HBase 数据结构
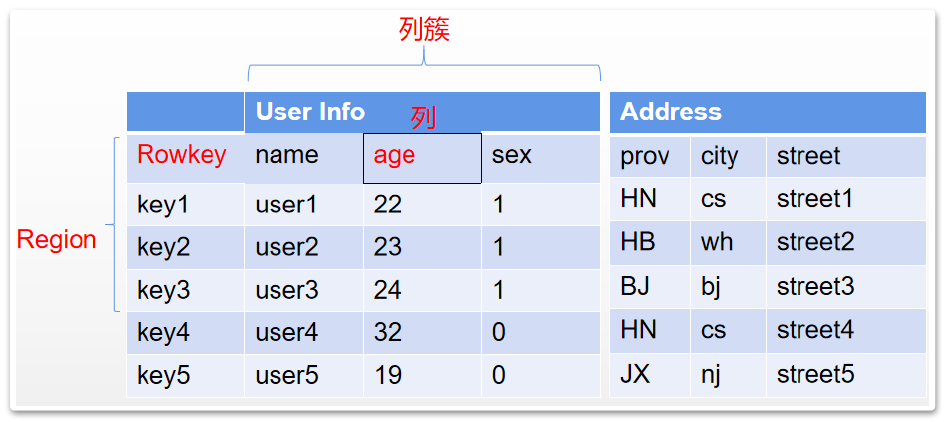
HBase 虽然也有表、列这样的逻辑结构,但是整体上是以一种 k-v 键值对的方式来存储数据的。
纵向来看,HBase 中的每张表由 Rowkey 和若干个列族或者称为列簇组成。其中 Rowkey 是每一行数据的唯一标识,在对数据进行管理时,必须自行保证 Rowkey 的唯一性。接下来 HBase 依然会以不同的列来管理数据,但是这些列分别归属于不同的列簇。在 HBase 中,同一张表的数据,只需要保证列簇是相同的,而列簇下的列,可以是不相同的。所以由此可以扩展出非常多的列。在 HBase 中,对于同一张表,不建议定义过多的列簇,通常不要超过三个。而更多的数据,可以以列的方式来扩展。
从横向来看,HBase 中的记录,会划分为一个一个的 Region,存储在不同的 RegionServer 上。并且会在不同的 RegionServer 之前形成备份,以 Region 为单位提供了故障后自动恢复的机制。
最后,从整体来看,HBase 虽然还是以 HDFS 作为文件存储,但是他存储的数据不再是简单的文本文件,而是经过 HBase 优化压缩过的二进制文件,所以他的存储文件通常是不能够直接查看的。
RowKey
Rowkey 是用来检索记录的唯一主键,类似于 Redis 中的 key。访问 HBase 中的表数据,只能通过 Rowkey 来查找。访问 HBase 的数据只有三种方式:
1、通过 get 指令访问单个 rowkey 对应的数据。
2、通过 scan 指令,默认全表扫描。
3、通过 scan 指令,指定 rowkey 的范围,进行范围查找。
Rowkey 可以是任意字符串,最大长度是 64 KB,实际中通常用不到这么长。在 HBase 内部,Rowkey 保存为字节数组。存储时,会按照 Rowkey 的字典顺序排序存储。
在实际使用时,对 Rowkey 的设计是很重要的,往往需要将一些经常读取的重要列都包含到 Rowkey 中。并且要充分考虑到排序存储这个特性,让一些相关的数据尽量放到一起。比如我们创建一个用户表,经常会按用户 ID 来查询, 那 Rowkey 中一定要包含用户 ID 字段。而如果把用户 ID 放在 Rowkey 的开头,那数据就会按照用户 ID 排序存储,查询 Rowkey 时效率就会比较快。
列簇与列
HBase 中的列都是归属于某一个 Column Family(列簇) 的,HBase 在表定义中只有对列簇的定义,没有对列的定义。也就是说,列是可以在列簇下随意扩展的。要访问列,也必须以列簇作为前缀,使用冒号进行连接。列中的数据是没有类型的, 全部都是以字节码形式存储。同一个表中,列簇不宜定义过多。
物理上,一个列簇下的所有列都是存储在一起的。也就是说 HBase 是以列簇为单位来组织文件,对应 HDFS 中一个单独的目录。由于 HBase 对于数据的索引和存储都是在列簇级别进行区分的,所以,通常在使用时,建议一个列簇下的所有列都有大致相同的数据结构和数据大小,这样可以提高 HBase 管理数据的效率。
Versions
在 HBase 中,是以一个 {row,column,version} 这样的数据唯一确定一个存储单元,称为 cell。在 HBase 中,可能存在很多 cell 有相同的 row 和 column,但是却有不同的版本。多次使用 put 指令,指定相同的 row 和 column,就会产生同一个数据的多个版本。
默认情况下,HBase 是在数据写入时以时间戳作为默认的版本,也就是用 scan 指令查找数据时看到的 timestamp 内容。HBase 就是以这个时间戳降序排列来存储数据的,所以,HBase 去读取数据时,默认就会返回最近写入的数据。客户端也可以指定写入数据的版本,并且这个版本并不要求严格递增。
当一个数据有多个版本时,HBase 会保证只有最后一个版本的 cell 数据是可以查询的,而至于其他的版本,会由 HBase 提供版本回收机制,在某个时间进行删除。
另外,在使用 scan 查询批量数据时,Hbase 会返回一个已经排好序的结果。按照 列=>列簇=>时间戳 的顺序进行排序。也可以在scan 时,指定逆序返回。
#给basicinfo声明最多保存5个版本alter 'user',NAME => 'basicinfo',VERSIONS=>5#指定最少两个版本alter 'user',NAME => 'basicinfo',MIN_VERSIONS => 2#查询多个版本的数据。get 'user','1001',{COLUMN => 'basicinfo:name',VERSIONS => 3}#查询10个历史版本scan 'user',{RAW => true, VERSIONS => 10}
Namespace
在创建表的时候,还可以指定表所属的命名空间。例如:
create_namespace 'my_ns'create 'my_ns:my_table','fam'alter_namespace 'my_ns',{METHOD => 'set','PROPERTY_NAME' =>'PROPERTY_VALUE'}list_namespacedrop_namespace 'my_ns'
在 HBase 中,每个命名空间会对应 HDFS 上的 /hbase/data 目录下的一个文件夹。不同命名空间的表存储是隔离的。在 HDFS 上可以看到, HBase 默认创建了两个命名空间,一个是 hbase,这是系统的命名空间,用来存放 HBase 的一些内部表。另一个是 default,这个是默认的命名空间。不指定命名空间的表都会创建在这个命名空间下。

若有收获,就点个赞吧
0 人点赞
