在 kafka 中, topic 是一个存储消息的逻辑概念,partition分区是 topic 的进一步拆分,每个 topic 可以拆分为多个 partition 分区,类似于数据库中表的水平拆分。
- 一个 Partition 只对应一个 Broker,一个 Broker 可以管理多个 Partition。
- 同一个 Topic 下,不同的 Partition 里的消息是不同的。
- 在一个 Partition 里消息是有序的,Kafka 不保证跨分区的消息有序性。
——> 如果要保证消息的全局有序,那么可以将 Partition 设置为 1。
- 可以动态的增加 Partition 的数量,但是不支持减少。
- 对于同一个消费组,一个 Partition 只能被一个消费者消费。即分区数决定了同组消费者个数的上限。一般不建议同组消费者的数量大于分区数。
- 分区越多,理论上整个集群所能达到的吞吐量就越大。
- 一个 Partition 对应着一个日志文件夹,(文件夹的命名规则为 topic 名称+分区序号,比如 test1-0),该文件夹下会有多个分段的 log 日志文件,即分 segment 存储。
- partition 的数量上限是没有限制的。
kafka 中关于topic、broker 及 partition 相关参数的几点说明:
1:num.partitions 参数
默认值为1,可增加 topic 的 partition 数量,不可减少其个数。
kafka 集群通过 partition 对 topic 进行横向扩展,当有新 broker 加入 kafka 集群,可通过 hash 调用 partition 个数负载均衡。
partition 数量选定标准:
- 主题吞吐量。
- 单个 partition 读取数据的最大吞吐量。
- 每个 broker 包含的 partition 个数、可用磁盘空间和网络带宽。
- 单个 broker 对 partition 个数有限制,partition 越多,占用的内存越多,完成选举所需时间越长。
Partition 分配算法
为了更好的做负载均衡,Kafka 尽量将所有的 Partition 均匀分配到整个集群上。Kafka 分配 Replica 的算法如下:
- 将所有存活的 N 个 Brokers 和待分配的 Partition 排序;
- 将第 i 个 Partition 分配到第 (i mod n) 个 Broker 上,这个 Partition 的第一个 Replica 存在于这个分配的 Broker 上,并且会作为partition 的优先副本;
- 将第 i 个 Partition 的第 j 个Replica分配到第 ((i + j) mod n) 个 Broker 上。
假设现在有 5 个 Broker,分区数为 5,副本为 3 的主题,按照上面的说法,主题最终分配在整个集群的样子如下:
但事实真的是这样的吗?实际上如果真按照这种算法,会存在以下明显几个问题:
- 所有主题的第一个分区都是存放在第一个 Broker 上,这样会造成第一个 Broker 上的分区总数多于其他的 Broker,这样就失去了负载均衡的目的;
- 如果主题的分区数多于 Broker 的个数,多于的分区都是倾向于将分区发放置在前几个 Broker 上,同样导致负载不均衡。

随机的从 broker 列表里取一个 broker 当做起始位置,由此顺序的分配 partition;然后随机获取 nextReplicaShift,通过该参数确定副本 partition 的相对于 partition0 的偏移量。然后顺序的分配副本 Partition 的 broker。
def assignReplicasToBrokers(brokerList: Seq[Int],nPartitions: Int,replicationFactor: Int,fixedStartIndex: Int = -1,startPartitionId: Int = -1): Map[Int, Seq[Int]] = {if (nPartitions <= 0)throw new AdminOperationException("number of partitions must be larger than 0")if (replicationFactor <= 0)throw new AdminOperationException("replication factor must be larger than 0")if (replicationFactor > brokerList.size)throw new AdminOperationException("replication factor: " + replicationFactor +" larger than available brokers: " + brokerList.size)val ret = new mutable.HashMap[Int, List[Int]]()// 随机获取 startIndexval startIndex = if (fixedStartIndex >= 0) fixedStartIndex else rand.nextInt(brokerList.size)var currentPartitionId = if (startPartitionId >= 0) startPartitionId else 0// 随机获取副本的偏移位置var nextReplicaShift = if (fixedStartIndex >= 0) fixedStartIndex else rand.nextInt(brokerList.size)for (i <- 0 until nPartitions) {if (currentPartitionId > 0 && (currentPartitionId % brokerList.size == 0))nextReplicaShift += 1val firstReplicaIndex = (currentPartitionId + startIndex) % brokerList.sizevar replicaList = List(brokerList(firstReplicaIndex))for (j <- 0 until replicationFactor - 1)replicaList ::= brokerList(replicaIndex(firstReplicaIndex, nextReplicaShift, j, brokerList.size))ret.put(currentPartitionId, replicaList.reverse)currentPartitionId = currentPartitionId + 1}ret.toMap}private def replicaIndex(firstReplicaIndex: Int, secondReplicaShift: Int, replicaIndex: Int, nBrokers: Int): Int = {val shift = 1 + (secondReplicaShift + replicaIndex) % (nBrokers - 1)(firstReplicaIndex + shift) % nBrokers}
- Partition 数量不能小于等于 0。
- 副本因子不能大于 Broker 的个数;
- 第一个分区(编号为0)的第一个副本放置位置是随机从 brokerList 选择的;
- 其他分区的第一个副本放置位置相对于第 0 个分区依次往后移。也就是如果我们有 5 个 Broker,5 个分区,假设第一个分区放在第四个 Broker 上,那么第二个分区将会放在第五个 Broker 上;第三个分区将会放在第一个 Broker 上;第四个分区将会放在第二个 Broker 上,依次类推;
- 剩余的副本相对于第一个副本放置位置其实是由 nextReplicaShift 决定的,而这个数也是随机产生的;
分区 leader 选举
从 ISR 列表里选第一个 broker 作为 Leader
Controller 感知到分区 Leader 所在的 broker 挂了(Controller 监听了很多 zk 节点可以感知到 broker 存活),Controller 会从 ISR 列表(参数 unclean.leader.election.enable=false 的前提下)里挑第一个 broker 作为 Leader (第一个 broker 最先放进 ISR 列表,可能是同步数据最多的副本),如果参数 unclean.leader.election.enable 为 true,代表在 ISR 列表里所有副本都挂了的时候可以在 ISR 列表以外的副本中选 Leader,这种设置,可以提高可用性,但是选出的新 Leader 有可能数据少很多。
消费者分区分配策略
消费者 Rebalance
Kafka 里一个分区只能被一个消费组里的一个消费者消费。 Rebalance 就是将一个 Topic 下的 Partition 交由 Consumer Group 里的指定的消费者消费的过程。就是建立 Partition 与 Consumer 的对应关系。
Rebalance 就是说如果消费组里的消费者数量有变化或消费的分区数有变化,Kafka 会重新分配消费者消费分区的关系。比如 Consumer Group 中某个消费者挂了,此时会自动把分配给他的分区交给其他的消费者,如果他又重启了,那么又会把一些分区重新交还给他。
注意:Rebalance 只针对 subscribe 这种不指定分区消费的情况,如果通过 assign 这种消费方式指定了分区,Kafka 不会进行 Rebanlance。
如下情况可能会触发消费者 Rebalance:
- 消费组里的 Consumer 增加或减少了;
- 动态给 topic 增加了分区;
- 消费组订阅了更多的 topic。
Rebalance 过程中,消费者无法从 Kafka 消费消息,这对 Kafka 的 TPS 会有影响,如果 Kafka 集群内节点较多,比如数百个,那重平衡可能会耗时极多,所以应尽量避免在系统高峰期的 Rebalance 发生。
消费者 Rebalance 分区分配策略
一个 Consumer Group 中有多个 Consumer,一个 topic 有多个 Partition,所以必然会涉及到 Partition 的分配问题,即确定那个 Partition 由哪个 Consumer 来消费。
主要有三种 Rebalance的策略:range、round-robin、sticky。
Kafka 提供了消费者客户端参数 partition.assignment.strategy 来设置消费者与订阅主题之间的分区分配策略。默认情况为 range 分配策略。
假设一个主题有 10 个分区(0-9),现在有三个 Consumer 消费:
range 策略
Range 策略就是按照分区序号排序。
假设 n=分区数/消费者数量 = 3, m=分区数%消费者数量 = 1,那么前 m 个消费者每个分配 n+1 个分区,后面的(消费者数量-m )个消费者每个分配 n 个分区。
Consumer1:0,1,2,3
Consumer2:4,5,6
Consumer3:7,8,9
基本原则是按区间等分,如果没法均等分配的话,前面的分区在一开始分配的时候就会多分配
round-robin 策略
Consumer1:0,3,6,9
Consumer2:1,4,7
Consumer3:2,5,8
sticky 策略
sticky 策略初始时分配策略与 round-robin 类似,但是在 Rebalance 的时候,需要保证如下两个原则。
1)分区的分配要尽可能均匀 。
2)分区的分配尽可能与上次分配的保持相同。
当两者发生冲突时,第一个目标优先于第二个目标 。这样可以最大程度维持原来的分区分配的策略。
比如对于第一种 range 情况的分配,如果第三个 Consumer 挂了,那么重新用 sticky 策略分配的结果如下:
consumer1 除了原有的 0~3,会再分配一个 7;
consumer2 除了原有的 4~6,会再分配 8 和 9。
Rebalance 过程
分区方案由谁制定? 如果由 Kafka broker 来制定,那么每次新增消费者,broker 都需要进行 rebalance,broker 的压力会比较大,影响 Kafka 性能。因此是由消费者来制定的。分区方案制定完成后需要再同步给组内的所有的消费者,而每个消费者之间是没法直接通信的,因此这个通信交由 broker 来完成。 GroupCoordinate:broker 端的协调者,消费者对应的 __consumer_offsets 的分区的 Leader; ConsumerCoordinate:消费组的协调者,由第一个加入消费组的消费者担任。
消费组里的 Coordinator 指定分区方案,然后将分区方案同步给 Kafka 的 Coordinator,然后由 GroupCoordinate 将分区方案同步给所有的消费者。
当有消费者加入消费组时,消费者、消费组及组协调器之间会经历以下几个阶段。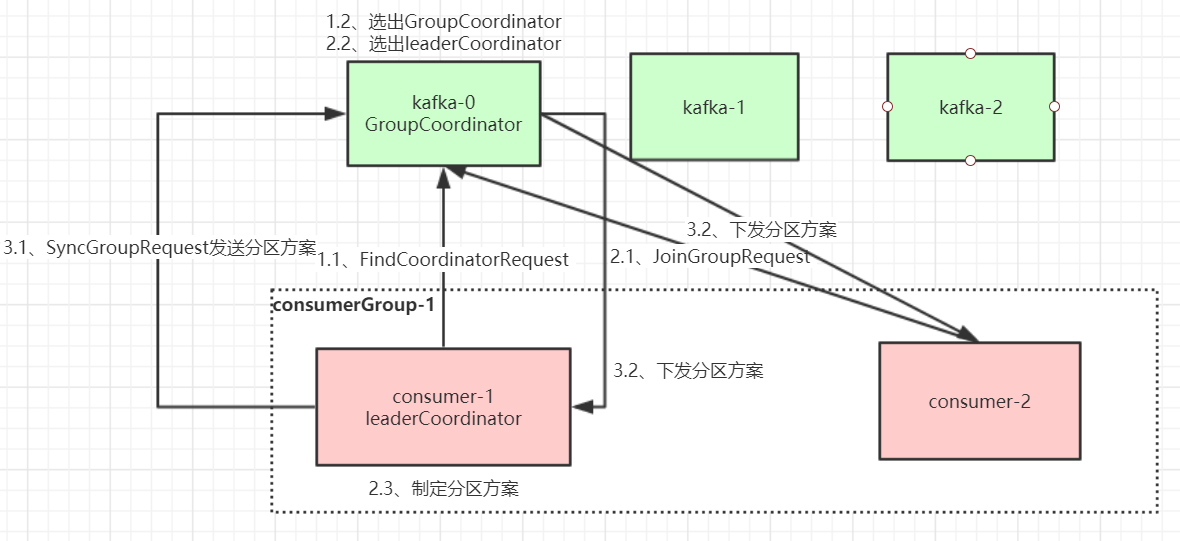
第一阶段:选择组协调器
组协调器 GroupCoordinator:每个 Consumer Group 都会选择一个 broker 作为自己的组协调器 Coordinator,负责监控这个消费组里的所有消费者的心跳,以及判断是否宕机,然后开启消费者 Rebalance。
Consumer Group 中的每个 Consumer 启动时会向 Kafka 集群中的某个节点发送 FindCoordinatorRequest 请求来查找对应的组协调器 GroupCoordinator,并跟其建立网络连接。
组协调器选择方式:
Consumer 消费的 offset 要提交到 __consumer_offsets 的哪个分区,这个分区 Leader 对应的 broker 就是这个Consumer Group 的 Coordinator。
第二阶段:加入消费组 JOIN GROUP
在成功找到消费组所对应的 GroupCoordinator 之后就进入加入消费组的阶段,在此阶段的消费者会向 GroupCoordinator 发送 JoinGroupRequest 请求,并处理响应。然后 GroupCoordinator 从一个 Consumer Group 中选择第一个加入 Group 的 Consumer 作为 Leader(消费组协调器),把 Consumer Group 情况发送给这个 Leader,接着这个 Leader 会负责制定分区方案。
第三阶段:SYNC GROUP
Consumer Leader 通过给 GroupCoordinator 发送 SyncGroupRequest,接着 GroupCoordinator 就把分区方案下发给各个 Consumer,他们会根据指定分区的 Leader broker 进行网络连接以及消息消费。
生产者分区策略(消息路由)
producer 发送消息到 broker 时,会根据分区算法选择将其存储到哪一个 partition。其路由机制为:
(1)指明 partition 的情况下,直接将指明值作为 partiton 值;
(2)没有指明 partition 值,但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值;
(3)既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,也就是常说的 round-robin 算法。

若有收获,就点个赞吧
0 人点赞
