基本名称
OLTP&OLAP
OLTP 的全称是 On-line Transaction Processing,中文名称是联机事务处理。其特点是会有高并发且数据量级不大的查询,是主要用于管理事务(transaction-oriented)的系统。此类系统专注于 short on-line-tansactions 如 INSERT、UPDATE、DELETE 操作。通常存在此类系统中的数据都是以实体对象模型来存储数据,并满足 3NF(数据库第三范式)。
OLAP 的全称是 On-line Analytical Processing,中文名称是联机分析处理。其特点是查询频率较 OLTP 系统更低,但通常会涉及到非常复杂的聚合计算。 OLAP 系统以维度模型来存储历史数据,其主要存储描述性的数据并且在结构上都是同质的。
星型模型
当所有维表都直接连接到“ 事实表”上时,整个图解就像星星一样,故将该模型称为星型模型。
星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余。
雪花模型
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的” 层次” 区域,这些被分解的表都连接到主维度表而不是事实表。
它的优点是:通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。雪花型结构去除了数据冗余。
Decision Support System
DSS,字面上来看就是在一定的业务场景下帮助做一些决策的系统,就是对大规模的数据做一些真实业务场景下的分析查询,根据结果做一些相关业务决策。
TPCDS 模型
TPCDS 模型模拟一个大型零售商的销售系统,包含多家专卖店,其中含有三种销售渠道:store(实体店)、web(网店)、catalog(电话订购),每种渠道使用两张表分别模拟销售记录和退货记录,同时包含商品信息(库存管理)和促销信息的相关表结构。
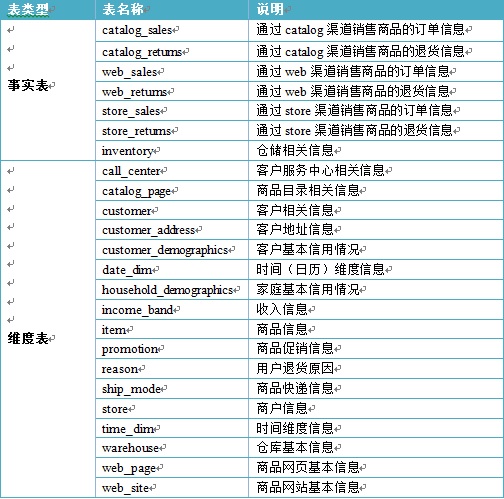
TPCDS 采用雪花型数据模型,三种渠道的销售、退货表、及总体的存货清单作为事实表,其他商品相关信息、用户相关信息、时间信息等其他信息等都作为维度表,同时各表命名达到见名识义,详细如下表所示:
| 表类型 | 表名称 | 说明 |
|---|---|---|
| 事实表 | catalog_sales | 通过catalog渠道销售商品的订单信息 |
| catalog_returns | 通过catalog渠道销售商品的退货信息 | |
| store_sales | 通过store渠道销售商品的订单信息 | |
| store_returns | 通过store渠道销售商品的退货信息 | |
| web_sales | 通过Web渠道销售商品的订单信息 | |
| web_returns | 通过Web渠道销售商品的退货信息 | |
| inventory | 仓储相关信息 | |
| 维度表 | call_center | 客户服务中心相关信息 |
| catalog_page | 商品目录相关信息 | |
| customer | 客户相关信息 | |
| customer_address | 客户地址信息 | |
| customer_demographics | 客户基本信用信息 | |
| date_dim | 时间维度信息 | |
| household_demographics | 家庭基本信用信息 | |
| income_band | 收入信息 | |
| item | 商品信息 | |
| promotion | 商品促销信息 | |
| reason | 用户退货原因 | |
| ship_mode | 商品快递信息 | |
| store | 商户信息 | |
| time_dim | 时间维度信息 | |
| warehouse | 仓库级别信息 | |
| web_page | 商品网页基本信息 | |
| web_site | 商品网站基本信息 | |
| 系统表 | dbgen_version | TPC-DS 的命令记录 |
测试步骤
测试分为以下几个流程,有先后顺序
- Load Test
- Power Test
- ThroughPut Test 1
- Data Maintenance Test 1
- Throughput Test 2
- Data Maintenance Test 2
Power test 是单线程处理一个 query stream(包含99个查询),而 Throughput test 是并行处S个(TPC-DS 要求 >= 4)query streams,相当于是压测。跑完性能测试以后就开始 Data maintenance test 做一些数据 refresh,替换成新的数据。
指标
测试完成以后,需求有指标来衡量结果。TPC-DS 给出了 3 个主要指标:
- Performance Metric,QPhDS@SF
第一个性能指标直接上原图,SF 控制了测试数据规模,Q 代表 query 个数,由于 Throughput test 会跑几批 query streams,总数记为  * 99,于是在
* 99,于是在  上面我们需要把真实 Power tes t的时间去乘上这个
上面我们需要把真实 Power tes t的时间去乘上这个  保证量纲。
保证量纲。
- Price-Performance Metric,$/kQphDS@SF
第二个价格-性能指标就是计算单位性能指标上的价格,  。
。
- System availability date
下载编译
CentOS/RHEL:
sudo yum install gcc make flex bison byacc git
Then run the following commands to clone the repo and build the tools:
git clone https://github.com/gregrahn/tpcds-kit.gitcd tpcds-kit/toolsmake OS=LINUX
编译后,得到:dsdgen 和 dsqgen。
TPC-DS 测试会生成 25 张表,其中包括 7 张业务数据的事实表,17 张业务数据的维度表,还有1张 TPC-DS 的系统表(与性能测试无关)。
/tools 目录下,tpcds.sql 文件里。很多数据平台可能不能直接使用,需要修改。建表语句的修改主要是依据不同环境支持的数据类型修改和一些基础语法修正,还需依照生成的数据的分割符在建表时指定分隔符。
以 hive 为例:integer 改为 int,time 改为 timestamp,去掉 NOT NULL,删除 primary key,指定分隔符 row format delimited fieldsterminated by ‘|’; 等等。
tpcds.sql 测试业务表
tpcds_ri.sql 创建约束外键
tpcds_source.sql
构建测试数据
通过 tools 下的 dsdgen 脚本来生成测试所需数据。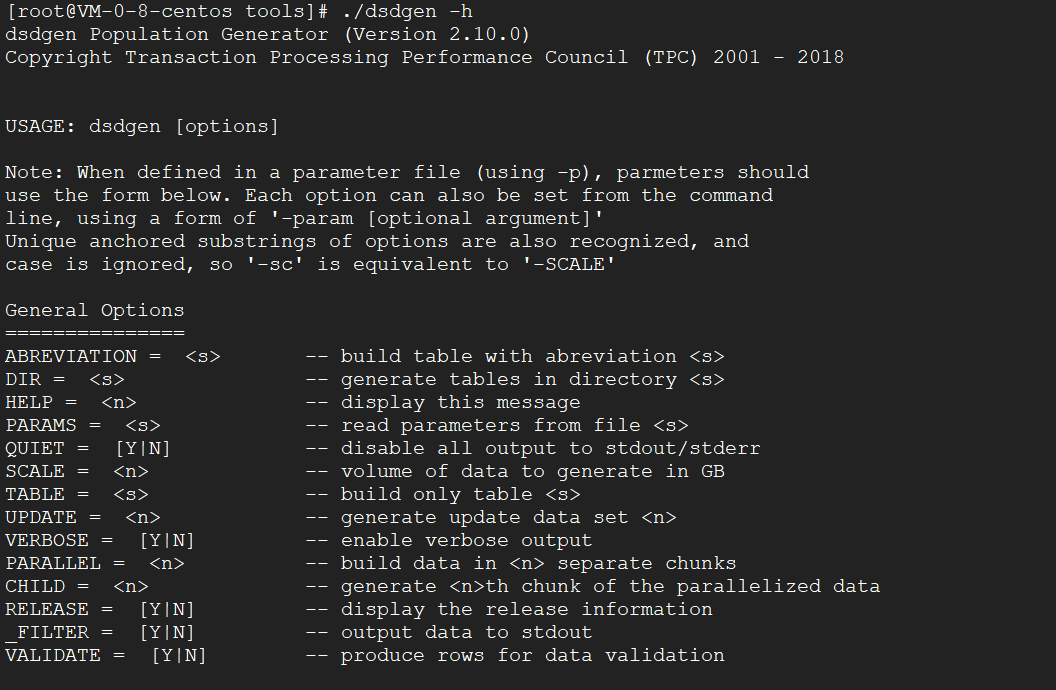

参数说明如下:
| 参数 | 说明 | 示例 |
|---|---|---|
| -sc | 测试数据量的大小。(单位GB) | 10表示10GB,1000表示1000GB(1TB) |
| -DELIMITER | 字段分隔符,默认 | | |
| -dir | 生成的数据文件写入的目录。 | data1tb |
| -TERMINATE | 每行最后是否加字段分隔符。 | N 或者 Y - N:每行最后不加字段分隔符。 - Y:每行最后添加字段分隔符。比如分隔符 |。 |
| -PARALLEL | 生成的数据分成几份。大数据量时会用到。 一条语句只能生成一个 chunk。因此设置了几个,就要执行几次。 |
5 |
| -CHILD | 当前命令生成第几个份。与 PARALLEL 配合使用 | 1 |
| -TABLE | 指定要生成数据的表 | web_returns |
# 目录需要提前创建好 不然会报错../dsdgen -scale 1 -dir /data/tpc-ds/tpcds-data -TERMINATE N

dsdgen 是个单线程程序,一般在测试过程中,会通过指定表名(“-TABLE”参数)以多个进程并发(每个进程对应1张表)的方式来加快生成数据:
./dsdgen -SCALE 1 -DISTRIBUTIONS tpcds.idx -TERMINATE N -TABLE time_dim
因为事实表普遍比较大,所以考虑使用 dsdgen 通过分块的方式加速生成数据:
./dsdgen -SCALE 1 -DISTRIBUTIONS tpcds.idx -TERMINATE N -TABLE catalog_sales -PARALLEL 10 -CHILD 1
命令中:“-PARALLEL 10” 参数表示整个表分成 10 块,“-CHILD 1” 参数表示生成第 1 块;同时启动 10 个 dsdgen 进程,每个进程 CHILD编号递增,加速效果就出来了。
导入测试数据
:::tips 说明
- 如果是在Linux环境运行生成的数据文本,每行的结束符是’\n’。
- 如果是在Windows环境运行生成的数据文本,每行的结束符是’\r\n’。
:::
LOAD DATA LOCALINFILE 'call_center.dat' -- 访问的导入文件INTO TABLE call_center -- 导入的表FIELDS TERMINATED BY '|' -- 字段分隔符LINES TERMINATED BY '\n'; -- 每行结束符-- trailing nullcols -- 表示支持导入空值

生成查询sql

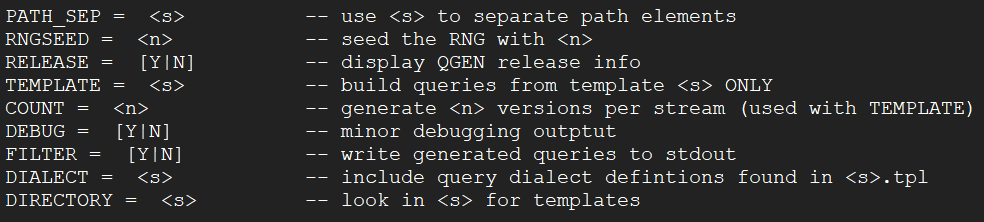
| 参数 | 说明 | 示例 |
|---|---|---|
| -TEMPLATE | 指定模板 | |
| -DIRECTORY | 模板所在的目录 | |
| -DIALECT | 方言。设置生成哪种数据库的SQL语法。支持的数据库类型包括oracle,db2,sqlserver,netezza,ansi。可以在 query_templates 目录下查看有哪些 tpl 文件。(非 query 开头的) |
#!/bin/sh
for i in `seq 1 99`
do
./dsqgen -DIRECTORY ../query_templates/ -TEMPLATE "query${i}.tpl" -DIALECT ansi -FILTER Y > ../../sql/query${i}.sql
done
MySQL 5.7 问题点
with as
MySQL 5.7 不支持 with as 语法,可以使用 create or replace view 代替。
使用 create view 时,如果有 union ;as 后不能用()
# 该语句会报错,去掉 () 后 ok
CREATE VIEW view_test_main
AS
(
SELECT * FROM test_main
UNION ALL
SELECT * FROM test_main2
);
衍生表
日期相加
SELECT DATE_ADD(cast('2001-01-12' AS date), INTERVAL 30 DAY);

若有收获,就点个赞吧
0 人点赞
