1,* 消息队列的作用:
作用与其他消息队列一样:
- 异步处理:
- 可以将一些比较耗时的操作放到其他系统中,通过消息队列将需要进行处理的操作进行存储,其他系统可以消费消息队列中的数据处理需要的业务;
- 常见的应用场景:发送短信验证码,发送邮箱验证等;
- 系统解耦:
- 原先一个微服务是通过接口(http)调用另外一个微服务,耦合严重,当如果需要修改一个微服务,那么与之相关的微服务也要随之修改,否则可能会导致系统不可用;
- 使用消息队列进行解耦,由第一个微服务将操作消息放到消息队列,另外一个微服务可以从消息队列中获取进行处理,进行系统解耦;
- 流量削峰:
- 因为消息队列是低延迟,高可靠,高吞吐的,可以应对大量海量的并发量;
- 日志处理:
- 异步处理:
-
2.1,Kafka的应用场景:
- **通常Kafka应用在两类程序:**1. 建立实时数据管道;可以可靠地在系统与应用程序之间获取数据;1. 构建实时流应用程序;以转换或响应数据流;
2.2,那么Kafka和RabbitMQ之间的区别?
1.应用场景方面
RabbitMQ:用于实时的,对可靠性要求较高的消息传递上。
kafka:用于处于活跃的流式数据,大数据量的数据处理上。
2.语言方面
RabbitMQ是由内在高并发的erlanng语言开发,用在实时的对可靠性要求比较高的消息传递上。
kafka是采用Scala语言开发,它主要用于处理活跃的流式数据,大数据量的数据处理上
3.吞吐量方面- RabbitMQ:支持消息的可靠的传递,支持事务,不支持批量操作,基于存储的可靠性的要求存储可以采用内存或硬盘,吞吐量小。 - kafka:内部采用消息的批量处理,数据的存储和获取是本地磁盘顺序批量操作,消息处理的效率高,吞吐量高。
4.Brokerr与Consume交互方式不同
RabbitMQ 采用push的方式
kafka采用pull的方式
5.集群负载均衡方面
- RabbitMQ:本身不支持负载均衡,需要**loadbalancer**的支持
- kafka:采用zookeeper对集群中的broker,consumer进行管理,可以注册topic到zookeeper上,通过zookeeper的协调机制, producer保存对应的topic的broker信息,可以随机或者轮询发送到broker上,producer可以基于语义指定分片,消息发送到broker的某个分片上。
3,Kafka的原理结构:
3.1,结构图:
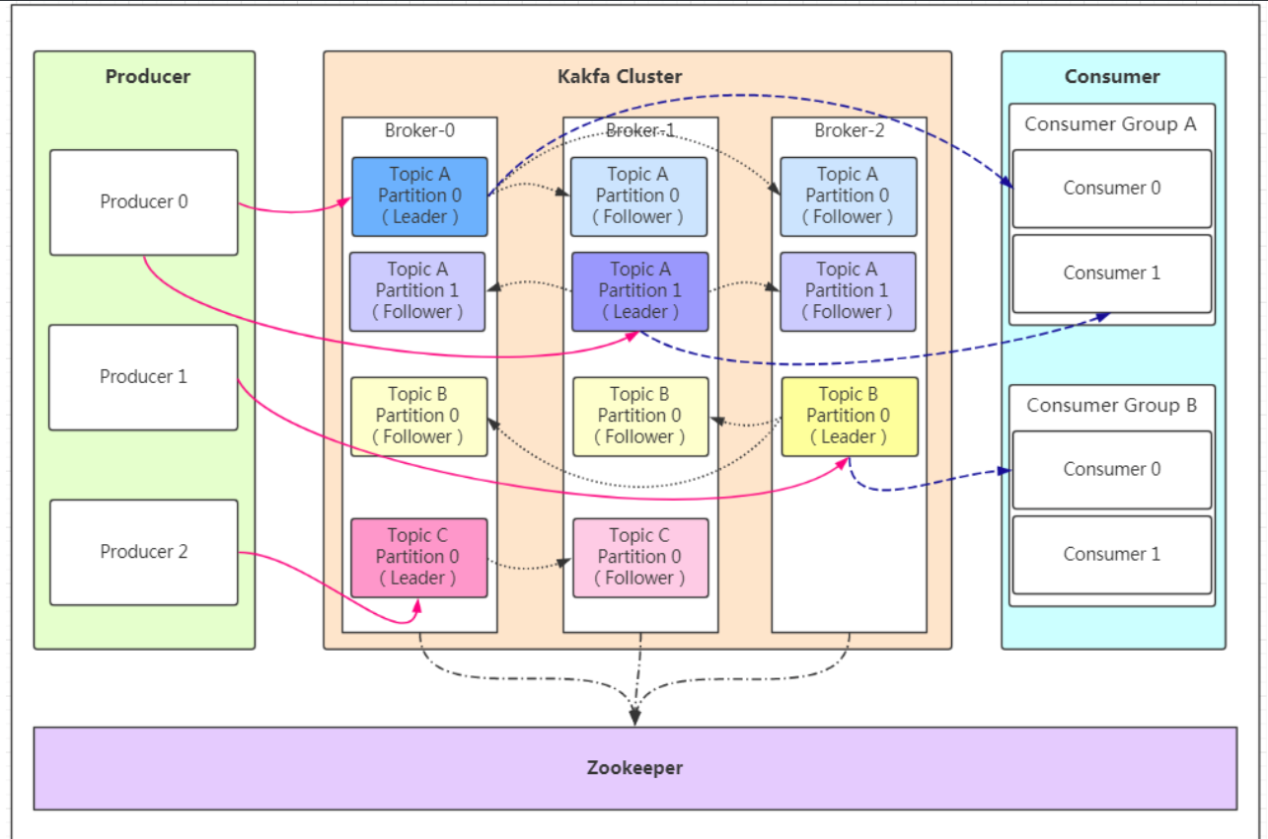
3.2,* 结构图解:
- **消息Message:**Kafka 中的数据单元被称为消息message,也被称为记录,可以把它看作数据库表中某一行的记录。
- **topic(话题/主题):**Kafka将消息分门别类,每一类的消息称之为一个主题(Topic)
- **批次:**为了提高效率, 消息会分批次写入 Kafka,批次就代指的是一组消息。
- **分区 Partition:(高并发)**
- 主题可以被分为若干个分区(partition),同一个主题中的分区可以不在一个机器上,有可能会部署在多个机器上,由此来实现 kafka 的伸缩性。topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个文件进行存储。**一个partition中的数据是有序的,多个partition之间的数据是没有顺序的**。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
- **注意:消费者数量要尽量保证等于或者大于分区数量,否则会可能导致消息堆积导致阻塞;**
- **broker:**一个独立的 Kafka 服务器就被称为 broker,broker 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。
- **Broker集群:**
- broker 是集群 的组成部分,broker 集群由一个或多个 broker 组成,每个集群都有一个 broker同时充当了集群控制器的角色(自动从集群的活跃成员中选举出来)。
- **副本 Replica:在kafka中定义了两种副本;**
- *** 领导者(Leader)副本 和 跟随者(follower)副本:所有的写请求都会通过leader路由,数据变更会广播给所有Follower,保证了Leader和Follower的数据一致性;如果Leader失效,那么将会从Follower中选举一个新的Leader;当Follower与Leader的连接挂掉,卡住或者太慢,leader会把这个follower从ISR列表中(保持同步的副本列表)删除,并重新创建一个Follower;**
- **Zookeeper:**
- **kafka对与zookeeper是强依赖的**,是以zookeeper作为基础的,即使不做集群,也需要zk的支持。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行重平衡。
- **消费者群组Consumer Group:**
- 生产者与消费者的关系就如同餐厅中的厨师和顾客之间的关系一样,一个厨师对应多个顾客,也就是一个生产者对应多个消费者,消费者群组(Consumer Group)指的就是由一个或多个消费者组成的群体。
- **偏移量 Offest:**
- 偏移量(Consumer Offset)是一种元数据,它是一个不断递增的整数值,用来记录消费者发生重平衡时的位置,以便用来恢复数据。
- **重平衡 Rebalance:**
- 消费者同组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。(当**消费者数量大于分区数量**时会发生重平衡)
3.3,Kafka的消费者偏移量属性:
- 该属性指定了消费者是否自动提交偏移量,默认值是true。为了尽量避免出现重复数据和数据丢失,可以把它设置为false,由自己控制何时提交偏移量。如果把它设置为true,还可以通过配置
auto.commit.interval.ms属性来控制提交的频率。 - auto.offset.reset
- earliest
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费 - latest(默认值)
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据 - none
topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常 - anything else
向consumer抛出异常
- earliest
- 如果没有设置自动提交偏移量的话,就要手动在业务处理完毕后写代码提交offest(偏移量);
- 如果没有设置偏移量的话,又要避免重复消费的情况,就要为消息设置唯一标识避免重复消费;
4,* Kafka的生产者详解:
*,发送消息的工作原理:
- 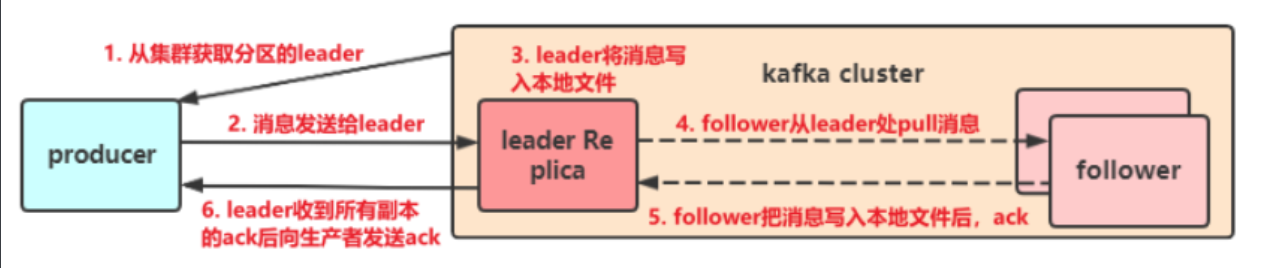
- **总结:**
- **首先生成者(producer)从集群中获取分区的leader,再将消息发送给leader,leader收到消息后将消息写入本地文件,follower会从leader那里拉取(pull)消息,当follower把消息写入本地文件后,会通过ack消息确认机制发送操作结果信息给leader,如果leader收到了所有副本的ack后再向生产者发送ack;**
*,如何从集群中获取分区中的Leader:
1. **生产者producer把消息发送给指定的topic;**
1. **生产者发送消息key给kafka;**
1. **kafka到指定的topic中,使用key进行hash计算,得到哈希值,利用哈希值%(模)分区总数 = 分区下标;**
1. **Kafka根据分区下标找到分区下的Leader;**
4.1,Kafka的三种消息发送类型:
4.1.1,异步发送并忘记(fire-and-forget)(用的最多):
把消息发送给服务器,并不关心它是否正常到达,大多数情况下,消息会正常到达,因为kafka是高可用的,而且生产者会自动尝试重发,使用这种方式有时候会丢失一些信息
//发送消息
try {
producer.send(record);
}catch (Exception e){
e.printStackTrace();
}
应用场景:如果业务只关心消息的吞吐量,容许少量消息发送失败,也不关注消息的发送顺序,那么可以使用发送并忘记的方式
4.1.2,同步发送(用的很少):
使用send()方法发送,它会返回一个Future对象,调用get()方法进行等待,就可以知道消息是否发送成功
//发送消息
try {
RecordMetadata recordMetadata = producer.send(record).get();
System.out.println(recordMetadata.offset());//获取偏移量
}catch (Exception e){
e.printStackTrace();
}
如果服务器返回错误,get()方法会抛出异常,如果没有发生错误,我们就会得到一个RecordMetadata对象,可以用它来获取消息的偏移量
**应用场景:** 如果业务要求消息尽可能不丢失且必须是按顺序发送的,那么可以使用同步的方式 ( 只能在一个partation上 )
4.1.3,异步发送+回调:
调用send()方法,并指定一个回调函数,服务器在返回响应时调用函数。如下代码
//发送消息
try {
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if(e!=null){
e.printStackTrace();
}
System.out.println(recordMetadata.offset());
}
});
}catch (Exception e){
e.printStackTrace();
}
如果kafka返回一个错误,onCompletion()方法会抛出一个非空(non null)异常,可以根据实际情况处理,比如记录错误日志,或者把消息写入“错误消息”文件中,方便后期进行分析。
应用场景: 如果业务需要知道消息发送是否成功,并且对消息的顺序不关心,那么可以用异步+回调的方式来发送消息
4.1.4,(优化)如何达到Kafka最高并发量:
- 1)一个主题多个分区 + 异步发送+不回调、
- 达到Kafka数据一致性最高+消息有序(消息不丢失):<br />1)一个主题一个分区+ 同步发送 + 回调函数
4.2,生成者参数详解:(ack 和 retries)
到目前为止,我们只介绍了生产者的几个必要参数(bootstrap.servers、序列化器等)
生产者还有很多可配置的参数,在kafka官方文档中都有说明,大部分都有合理的默认值,所以没有必要去修改它们,不过有几个参数在内存使用,性能和可靠性方法对生产者有影响
- acks:消息确认机制
指的是producer的消息发送确认机制- acks=0
生产者在成功写入消息之前不会等待任何来自服务器的响应,也就是说,如果当中出现了问题,导致服务器没有收到消息,那么生产者就无从得知,消息也就丢失了。不过,因为生产者不需要等待服务器的响应,所以它可以以网络能够支持的最大速度发送消息,从而达到很高的吞吐量。 - acks=1 (默认值)
只要集群首领节点收到消息,生产者就会收到一个来自服务器的成功响应,如果消息无法到达首领节点,生产者会收到一个错误响应,为了避免数据丢失,生产者会重发消息。 - acks=all
只有当所有参与赋值的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应,这种模式是最安全的,它可以保证不止一个服务器收到消息,就算有服务器发生崩溃,整个集群仍然可以运行。不过他的延迟比acks=1时更高。- 具有同样的机制的技术组件还有:Nacos微服务组件
- acks=0
- retries:消息重试机制
生产者从服务器收到的错误有可能是临时性错误,在这种情况下,retries参数的值决定了生产者可以重发消息的次数,如果达到这个次数,生产者会放弃重试返回错误,默认情况下,生产者会在每次重试之间等待100ms
5,* Kafka的消费者详解:
*,消费者的工作原理:
- 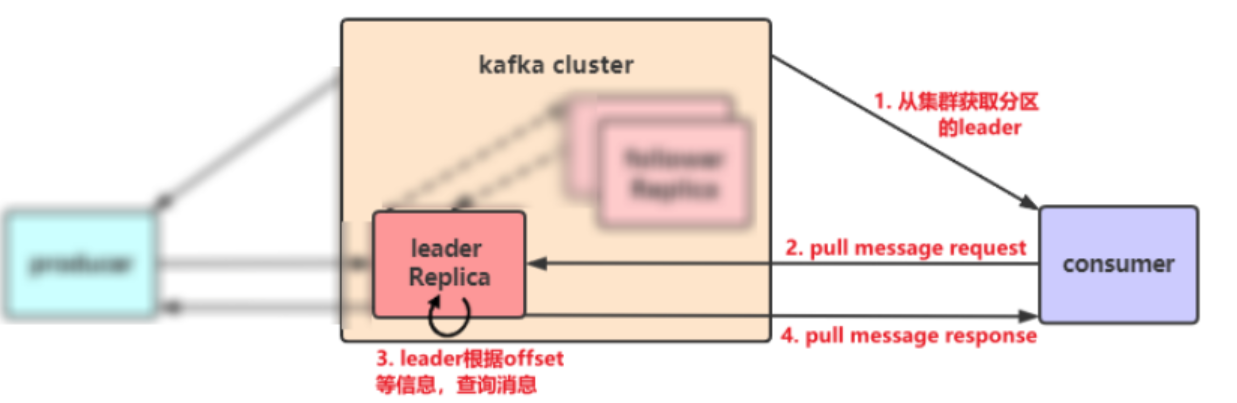
*,消费重平衡 Rebalance:
- 消费者同组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
5.1,Kafka的消费者偏移量属性:
- 该属性指定了消费者是否自动提交偏移量,默认值是true。为了尽量避免出现重复数据和数据丢失,可以把它设置为false,由自己控制何时提交偏移量。如果把它设置为true,还可以通过配置
auto.commit.interval.ms属性来控制提交的频率。 - auto.offset.reset
- earliest
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费 - latest(默认值)
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据 - none
topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常 - anything else
向consumer抛出异常
- earliest
- 如果没有设置自动提交偏移量的话,就要手动在业务处理完毕后写代码提交offest(偏移量);
- 如果没有设置偏移量的话,又要避免重复消费的情况,就要为消息设置唯一标识避免重复消费;
6,* SpringBoot整合Kafka-1:
6.1,导入依赖:
<!-- kafkfa -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>${kafka.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.client.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
6.2,在resource或者nacos配置application文件:
server:
port: 9991
spring:
application:
name: kafka-demo
kafka:
bootstrap-servers: 119.23.63.60:9092
producer:
retries: 10
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: test-hello-group
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
6.3,创建启动类:
package com.itheima.kafka;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class KafkaApplication {
public static void main(String[] args) {
SpringApplication.run(KafkaApplication.class,args);
}
}
6.4,* 创建生产者:
package com.heima.kakfa.springboot;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class HelloController {
//注入kafka的模板方法对象
@Autowired
private KafkaTemplate<String,String> kafkaTemplate;
/**
* 普通消费发现
*/
@GetMapping("/hello1")
public String hello1(){
kafkaTemplate.send("boot","1001","hello springboot kafka!");
return "发送成功";
}
}
6.5,* 创建消费者:
- **或者说是创建Listener(监听)类:**
package com.heima.kakfa.springboot;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class HelloListener {
@KafkaListener(topics = "boot")
public void handleHello1(ConsumerRecord<String,String> record){
String key = record.key();
String value = record.value();
System.out.println(key+"---"+value);
}
}
7,* SpringBoot整合Kafka-2 之 序列化与传递对象:
目前SpringBoot整合后的Kafka,因为序列化器是StringSerializer,这个时候如果需要传递对象可以有两种方式
- 方式一:可以自定义序列化器,对象类型众多,这种方式通用性不强,本章节不介绍(略)
- 方式二:可以把要传递的对象进行转json字符串,接收消息后再转为对象即可,本项目采用这种方式
7.1,新建类User
package com.itheima.kafka.boot;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private String username;
private Integer age;
}
7.2,修改消息发送
package com.heima.kakfa.springboot;
import com.alibaba.fastjson.JSON;
import com.heima.kakfa.pojo.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class HelloController {
@Autowired
private KafkaTemplate<String,String> kafkaTemplate;
/**
* 普通消费发现
*/
@GetMapping("/hello1")
public String hello1(){
kafkaTemplate.send("boot","1001","hello springboot kafka!");
return "发送成功";
}
/**
* 消息只发送value值,不发key
* @return
*/
@GetMapping("/hello2")
public String hello2(){
kafkaTemplate.send("boot2","Only value");
return "发送成功";
}
/**
* 消息发送对象
* @return
*/
@GetMapping("/hello3")
public String hello3(){
User user = new User("如花",18);
//转换json字符串
String json = JSON.toJSONString(user);
kafkaTemplate.send("boot3",json);
return "发送成功";
}
}
7.3,修改消费者
package com.heima.kakfa.springboot;
import com.alibaba.fastjson.JSON;
import com.heima.kakfa.pojo.User;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class HelloListener {
@KafkaListener(topics = "boot")
public void handleHello1(ConsumerRecord<String,String> record){
String key = record.key();
String value = record.value();
System.out.println(key+"---"+value);
}
/**
* 只接收value
* @param value
*/
@KafkaListener(topics = "boot2")
public void handleHello2(String value){
System.out.println(value);
}
/**
* 接收对象
* @param value
*/
@KafkaListener(topics = "boot3")
public void handleHello3(String value){
//转为对象
User user = JSON.parseObject(value, User.class);
System.out.println("username:"+user.getUsername()+",age:"+user.getAge());
}
}
8,为什么Kafka这么快?
1)利用 Partition (分区)实现并行处理
2)顺序写磁盘
3)充分利用 Page Cache(减少磁盘擦写)
4)零拷贝技术,减少CPU上下文切换成本
5)消息的批处理
6)消息数据压缩

若有收获,就点个赞吧
0 人点赞
