Chapter 1 引言
1.1 统计学介绍
统计学习(Statistic Learning),是一套以理解数据为目的的庞大的工具集。统计学习工具分为两类,有指导(supervised)的学习和无指导的(unsupervised)学习。
(1)有指导的统计学习工具主要有两种用途:一是面向预测的统计模型的建立,二是对一个或者多个给定的输入估计某个输出(有X有Y)。(2)无指导的统计学习问题中,有输入数据但是没有输出结果,从中可以学习到数据和结构的关系,是面向推测的统计模型的建立(只有X没有Y)
1.2 统计学简史
19世纪初期,勒让德(Legendre)高斯(Gauss),最小二乘法,线性回归的最早形式。线性回归可用于预测定量变量,如一个的薪资水平等等。
1936年,费舍尔(Fisher)提出线性判别分析,可以预测定性变量,如病人的死活,股市的涨跌等。
20世纪40年代,许多学者提出替代线性判别分析的方法,如逻辑斯蒂回归。
20世纪70年代初,内德尔(Nelder)和韦德伯恩(Wedderburn)提出一个新概念——-广义线性模型。
20世纪80年代中期,分类回归数,非线性模型。
1986年,广义可加的模型
Chapter2 统计学习的基本内容
输入变量(input vairable) :有几个不同称呼,如预测变量、自变量、属性变量、有时候就称为变量。
:有几个不同称呼,如预测变量、自变量、属性变量、有时候就称为变量。
输出变量 :我们称为响应变量或者因变量。
:我们称为响应变量或者因变量。 ,
, 为提供给的系统信息,
为提供给的系统信息, 为随机误差项。
为随机误差项。
2.1 什么条件需要估计函数f
估计函数f的主要原因有两个:预测(prediction)和推断(inference)
预测(只需要预测Y值,不需要知道X与Y的关系,选择光滑模型)
许多情形下,输入集X是现成的,但是输出Y是不易获得的。这是,由于误差项的均值为0( = 0),那么可以通过下式预测Y:
= 0),那么可以通过下式预测Y: =
=  (X)
(X)
这里的 是对Y的预测,
是对Y的预测, 是对f的预测,
是对f的预测, 是黑箱。如果该黑箱能提供准确的预测Y,并不会十分追求f的确切形式。
是黑箱。如果该黑箱能提供准确的预测Y,并不会十分追求f的确切形式。 做为响应变量Y的预测,其精确性依赖两个量,一个是可约误差(reducible error),另一个是不可约误差(irreducible error)。
做为响应变量Y的预测,其精确性依赖两个量,一个是可约误差(reducible error),另一个是不可约误差(irreducible error)。
可约误差可以降低(选用合适的模型),不可约误差无法降低(样本噪声),不可约误差提供了Y预测精度的一个上界,这个上界在实践中是未知的。
推断(想知道f,即X和Y的关系,选择欠光滑模型)
可能涉及的问题有
1)哪些预测变量与响应变量有关?
2)响应变量与每个预测因子之间的关系是什么?
3)Y与每个预测变量的关系能否用一个线性方程概括,还是需要更加复杂的形式?
2.2 如何估计f
估计方法可以分为两类:参数方法和非参数方法
参数方法(选择模型——数据拟合)
参数方法是一种基于模型估计的两阶段方法。
(1)首先,假设函数f具有一定的形式或形状,例如一个常用的假设是f是线性的,具有如下的形式
一旦假设f是线性的,估计f的问题就被简化了。不需要估计任意一个p维函数,只需要估计系数β。
(2)一旦模型被选定后,就需要用训练数据集去拟合或者训练模型。在线性模型中就是估计参数β的值。最常用的方法是最小二乘法。
参数方法的缺陷是选定的模型并非与真正的f在形式上是一致的,假如我们选择的模型与真实的f差距过大,这样估计的效果也很差。此类问题的解决方式之一是选择光滑模型拟合不同形式的函数f,拟合光滑度更强的模型需要更多的参数估计,可能会导致过拟合现象的出现。
非参数方法
非参数方法不需要对函数f的形式事先做明确的假设。相反,这类方法追求的是最接近数据点的估计
非参数方法相较于参数方法的优点表现为:不限于函数f的具体形式,在更大的范围内选择更加适宜f形状的估计。
非参数方法的缺点是,无法将估计f的问题简化到仅仅对少数参数进行估计的问题,所以为了获得f更为精确的估计,往往需要大量的观测点。
2.3 预测精度和模型解释性的权衡
光滑度较高的模型,在一个较为广泛的函数形状范围内对f的估计。欠光滑的模型,在形式上收到限定,只能在一个相对较窄的函数范围内来对f进行估计。那么为什么会选择一个更受限定的方式而不是光滑模型来建模呢?若建模的目的在于推断,需要模型的解释性比较强,那么采用结构限定的模型(光滑度低的模型)。若建模的目的在于预测,则选择光滑度更高的模型更加接近实际的情况,是更好的选择。
2.4 指导学习和无指导学习
指导学习:对于每一个预测变量观测值x都有相应的响应变量y。建模的目的是通过建立预测变量和响应变量之间的关系,精准预测响应变量或者更好的理解响应变量和预测变量之间的关系。例如:线性回归,逻辑斯蒂回归,广义可加模型(GAM),提升方法和支持向量机(SVM)等方法。
无指导学习:只有预测变量的观测变量x,这些变量没有相应的响应变量与之对应。理解变量之间或观测之间的关系即可。例如:聚类分析。
2.5 回归和分类问题
变量分为定量和定性两种类型
定量变量呈数值型,例如年龄、身高或者收入、股票的价格等等。定性变量也称为分类变量,定性变量,如一个人的性别(男、女),所购买的产品(A、B、C)等。习惯将响应变量为定量的问题称为回归分析问题,将具有定性响应变量的问题定义为分类问题。但这并不是绝对的。
2.6 评价模型精度
2.6.1 拟合效果检验
对于一个给定的观测,需要定量测量预测响应值与真实响应值之间的接近程度,在回归中,最常用的评价准则是均方误差,其表达式如下:
MSE = 


其中 是第i个观测点上应用
是第i个观测点上应用 的预测值。如果预测的响应值与真实的响应值很接近,则均方误差会非常小。所以均方误差是用来评估预测值和真实值偏差程度的一个指标。在实践之中,计算训练均方误差(training MSE)相对容易,而估计测试均方误差(test MSE)相对困难。
的预测值。如果预测的响应值与真实的响应值很接近,则均方误差会非常小。所以均方误差是用来评估预测值和真实值偏差程度的一个指标。在实践之中,计算训练均方误差(training MSE)相对容易,而估计测试均方误差(test MSE)相对困难。
训练均方误差是用训练数据集计算出来,而这些训练数据集是用来拟合模型的,所以预测精准的程度一般比较高。一般而言,我们并不关心这个模型在训练集中表现如何,而真正感兴趣的在于将模型用于测试数据获得怎样的预测精度。这个时候,我们需要选择使测试均方最小的模型,测试均方误差决定了这个模型的推广性,测试均方误差的表达式如下:
Ave
测试均方误差需要掌握大量的测试样本数据,计算如上的函数。该模型的测试均方误差最小,不一定会是该模型的训练均方误差最小。
当模型的光滑度增加时,观察到训练均方误差单调递减,测试均方误差呈U形分布(先减后增),这是统计学习的一个基本特征。当所建的模型有一个较小的训练均方误差,但是却有一个较大的测试均方误差,就称为该数据的过拟合。
2.6.2 偏差-方差权衡
期望测试均方误差能分解成三个基本量的和,分别为: 的方差、
的方差、 的偏差的平方和和误差项
的偏差的平方和和误差项 的方差,具体而言:
的方差,具体而言:
E = Var(
= Var( ) +
) +  + Var(
+ Var( )
)
E 是模型的期望测试均方误差,是用大量的数据集重复估计f后求的平均测试均方误差。
是模型的期望测试均方误差,是用大量的数据集重复估计f后求的平均测试均方误差。
为使期望测试误差达到最小,需要选择一种方法使偏差(bias)和方差(variance)同时达到最小。偏差:训练模型得到的样本预测偏离真实值的程度(由算法或者模型本身带来)。方差:输入不同的数据集输入模型时,模型预测值之间的差别大小。也就是说这个模型依赖样本的程度,如果方差过高,模型的推广性就差。
一般而言,使用光滑度更高的方法,所得的模型方差会增加,偏差会减少。这两个比值的相对变化率会导致测试均方误差整体的增加或者减少。可以调整模型的光滑度使期望均方误差降低。在实践中,要使一个统计学习模型测试性能好,就要考虑偏差、方差和测试均方误差之间权衡的问题,使该模型有较小的偏差和方差。
2.6.3 分类模型
贝叶斯分类器
贝叶斯分类器是简单的分类模型,它将每个观测值分配到它最大可能所在的类别中,将这个类作为它的预测值即可,这里的响应变量为定性变量。换句话说,将一个待判的 分配到下面的式子中的最大的j类上是合理的。
分配到下面的式子中的最大的j类上是合理的。 (Y = j | X =
(Y = j | X =  )
)
其实这就是一个条件概率,它给定了观测向量 条件下Y = j的概率。比如说,在一个二分类的问题中,有两个可能的响应值,一个类别称为1,另一个为2. 若
条件下Y = j的概率。比如说,在一个二分类的问题中,有两个可能的响应值,一个类别称为1,另一个为2. 若 > 0.5,(在X=
> 0.5,(在X= 的条件下Y=1的概率大于0.5),该贝叶斯分类器就将该观测值的类别预测为1,否则预测类别为2.
的条件下Y=1的概率大于0.5),该贝叶斯分类器就将该观测值的类别预测为1,否则预测类别为2.
但是现实生活很难知道给定X后Y的条件分布,所以现实中贝叶斯分类器的应用是不可能的,贝叶斯的方法对于其他方法而言是一种难以达到的黄金标准。贝叶斯分类器将产生最低的测试错误率,称为贝叶斯错误率,贝叶斯错误率类似于不可约误差。
K最邻近方法
许多方法尝试在给定X后先估计Y 的条件分布,然后将一个给定的观测分类到估计分布概率的最大类别中。其中一个方法就是K最邻近(KNN)分类器。给一个正整数K和一个测试观测值 ,KNN分类器从训练集中识别K个最靠近
,KNN分类器从训练集中识别K个最靠近 的点开始,用
的点开始,用 表示K个点的集合,然后对每个类别 j 分别用
表示K个点的集合,然后对每个类别 j 分别用 中的点估计一个分值作为条件概率的估计,这个值等于 j:
中的点估计一个分值作为条件概率的估计,这个值等于 j:
最后,对KNN方法运用贝叶斯分类将观测值 分配到概率最大的类中。
分配到概率最大的类中。
举1个栗子,左图绘制了一个由6个蓝色和6个橙色观测值组成的小训练集。问题的目标是对黑色十字标记的点做出预测。假设K=3,那么KNN首先识别最靠近十字处的三个观测值。绿色圆形代表这三个点构成的领域。蓝色点的估计概率是2/3,橙色点的估计概率是1/3.
于是KNN预测黑色十字为蓝色。右图,当K=3时,将KNN方法用于 和
和 中所有可能的值,绘制相应的KNN决策边界。
中所有可能的值,绘制相应的KNN决策边界。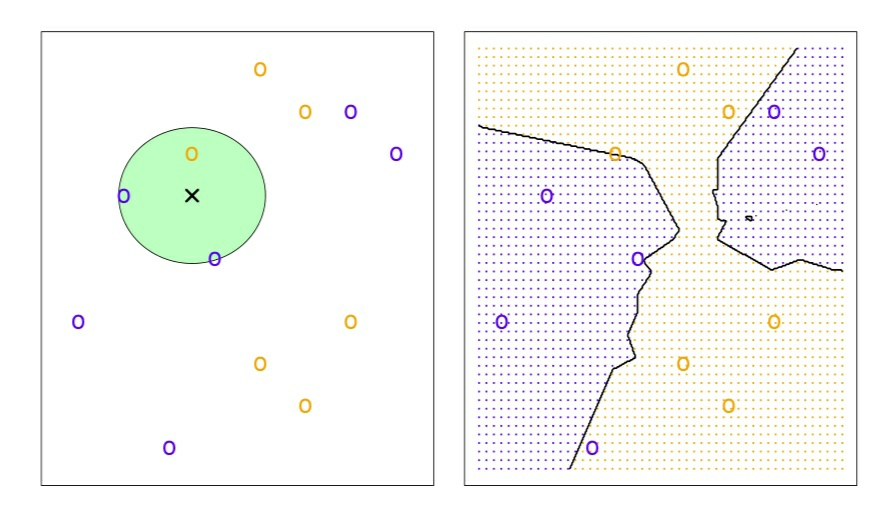
K的选择对获得KNN分类器有根本性的影响。当 增加时(K降低),模型的光滑度增加,训练错误率递减,测试错误率呈现为U形,递增后就出现了过拟合(过光滑)现象。
增加时(K降低),模型的光滑度增加,训练错误率递减,测试错误率呈现为U形,递增后就出现了过拟合(过光滑)现象。
Chr 02 习题
1)梳理偏差、方差、训练误差、测试误差和贝叶斯(或不可约)误差曲线这几个概念。
误差(包括训练误差和测试误差)都等于偏差,方差与噪声的和。偏差:训练模型得到的样本预测偏离真实值的程度(由算法或者模型本身带来)。方差:输入不同的数据集输入模型时,模型预测值之间的差别大小。也就是说这个模型依赖样本的程度,如果方差过高,模型的推广性就差。训练误差:用训练数据集拟合模型计算得到的误差。测试误差:用测试数据集测试模型计算得到的误差。贝叶斯误差:样本噪声。他们的关系如下所示:
2)一个光滑度高的(或者光滑度低)的回归模型或者分类模型的优点和缺点是什么?什么情况下需要光滑度高的模型合适?
光滑度高的模型可以更好地拟合非线性情况,光滑度高的模型偏差小,方差大,容易造成过拟合的情况。光滑度高的模型适合拟合非线性模型,适合预测,
3)比较参数模型和非参数模型之间的不同。优缺点是什么?
参数方法将估计f的问题简化为对参数的估计,优点是比较简单,缺点是与实际的f可能会存在很大区别。适合推断。非参数方法追求接近数据点的估计优点是不限定函数f的具体形式,缺点是无法将估计f的问题简化到对少数参数进行估计,所以常常需要大量的观测点,适合预测。

若有收获,就点个赞吧
0 人点赞
