5 重抽样方法
现代统计学中,重抽样方法(resampling method)是一种不可或缺的工具。这种方法通过反复从训练集中抽取样本,然后对每一个样本重新拟合一个感兴趣的模型,来获取关于拟合模型的附加信息。
两种最常用的重抽样方法,即交叉验证法(cross-validation)和自助法(bootstrap)。这两种方法在许多统计学习过程的实际应用中都是十分重要的工具。比如说,交叉验证法可以用来估计一种指定的统计学习方法的测试误差,从而评价这种方法的表现,或者为这种方法选择合适的光滑度。评价一个模型的表现的过程被称为模型评价(model assessment),而为一个模型选择合适的光滑度的过程则被称为模型选择(model selection)。自助法的应用范围很广,最常用于为一个参数估计或者一个指定的统计学习方法提供关于准确度的测量。
5.1 交叉验证法(选参数 选模型,不是用来建模的,而是用来验证模型是不是最好的)
在第二章中,主要讨论了测试错误率(test error rate)和训练错误率(training errorrate)的区别。测试误差是用一种统计学方法预测一个新的观测上(在训练模型时没有用到的一个测量)的响应值所产生的平均误差。对于一个数据集而言,如果一种统计学方法产生了一个较小的测试误差,那么这种统计学习方法是值得肯定的。如果能事先指定一个测试训练集,那么是很容易计算出测试误差的。一般无法事先指定一个测试数据集,只能讲统计学习方法用在训练观测上计算训练误差,但是训练错误率通常跟测试错误率有很大差别。
尽管缺少可直接用于估计测试错误率的一个非常大的指定测试数据集,但是有很多方法可以通过对可获得的训练数据集估计测试错误率。这些方法将在后面讨论,而在本节中,只考虑这样一类方法:在拟合过程中,保留训练观测的一个子集,然后对保留的观测运用统计学方法,从而来估计测试错误其测试错误率。
5.1.1 验证集方法
假设想要估计在一个观测数据集上,拟合一种指定的统计学习方法所产生的测试误差。图5-1所展示的验证集方法(validation set approach)就是一个非常简单的方法。这种方法首先随机地(把样本打乱)把可获得的观测集分为两部分:一个训练集(training set)和一个验证集(validation set)。模型在训练集上拟合,然后用拟合的模型来预测验证集中观测到的响应变量。最后得到验证集错误率——通常均方误差作为定量响应变量的误差度量——提供了对于测试错误率的一个估计。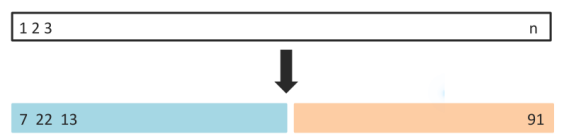
5-1 验证集方法原理图。一个有n个观测的集合被随机地分为一个训练集(左下角部分,包括7,22,13以及其他观测)和一个验证集(右下角部分,包括91及其他观测)验证集方法是在训练集上拟合统计学习方法,然后在验证集上评价其表现的方法
如Auto(汽车)数据集中(图5-2),汽车的mpg(油耗)和horsepower(马力)。mpg和horsepower相关,但它们并非线性关系(橙色线)。数据呈现一种曲线关系,使用预测变量转换模式是一种将非线性因素纳入线性模型的简单方法。图5-2似乎有些二次方的形状特征,这表明模型:mpg= 可能会提供更好的拟合。将
可能会提供更好的拟合。将 看做
看做 ,将
,将 看做
看做 ,这个模型仍然可以看做线性回归模型。
,这个模型仍然可以看做线性回归模型。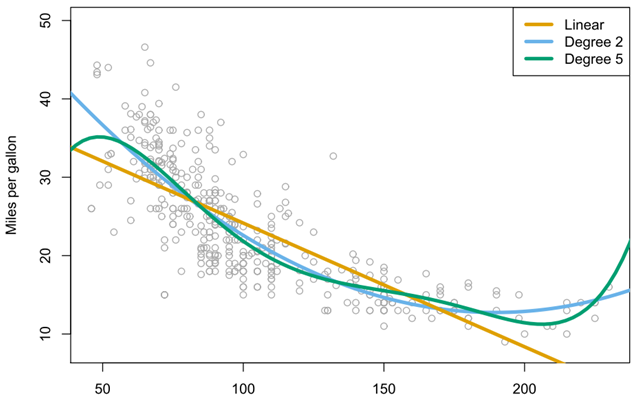
图5-2 Auto 数据集。一些汽车的油耗 (mpg) 和马力 (horsepower) 。线性回归拟合线是橙色线。包含马力 变量的线性回归拟合线是蓝色线。包含马力horsepower的所有五次以内项的线性回归拟合线是绿色线。
在这个例子中用 预测mpg的模型比只用线性模型拟合要好。那么会产生这样一个问题,用三次及其更高次多项式来拟合模型效果是不是更好呢?我们可以考察p值或者用验证法来解决这个问题。首先随机地将392个观测分为两个集合,一个是包含196个数据点的训练集,一个是包含196个数据点的验证集。图5-3的左边部分为验证集错误率,其中用均方误差作为衡量验证集误差的度量指标,表明用二次项拟和所得到的验证集均方误差要比用线性项拟合小得多。不过,用三次项拟和所得到的验证集均方误差却比二次项拟和的稍大一点。这表示用三次项拟合回归模型并不比只用二次项拟合模型的预测效果要更好。
预测mpg的模型比只用线性模型拟合要好。那么会产生这样一个问题,用三次及其更高次多项式来拟合模型效果是不是更好呢?我们可以考察p值或者用验证法来解决这个问题。首先随机地将392个观测分为两个集合,一个是包含196个数据点的训练集,一个是包含196个数据点的验证集。图5-3的左边部分为验证集错误率,其中用均方误差作为衡量验证集误差的度量指标,表明用二次项拟和所得到的验证集均方误差要比用线性项拟合小得多。不过,用三次项拟和所得到的验证集均方误差却比二次项拟和的稍大一点。这表示用三次项拟合回归模型并不比只用二次项拟合模型的预测效果要更好。
右图展示了对Auto数据集用10种不同的随机分隔,把观测分为训练集和验证集,所得到10条不同的验证集的均方误差曲线。10条曲线都说明了用二次项拟合模型所得到的验证集均方误差要比只用线性项拟合模型要小的多。但值得一提的是,每一条曲线都对应了每一个回归模型不同的测试均方误差估计。这些曲线并不能说明哪个模型有最小的验证集均方误差。基于这些曲线的波动性,只能确定对这个数据做线性拟告是不恰当的。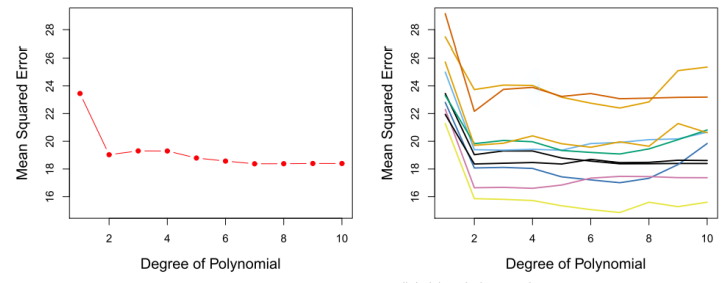
图5-3 在 Auto数据集上,用验证集方法来估计用 horsepower 的多项式函数来预测 mpg所产生的测试误差。左: 用一种分割把数据分为训练数据集和验证数据集,所产生的验证误差估计。右图:重复运用验证集方法十次,每次用一种不同的随机分割把现测分为一个训练集和验证集。这表现了用验证集方法所产生的测试均方误差估计的波动性
验证集方法的原理很简单,但是有两个潜在的缺陷:
1 测试错误率的验证法估计波动很大,这取决于具体哪些观测被包括在训练集中,哪些观测被包括在验证集中。(依赖分割的数据集特征,不知道应该选择哪种分组)
2 在验证法中,只有一部分观测——那些被包含在训练集而非验证集中的观测——被用于拟合模型。由于被训练的观测越少,统计方法的表现越不好,这意味着,验证集的错误率可能会高估在整个数据集上拟合模型所得到的测试错误率。
5.1.2 留—交叉验证法
留—交叉验证法(leave-one-out cross-validation,LOOCV)这种方法与验证集的方法十分相似,但这种方法尝试去解决验证集方法遗留的缺陷问题。
留—交叉验证法将一个单独的观测 作为验证集,剩下的观测【
作为验证集,剩下的观测【 】组成训练集。然后在n-1个训练观测上拟合统计学习方法,再对余下的观测根据它的值
】组成训练集。然后在n-1个训练观测上拟合统计学习方法,再对余下的观测根据它的值 来做预测
来做预测 。得出
。得出
重复这个步骤,把 选为验证数据,在剩下的n-1个观测上训练统计学习方法,得到
选为验证数据,在剩下的n-1个观测上训练统计学习方法,得到 .重复n次得到n个均方误差,
.重复n次得到n个均方误差, 。对测试均方误差的LOOCV估计是这n个测试误差估计的均值:
。对测试均方误差的LOOCV估计是这n个测试误差估计的均值: (5.1)
(5.1)
相较于验证集方法,LOOCV方法有以下几个主要的有点。
(1)它的偏差比较小。在LOOCV方法中,反复地用包含n-1个观测的训练集来拟合统计学习方法,观测数几乎与整个数据集中的数据量相等。这与训练集通常占原始数据集一半左右的验证集方法不同,因此,LOOCV方法比验证集方法更不容易高估测试错误率。
(2)由于训练集和验证集分割的随机性,在反复运用时会产生不同的结果,而多次运用LOOCV方法会得到相同的结果(如图5-4),LOOCV方法在训练集和验证集的分割上不存在随机性。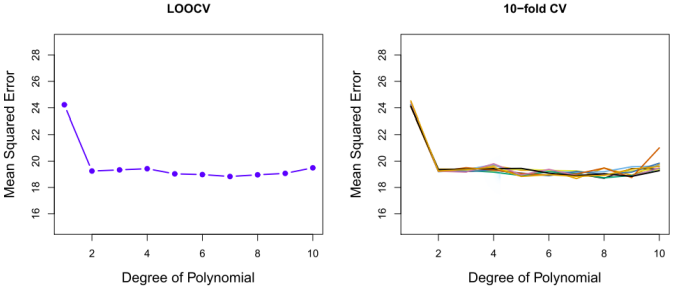
图5-4 在 Auto数据集上,用交叉验证法来估计用 horsepower 的多项式函数来预测 mpg所产生的测试误差。左:LOOCV误差曲线。右:运用10折CV方法重复9次所得到的曲线。
但是这个方法的缺点在于计算量可能会很大,因为模型需要被拟合n次。如果n很大,这种方法会非常耗时。
5.1.3 K折交叉验证法
k折交叉验证法(k-fold CV)是LOOCV方法的一个替代。这种方法将观测集随机地分为k个大小基本一致的组,或者说折(fold)。第一折作为验证集,然后在剩下的k-1折上拟合模型。均方误差 由保留折的观测计算得出。重复这个步骤k次,每一次把不同的观测组作为验证集。整个过程】会得到k个测试误差的估计,
由保留折的观测计算得出。重复这个步骤k次,每一次把不同的观测组作为验证集。整个过程】会得到k个测试误差的估计, k折CV估计由这些值求平均得到,
k折CV估计由这些值求平均得到, (5.2)
(5.2)
与交叉验证法相比,这种方式减少了计算量。交叉验证法需要对一种统计学习方法拟合n次,使用k折CV方法时,一般令k=5或k=10. CV估计存在一定的波动性,这是由于将观测分为10折的分割不同所造成的,这种波动比验证集方法得到的波动要小得多。
考察模拟数据集时,测试均方误差的真值是可以得到的,因此就可以衡量交叉验证法的精度。如图5-5所示,某个模拟数据集用光滑样条法所得到的测试错误率的交叉验证估计及真值。蓝色实线为测试均方误差真值。黑色虚线和橙色实线分别表示LOOCV估计和10折CV估计。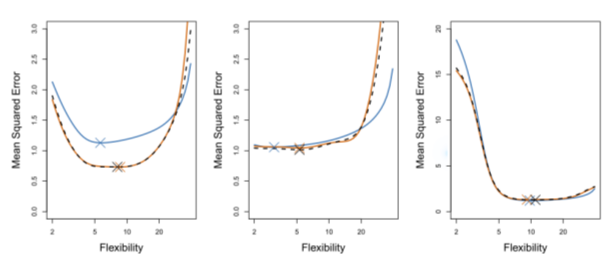
图5-5 模拟数据集测试均方误差的真值和估计值。蓝色实线为测试均方误差的真值,黑色虚线为LOOCV估计值,橙色实线为10折CV估计值。用“X”标注的点表示每条均方误差曲线最小值点。
现在来比较这三个图,左图,CV曲线的形状大致正确,但都低估了测试均方误差的真值。中图,模型光滑度低时,CV估计曲线和真实曲线比较接近,但是当光滑度较高时,CV曲线高估了测试集均方误差。右图,CV估计曲线与测试均方误差曲线几乎完全重合。
有时候,我们不关心测试均方误差的估计精度,仅对测试均方误差的最小值点(minimum point in the estimate test MSE curve)感兴趣。这是因为可能有几种统计学习方法,或者一种统计学习方法在不同的光滑度上使用交叉验证法,其目的是找到测试误差最小的办法。在图5-5中,即使测试均方误差的估计和真值有一定的差距,但CV曲线所确定的最小光滑度水平都十分接近正确的光滑度水平,所以我们仍可以用这个方法来寻找最佳统计方法或者预测最佳光滑度水平。
5.1.4 k折交叉验证中的偏差-方差平衡
k折交叉验证的方法,除了相对于LOOCV有计算上的优势外,还有另一个优势,就是它对LOOCV方法来说,对测试错误率的估计往往更加准确。
这涉及到方差-偏差权衡的问题。验证集的方法由于被训练的观测少,统计方法的表现会越不好,往往会高估测试集的错误率。而LOOCV的方法测试集用了n-1组数据,几乎相当于整个数据集中观测的数目,所以能提供近似无偏的测试误差估计,这种方法得到的模型偏差极小。
但是在第二章讨论过,偏差并不是唯一需要考虑的问题(偏差极小的话模型的推广性会很差),估计量的方差同样需要被考虑。所以我们使用k折交叉验证法使得产生一个中等程度的偏差,通过调整k的值,我们可以调整偏差和方差的值,从经验上来说,一般选择k=5或者k=10,从经验上来说,这些值使测试错误率不会有过大的偏差或者方差。
5.1.5 自助法 (用计算弥补随机性)
5.1.5 交叉验证法在分类问题中的应用
在分类问题上,当响应变量为定性变量时,交叉验证也是一种十分有用的方法,它与回归问题的区别在于被误分类的观测的数量,而不是均方误差作为衡量测试误差的指标。在分类问题下,LOOCV方法的错误率的形式为 (5.3)
(5.3)
其中 . k折CV错误率和验证集的错误率的定义也是类似的。
. k折CV错误率和验证集的错误率的定义也是类似的。
(关于扩展这一节看完逻辑斯底回归再来补充)
5.2 自助法
自助法(bootstrap)是一个广泛应用且十分强大的统计工具,可以用它来衡量一个指定的估计量或者统计学习方法中不确定的因素。自助法的强大体现在它可以简便地应用在很多统计学习方法之中,其中包括一些对波动性的测量要么很难获得,要么不会由统计软件自动输出。
通过一个简单的例子来说明自助法的原理,在这个例子中,目标是希望能确定一个简单模型下最优的投资分配。假设有一笔钱对两个分别收益为 的金融资产进行投资,其中
的金融资产进行投资,其中 是随机变量。打算把所有钱的百分比α的部分投资到
是随机变量。打算把所有钱的百分比α的部分投资到 ,把剩下的1-α部分投资到
,把剩下的1-α部分投资到 。由于这两笔投资都具有波动性,所以希望选择一个α,使得投资的总风险最小(方差最小)也就是希望
。由于这两笔投资都具有波动性,所以希望选择一个α,使得投资的总风险最小(方差最小)也就是希望 最小。使得风险最小的α值为
最小。使得风险最小的α值为 (5.4)
(5.4)
其中 ,以及
,以及
在现实生活中 是不知道的,所以我们可以过去的的数据集,来计算这些量的估计
是不知道的,所以我们可以过去的的数据集,来计算这些量的估计 。那么就可以估计使得投资的方差最小的α值
。那么就可以估计使得投资的方差最小的α值 (5.5)
(5.5)
图5-6展示了在一个模拟数据集上用这种方法来估计α的结果。模拟生成了100对投资的收益。用这些收益来估计,带入公式5.5得到α的估计。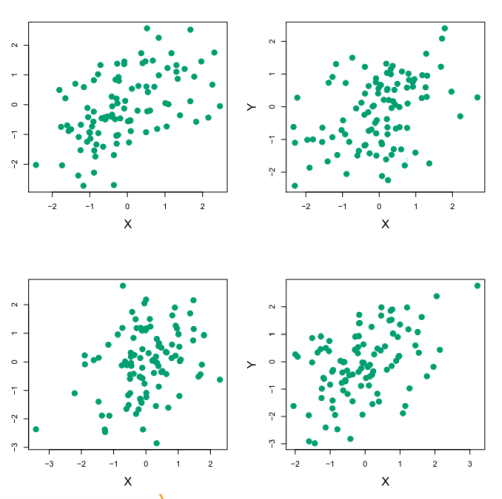
图5-6 每一部分展示了100个模拟生成的投资的收益X和Y。从左到右,从上到下,所得到的α的估计为0.576, 0.532,0.657, 0.651。
将模拟生成100对的X和Y的观测这一步骤进行了1000次,因此可以得到1000个α的估计,这1000个α估计的的均值为 (5.6)
(5.6)
这个值与 非常接近。
非常接近。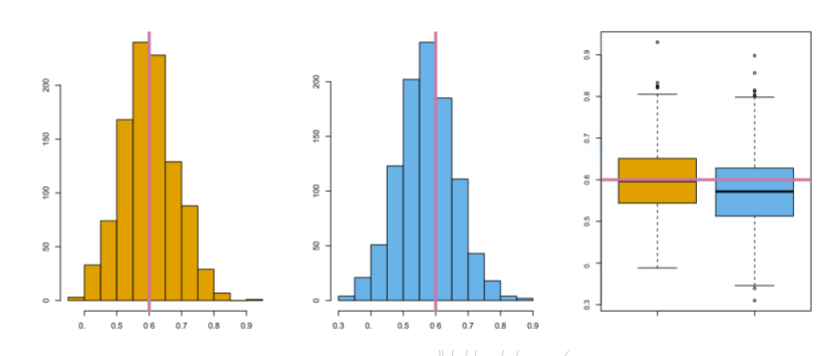
图5-7 左:由真实的总体生成的1000个模拟数据集所得到的α估计的直方图。中:由同一个数据集生成的1000个自助法样本所得到的α的直方图。右:左边和中间部分展示的α估计的箱线图。粉色的线都代表α的值。
在真实的数据中,我们无法从原始的总体中生成新的样本。不过,自助法可以通过反复地从原始的数据集(orginal data set)中抽取观测得到数据集。用这些抽取的观测数据集估计α值,图5-8阐释了自助重抽样的原理。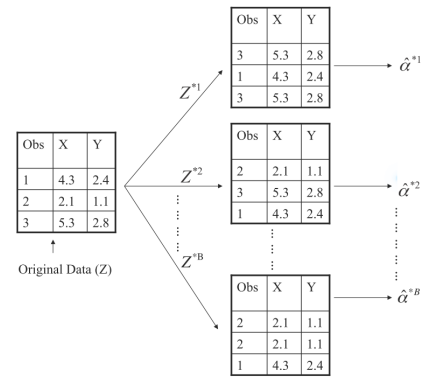
图5-8 在一个包含n=3个观测的小样本阐述自助法的原理。每一个自助法数据集包含n个观测,从原始数据集中有放回地抽样得到。用每个自助法数据集得到一个α的估计。
重抽样得到的α的平均值为估计的α值。

若有收获,就点个赞吧
0 人点赞
