Chapter 3 线性回归
线性回归是一类简单易学的有指导的学习方法(对于每一个观测变量X都有与之对应的响应变量Y),是预测定量响应变量的一个有用的工具。在这章中,我们将回顾线性回归模型的主要思路以及最常用的拟合模型的最小二乘法。
3.1 简单线性回归
简单线性回归:是一种根据单一预测变量X预测定量响应变量Y的方法。它假定X和Y之间存在线性关系。在数学上,可以将这种线性关系记为: (3.1)
(3.1)
“ “可视为“近似建模”,式子(3.1)可视为Y对X的回归。
“可视为“近似建模”,式子(3.1)可视为Y对X的回归。 被称为模型的系数或者参数。一旦通过训练数据集估计出这些系数,我们就可以通过计算
被称为模型的系数或者参数。一旦通过训练数据集估计出这些系数,我们就可以通过计算 (3.2)
(3.2)
预测未来的销量。其中, 表示在
表示在 的基础上对
的基础上对 的预测。符号“
的预测。符号“ ”表示为对一个未知的参数或者系数的估计值,或者表示响应变量的预测值。
”表示为对一个未知的参数或者系数的估计值,或者表示响应变量的预测值。
3.1.1 估计系数
在实践中,系数都是未知的,为了使模型具有预测能力,我们必须根据数据集估计系数 和
和 。我们希望由这两个系数产生的直线尽可能的接近观测数据点。测量接近程度(closeness)的方法有很多,不过到目前为止,最常用的方法是残差平方和最小化准则。
。我们希望由这两个系数产生的直线尽可能的接近观测数据点。测量接近程度(closeness)的方法有很多,不过到目前为止,最常用的方法是残差平方和最小化准则。
根据变量 的第
的第 个值,用来估计
个值,用来估计 。
。 代表第
代表第 个残差——第个观测到的响应值和第个用线性模型预测出的响应值之间的差距。定义为残差平方和(residualsum of squares,RSS)
个残差——第个观测到的响应值和第个用线性模型预测出的响应值之间的差距。定义为残差平方和(residualsum of squares,RSS) (3.3)**
(3.3)**
通过微积分计算得知(求偏导,令其等于0),使RSS达到最小的参数估计值为:
 (3.4)
(3.4)
这里的 是样本均值,式(3.4)定义了简单线性回归的最小二乘估计(least squares coeffcient estimate). 这样就可以根据样本数据得到参数的最小二乘估计(
是样本均值,式(3.4)定义了简单线性回归的最小二乘估计(least squares coeffcient estimate). 这样就可以根据样本数据得到参数的最小二乘估计( ),使残差平方和达到最小。
),使残差平方和达到最小。
3.1.2 评估系数估计值的准确性
在上一章中有提到,假设的 之间的真实关系表达式如下
之间的真实关系表达式如下 ,其中
,其中 是均值为零的随机误差项。
是均值为零的随机误差项。 为未知函数,若可用线性函数近似,那么这种关系可以记为:
为未知函数,若可用线性函数近似,那么这种关系可以记为: (3.5)
(3.5) 是截距,
是截距, 是斜率。误差项包括了在这个模型中我们没有考虑到的因素:如真实的关系可能不是线性的,或者有其他变量导致了的变化,也可能存在测量误差。式(3.5)给出的模型定义了总体回归直线(population regression line),总体回归直线是对的最佳线性近似。
是斜率。误差项包括了在这个模型中我们没有考虑到的因素:如真实的关系可能不是线性的,或者有其他变量导致了的变化,也可能存在测量误差。式(3.5)给出的模型定义了总体回归直线(population regression line),总体回归直线是对的最佳线性近似。
在实际的数据中,真实关系一般是未知的,我们只能根据观测数据得到最小二乘估计,计算最小二乘线。
最小二乘线和总体回归直线的概念是对标准统计方法(利用样本信息估计一个较大总体的特征)的一种自然延伸。最小二乘估计具有无偏性:如果在特定的数据集的基础上估计,则估计值不会恰等于。但是,如果我们从大量数据集上得到估计值求平均,它们的均值将恰为真值!图3-1用 这个模型生成了10个不同的数据集,并绘制了10条相应的最小二乘线。这十条最小二乘线的平均(深蓝色)非常接近真实总体回归直线。
这个模型生成了10个不同的数据集,并绘制了10条相应的最小二乘线。这十条最小二乘线的平均(深蓝色)非常接近真实总体回归直线。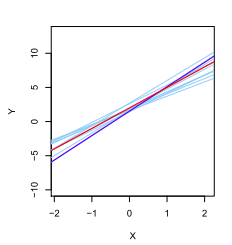
图 3-1 总体回归直线为红色,深蓝色的为最小二乘线。淡蓝色的为10条最小二乘线的平均,每条都是根据一个独立的随机观测集计算出的。各条最小二乘线是不同的,但平均而言,最小二乘线相当接近总体回归直线。
我们知道,单一数据集估计参数并不准确,那么估计值偏离真值的程度有多远呢?为了探究和 与真实值和
与真实值和 的接近程度,我们可以计算和的标准误差,标准误差告诉我们
的接近程度,我们可以计算和的标准误差,标准误差告诉我们 和偏离真实和的平均量。这种偏差随着n的增大而减小。标准误差公式如下:
和偏离真实和的平均量。这种偏差随着n的增大而减小。标准误差公式如下: ,
, (3.6)
(3.6)
其中 ,在一般情况下,
,在一般情况下, 是未知的,但是可以从数据中估计出来。对的估计被称为残差标准误(residual standard error), 由公式
是未知的,但是可以从数据中估计出来。对的估计被称为残差标准误(residual standard error), 由公式 所定义。
所定义。
标准误差可用于计算置信区间(confidence interval)。95%置信区间被定义为一个取值范围:该范围有95%的概率会包含未知参数的真值。对于线性回归模型, 的置信区间约为:
的置信区间约为: ,
, (3.7)
(3.7)
标准误差也可以用来对系数进行假设检验。最常用的假设检验包括对零假设(null hypothesis)和备择假设(alternative hypothesis)进行检验。比如说,我们检测一下X和Y之间的关系。零假设 之间没有关系。备择假设
之间没有关系。备择假设 :之间有一定的关系,从数学上来说,这就是检验
:之间有一定的关系,从数学上来说,这就是检验 (3.8)
(3.8)
因为如果 ,则模型简化为
,则模型简化为 ,这时X和Y不相关。为了检验零假设,需要确定距离零是否足够远,从而能确定是非零的。在实践中,我们采用t统计量检验:
,这时X和Y不相关。为了检验零假设,需要确定距离零是否足够远,从而能确定是非零的。在实践中,我们采用t统计量检验: (3.9)
(3.9)
如果X和Y无关(),那么我们的预期式(3.9)将服从自由度为n-2的t分布。t分布有钟型结构,当样本量n大于30的时候,它就很类似于正态分布。这时,计算任意观测值大于等于 的概率就十分简单了,我们称这个概率为p值。如果看到一个很小的p值,这时候拒绝另加上色,就可以推断预测变量和响应变量之间存在关联。典型的拒绝零假设的临界的p值是5%或1%。
的概率就十分简单了,我们称这个概率为p值。如果看到一个很小的p值,这时候拒绝另加上色,就可以推断预测变量和响应变量之间存在关联。典型的拒绝零假设的临界的p值是5%或1%。
3.1.3 评价模型的准确性
一旦我们接受了备择假设(在这里也等同于确定了系统的准确性)后,就会很自然地想要量化模型拟合数据的程度。判断线性回归的拟合质量通常使用两个相关的量:残差标准误(residual standard error,RSE)和 统计量。
统计量。
残差标准误
我们知道,每个观测都是有误差项的。由于这些误差项的存在,即使我们知道真正的回归线,也不能用X对Y做出完美预测。RSE是对的标准偏差的估计。大体而言,它是响应值偏离真正的回归直线的平均量。公式为: (3.10)
(3.10)
RSE被认为是对模型(3.5)失拟(lack of fit)的度量。如果用该模型得到的预测值都非常接近真实值(RSE的值会很小),则可以认为该模型很好的拟合了数据。统计量
RSE提供了一个模型对数据失拟的测度方法,但是因为它是以Y的单位衡量的,所以并不清楚构成良好的RSE的要素有哪些。统计量是衡量拟合度的另一个标准,采取比例(被解释方差的比例)形式,所以它的值总在0和1之间。用下列公式计算: (3.11)
(3.11) 是总平方和(total sum of squares),反应了观测值
是总平方和(total sum of squares),反应了观测值 围绕均值
围绕均值 的离散程度,可以认为是在执行回归分析前响应变量中的固有变异性。RSS是残差平方和,是进行回归后无法解释的变异性。因此,
的离散程度,可以认为是在执行回归分析前响应变量中的固有变异性。RSS是残差平方和,是进行回归后无法解释的变异性。因此, 测量的是响应变量进行回归后被解释的(或者被消除的)变异性。测量的是Y的变异中能被X解释的部分所占比例。
测量的是响应变量进行回归后被解释的(或者被消除的)变异性。测量的是Y的变异中能被X解释的部分所占比例。 统计量接近0说明回归没有解释太多响应变量的变异,这可能是因为线性模型是错误的,也可能是因为固有误差项
统计量接近0说明回归没有解释太多响应变量的变异,这可能是因为线性模型是错误的,也可能是因为固有误差项 较大,亦或者两者兼有。统计量与RSE相比更容易解释,因为它总是位于0和1之间,RSE则不然。然而,确定何为“好”值仍然十分具有挑战性,这取决于具体的应用环境。统计量衡量了X与Y之间的线性关系。而相关性(correlation)也可以衡量X与Y之间的线性关系,相关性的定义为:
较大,亦或者两者兼有。统计量与RSE相比更容易解释,因为它总是位于0和1之间,RSE则不然。然而,确定何为“好”值仍然十分具有挑战性,这取决于具体的应用环境。统计量衡量了X与Y之间的线性关系。而相关性(correlation)也可以衡量X与Y之间的线性关系,相关性的定义为: (3.12)
(3.12)
这意味着 可以代替评估线性模型的拟合度。在简单线性回归模型中,
可以代替评估线性模型的拟合度。在简单线性回归模型中, ,然而在多元线性回归模型中,相关系数的平方无法用来评估线性模型的拟合度,因为它只是衡量一对变量之间的联系。将在多元回归中承担评价线性回归的模型拟合度的任务。
,然而在多元线性回归模型中,相关系数的平方无法用来评估线性模型的拟合度,因为它只是衡量一对变量之间的联系。将在多元回归中承担评价线性回归的模型拟合度的任务。
3.2 多元线性回归
简单线性回归是用单个预测变量预测响应变量的一种有用的方法。然而在实践中,预测变量常常不止一个,此时可以扩展简单线性回归模型,使其包含多个预测变量。多元回归模型的形式为: (3.13)
(3.13)
其中 代表第j个预测变量,
代表第j个预测变量, 代表第j个预测变量和响应变量之间的关联。
代表第j个预测变量和响应变量之间的关联。 可以解释为所有其他预测变量保持不变的情况下,增加一个单位对产生的平均效果。
可以解释为所有其他预测变量保持不变的情况下,增加一个单位对产生的平均效果。
3.2.1 估计回归系数
与简单线性回归中的情况类似,多元线性回归中的回归系数 是未知的,需要进行估计。对于给定的
是未知的,需要进行估计。对于给定的 可以用如下公式进行预测:
可以用如下公式进行预测: (3.14)
(3.14)
与简单线性回归相同,多元线性回归也是用最小二乘法进行估计。选择使残差平方和RSS最小: (3.15)
(3.15)
能最大限度减小RSS的即为多元回归系数的最小二乘估计。多元回归的估计形式稍微复杂,用矩阵代数表示最为简便。可以用R来进行估计。
但是在多元线性回归中有一个问题,观测变量中可能存在潜在的相关性。如下面给出一个例子,Advertising(广告)数据集记录了该产品在200个不同市场的销售情况及该产品在每个市场中3类广告媒体的预算。这三类媒体分别是:TV(电视),radia(广播),newspaper(报纸)。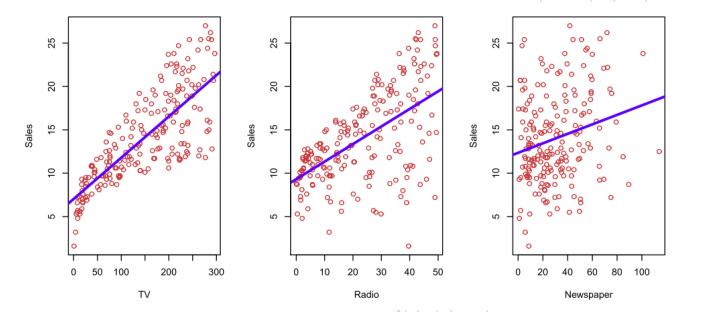
图3-1 advertising(广告)数据集。蓝色的线为最小二乘法的拟合线
利用这三类媒体和销量建立简单的线性回归模型,其中每一个都用不同的广告媒体作为预测变量。如下所示
表3-1 简单线性回归的系数估计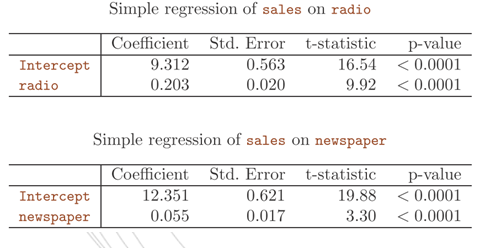
Simple regression of sales on TV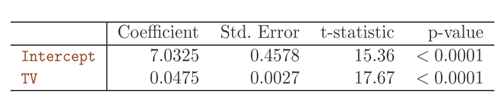
为每个预测变量建立一个单独的简单回归模型时,每个回归方程都会忽略其他两种媒体,对销售量受某种媒体的影响的估计可能是有误导性的。
当我们扩展简单线性模型,建立多元线性回归方程时,会发现不一样的结果:
表3-2 sales关于radio,TV和newspaper的多元线性回归的最小二乘估计系数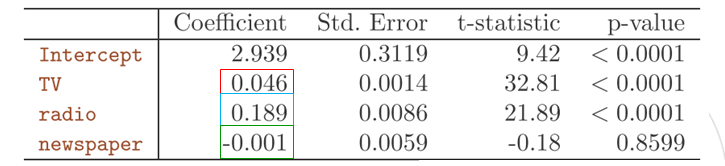
可以看出,TV和radio两变量的多元回归系数与简单线性回归系数估计非常相似。然而,newspaper在简单线性回归中的系数估计是显著不为零的,但是在多元回归模型中却接近于零切不再显著,相应的p值显著,约为0.86.这说明简单回归系数和多元回归系数的可能有着极大的差异。为什么会出现这种现象呢,我们计算了TV,radio,newspaper和sales之间的相关矩阵,如表3-3所示:
表3-3 Advertising数据中,TV,radio,newspaper和sales的相关矩阵
表中可见radio和newspaper之间的相关性为0.35,这表明在报纸广告费更高的市场上,对广播广告的投入也趋于更高(预测变量之间有着比较高的相关性)。现在假设多元回归是正确的,报纸广告对销售没有直接影响,但是广播广告能增加销量。那么在广播广告费较高的市场,销量也会趋于更高,但是相关矩阵显示,在市场上的报纸广告投入往往也会更高。因此,尽管报纸广告实际上并不影响销量,由于简单线性回归中只检查sales和newspaper之间的关系,于是导致了在简单线性回归中观察到的商品高销量(sales)和报纸(newspaper)之间的相关关系。实际上,newspaper是通过radia对sales的影响来获得“认可”。
3.3.2 一些重要问题
在进行多元线性回归时,通常有一些重要的问题,如:
(1)预测变量 中是否至少有一个可以用来预测响应变量?
中是否至少有一个可以用来预测响应变量?
(2)所有预测变量都有助于解释吗?还是仅仅预测变量中的一个子集对预测有用?
(3)模型对数据的拟合程度如何?
(4)给定一组预测变量的值,响应值应该为多少?所作预测的准确程度如何?
1 响应变量和预测变量是否有关系?
与简单线性回归类似,我们用假设检验回答这个问题。在这里,我们要问的是所有的回归系数是都均为零,即 是否成立。
是否成立。
检验零假设: , 备择假设:至少有一个不为0
, 备择假设:至少有一个不为0
这个假设需要计算F统计量: (3.16)
(3.16)
如果线性回归假设是正确的,可知 {
{ }
}
进一步,若 为真,则有{
为真,则有{ }=
}=
因此,当响应变量与预测变量无关,F统计量应该接近1. 如果 为真,那么{}
为真,那么{} ,所以我们预计F大于1. 一个较大的F统计量表明,至少有一个预测变量与响应变量相关。但是如果F统计量更加接近1一点呢?F统计量需要多大才能拒绝,并得出相关性存在的结论呢?事实证明,这些问题的答案取决于n和p的值。如果n很大,即使F统计量只是略大于1,可能也仍然提供了拒绝的证据。相反,若n较小,则需要较大的F统计量才能拒绝
,所以我们预计F大于1. 一个较大的F统计量表明,至少有一个预测变量与响应变量相关。但是如果F统计量更加接近1一点呢?F统计量需要多大才能拒绝,并得出相关性存在的结论呢?事实证明,这些问题的答案取决于n和p的值。如果n很大,即使F统计量只是略大于1,可能也仍然提供了拒绝的证据。相反,若n较小,则需要较大的F统计量才能拒绝
2 选定重要变量.
多元回归分析的第一步是计算F统计量并检查相应的p值,如果我们根据p值得出至少有一个预测变量和响应变量有关的结论,那么自然想知道哪些变量是和响应变量有关的。但是如果预测变量数p很大,我们有可能得出一些错误结论(如果p值足够大,肯定能观察到一个碰巧小于0.05的p值)。所有的预测变量都可能与响应变量有关,但常见的情况是只和预测变量的一个子集有关。确定哪些预测变量与响应变量有关,以建立只包含预测变量的模型的任务被称为变量选择(variable selection)。
包含 个变量的模型共有
个变量的模型共有 个,尝试预测变量的每一个可能的子集是不可能的。所以需要一种自动,高效的方法来选出少量待考虑的模型。有三种经典方法可以完成这个任务:
个,尝试预测变量的每一个可能的子集是不可能的。所以需要一种自动,高效的方法来选出少量待考虑的模型。有三种经典方法可以完成这个任务:
(1)向前选择(forword selection),从零模型(null model)——只含有截距但不含预测变量的模型开始。建立简单的线性回归模型,并把使RSS最小的变量添加到零模型中。然后再加入一个新变量,得到双变量模型,新加入的变量是使新模型的RSS最小的变量。这一过程持续到满足某种停止规则为止。
(2)向后选择(backward selection)。先从包含所有变量的模型开始。并删除p值最大的变量——统计学上最不显著的变量,拟合完包含(p-1)个变量的新模型后,再删除p值最大的变量。此过程持续到满足某种停止规则为止。
(3)混合选择(mixed selection)。这是对向前和向后选择的综合。与向前选择相同,我们从不含变量的模型开始,向模型中添加拟合最好的变量,然后依次增加变量。如果新加入变量,已有的p值可能会变大。因此,一旦模型中的某个变量的p值超过一定的阈值时,就从模型中删除该变量。我们不断执行这些向前或者向后的步骤,直到模型中所有变量的p值都足够低,且模型外的任何变量加入后模型都将有较大的p值。
当p>n时,不能使用向后选择,而向前选择在各个情况下都能使用。
3 模型拟合
两个最常见的衡量模型拟合的优劣指标是 . 它们在多元回归中的计算和解释与在普通线性回归中相同,这里的
. 它们在多元回归中的计算和解释与在普通线性回归中相同,这里的 , p是系数个数。
, p是系数个数。
4 预测
一旦拟合出多元回归模型,但在预测中也具有三类不确定性。
(1)系数估计的不准确性(可约误差)
(2)线性模型只是对现实的一种近似(可约误差)
(3)不可约误差的存在
3.3 回归模型中的其他注意事项
3.3.1 定性预测变量
预测变量是定性的应该如何处理?
如果一个定性预测变量(也称为因子(factor)只有两个水平或者可能的取值,那么将它纳入回归模型是十分简单的。我们只需要给二值变量创建一个指标,或者称为哑变量(dummy variable))。例如我们可以基于gender变量创建一个新变量,响应变量为信用卡债务: (3.17)
(3.17)
并在回归方程中使用这个变量,从而有以下模型: (3.18)可以解释为男性的平均信用卡债务,
(3.18)可以解释为男性的平均信用卡债务, 为女性的平均信用卡债务,所以是男性和女性之间信用卡债务的差异。
为女性的平均信用卡债务,所以是男性和女性之间信用卡债务的差异。
当定性预测变量有两个以上的水平时,我们可以创建更多的哑变量。
3.3.2 线性模型的扩展
在线性模型中两个重要的假设是预测变量和响应变量之间的关系是可加的(additive)和线性的(linear).可加性假设是指预测变量 的变化对响应变量产生的影响与其他预测变量的取值无关。线性假设是指无论
的变化对响应变量产生的影响与其他预测变量的取值无关。线性假设是指无论 取值如何,变化一个单位引起的响应变量Y的变化是恒定的。这两个假设在实践中通常是被违背的,所以在实际应用中需要一些模型来放宽这两个假设。
取值如何,变化一个单位引起的响应变量Y的变化是恒定的。这两个假设在实践中通常是被违背的,所以在实际应用中需要一些模型来放宽这两个假设。
去除可加性假设
线性模型假设一种观测变量的变化引起的响应变量的变化与其他观测变量无关。然而在实际的情况中,预测变量之间可能互相影响改变响应变量。这种效应在统计学中被称为交互作用(interaction)。我们可以将一个含有两个变量的标准线性回归模型 扩展,引入第三个预测变量,名为交互项(interaction term),交互项由
扩展,引入第三个预测变量,名为交互项(interaction term),交互项由 的乘积构成,由此可以得到模型:
的乘积构成,由此可以得到模型:
此时, 的效应不再是常数:调整
的效应不再是常数:调整 的值将改变
的值将改变 对Y的影响。
对Y的影响。
非线性关系
某些情况下,响应变量与预测变量的真实关系可能是非线性的,可以用非常简单的方法来扩展模型,比如说多项式回归(polynomial regression)。指的是预测变量可以不止有一次项,可以有二次项,三次项等等。
3.3.3 潜在的问题
当我们利用线性回归模型对某个数据集进行拟合时,可能会遇见许多问题。其中最常见的有以下几种:
(1)非线性的响应-预测关系(nonlinearity of response-predictor relationship)
线性回归模型假定预测变量和响应变量之间有直线关系。如果真实关系是非线性的,那么我们得出的几乎所有的结论都是不可信的,而且模型的预测精度也可能显著降低。
残差图(residual plot)是一种非常有用的工具,可以用于识别非线性。给定一个简单的线性回归模型,我们就可以绘制残差 和预测变量
和预测变量 的散点图。在多元回归中,由于有多个预测变量,转而绘制残差与预测值的散点图。理想情况下,残差图显示不出明显的规律。若存在明显的规律,则表示线性模型在某些方面可能存在问题。
的散点图。在多元回归中,由于有多个预测变量,转而绘制残差与预测值的散点图。理想情况下,残差图显示不出明显的规律。若存在明显的规律,则表示线性模型在某些方面可能存在问题。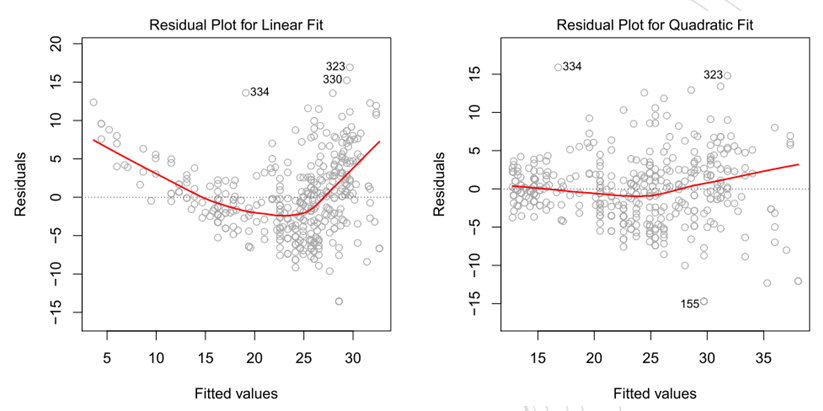
图3-2 某个数据集预测值的残差图。左图, 的线性回归。右图,
的线性回归。右图, 的线性回归(多项式回归)
的线性回归(多项式回归)
若模型与真实情况足够接近,则影响预测精度的主要因素在于不可约误差,虽然每次观测时不可约误差不可能完全相等,但是它们总是维持在一个相对稳定的状态,所以如果模型的拟合度足够好,则残差应该是相对平滑的曲线。在3-2图中,左图残差有较强的模式,这表示数据是非线性的。右图残差图比较平滑,表明模型对数据拟合地比较好.
如果残差图表明数据存在非线性关系,那么一种简单的方法是在模型中使用预测变量的非线性变换,例如 。后面会讨论其他方法解决这个问题。
。后面会讨论其他方法解决这个问题。
(2)误差项相关(correlation of error term)
线性回归模型中一个重要的假设是误差项 不相关。举个栗子,如果误差项不相关,那么
不相关。举个栗子,如果误差项不相关,那么 为正这一事实完全不能(或几乎不能)为判断
为正这一事实完全不能(或几乎不能)为判断 的符号提供任何信息。回归系数和拟合值的标准误的计算都基于误差项不相关的假设。如果误差项之间有相关性,那么估计标准误往往低估了真实标准误。因此,置信区间和预测区间比真实区间窄。例如 , 95% 置信区间包含真实参数的实际概率将远低于 0.95。 此外,与模型相关的 p 值也会更低,这可能导致我们得出错误的结论,认为参数是统计显著的。总之,如果误差项相关,那么模型的置信度可能是无法保证的。
的符号提供任何信息。回归系数和拟合值的标准误的计算都基于误差项不相关的假设。如果误差项之间有相关性,那么估计标准误往往低估了真实标准误。因此,置信区间和预测区间比真实区间窄。例如 , 95% 置信区间包含真实参数的实际概率将远低于 0.95。 此外,与模型相关的 p 值也会更低,这可能导致我们得出错误的结论,认为参数是统计显著的。总之,如果误差项相关,那么模型的置信度可能是无法保证的。
举一个极端的例子,假设我们不小心把数据重复了一遍,导致相同的观测和误差项成对出现。如果忽略这一点,那么我们似乎是在计算一个规模为2n的样本的标准误,但事实上,样本量仅为 n 。我们对 2n 个样本的参数估计和对 n 个样本的估计是相同的 但后者置信区间的宽度是前者的 倍!
倍!
(3)误差项方差非恒定(non-constant variance of error term)
线性回归的另一个重要假设是误差项的方差是恒定的, 。线性模型中的假设检验和标准误差置信区间的计算都依赖于这一假设。
。线性模型中的假设检验和标准误差置信区间的计算都依赖于这一假设。
通常情况下,误差项的方差不是恒定的。例如,误差项的方差可能会随响应值的增加而增加。如果残差图呈漏斗形 (funnel shape) ,说明误差项方差非恒定或存在异方差性( heteroscedasticity )。如图 3-3 的左图所示,残差随拟合值增加而增加。在面对这样的问题时,一个可能的解决方案是用凹函数对响应值 y 做变换,比如  。这种变换使得较大的响应值有更大的收缩,降低了异方差性。图 3-3 的右图中展示了对 Y 进行对数变换后的残差图。
。这种变换使得较大的响应值有更大的收缩,降低了异方差性。图 3-3 的右图中展示了对 Y 进行对数变换后的残差图。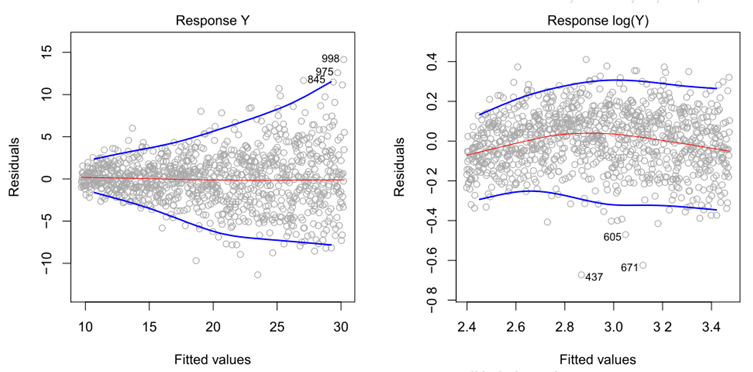
图3-3 残差图。在每张图中,红线是对残差的光滑拟合,目的是使其中的趋势更易于识别。蓝线描绘了残差的外分位数并强调了残差的模式。左:漏斗状残差表示存在异方差。右:经过对数变换的预测变量,异方差证据不明显。
(4)离群点(outlier)
离群点( outlier) 是指远离模型预测值的点。产生离群点的可能原因有很多,如数据收集过程中对某个观测点的错误记录。离群点不会影响最小二乘法拟合,但它的变化会影响 的数值,这会影响对拟合的解释。
的数值,这会影响对拟合的解释。
残差图可以用来识别离群点。如图 3-4 中间的残差图所示,离群点是清晰可见的。但在实践中,确定残差多大的点可以被认为是一个离群点会十分困难。为了解决这个问题,我们可以绘制学生化残差(studentized residual)而不是残差。学生化残差由残差 除以它的估计标准误得到。学生化残差绝对值大于 3 的观测点可能是离群点。图 3-3 的右图中,离群点的学生化残差大于 6 ,而其他所有观测的学生化残差均在-2 和 2 之间。
除以它的估计标准误得到。学生化残差绝对值大于 3 的观测点可能是离群点。图 3-3 的右图中,离群点的学生化残差大于 6 ,而其他所有观测的学生化残差均在-2 和 2 之间。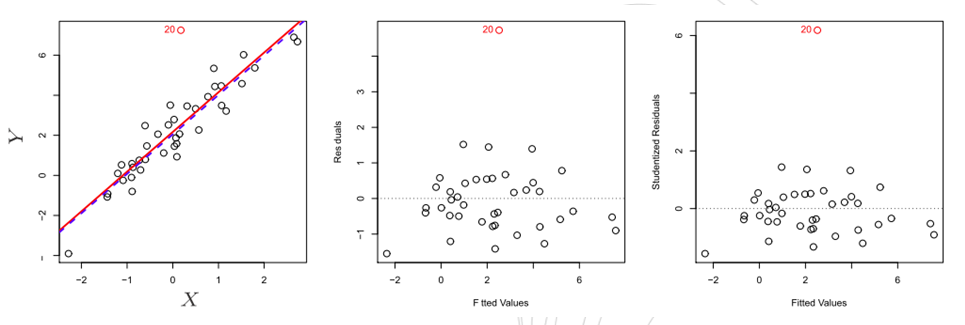
左:最小二乘回归线为红线,而删除离群点后的回归线用蓝色表示。中:残差图清楚地识别出了离群点。右:离群点的学生化残差为 6 ,通常的学生化残差在-3至3 之间。
如果能确信某个离群点是由数据采集或记录中的错误导致的,那么一个解决方案是直接删除此观测点。但是我们应该小心,因为一个离群点可能不是由失误导致的,而是暗示模型存在缺陷,比如缺少预测变量。
(6)共线性(collinearity)**
共线性( collinearity) 是指两个或更多的预测变量高度相关。在回归中,共线性的存在可能会引发问题,因为可能难以分离出单个变量对响应值的影响。
共线性会降低回归系数估计的准确性,它会导致 的标准误变大。回想一下,每个预测值的 t 统计量是由除以其标准误得到的。所以共线性导致 t 统计量的下降。因此,如果存在共线性,我们可能无法拒绝:
的标准误变大。回想一下,每个预测值的 t 统计量是由除以其标准误得到的。所以共线性导致 t 统计量的下降。因此,如果存在共线性,我们可能无法拒绝: 。这意味着,假设检验的效力 一一正确地检测出非零系数的概率被共线性减小了。
。这意味着,假设检验的效力 一一正确地检测出非零系数的概率被共线性减小了。

若有收获,就点个赞吧
0 人点赞
