文档说明
此文档为拉钩Java高薪训练营2期课程学习过程,完成作业的文档。顺便说一句拉钩的课程,整个课程,体系非常全,价格上也是所有培训课程中最便宜的。如果希望构建一个整体的技术视野,非常推荐。
Hadoop 架构图

图片来源于网络,侵删。
Hadoop 安装
前置环境
- 设置静态 IP
- 修改主机名
- 关闭防火墙
- 安装 JDK
- ssh 免密登录
- hosts 配置
- 集群时间同步
- 创建用户(用户具有 root 权限)
安装
- 各版本 hadoop 下载:https://archive.apache.org/dist/hadoop/common/
- 在 opt 目录创建 module 文件夹,将 hadoop-2.7.2.tar.gz 上传,解压。
将 hadoop 添加到环境变量
# HADOOP_HOMEexport HADOOP_HOME=/opt/module/hadoop-2.7.2export PATH=$PATH:$HADOOP_HOME/binexport PATH=$PATH:$HADOOP_HOME/sbin
检验是否安装成功
hadoop version
本地运行模式
本地运行模式,不需要做任何配置即可运行。
伪分布式
修改配置
hadoop-env.sh,修改 JAVA_HOME 路径
export JAVA_HOME=/opt/module/jdk1.8.0_144
core-site.xml ```xml
fs.defaultFS hdfs://hadoop103:9000
3. hdfs-site.xmlxml
<a name="a9957162"></a>
### 启动集群
1. 第一次启动需要格式化 NameNode:`hdfs namenode -format`
1. 启动 Namenode:`hadoop-daemon.sh start namenode`
1. 启动 Datanoe:`hadoop-daemon.sh start datanode`
<a name="3d61c89f"></a>
### 查看集群
1. jps 查看是否有 NameNode 和 DataNode 进程
1. 通过 50070 端口查看 HDFS 文件系统 WEB 界面
1. 查看日志
<a name="bc8914ac"></a>
### 启动 Yarn 运行 MapReduce 程序
<a name="224e2ccd"></a>
#### 配置
1. 修改 yarn-env.sh,配置 JAVA_HOMEshell
export JAVA_HOME=/opt/module/jdk1.8.0_144
2. 配置 yarn-site.xmlxml
3. mapred-env.shshell
export JAVA_HOME=/usr/java/jdk1.8.0_241
4. 配置: (对mapred-site.xml.template重新命名为) mapred-site.xmlxml
<a name="8e54ddfe"></a>
#### 启动
1. 确保 NameNode 和 DataNode 已经启动
1. 启动 ResourceManager `yarn-daemon.sh start resourcemanager`
1. 启动 NodeManager `yarn-daemon.sh start nodemanager`
1. 查看 Yarn WEB 界面 8088
<a name="bbb0a0f6"></a>
### 配置历史服务器
1. 配置mapred-site.xmlxml
2. 启动历史服务器 `mr-jobhistory-daemon.sh start historyserver`
2. 查看 JobHistory WEB 界面:19888 端口
<a name="cf1eeeaf"></a>
### 配置日志聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
1. 配置yarn-site.xmlxml
2. 关闭 ResourceManager、NodeManager和HistoryServershell
sbin/yarn-daemon.sh stop resourcemanager
sbin/yarn-daemon.sh stop nodemanager
sbin/mr-jobhistory-daemon.sh stop historyserver
3. 启动ResourceManager、NodeManager和HistoryServershell
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
sbin/mr-jobhistory-daemon.sh start historyserver
4. 运行 MR 程序,在 JobHistory 界面中查看日志 [http://hadoop103:19888/jobhistory](http://hadoop103:19888/jobhistory)
<a name="31e06a9e"></a>
## 完全分布式环境搭建
首先确保各个服务器上单节点运行正常。hadoop-env.sh yarn-env.sh mapred-env.sh 中 JAVA_HOME 配置正确。
<a name="47b520ed"></a>
### 集群规划
| | hadoop103 | hadoop104 | hadoop105 |
| --- | --- | --- | --- |
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
<a name="b6d3481f"></a>
### 配置集群
1. core-site.xmlxml
2. hdfs-site.xmlxml
3. yarn-site.xmlxml
4. mapred-site.xmlxml
5. slaves 配置tex
# slaves 文件不能有空行,结尾不能有空格
hadoop103
hadoop104
hadoop105
<a name="8e54ddfe-1"></a>
### 启动
1. 在 NameNode 节点格式化 NameNode `hdfs namenode -format`
1. 启动 HDFS `start-dfs.sh`(任意节点皆可)
1. 启动 Yarn `start-yarn.sh` (如果 NameNode 和 ResourceManger 如果不是同一台机器,不能在 NameNode 上启动 YARN,应该在ResouceManager 所在的机器上启动YARN。)
<a name="a0339520"></a>
## HDFS-HA 配置
<a name="47b520ed-1"></a>
### 集群规划
| hadoop103 | hadoop1034 | hadoop105 |
| --- | --- | --- |
| NameNode | NameNode | |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| ZK | ZK | ZK |
| | ResourceManager | |
| NodeManager | NodeManager | NodeManager |
<a name="c799c49f"></a>
### 安装 zookeeper
<a name="e655a410-1"></a>
#### 安装
1. 将 zk 安装包解压到 /opt/moudle/ 目录shell
tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/
2. 在/opt/module/zookeeper-3.4.10/这个目录下创建zkData
2. 重命名/opt/module/zookeeper-3.4.10/conf这个目录下的zoo_sample.cfg为zoo.cfg
<a name="224e2ccd-1"></a>
#### 配置
修改 zoo.cfg
dataDir=/opt/module/zookeeper-3.4.10/zkData
增加如下配置
#######################cluster##########################
# Server.A=B:C:D A 为服务器编号,B 为本机 ip,C 为数据交换端口,D 为选举端口
# A 的值,需要在 zkData 目录创建 myid 文件写入
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
server.5=hadoop105:2888:3888
<a name="8e54ddfe-2"></a>
#### 启动
1. 在各个节点启动 zk。`bin/zkServer.sh start`
1. 查看 zk 状态。`bin/zkServer.sh status`
<a name="46d7271e"></a>
### 配置 HA 集群
1. 在opt目录下创建一个ha文件夹
1. 将/opt/module/下的 hadoop-2.7.2拷贝到/opt/ha目录下
1. 配置hadoop-env.sh,以及 Hadoop 环境变量,如果之前的非 HA 集群未停止,先停止
1. core-site.xmlxml
<!-- 指定hadoop运行时产生文件的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/ha/hadoop-2.7.2/data/tmp</value></property>
5. hdfs-site.xml```xml<configuration><!-- 完全分布式集群名称 --><property><name>dfs.nameservices</name><value>mycluster</value></property><!-- 集群中NameNode节点都有哪些 --><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><!-- nn1的RPC通信地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>hadoop103:9000</value></property><!-- nn2的RPC通信地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>hadoop104:9000</value></property><!-- nn1的http通信地址 --><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>hadoop103:50070</value></property><!-- nn2的http通信地址 --><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>hadoop104:50070</value></property><!-- 指定NameNode元数据在JournalNode上的存放位置 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://hadoop103:8485;hadoop104:8485;hadoop105:8485/mycluster</value></property><!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 --><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><!-- 使用隔离机制时需要ssh无秘钥登录--><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><!-- 声明journalnode服务器存储目录--><property><name>dfs.journalnode.edits.dir</name><value>/opt/ha/hadoop-2.7.2/data/jn</value></property><!-- 关闭权限检查--><property><name>dfs.permissions.enable</name><value>false</value></property><!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式--><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 指定Hadoop运行时产生文件的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-2.7.2/data/tmp</value></property><!-- 默认${hadoop.tmp.dir}/dfs/data --><property><name>dfs.datanode.data.dir</name><value>file:///RaidDisk/dfs/dn</value></property><!-- 默认${hadoop.tmp.dir}/dfs/name --><property><name>dfs.namenode.name.dir</name><value>file:///RaidDisk/dfs/nn</value></property></configuration>
- 拷贝配置好的hadoop环境到其他节点
启动和验证HDFS-HA 集群
- 在各个 JournalNode 上启动 JournalNode。
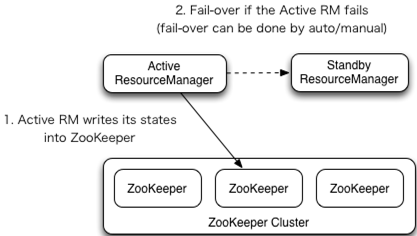
hadoop-daemon.sh start journalnode(如果之前配过 HADOOP 环境变量,可能需要登出重连一下) 在[nn1]上,对其进行格式化,并启动
hdfs namenode -formathadoop-daemon.sh start namenode
在[nn2]上,同步nn1的元数据信息,并启动
hdfs namenode -bootstrapStandbyhadoop-daemon.sh start namenode
在 50070 端口,查看两个 NameNode 的界面。两个都显示 standby
在[nn1]上,启动所有 datanode
# 注意是复数的 daemons,启动所有 datanodehadoop-daemons.sh start datanode
将[nn1]切换为Active
hdfs haadmin -transitionToActive nn1- 查看是否Active
hdfs haadmin -getServiceState nn1
配置 HA 自动故障转移
配置
hdfs-site.xml 增加
<property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property>
core-site.xml 增加
<property><name>ha.zookeeper.quorum</name><value>hadoop103:2181,hadoop104:2181,hadoop105:2181</value></property>
启动和验证
- 关闭所有 HDFS 服务
stop-dfs.sh - 启动 zk 集群
zkServer.sh start - 初始化HA在Zookeeper中状态
hdfs zkfc -formatZK - 启动HDFS服务
start-dfs.sh - kill 掉 Active 状态的 NameNode 或者将该服务器断网,检查集群状态
- 再次启动该 NameNode
hadoop-daemon.sh start namenode
YARN-HA 配置
集群规划
| hadoop103 | hadoop104 | hadoop105 |
|---|---|---|
| NameNode | NameNode | |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| ZK | ZK | ZK |
| ResourceManager | ResourceManager | |
| NodeManager | NodeManager | NodeManager |
配置
- yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!--启用resourcemanager ha--><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><!--声明两台resourcemanager的地址--><property><name>yarn.resourcemanager.cluster-id</name><value>cluster-yarn1</value></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>hadoop103</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>hadoop104</value></property><!--指定zookeeper集群的地址--><property><name>yarn.resourcemanager.zk-address</name><value>hadoop103:2181,hadoop104:2181,hadoop105:2181</value></property><!--启用自动恢复--><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><!--指定resourcemanager的状态信息存储在zookeeper集群--><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property></configuration>
启动
- HDFS-HA 集群启动,参考上面
- 启动 YARN,
start-yarn.sh,在 rm1 节点执行。 - 启动第二个 YARN,
yarn-daemon.sh start resourcemanager,在 rm2 节点执行 - 查看 yarn 服务状态:
yarn rmadmin -getServiceState rm1 - 访问 Yarn Web 界面:8088
如果启动失败,注意查看 out 日志和 log 日志
注意事项
- 最好再修改一下 hadoop PID 文件存放位置。hadoop PID 文件默认存放在 /tmp 目录下,该目录会定时清理。如果 Hadoop PID 文件被清理了,当我们使用命令停止 hadoop 时,会出现 no datanode to stop 的错误提示。
其他
集群启动总结
各个服务组件逐一启动/停止
- 分别启动/停止HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode - 启动/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
各个模块分开启动/停止(配置ssh是前提)常用
- 整体启动/停止HDFS
start-dfs.sh / stop-dfs.sh(任意节点皆可) - 整体启动/停止YARN
start-yarn.sh / stop-yarn.sh(如果 NameNode 和 ResourceManger 如果不是同一台机器,不能在 NameNode 上启动 YARN,应该在ResouceManager 所在的机器上启动YARN。)
集群时间同步配置
时间服务器配置(必须root用户)
- 检查ntp是否安装 ``` rpm -qa|grep ntp
ntp-4.2.6p5-10.el6.centos.x86_64 # 没有,需要安装 fontpackages-filesystem-1.41-1.1.el6.noarch ntpdate-4.2.6p5-10.el6.centos.x86_64
2. 修改ntp配置文件
vi /etc/ntp.conf
修改内容如下 a)修改1(授权192.168.1.0-192.168.1.255网段上的所有机器可以从这台机器上查询和同步时间)
restrict default nomodify notrap nopeer noquery 为
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
b)修改2(集群在局域网中,不使用其他互联网上的时间) server 0.centos.pool.ntp.org iburst server 1.centos.pool.ntp.org iburst server 2.centos.pool.ntp.org iburst server 3.centos.pool.ntp.org iburst为
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步) server 127.127.1.0 fudge 127.127.1.0 stratum 10
3. 修改/etc/sysconfig/ntpd 文件,增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
4. 重新启动ntpd服务 `service ntpd restart`4. 设置ntpd服务开机启动```shellchkconfig ntpd onsystemctl enable ntpd
其他机器配置(必须root用户)
- 在其他机器配置10分钟与时间服务器同步一次。(稍后可以修改时间进行测试。)
crontab -e*/10 * * * * /usr/sbin/ntpdate hadoop102
脚本
xsync 脚本
同步文件到各个服务器
#!/bin/bash#1 获取输入参数个数,如果没有参数,直接退出pcount=$#if ((pcount==0)); thenecho no args;exit;fi#2 获取文件名称p1=$1fname=`basename $p1`echo fname=$fname#3 获取上级目录到绝对路径pdir=`cd -P $(dirname $p1); pwd`echo pdir=$pdir#4 获取当前用户名称user=`whoami`#5 循环for((host=104; host<106; host++)); doecho ------------------- hadoop$host --------------rsync -av $pdir/$fname $user@hadoop$host:$pdirdone
Troubleshootings
ReadOnly
发现 Hadoop 集群无法读写,检查发现两个 Namenode 都是 standby 状态。原因是启动集群之前未正常启动 zk 集群。需要重新启动集群。

若有收获,就点个赞吧
0 人点赞
