chapter04 分类
这一章将学习预测定性响应变量的方法及分类(classification)的过程,大部分的分类方法先从预测定性变量的不同类别的概率开始,将分类问题作为概率估计的一个结果。从这个角度来看,分类方法和回归方法有许多类似之处。
如今许多分类技术或分类模型(classifier)已经被开发出来用于预测定性响应变量值。这章将讨论应用最为广泛的三种分类方法:逻辑斯谛回归(logistic regression),线性判别分析(linear discriminant analysis)和K最邻近(K-nearest neighbor)。数据密集型的计算方法,例如广义可加模型、树方法、随机森林、提升法以及支持向量机的方法会在后面的章节提到。
4.1 分类问题概述
现实生活中分类问题十分常见,甚至比回归问题更多。举一个例子,某人来到急诊室,医生通过该病人的一系列症状将病人归到三类可能的病症中的一类。
与回归问题一样,在分类中假定有一系列的训练观测%2C(x_2%EF%BC%8Cy_2)%2C…%2C(x_n%EF%BC%8Cy_n)#card=math&code=%28x_1%EF%BC%8Cy_1%29%2C%28x_2%EF%BC%8Cy_2%29%2C…%2C%28x_n%EF%BC%8Cy_n%29&height=24&width=230),可以根据训练数据建立一个分类模型,要求该模型不仅能较好地拟合训练数据,而且在测试集上也能有较好地效果。
这一章会通过一个模拟的Default(违约)数据集来阐述分类模型的概念。在该问题中,感兴趣的是基于一个人的年收入(income)和月信用卡余额(balance)预测其违约的状态,数据集如图4-1示,图4-1 是对 10000 个样本子集绘出的 income和 balance的关系图。在图中橙色表示某个月份出现违约的个体用户,蓝色表示来构成违约的个体用户。(总体违约率大约为3%)。右图显示了两对箱线图。第一对根据default变量的两个状态显示了balance的分布,第二对是类似的做法。在这里,我们使用balance和income作为预测变量 来预测违约状态
来预测违约状态 。
。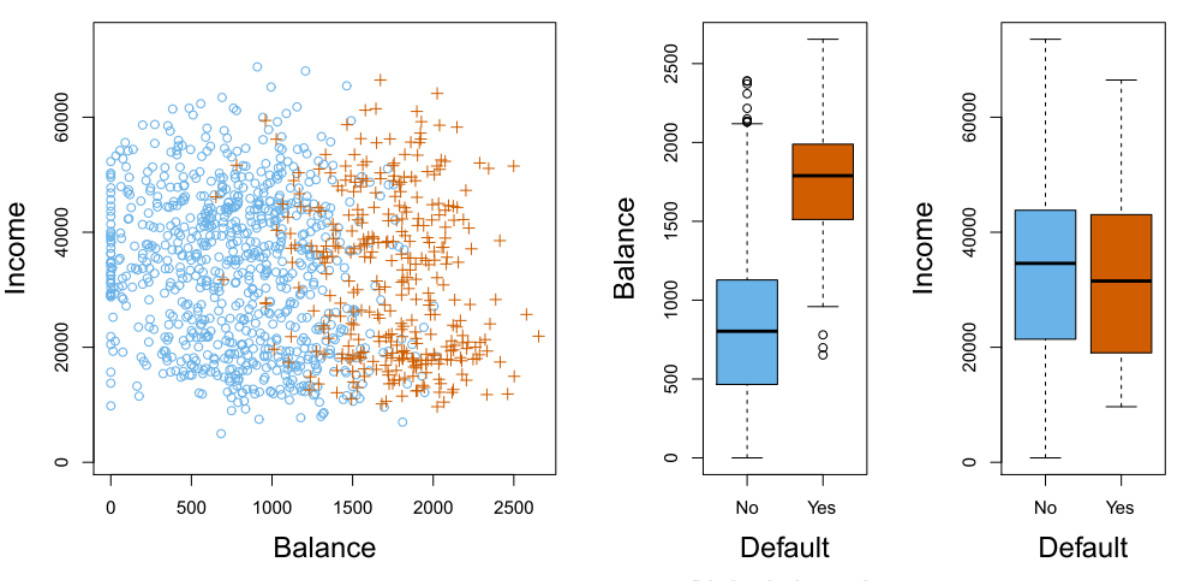
图 4-1 Default数据集,蓝色是不违约,棕色是违约。
4.2 为什么线性回归不可用
线性回归在定性响应变量的情况下是不适用的,为什么会这样呢?
假设现在要通过一个急救室病人的症状来预测它的患病情况。有三种可能的诊断:中风、服药过量和癫痫发作,考虑一个定量的响应变量 对这些值编码,如下:
对这些值编码,如下: (4.1)
(4.1)
根据这些编码,结合一系列预测变量通过最小二乘法建立线性回归模型来预测。但这样做有一个问题,就是默认了一个有序输出,服药过量在中风和癫痫发作的中间,这就表明中风-服药过量和服药过量-癫痫发作的差距是一样的,而这种情况在现实生活中并不合理。
值得提一句的是,对于一个二元定性响应变量而言,最小二乘回归是有意义的,这时候的估计值可以视为一个预测概率的大小,有部分的解释作用。
4.3 逻辑斯谛回归
考虑Default数据集,响应变量default只取两个值yes(违约)和no(不违约)。逻辑斯谛回归对Y属于某一类的概率建模而不直接对响应变量Y建模。
对Default数据而言,逻辑斯谛回归建立违约概率模型。例如,给定balance时,可以记为: 的值,简记为
的值,简记为 ,取值范围在0到1之间。那么任意给定一个balance值,就可以根据这个概率对default预测。例如,如果某人的
,取值范围在0到1之间。那么任意给定一个balance值,就可以根据这个概率对default预测。例如,如果某人的 ,可以预测这个人的
,可以预测这个人的
4.3.1 逻辑斯谛模型
那么该怎样建立 与X之间的关系呢?(为了方便起见,本节的响应变量按照常规的0/1编码取值)
与X之间的关系呢?(为了方便起见,本节的响应变量按照常规的0/1编码取值)
思考一下,如果我们对Y属于某一类的概率建模而不直接对响应变量建模是不是将定性问题转变成为定量问题了呢?这时候是不是就能用线性回归公式: 建模了呢?
建模了呢?
答案是不可以的,如4-2左图是利用线性回归估计的default的概率,如图上所示:当信用卡余额(balance)接近于0,会产生一个负值的违约概率,当余额非常大时,会得到一个大于1的违约概率值
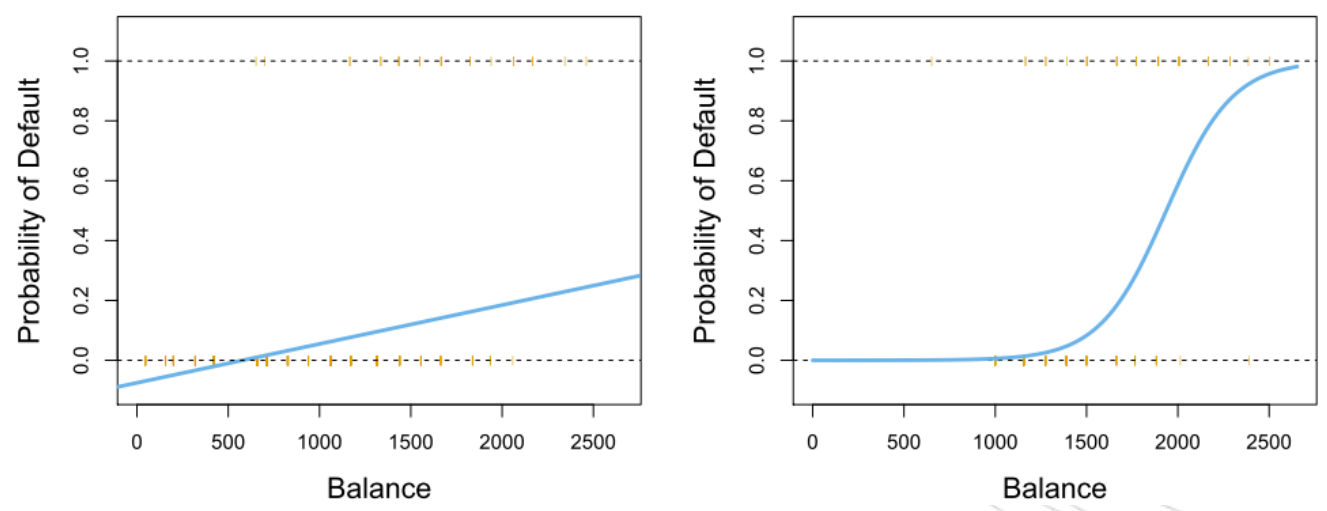
图4-2 Default数据分类。左:线性回归default概率。其中一些数据上估计的概率是负的。右:逻辑斯谛回归预测的default概率,所有估计的概率均落在0和1之间。 橙色记号表示的是0/1编码的default值。
为了避免这类问题,必须找一个函数建立针对 的模型,使任意
的模型,使任意 值该输出的函数结果都在0和1之间。逻辑斯谛函数满足这项要求:
值该输出的函数结果都在0和1之间。逻辑斯谛函数满足这项要求: (4.2)
(4.2)
图4-2右图可以看出default数据集应用逻辑斯谛回归模型拟合的情况。注意到信用卡余额越低,预测违约概率就越接近为0,但是违约概率不会小于0,同样,信用卡余额越高,预测的违约概率将越接近1,但不会高于1.它对default数据集的捕获能力也优于线性回归。
通过整理(4.2),可得 (4.3)
(4.3)
 的值为发生比(odd),取值范围是0到
的值为发生比(odd),取值范围是0到 ,它的值接近于于0表示违约发生概率很低,它的值接近于时表示违约概率非常高。
,它的值接近于于0表示违约发生概率很低,它的值接近于时表示违约概率非常高。
对(4.3)两边同时取对数,得到 (4.4)
(4.4)
等式左边称为对数发生比(log-odd)或者对分数(logit),逻辑斯谛回归模型(4.2)可以视为分对数变换下的一个关于X的线性模型
4.3.2 估计回归系数
在这里用极大似然法(maximum likelihood)方法估计逻辑斯谛模型的系数。
极大似然法拟合逻辑斯谛回归模型的基本思想是:寻找 的一个估计,使得由(4.2)得到的预测违约概率
的一个估计,使得由(4.2)得到的预测违约概率 最大可能地与违约的观测情况接近。拿上面的例子来说,就是使所有违约的人的值接近于1,而未违约的值接近于0。这个思想可以用数学方程的似然函数(likeihood function)表示,如下:
最大可能地与违约的观测情况接近。拿上面的例子来说,就是使所有违约的人的值接近于1,而未违约的值接近于0。这个思想可以用数学方程的似然函数(likeihood function)表示,如下:
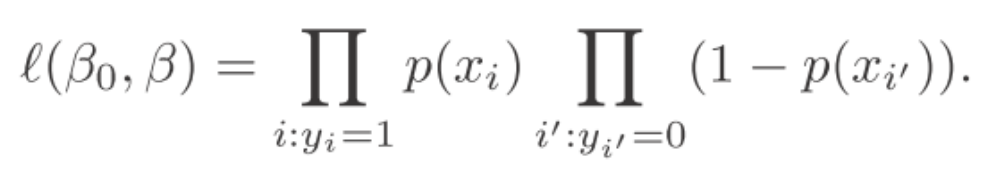 (4.5)
(4.5)
所估计的系数 应使似然函数值最大,这里不讨论具体的拟合细节。
应使似然函数值最大,这里不讨论具体的拟合细节。
表4-1 Default数据中,建立用balance预测default概率的逻辑斯谛回归模型的系数估计。

4.3.3 预测
当知道参数后,进行预测就比较容易了,当X是定量变量时,将X带入即可求概率。如当某人的balance为1000美元时,预测它的违约概率为: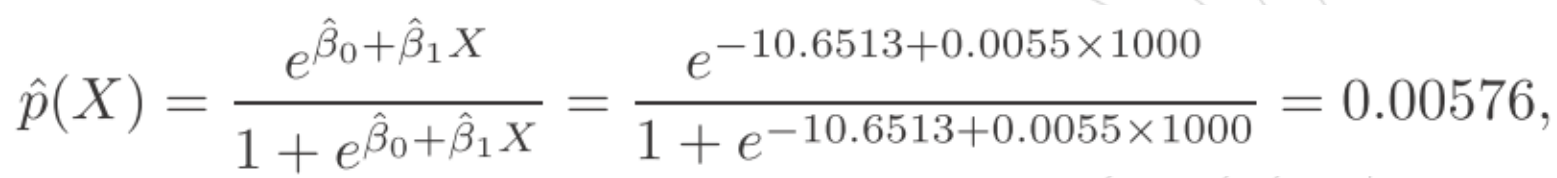
违约概率小于1%。
逻辑斯谛回归也可以依据哑变量的方法分析定性的预测变量。举一个例子,Default数据集包含了student(学生身份)这一定性变量。为拟合模型设立一个哑变量:设学生的身份为1,非学生的身份为0. 利用学生身份估计的逻辑斯谛回归模型结果如下
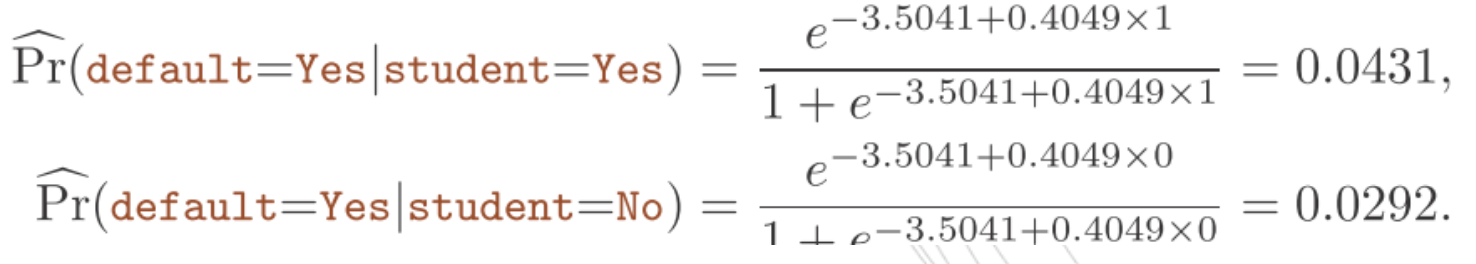
可以看出,学生身份比非学生身份更容易违约。
4.3.4 多元逻辑斯谛回归
现在考虑一个二元响应变量受多个因素(多个预测变量)影响的情况。可以做如下推广: (4.6)
(4.6)
这里的 是p个预测变量,方程(4.6)可以重新写成:
是p个预测变量,方程(4.6)可以重新写成: (4.7)
(4.7)
也利用极大似然法估计
4.3.5 响应变量数超过2的逻辑斯谛回归
对于响应变量超过2的分类问题,两类逻辑斯谛回归模型可以推广到多类,但是在实际中并不多用,因为线性判别分析是专门用来解决多类响应变量的问题的。
4.4 线性判别分析
在二元响应变量的情况下,逻辑斯谛函数直接建立了 的模型。用统计的语言说,就是在给定预测变量的条件下,建立响应变量Y的条件分布模型。现在考虑另一种间接估计这些概率的方法。在这类方法中,分别对每种响应分类(给定的Y)建立预测变量X的分布模型(后面要估计X的密度函数
的模型。用统计的语言说,就是在给定预测变量的条件下,建立响应变量Y的条件分布模型。现在考虑另一种间接估计这些概率的方法。在这类方法中,分别对每种响应分类(给定的Y)建立预测变量X的分布模型(后面要估计X的密度函数 ),然后利用贝叶斯定理反过来去估计。若分布是正态分布时,则模型在形式上与逻辑斯谛回归很相似。
),然后利用贝叶斯定理反过来去估计。若分布是正态分布时,则模型在形式上与逻辑斯谛回归很相似。
为什有了逻辑斯谛回归回归,我们还要用别的方法做分类呢?
(1)当类别区分度比较高时,逻辑斯谛回归估计的参数不够稳定,而这一点在线性判别分析中时不存在的。
(2)如果样本量n比较小,而且每一类响应变量中预测变量X近似服从正态分布,线性判别分析模型比逻辑斯谛回归模型更加稳定。
(3)响应变量多于两类时,线性判别分析应用更为普遍。
4.4.1 运用贝叶斯定理进行分类
我们将观测分为K类,K≥2,换句话说,定性的响应变量Y 可以去K个不同的无序值(如K=0,K=2,K=4等等)。设 为一个随机选择的观测来自第K类的先验概率,也就是说,给定观测属于响应变量Y的第K类概率。设
为一个随机选择的观测来自第K类的先验概率,也就是说,给定观测属于响应变量Y的第K类概率。设 表示第k类观测的X密度函数(density function)。如果第k类的观测在
表示第k类观测的X密度函数(density function)。如果第k类的观测在 附近有很大的可能性,那么的值很大,反之的值很小。贝叶斯定理可以表述为:
附近有很大的可能性,那么的值很大,反之的值很小。贝叶斯定理可以表述为: (4.8 )
(4.8 ) 的估计是容易求得的,选取一些变量Y的随机样本,分别计算属于第k类样本占总样本的比例即可。对于的估计要更复杂一些,除非它们的密度函数形式简单。我们记
的估计是容易求得的,选取一些变量Y的随机样本,分别计算属于第k类样本占总样本的比例即可。对于的估计要更复杂一些,除非它们的密度函数形式简单。我们记 ,
, 为
为 的观测属于第k类的后验概率,即给定观测的预测变量值时,观测属于第k类的概率。
的观测属于第k类的后验概率,即给定观测的预测变量值时,观测属于第k类的概率。
(先验概率和后验概率的区别在于有没有给定的条件,先验概率一般是比较好估计的)
在前面ch2中说过,贝叶斯分类器将一个观测分到 最大的一类中,它在所有分类器中错误率最小,因此,如果找到一个估计
最大的一类中,它在所有分类器中错误率最小,因此,如果找到一个估计 的方法,可以依此发展出一个与贝叶斯分类器类似的分类方法。下面主要介绍这一类的方法。
的方法,可以依此发展出一个与贝叶斯分类器类似的分类方法。下面主要介绍这一类的方法。
4.4.2 p=1的线性判别分析
假设p=1,即只有一个预测变量。要估计出,首先得做出一些假设。假设是正态的或者高斯的。在一维的情况下,正态密度函数为: (4.9)
(4.9)
其中 是第k类的平均值和方差,假设
是第k类的平均值和方差,假设
4.4.3 p>1的线性判别分析
4.4.4 二次判别分析
4.5 分类方法比较

若有收获,就点个赞吧
0 人点赞
