拓展:ZK是什么

拓展:强、弱、最终一致性
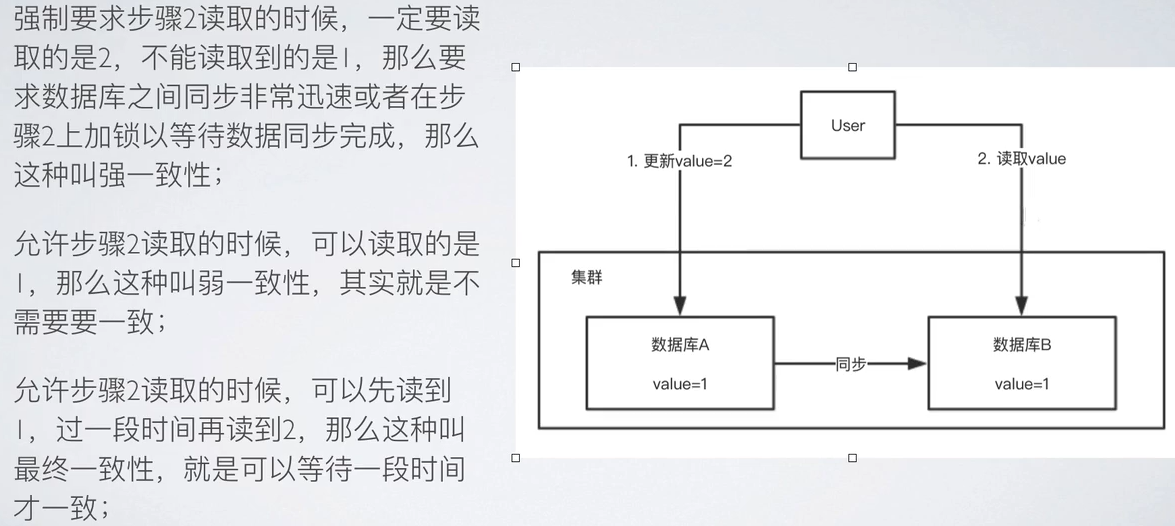
PS:ZK尽量保持强一致性,但是最终达到的还是“最终一致性”
拓展:ZK领导选举:过半机制
1、集群启动
集群刚启动的时候,此时都还没有zxid,每个zk服务器都处于looking状态,都投票给自己,这样就都是
获取1票,然后根据myid来选举领导,myid比较大的,最先达到集群数量一半以上的节点就是领导。如
3个机器的zk集群,领导是myid = 2的机器;5个机器的zk集群,领导是myid为3的机器
2、领导挂掉
(1)投票给自己
(2)接收其他服务器的选票
(3)比较zxid,zxid比较大的就说明修改比较新,相当于进行一个pk
(4)记录自己的票投给了哪台服务器(即“pk之后最厉害的服务器”)
(5)这些投票的信息都会维护在一个投票箱中,实际上是一个Map
(6)对投票箱进行统计,获取票数超过集群数量一半的节点成为新的leader
PS:可以看到,无论是启动时进行的领导选举,还是其中过程中由于leader宕机导致的新一轮领导选举,
都利用了过半机制。
拓展:ZK内存结构:DataTree
ZK服务器处理客户端请求,数据是从内存中获取的,ZK在内存中维护了一个叫做DataTree的数据结构,
mysql中也有类似的结构,不同的是mysql的内存结构只会缓存部分的数据,而ZK的DataTree会缓存
zk的所有数据。
拓展:ZK处理请求:事务日志
ZK服务器处理客户端请求,不会直接修改DataTree中的数据(更新),而是先生成1个事务日志,持久化到磁盘中,然后进行2阶段提交,最后才更新内存中的数据。
这是因为,ZK有4类节点,主要是持久、临时类型的节点,持久化的节点显然需要将数据持久化到磁盘中,
ZK先生成事务日志,持久化到磁盘中,最后才更新内存数据,这是为了确保ZK服务器宕机之后,能够恢复
完整的数据,不会丢失任何数据,这也是ZK保证强一致性的原因。
拓展:ZK处理请求:两阶段提交
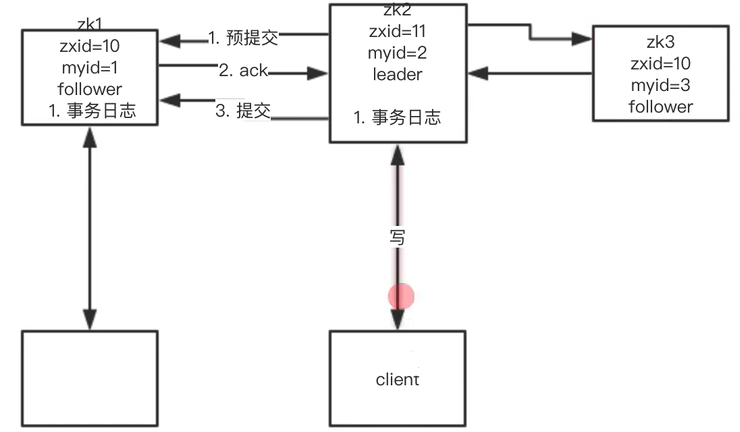
PS:解释如下(以下发送的是写请求)
1、client发送请求到zk的leader节点
2、leader节点生成1个事务日志
3、leader节点发起“预提交”命令到follower节点
4、follower节点收到命令生成事务日志
5、follower节点发送ack到leader节点
6、leader节点发送“提交”命令到follower节点
7、leader和follower节点通过事务日志更新内存最新数据
注意:
(1)leader收到一般以上节点(包括自己)的ack请求,就会发起“提交”命令
(2)当发送的是读请求,处理节点可以是leader、follower节点
(3)当发送的是写请求,处理节点只能是leader,follower会将请求转发到leader处理
拓展:ZK集群个数尽量是奇数(反证)
zookeeper的通信协议采用的是paxos协议,paxos协议的核心思想是“过半操作成功,才算成功”。
这里简单利用反证法来证明即可
集群数量为4,需要3台机器来确保集群能对外提供服务,
集群数量为5,也需要3台几区来确保集群能对外提供服务,
那么,“只花3台机器”就能“控制5台机器”,提供更好的服务,为什么我不多增1台呢
拓展:不参与选举的Observer节点
一般来说为了提高ZK集群的“读”能力,可以引入多个follower节点;缺点是leader进行而阶段提交的时候
需要等待更多的ack,影响了leader节点的写性能。因此引入了不需要ack,且能够为客户端提供读操作的角色,
即observer,区别是observer节点不参与leader和follower的领导选举。主要的工作流程如下
1、处理读请求
(1)zk客户端发送读请求到observer
(2)observer和follower一样直接返回
2、处理写请求
(1)leader发送预提交给follower(不发给observer)
(2)leader收到一半以上follower发送的ack
(3)leader发送“提交”命令到follower、observer
PS:可以看到,observer直接接受leader节点的“提交”命令,直接更新内存中的datatree,不会生成事务日志

若有收获,就点个赞吧
0 人点赞
