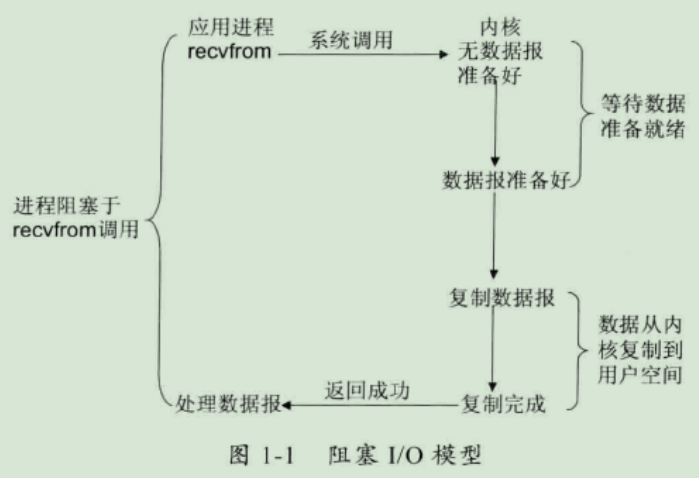
比喻:一个人在钓鱼,当没鱼上钩时,就坐在岸边一直等。
优点:程序简单,在阻塞等待数据期间进程/线程挂起,基本不会占用 CPU 资源。
缺点:每个连接需要独立的进程/线程单独处理,当并发请求量大时为了维护程序,内存、线程切换开销较大,这种模型在实际生产中很少使用
2、非阻塞 I/O 模型
在非阻塞式 I/O 模型中,应用程序把一个套接口设置为非阻塞,就是告诉内核,当所请求的 I/O 操作无法完成时,不要将进程睡眠。而是返回一个错误,应用程序基于 I/O 操作函数将不断的轮询数据是否已经准备好,如果没有准备好,继续轮询,直到数据准备好为止。
比喻:边钓鱼边玩手机,隔会再看看有没有鱼上钩,有的话就迅速拉杆。
优点:不会阻塞在内核的等待数据过程,每次发起的 I/O 请求可以立即返回,不用阻塞等待,实时性较好。
缺点:轮询将会不断地询问内核,这将占用大量的 CPU 时间,系统资源利用率较低,所以一般 Web 服务器不使用这种 I/O 模型。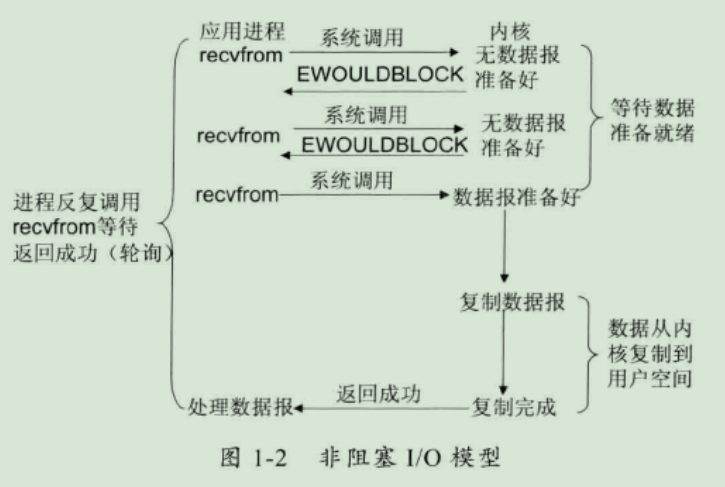
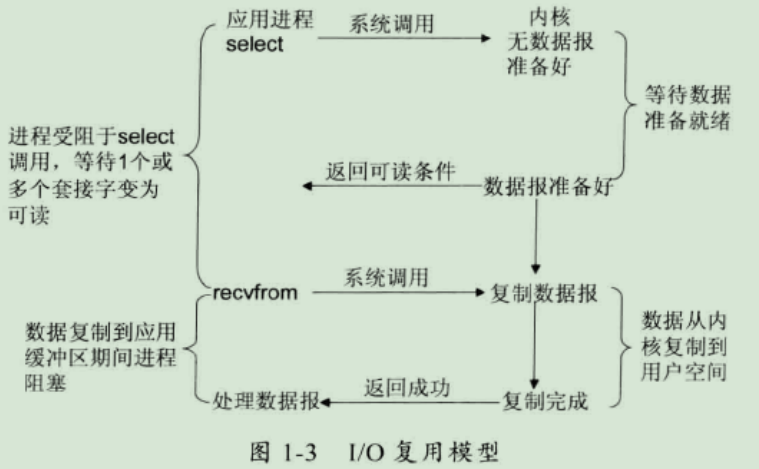
3、I/O 复用模型
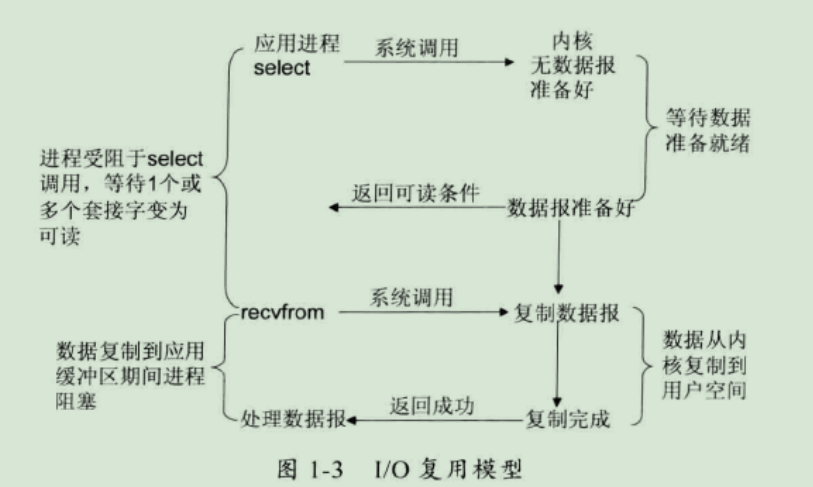
在 I/O 复用模型中,会用到 Select 或 Poll 函数或 Epoll 函数(Linux 2.6 以后的内核开始支持),这两个函数也会使进程阻塞,但是和阻塞 I/O 有所不同。这两个函数可以同时阻塞多个 I/O 操作,而且可以同时对多个读操作,多个写操作的 I/O 函数进行检测,直到有数据可读或可写时,才真正调用 I/O 操作函数。
比喻:放了一堆鱼竿,在岸边一直守着这堆鱼竿,没鱼上钩就玩手机。
优点:可以基于一个阻塞对象,同时在多个描述符上等待就绪,而不是使用多个线程(每个文件描述符一个线程),这样可以大大节省系统资源。
缺点:当连接数较少时效率相比多线程+阻塞 I/O 模型效率较低,可能延迟更大,因为单个连接处理需要 2 次系统调用,占用时间会有增加。
众所周知,Nginx 这样的高性能互联网反向代理服务器大获成功的关键就是得益于 Epoll。
4、信号驱动 I/O 模型
在信号驱动式 I/O 模型中,应用程序使用套接口进行信号驱动 I/O,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,进程会收到一个 SIGIO 信号,可以在信号处理函数中调用 I/O 操作函数处理数据。
比喻:鱼竿上系了个铃铛,当铃铛响,就知道鱼上钩,然后可以专心玩手机。
优点:线程并没有在等待数据时被阻塞,可以提高资源的利用率。
缺点:信号 I/O 在大量 IO 操作时可能会因为信号队列溢出导致没法通知。
信号驱动 I/O 尽管对于处理 UDP 套接字来说有用,即这种信号通知意味着到达一个数据报,或者返回一个异步错误。但是,对于 TCP 而言,信号驱动的 I/O 方式近乎无用,因为导致这种通知的条件为数众多,每一个来进行判别会消耗很大资源,与前几种方式相比优势尽失。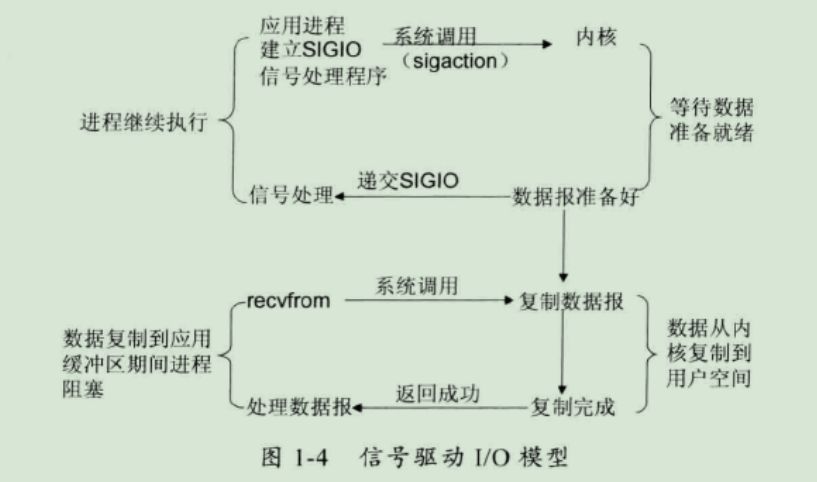
5、异步 I/O 模型
即AIO,全称asynchronous I/O。由 POSIX 规范定义,应用程序告知内核启动某个操作,并让内核在整个操作(包括将数据从内核拷贝到应用程序的缓冲区)完成后通知应用程序。
这种模型与信号驱动模型的主要区别在于:信号驱动 I/O 是由内核通知应用程序何时启动一个 I/O 操作,而异步 I/O 模型是由内核通知应用程序 I/O 操作何时完成。
优点:异步 I/O 能够充分利用 DMA 特性,让 I/O 操作与计算重叠。
缺点:要实现真正的异步 I/O,操作系统需要做大量的工作。
目前 Windows 下通过 IOCP 实现了真正的异步 I/O。而在 Linux 系统下,Linux 2.6才引入,目前 AIO 并不完善,因此在 Linux 下实现高并发网络编程时都是以 IO 复用模型模式为主。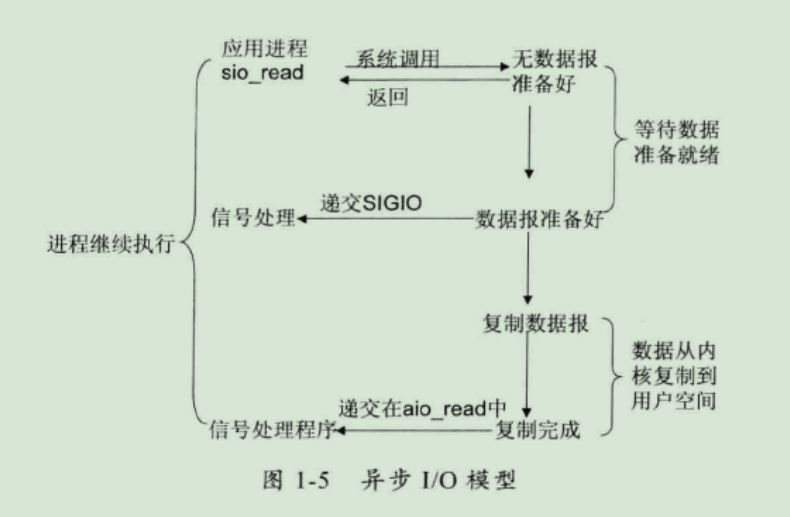
1.3 I/O 多路复用技术
二、NIO 入门
1、BIO 编程
网络编程的基础模型是 Client/Server 模型,ServerSocket 负责提供位置信息(IP 和 port),客户端通过连接操作向 Server 监听的地址发起请求,经过三次握手建立连接,通过网络套接字(Socket)进行通信。
1.1 BIO 通信模型
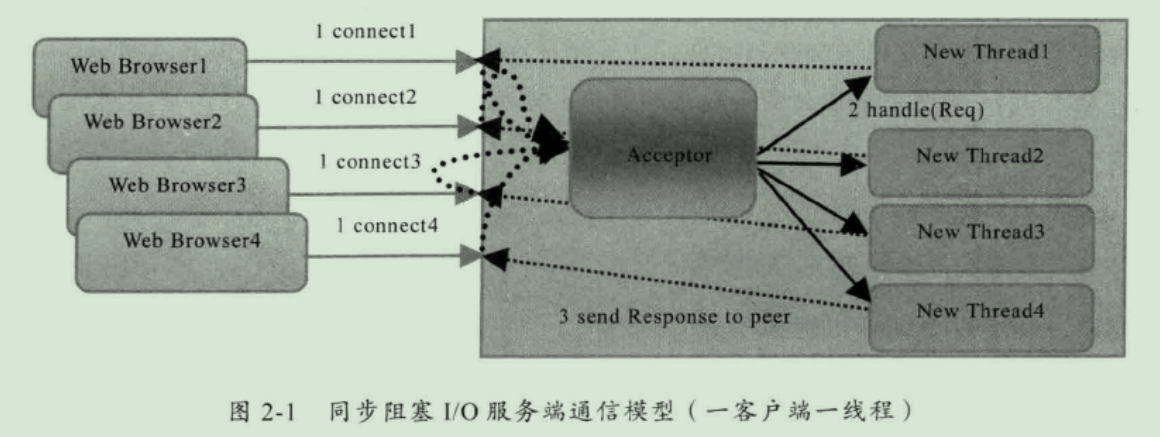
缺点:缺乏弹性伸缩能力,服务端线程数与客户端并发数为 1:1 关系!
2、 NIO 编程
2.1 NIO 类库介绍
- 缓冲区 Buffer
Buffer,包含一些要写入或者是要读出的数据,在 NIO 库所有的数据都是在缓冲区中处理的。Buffer 实际上就是一个数组,同时还提供了对数据的结构化访问以及维护了读写位置(limit)的信息。ByteBuffer 是最常用的缓冲区。Buffer 的关系类图如下: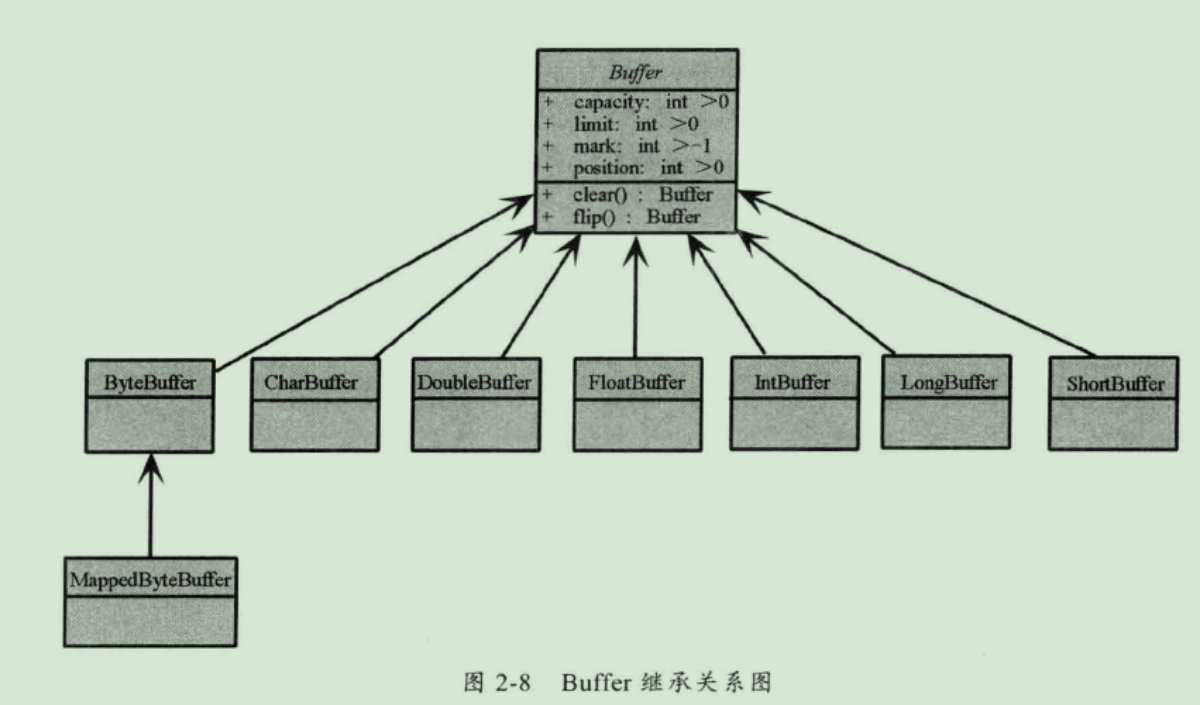
- 通道 Channel
Channel 是一个双向的通道,可以用于读、写或者两者同时进行。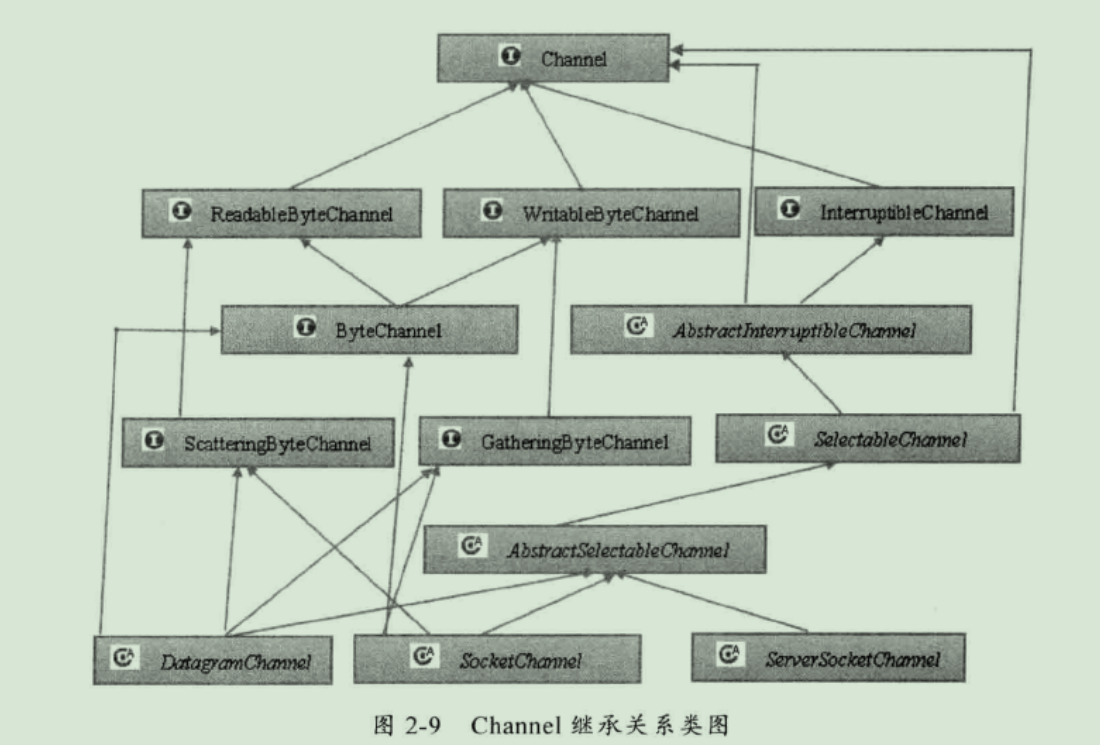
- 多路复用器 Selector
多路复用器提供了选择就绪的任务的能力。Selector 不断轮询 注册在其上的 Channel,当 Channel 上发生读写事件,就说明该 Channel 已经就绪,会被 Selector 轮询出来,然后通过 SelectorKey 可以获取到已经就绪的 Channel 集合,进行后续的 I/O 操作。
2.2 NIO 服务端序列图
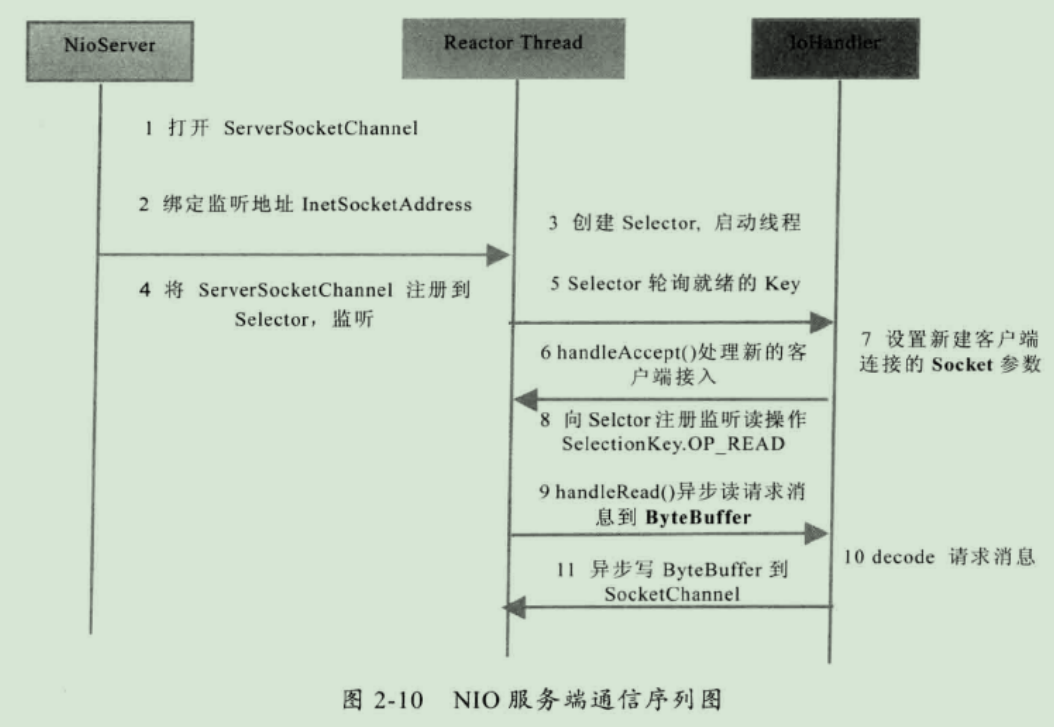
2.3 NIO 客户端序列图
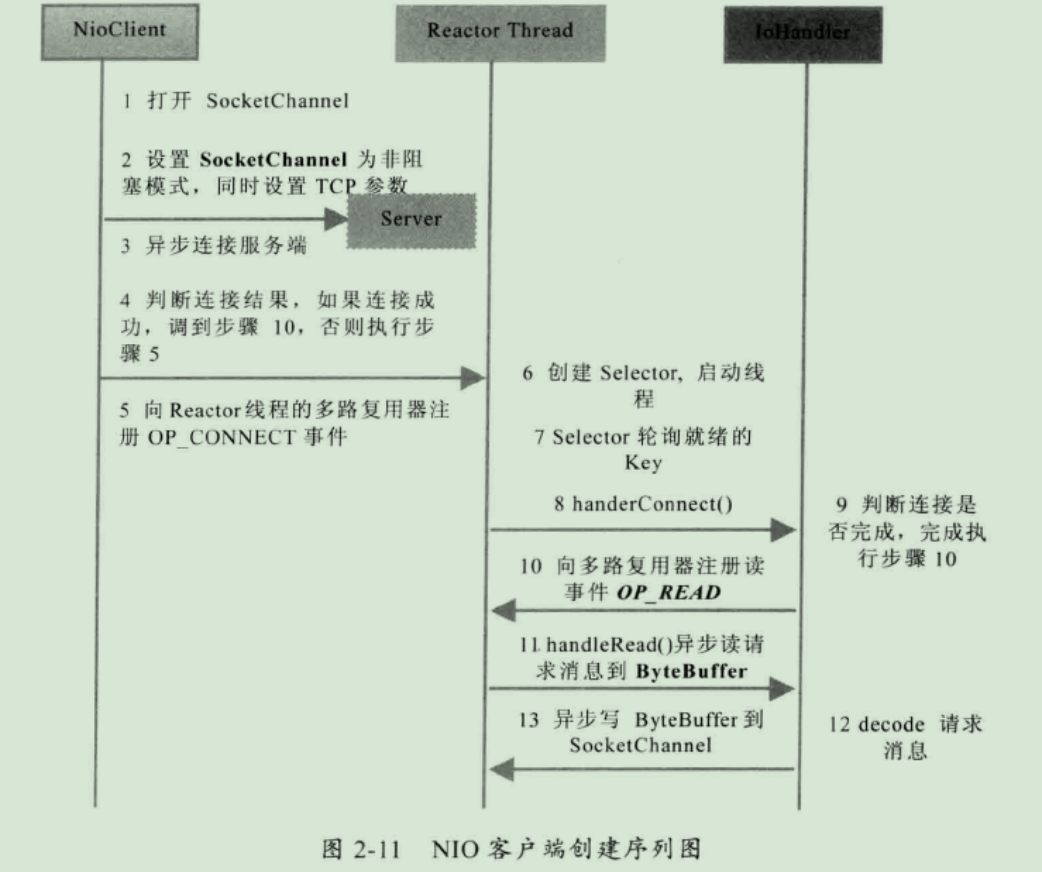
// 1. 打开 SocketChannel
SocketChannel clientChannel = SocketChannel.open();
三、Netty 概述
Netty 是一款异步的事件驱动的网络应用程序框架,支持快速地开发可维护的高性能的面向协议的服务器和客户端。
1、Netty 的特性

2、Netty 核心组件
2.1 Channel
Channel 是 Java NIO 的一个基本构造。可以把 Channel 看做是数据传输的载体,可以被打开、关闭,连接或者断开。
/** A channel represents an open connection to an entity* such as a hardware device, a file, a network socket,* or a program component that is capable of* performing one or more distinct I/O operations, for example reading * or writing.*/public interface Channel extends Closeable {boolean isOpen();void close() throws IOException;}
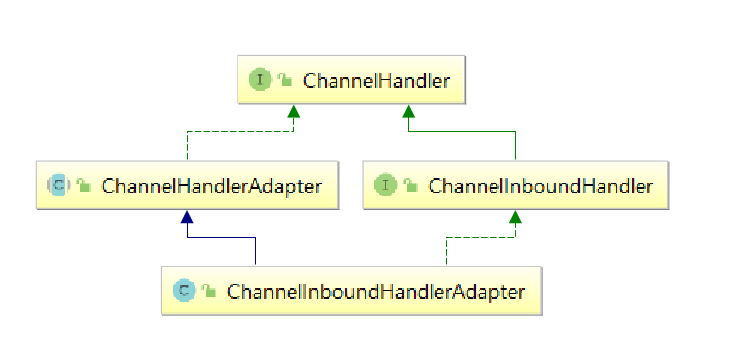
2.2 ChannelHandler & ChannelPipeline
一个回调其实就是一个方法,是在操作完成后通知相关方最常见的方式之一。
Netty 在内部使用了回调来处理事件;当一个回调被触发时,相关的事件可以被一个ChannelHandler 的实现处理。ChannelHandler,充当了所有处理入站和出站数据的应用程序逻辑的容器。
// 当一个新的连接已经被建立时,channelActive(ChannelHandlerContext)将会被调用public class ConnectHandler extends ChannelInboundHandlerAdapter {@Overridepublic void channelActive(ChannelHandlerContext ctx)throws Exception {System.out.println("Client " + ctx.channel().remoteAddress() + " connected");}}
2.3 ChannelFuture
Future 提供了另一种在操作完成时通知应用程序的方式。这个对象可以看作是一个异步操
作的结果的占位符;它将在未来的某个时刻完成,并提供对其结果的访问。
JDK 预置了 java.util.concurrent.Future,但是其所提供的实现,只允许手动检查对应的操作是否已经完成,或者一直阻塞直到它完成。这是非常繁琐的,所以 Netty 提供了它自己的实现 ChannelFuture,用于在执行异步操作的时候使用。
3、第一款 Netty 应用
3.1 编写 Echo 服务端
所有的 Netty 服务器都需要以下两个部分:
- 至少一个 ChannelHandler:该组件实现了服务器对从客户端接收的数据的处理,即它的业务逻辑。
- 引导:这是配置服务器的启动代码。至少,它会将服务器绑定到它要监听连接请求的端口上。
- ChannelHandler 和业务逻辑
/*** `@ Sharable` 标识 Channel 可以被多给 Channel 安全的共享*/@ChannelHandler.Sharablepublic class EchoServerHandler extends ChannelInboundHandlerAdapter {/*** 对于每个传入的消息都要调用*/@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) {ByteBuf in = (ByteBuf) msg;System.out.println("Server Receive: " + in.toString(CharsetUtil.UTF_8));// 将接收到的消息写给发送者,而不冲刷出站消息ctx.write(in);}/*** 通知 ChannelInboundHandler 最后一次对 channel-Read() 的调用是当前批量读取中的最后一条消息;*/@Overridepublic void channelReadComplete(ChannelHandlerContext ctx) {// 将未决消息冲刷到远程节点,并且关闭该 Channelctx.writeAndFlush(Unpooled.EMPTY_BUFFER).addListener(ChannelFutureListener.CLOSE);}/*** 在读取操作期间,有异常抛出时会调用*/@Overridepublic void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {cause.printStackTrace();ctx.close();}}
- 引导服务器
- 绑定到服务器将在其上监听并接受传入连接请求的端口;
- 配置 Channel ,以将有关的入站消息通知给 EchoServerHandler 实例。
public class EchoServer {private final int port;public EchoServer(int port) {this.port = port;}public static void main(String[] args) throws InterruptedException {if (args.length != 1) {System.err.println("Usage: " + EchoServer.class.getSimpleName() + " <port>");}int port = Integer.parseInt(args[0]);new EchoServer(port).start();}public void start() throws InterruptedException {final EchoServerHandler handler = new EchoServerHandler();// 1. 创建 EventLoopGroupEventLoopGroup group = new NioEventLoopGroup();// 2. 创建 BootStrapServerBootstrap bootstrap = new ServerBootstrap();try {bootstrap.group(group)// 3. 指定使用的 NIO Channel.channel(NioServerChannel.class)// 4. 绑定端口IP.localAddress(new InetSocketAddress(port))// 5. 添加一个 Handler.childHandler(new ChannelInitializer<SocketChannel>() {@Overrideprotected void initChannel(SocketChannel ch) throws Exception {ch.pipeline().addLast(handler);}});// sync()方法的调用将导致当前 Thread 阻塞,一直到绑定操作完成为止// 6. 异步地绑定服务器;ChannelFuture cf = bootstrap.bind().sync();// 7. 获取 Channel 的 CloseFuture,cf.channel().closeFuture().sync();} catch (Exception e) {// 8. 关闭 EventLoopGroup 释放所有资源group.shutdownGracefully().sync();}}}
3.2 编写 Echo 客户端
Echo 客户端将会:
(1)连接到服务器;
(2)发送一个或者多个消息;
(3)对于每个消息,等待并接收从服务器发回的相同的消息;
(4)关闭连接。
编写客户端所涉及的两个主要代码部分也是业务逻辑和引导,和服务器一样。
四、TCP 粘包/拆包
1、TCP 粘包/拆包
TCP 是个“流”协议,所谓流,就是没有界限的一串数据。TCP 底层并不了解业务数据的具体含义,它会根据 TCP 缓冲区的实际情况进行包的划分,所以一个业务上完整的包可能会被 TCP 拆分成多个包进行发送,也有可能把多个小包打包成一个大的数据包进行发送,这就是 TCP 的粘包/拆包问题。
2、TCP 粘包/拆包发生的原因
- 应用程序 write 写入的字节大小大于套接口发送缓冲区的大小;
- 进行 MMS 大小的 TCP 拆分;
以太网帧的 playload 大于 MTU 进行 IP 分片。
3、粘包问题的解决策略
消息定长,不够时,空格补足;
- 在包尾增加回车换行符进行分割,例如 FTP 协议;
- 将消息分为消息头和消息体,消息头里指明消息的长度;
-
4、Netty 的粘包/拆包解决方案
为了解决TCP粘包/拆包导致的半包读写问题,Netty默认提供了多种编解码器用于处理半包。
LineBasedFrameDecoder
LinkeBasedFrameDecoder 的工作原理是它一次遍历 ByteBuf 中的可读字节,判断看是否有“\n”、“\r\n”,如果有,就一次位置为结束位置,从可读索引到结束位置区间的字节就组成一行。它是以换行符为结束标志的编解码,支持携带结束符或者不携带结束符两种解码方式,同时支持配置单行的最大长度。如果连续读取到最大长度后任然没有发现换行符,就会抛出异常,同时忽略掉之前读到的异常码流。
- DelimiterBasedFrameDecoder
实现自定义分隔符作为消息的结束标志,完成解码。
bootstrap.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
// 自定义分隔符解码器
ch.pipeline().addLast(new DelimiterBasedFrameDecoder(1024, Unpooled.copiedBuffer("$_".getBytes())));
}
});
- FixedLengthFrameDecoder
FixedLengthFrameDecoder 是固定长度解码器,能够按照指定的长度对消息进行自动解码,开发者不需要考虑 TCP 的粘包/拆包问题。
bootstrap.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
// 定长解码器
ch.pipeline().addLast(new FixedLengthFrameDecoder(20));
}
});
五、编解码技术
每个网络应用程序都必须定义如何解析在两个节点之间来回传输的原始字节,以及如何将其和目标应用程序的数据格式做相互转换。这种转换逻辑由编解码器处理,编解码器由编码器和解码器组成,它们每种都可以将字节流从一种格式转换为另一种格式。
在进行远程调用时,需要把被传输的 Java 对象编码为字节数组或者 ByteBuffer 对象,而当远程服务器读取到 ByteBuffer 对象或者字节数组时,需要将其解码为发送时的 Java 对象,这被称为 Java 对象编解码技术。
1、Java 序列化
Java 从 JDK 1.1 开始就提供了序列化功能,只需实现 Serializable 接口即可。但是 JDK 序列化有以下缺点:
- 无法跨语言;
- 序列化后的码流太大;
-
2、主流的编解码框架
Google ProtoBuf
- Facebook Thrift
- JBoss Marshalling
3、Netty 解码器
每当需要为 ChannelPipeline 中的下一个 Channel-InboundHandler 转换入站数据时会用到。此外,得益于 ChannelPipeline 的设计,可以将多个解码器链接在一起,以实现任意复杂的转换逻辑。(Netty 的解码器实现了 ChannelInboundHandler )3.1 抽象类 ByteToMessageDecoder
作用:将字节解码为消息(或者另一个字节序列)
| 方法 | 描述 |
|---|---|
| decode( ChannelHandlerContext ctx, ByteBuf in, List |
必须实现的唯一抽象方法。 decode() 方法被调用时将会传入一个包含了传入数据的 ByteBuf ,以及一个用来添加解码消息的 List 。对这个方法的调用将会重复进行,直到确定没有新的元素被添加到该 List ,或者该 ByteBuf 中没有更多可读取的字节时为止。然后,如果该 List 不为空,那么它的内容将会被传递给 ChannelPipeline 中的下一个 ChannelInboundHandler。 |
| decodeLast( ChannelHandlerContext ctx, ByteBuf in, List |
Netty提供的这个默认实现只是简单地调用了 decode() 方法。当 Channel 的状态变为非活动时,这个方法将会被调用一次。可以重写该方法以提供特殊的处理。 |
3.2 抽象类 ReplayingDecoder
ReplayingDecoder 扩展了 ByteToMessageDecoder,使得我们不必调用 readableBytes() 方法。它通过使用一个自定义的 ByteBuf(ReplayingDecoderByteBuf) 实现,包装传入的ByteBuf 实现了这一点,其将在内部执行该调用 readableBytes()。
3.3 抽象类 MessageToMessageDecoder
作用:在两个消息格式之间进行转换(例如从一种 POJO 转换为另一种 POJO)。
// 类型参数 I 指定了 decode()方法的输入参数 msg 的类型
public abstract class MessageToMessageDecoder extends ChannelInboundHandlerAdapter
| 方法 | 描述 |
|---|---|
| decode( ChannelHandlerContext ctx, I msg,List |
对于每个需要被解码为另一种格式的入站消息来说,该方法都 将会被调用。解码消息随后会被传递给 ChannelPipeline中的下一个 ChannelInboundHandler |
4、Netty 编码器
Netty 编码器实现了 ChannelOutboundHandler,并将出站数据从一种格式转换为另一种格式。
| 方法 | 描述 |
|---|---|
| encode( ChannelHandlerContext ctx, I msg,ByteBuf out) |
encode() 方法需要实现的唯一抽象方法。它被调用时将会传入要被该类编码为 ByteBuf 的(类型为 I 的)出站消息。该 ByteBuf 随后将会被转发给 ChannelPipeline 中的下一个 ChannelOutboundHandler |
4.2 抽象类 MessageToMessageEncoder
作用:将一种消息编码为另一种消息。
| 方法 | 描述 |
|---|---|
| encode( ChannelHandlerContext ctx, I msg,List |
需要实现的唯一方法。每个通过 write() 方法写入的消息都将会被传递给 encode() 方法,以编码为一个或者多个出站消息。随后,这些出站消息将会被转发给 ChannelPipeline 中的下一个 ChannelOutboundHandler |
5、MessagePack 编解码
MessagePack messagepack = new MessagePack();
List<String> src = new ArrayList<>();
src.add("aaa");
src.add("bbb");
// 序列化 编码
byte[] raw = messagepack.write(src);
// 解码
List<String> dst1 = messagepack.read(write,Templates.tList(Templates.TString));
6、Protobuf 编解码
7、Marshalling 编解码
POM 依赖:
<dependency>
<groupId>org.jboss.marshalling</groupId>
<artifactId>jboss-marshalling</artifactId>
<version>1.3.0.GA</version>
</dependency>
/**
* 创建 JBoss Marshalling 解码器
*/
public static MarshallingDecoder buildMarshallingDecoder() {
final MarshallerFactory marshallerFactory = Marshalling.getProvidedMarshallerFactory("serial");
final MarshallingConfiguration configuration = new MarshallingConfiguration();
configuration.setVersion(5);
UnmarshallerProvider provider = new DefaultUnmarshallerProvider(marshallerFactory, configuration);
MarshallingDecoder decoder = new MarshallingDecoder(provider, 1024);
return decoder;
}
/**
* 创建 JBoss Marshalling 编码器
*/
public static MarshallingEncoder buildMarshallingEncoder() {
final MarshallerFactory marshallerFactory = Marshalling.getProvidedMarshallerFactory("serial");
final MarshallingConfiguration configuration = new MarshallingConfiguration();
configuration.setVersion(5);
MarshallerProvider provider = new DefaultMarshallerProvider(marshallerFactory, configuration);
MarshallingEncoder encoder = new MarshallingEncoder(provider);
return encoder;
}
六、ByteBuf
网络数据的基本单位总是字节。Java NIO 提供了 ByteBuffer 作为它的字节容器,Netty 的 ByteBuffer 替代品是 ByteBuf ,一个强大的实现,既解决了 JDK API 的局限性,又为网络应用程序的开发者提供了更好的 API。
1、ByteBuf 类
1.1 ByteBuf 如何工作
ByteBuf 维护了两个不同的索引:一个用于读取,一个用于写入。名称以 read 或者 write 开头的 ByteBuf 方法,将会推进其对应的索引,而名称以 set 或者 get 开头的操作则不会。
1.2 ByteBuf 的使用模式
- 堆缓冲区
最常用的 ByteBuf 模式是将数据存储在 JVM 的堆空间中。这种模式被称为支撑数组
(backing array),它能在没有使用池化的情况下提供快速的分配和释放,非常适合于有遗留的数据需要处理的情况。
public void testHasArray() {
ByteBuf heapBuf = Unpooled.buffer();
// 检查 Buf 是否有支撑数组 当 hasArray() 方法返回 false 时,
// 尝试访问支撑数组将触发一个 Unsupported OperationException 。
if (heapBuf.hasArray()) {
// 获取支撑数组
byte[] array = heapBuf.array();
// 计算第一个字节的偏移量
int offSet = heapBuf.arrayOffset() + heapBuf.readerIndex();
// 可读字节数
int length = heapBuf.readableBytes();
}
}
- 直接缓冲区
NIO 在 JDK 1.4 中引入的 ByteBuffer 类允许 JVM 实现通过本地调用来分配内存。这主要是为了避免在每次调用本地 I/O 操作之前(或者之后)将缓冲区的内容复制到一个中间缓冲区(或者从中间缓冲区把内容复制到缓冲区)。直接缓冲区的内容将驻留在常规的会被垃圾回收的堆之外。通过套接字发送它之前,JVM将会在内部把你的缓冲区复制到一个直接缓冲区中。
直接缓冲区的主要缺点是,相对于基于堆的缓冲区,它们的分配和释放都较为昂贵。
// 直接缓冲区
ByteBuf directBuf = Unpooled.directBuffer();
// 检查 ByteBuf 是否由数组支撑,如果不是,则这是个直接缓冲区
if (!directBuf.hasArray()) {
// 可读字节数
int length = directBuf.readableBytes();
byte[] array = new byte[length];
// 将字节复制到该数组
directBuf.getBytes(directBuf.readerIndex(), array);
// handleArray(array, 0, length);
}
- 复合缓冲区
复合缓冲区是 JDK 的 ByteBuffer 类缺失的特性,它为多个 ByteBuf 提供了一个聚合视图。在这里可以添加或者删除 ByteBuf 实例。Netty 通过一个 ByteBuf 子类: CompositeByteBuf 实现了这个模式,它提供了一个将多个缓冲区表示为单个合并缓冲区的虚拟表示。
CompositeByteBuf 中的 ByteBuf 实例可能同时包含直接内存分配和非直接内存分配。如果其中只有一个实例,那么对 CompositeByteBuf 上的 hasArray() 方法的调用将返回该组件上的 hasArray() 方法的值;否则它将返回 false 。
使用 ByteBuffer 的复合缓冲区模式:
// Use an array to hold the message parts
ByteBuffer[] message = new ByteBuffer[] { header, body };
// Create a new ByteBuffer and use copy to merge the header and body
ByteBuffer message2 =
ByteBuffer.allocate(header.remaining() + body.remaining());
message2.put(header);
message2.put(body);
message2.flip();
// 使用 CompositeByteBuf 的复合缓冲区模式:
CompositeByteBuf messageBuf = Unpooled.compositeBuffer();
ByteBuf headerBuf = ...; // can be backing or direct
ByteBuf bodyBuf = ...; // can be backing or direct
messageBuf.addComponents(headerBuf, bodyBuf);
.....
messageBuf.removeComponent(0); // remove the header
for (ByteBuf buf : messageBuf) {
System.out.println(buf.toString());
}
// 访问 CompositeByteBuf 中的数据:
CompositeByteBuf compBuf = Unpooled.compositeBuffer();
int length = compBuf.readableBytes();
byte[] array = new byte[length];
compBuf.getBytes(compBuf.readerIndex(), array);
handleArray(array, 0, array.length);
2、字节级操作

若有收获,就点个赞吧
0 人点赞
