1. 找到torch安装目录
- D:\ProgramData\Anaconda3\envs\study-ml\Lib\site-packages\torch
- 我的路径在,conda的虚拟环境下的study-ml下
- 找到这个路径:Lib\site-packages\torch
- 版本大于1.4以后似乎就没有initpyi这个文件了
- 下载init.pyi附件,放在上面的路径下就可以了
2. init.pyi下载地址
网盘地址:https://pan.baidu.com/s/1DUcJq-fj0VR3xUiYkXHBA?_at=1622265991308
提取码:6pwe
原因是什么没有摸清,但是基本上可以确定是由于init.pyi缺失或者存在问题导致的。我的pytorch版本是0.4.1,但是在网上没有找到0.4.1的相关init.pyi的版本,所以我使用的是1.0.1的。
3. 解决方法:
进入到这个链接中,在pytorch文件夹下,找到一个版本的init.pyi放到你的虚拟环境所在目录下的torch中。如我的torch包所在位置为D:\Program Files (x86)\Anaconda\envs\pytorch\Lib\site-packages\torch,然后将init.pyi复制进来
到这就结束了吗?并没有,当你重启运行pycharm时,可以自动补全torch.sum、torch.mean等函数,但是却无法引用torch.nn等模块,此时只需要在init.pyi文件中加入下面两行即可。
from torch import nn, cuda, ops, functional, optim, autograd, onnx, utilsfrom torch import contrib, distributions, for_onnx, jit, multiprocessing
加入前: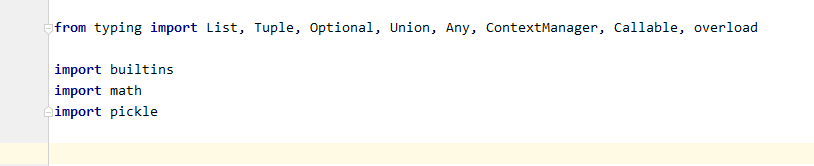
加入后: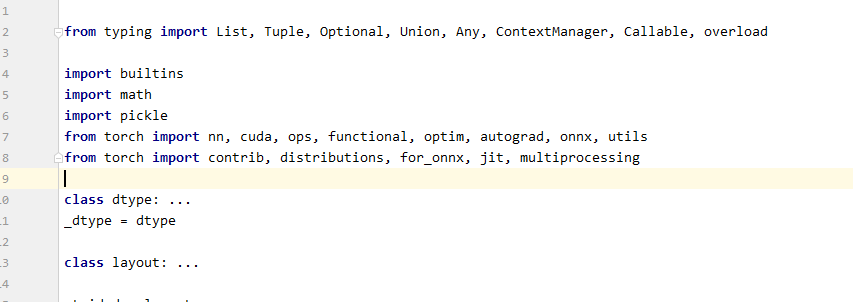
然后,再重启pycharm即可。
可以看到,代码自动补全功能已经恢复了。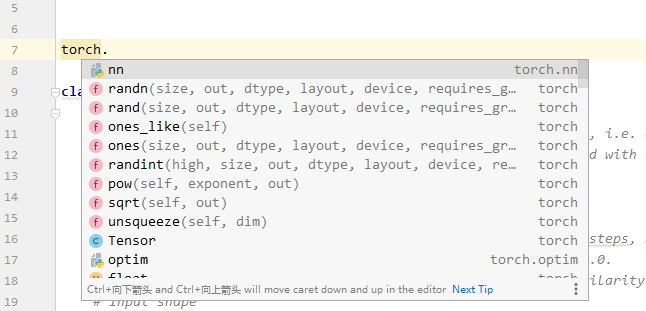
版权声明:本文为qq_35531985原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/qq_35531985/article/details/107980736
init.pyi文件可直接复制
from typing import List, Tuple, Optional, Union, Any, ContextManager, Callable, overloadimport builtinsimport mathimport picklefrom torch import nn, cuda, ops, functional, optim, autograd, onnx, utilsfrom torch import contrib, distributions, for_onnx, jit, multiprocessingclass dtype: ..._dtype = dtypeclass layout: ...strided : layout = ...class device:def __init__(self, device: Union[device, str, None]=None) -> None: ...class Generator: ...class Size(tuple): ...class Storage: ...class enable_grad():def __enter__(self) -> None: ...def __exit__(self, *args) -> None: ...def __call__(self, func : Callable) -> Callable: ...class no_grad():def __enter__(self) -> None: ...def __exit__(self, *args) -> None: ...def __call__(self, func : Callable) -> Callable: ...class set_grad_enabled():def __init__(self, mode: bool) -> None: ...def __enter__(self) -> None: ...def __exit__(self, *args) -> None: ...class Tensor:dtype: _dtype = ...shape: Size = ...requires_grad: bool = ...grad: Optional['Tensor'] = ...def __abs__(self) -> 'Tensor': ...def __add__(self, other: Any) -> 'Tensor': ...def __and__(self, other: Any) -> 'Tensor': ...def __array__(self, dtype=None): ...def __array_wrap__(self, array): ...def __bool__(self) -> bool: ...def __deepcopy__(self, memo): ...def __dir__(self): ...def __div__(self, other: Any) -> 'Tensor': ...def __eq__(self, other: Any) -> 'Tensor': ... # type: ignoredef __float__(self) -> builtins.float: ...def __floordiv__(self, other): ...def __format__(self, format_spec): ...def __ge__(self, other: Any) -> 'Tensor': ... # type: ignoredef __getitem__(self, indices: Union[None, builtins.int, slice, 'Tensor', List, Tuple]) -> 'Tensor': ...def __gt__(self, other: Any) -> 'Tensor': ... # type: ignoredef __hash__(self): ...def __iadd__(self, other: Any) -> 'Tensor': ...def __iand__(self, other: Any) -> 'Tensor': ...def __idiv__(self, other: Any) -> 'Tensor': ...def __ilshift__(self, other: Any) -> 'Tensor': ...def __imul__(self, other: Any) -> 'Tensor': ...def __index__(self) -> builtins.int: ...def __int__(self) -> builtins.int: ...def __invert__(self) -> 'Tensor': ...def __ior__(self, other: Any) -> 'Tensor': ...def __ipow__(self, other): ...def __irshift__(self, other: Any) -> 'Tensor': ...def __isub__(self, other: Any) -> 'Tensor': ...def __iter__(self): ...def __itruediv__(self, other: Any) -> 'Tensor': ...def __ixor__(self, other: Any) -> 'Tensor': ...def __le__(self, other: Any) -> 'Tensor': ... # type: ignoredef __len__(self): ...def __long__(self) -> builtins.int: ...def __lshift__(self, other: Any) -> 'Tensor': ...def __lt__(self, other: Any) -> 'Tensor': ... # type: ignoredef __matmul__(self, other: Any) -> 'Tensor': ...def __mod__(self, other: Any) -> 'Tensor': ...def __mul__(self, other: Any) -> 'Tensor': ...def __ne__(self, other: Any) -> 'Tensor': ... # type: ignoredef __neg__(self) -> 'Tensor': ...def __nonzero__(self) -> bool: ...def __or__(self, other: Any) -> 'Tensor': ...def __pow__(self, other: Any) -> 'Tensor': ...def __radd__(self, other: Any) -> 'Tensor': ...def __rdiv__(self, other): ...def __reduce_ex__(self, proto): ...def __repr__(self): ...def __reversed__(self): ...def __rfloordiv__(self, other): ...def __rmul__(self, other: Any) -> 'Tensor': ...def __rpow__(self, other): ...def __rshift__(self, other: Any) -> 'Tensor': ...def __rsub__(self, other): ...def __rtruediv__(self, other): ...def __setitem__(self, indices: Union[None, builtins.int, slice, 'Tensor', List, Tuple], val: Union['Tensor', builtins.float, builtins.int]) -> None: ...def __setstate__(self, state): ...def __sub__(self, other: Any) -> 'Tensor': ...def __truediv__(self, other: Any) -> 'Tensor': ...def __xor__(self, other: Any) -> 'Tensor': ...def abs(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def abs_(self) -> 'Tensor': ...def acos(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def acos_(self) -> 'Tensor': ...@overloaddef add(self, other: 'Tensor', *, alpha: Union[builtins.float, builtins.int]=1, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef add(self, other: Union[builtins.float, builtins.int], alpha: Union[builtins.float, builtins.int]=1, *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef add_(self, other: 'Tensor', *, alpha: Union[builtins.float, builtins.int]=1) -> 'Tensor': ...@overloaddef add_(self, other: Union[builtins.float, builtins.int], alpha: Union[builtins.float, builtins.int]=1) -> 'Tensor': ...def addbmm(self, batch1: 'Tensor', batch2: 'Tensor', *, beta: Union[builtins.float, builtins.int]=1, alpha: Union[builtins.float, builtins.int]=1, out: Optional['Tensor']=None) -> 'Tensor': ...def addbmm_(self, batch1: 'Tensor', batch2: 'Tensor', *, beta: Union[builtins.float, builtins.int]=1, alpha: Union[builtins.float, builtins.int]=1) -> 'Tensor': ...def addcdiv(self, tensor1: 'Tensor', tensor2: 'Tensor', *, value: Union[builtins.float, builtins.int]=1, out: Optional['Tensor']=None) -> 'Tensor': ...def addcdiv_(self, tensor1: 'Tensor', tensor2: 'Tensor', *, value: Union[builtins.float, builtins.int]=1) -> 'Tensor': ...def addcmul(self, tensor1: 'Tensor', tensor2: 'Tensor', *, value: Union[builtins.float, builtins.int]=1, out: Optional['Tensor']=None) -> 'Tensor': ...def addcmul_(self, tensor1: 'Tensor', tensor2: 'Tensor', *, value: Union[builtins.float, builtins.int]=1) -> 'Tensor': ...def addmm(self, mat1: 'Tensor', mat2: 'Tensor', *, beta: Union[builtins.float, builtins.int]=1, alpha: Union[builtins.float, builtins.int]=1, out: Optional['Tensor']=None) -> 'Tensor': ...def addmm_(self, mat1: 'Tensor', mat2: 'Tensor', *, beta: Union[builtins.float, builtins.int]=1, alpha: Union[builtins.float, builtins.int]=1) -> 'Tensor': ...def addmv(self, mat: 'Tensor', vec: 'Tensor', *, beta: Union[builtins.float, builtins.int]=1, alpha: Union[builtins.float, builtins.int]=1, out: Optional['Tensor']=None) -> 'Tensor': ...def addmv_(self, mat: 'Tensor', vec: 'Tensor', *, beta: Union[builtins.float, builtins.int]=1, alpha: Union[builtins.float, builtins.int]=1) -> 'Tensor': ...def addr(self, vec1: 'Tensor', vec2: 'Tensor', *, beta: Union[builtins.float, builtins.int]=1, alpha: Union[builtins.float, builtins.int]=1, out: Optional['Tensor']=None) -> 'Tensor': ...def addr_(self, vec1: 'Tensor', vec2: 'Tensor', *, beta: Union[builtins.float, builtins.int]=1, alpha: Union[builtins.float, builtins.int]=1) -> 'Tensor': ...@overloaddef all(self, *, out: Optional['Tensor']=None) -> Union[builtins.float, builtins.int]: ...@overloaddef all(self, dim: builtins.int, keepdim: bool=False, *, out: Optional['Tensor']=None) -> 'Tensor': ...def allclose(self, other: 'Tensor', rtol: builtins.float=1e-05, atol: builtins.float=1e-08, equal_nan: bool=False) -> bool: ...@overloaddef any(self, *, out: Optional['Tensor']=None) -> Union[builtins.float, builtins.int]: ...@overloaddef any(self, dim: builtins.int, keepdim: bool=False, *, out: Optional['Tensor']=None) -> 'Tensor': ...def apply_(self, callable: Callable) -> 'Tensor': ...def argmax(self, dim=None, keepdim=False): ...def argmin(self, dim=None, keepdim=False): ...def argsort(self, dim=None, descending=False): ...def asin(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def asin_(self) -> 'Tensor': ...def atan(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def atan2(self, other: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...def atan2_(self, other: 'Tensor') -> 'Tensor': ...def atan_(self) -> 'Tensor': ...def backward(self, gradient=None, retain_graph=None, create_graph=False): ...def baddbmm(self, batch1: 'Tensor', batch2: 'Tensor', *, beta: Union[builtins.float, builtins.int]=1, alpha: Union[builtins.float, builtins.int]=1, out: Optional['Tensor']=None) -> 'Tensor': ...def baddbmm_(self, batch1: 'Tensor', batch2: 'Tensor', *, beta: Union[builtins.float, builtins.int]=1, alpha: Union[builtins.float, builtins.int]=1) -> 'Tensor': ...@overloaddef bernoulli(self, *, generator: Generator=None, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef bernoulli(self, p: builtins.float, *, generator: Generator=None, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef bernoulli_(self, p: 'Tensor', *, generator: Generator=None) -> 'Tensor': ...@overloaddef bernoulli_(self, p: builtins.float=0.5, *, generator: Generator=None) -> 'Tensor': ...def bincount(self, weights: Optional['Tensor']=None, minlength: builtins.int=0) -> 'Tensor': ...def bmm(self, mat2: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...def btrifact(self, info=None, pivot=True): ...def btrifact_with_info(self, *, pivot: bool=True, out: Optional['Tensor']=None) -> Tuple['Tensor', 'Tensor', 'Tensor']: ...def btrisolve(self, LU_data: 'Tensor', LU_pivots: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...def byte(self) -> 'Tensor': ...def cauchy_(self, median: builtins.float=0, sigma: builtins.float=1, *, generator: Generator=None) -> 'Tensor': ...def ceil(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def ceil_(self) -> 'Tensor': ...def char(self) -> 'Tensor': ...def chunk(self, chunks: builtins.int, dim: builtins.int=0) -> Union[Tuple['Tensor', ...],List['Tensor']]: ...def clamp(self, min: builtins.float=-math.inf, max: builtins.float =math.inf, *, out: Optional['Tensor']=None) -> 'Tensor': ...def clamp_(self, min: builtins.float=-math.inf, max: builtins.float =math.inf) -> 'Tensor': ...def clone(self) -> 'Tensor': ...def contiguous(self) -> 'Tensor': ...def copy_(self, src: 'Tensor', non_blocking: bool=False) -> 'Tensor': ...def cos(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def cos_(self) -> 'Tensor': ...def cosh(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def cosh_(self) -> 'Tensor': ...def cpu(self) -> 'Tensor': ...def cross(self, other: 'Tensor', dim: builtins.int=-1, *, out: Optional['Tensor']=None) -> 'Tensor': ...def cuda(self, device: Optional[device]=None, non_blocking: bool=False) -> 'Tensor': ...@overloaddef cumprod(self, dim: builtins.int, *, dtype: _dtype, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef cumprod(self, dim: builtins.int, *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef cumsum(self, dim: builtins.int, *, dtype: _dtype, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef cumsum(self, dim: builtins.int, *, out: Optional['Tensor']=None) -> 'Tensor': ...def data_ptr(self) -> builtins.int: ...def det(self) -> 'Tensor': ...def detach(self) -> 'Tensor': ...def detach_(self) -> 'Tensor': ...def diag(self, diagonal: builtins.int=0, *, out: Optional['Tensor']=None) -> 'Tensor': ...def diagflat(self, offset: builtins.int=0) -> 'Tensor': ...def diagonal(self, offset: builtins.int=0, dim1: builtins.int=0, dim2: builtins.int=1) -> 'Tensor': ...def digamma(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def digamma_(self) -> 'Tensor': ...def dim(self) -> builtins.int: ...def dist(self, other: 'Tensor', p: Union[builtins.float, builtins.int]=2) -> Union[builtins.float, builtins.int]: ...@overloaddef div(self, other: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef div(self, other: Union[builtins.float, builtins.int], *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef div_(self, other: 'Tensor') -> 'Tensor': ...@overloaddef div_(self, other: Union[builtins.float, builtins.int]) -> 'Tensor': ...def dot(self, tensor: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...def double(self) -> 'Tensor': ...def eig(self, eigenvectors: bool=False, *, out: Optional['Tensor']=None) -> Tuple['Tensor', 'Tensor']: ...def element_size(self) -> builtins.int: ...@overloaddef eq(self, other: Union[builtins.float, builtins.int], *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef eq(self, other: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef eq_(self, other: Union[builtins.float, builtins.int]) -> 'Tensor': ...@overloaddef eq_(self, other: 'Tensor') -> 'Tensor': ...def equal(self, other: 'Tensor') -> bool: ...def erf(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def erf_(self) -> 'Tensor': ...def erfc(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def erfc_(self) -> 'Tensor': ...def erfinv(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def erfinv_(self) -> 'Tensor': ...def exp(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def exp_(self) -> 'Tensor': ...@overloaddef expand(self, size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], *, implicit: bool=False) -> 'Tensor': ...@overloaddef expand(self, *size: builtins.int, implicit: bool=False) -> 'Tensor': ...def expand_as(self, other: 'Tensor') -> 'Tensor': ...def expm1(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def expm1_(self) -> 'Tensor': ...def exponential_(self, lambd: builtins.float=1, *, generator: Generator=None) -> 'Tensor': ...def fft(self, signal_ndim: builtins.int, normalized: bool=False) -> 'Tensor': ...@overloaddef fill_(self, value: Union[builtins.float, builtins.int]) -> 'Tensor': ...@overloaddef fill_(self, value: 'Tensor') -> 'Tensor': ...def flatten(self, start_dim: builtins.int=0, end_dim: builtins.int=-1) -> 'Tensor': ...@overloaddef flip(self, dims: Union[Tuple[builtins.int, ...], List[builtins.int], Size]) -> 'Tensor': ...@overloaddef flip(self, *dims: builtins.int) -> 'Tensor': ...def float(self) -> 'Tensor': ...def floor(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def floor_(self) -> 'Tensor': ...@overloaddef fmod(self, other: Union[builtins.float, builtins.int], *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef fmod(self, other: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef fmod_(self, other: Union[builtins.float, builtins.int]) -> 'Tensor': ...@overloaddef fmod_(self, other: 'Tensor') -> 'Tensor': ...def frac(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def frac_(self) -> 'Tensor': ...def gather(self, dim: builtins.int, index: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef ge(self, other: Union[builtins.float, builtins.int], *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef ge(self, other: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef ge_(self, other: Union[builtins.float, builtins.int]) -> 'Tensor': ...@overloaddef ge_(self, other: 'Tensor') -> 'Tensor': ...def gels(self, A: 'Tensor', *, out: Optional['Tensor']=None) -> Tuple['Tensor', 'Tensor']: ...def geometric_(self, p: builtins.float, *, generator: Generator=None) -> 'Tensor': ...def geqrf(self, *, out: Optional['Tensor']=None) -> Tuple['Tensor', 'Tensor']: ...def ger(self, vec2: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...def gesv(self, A: 'Tensor', *, out: Optional['Tensor']=None) -> Tuple['Tensor', 'Tensor']: ...def get_device(self) -> builtins.int: ...@overloaddef gt(self, other: Union[builtins.float, builtins.int], *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef gt(self, other: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef gt_(self, other: Union[builtins.float, builtins.int]) -> 'Tensor': ...@overloaddef gt_(self, other: 'Tensor') -> 'Tensor': ...def half(self) -> 'Tensor': ...def hardshrink(self, lambd: Union[builtins.float, builtins.int]=0.5) -> 'Tensor': ...def histc(self, bins: builtins.int=100, min: Union[builtins.float, builtins.int]=0, max: Union[builtins.float, builtins.int]=0, *, out: Optional['Tensor']=None) -> 'Tensor': ...def ifft(self, signal_ndim: builtins.int, normalized: bool=False) -> 'Tensor': ...def index_add(self, dim, index, tensor): ...def index_add_(self, dim: builtins.int, index: 'Tensor', source: 'Tensor') -> 'Tensor': ...def index_copy(self, dim, index, tensor): ...def index_copy_(self, dim: builtins.int, index: 'Tensor', source: 'Tensor') -> 'Tensor': ...def index_fill(self, dim, index, value): ...@overloaddef index_fill_(self, dim: builtins.int, index: 'Tensor', value: Union[builtins.float, builtins.int]) -> 'Tensor': ...@overloaddef index_fill_(self, dim: builtins.int, index: 'Tensor', value: 'Tensor') -> 'Tensor': ...def index_put_(self, indices: Union[Tuple['Tensor', ...],List['Tensor']], values: 'Tensor') -> 'Tensor': ...def index_select(self, dim: builtins.int, index: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...def int(self) -> 'Tensor': ...def inverse(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def irfft(self, signal_ndim: builtins.int, normalized: bool=False, onesided: bool=True, signal_sizes: Union[Tuple[builtins.int, ...], List[builtins.int], Size]=()) -> 'Tensor': ...def is_contiguous(self) -> bool: ...def is_pinned(self): ...def is_set_to(self, tensor: 'Tensor') -> bool: ...def is_shared(self): ...def item(self) -> Union[builtins.float, builtins.int]: ...def kthvalue(self, k: builtins.int, dim: builtins.int=-1, keepdim: bool=False, *, out: Optional['Tensor']=None) -> Tuple['Tensor', 'Tensor']: ...@overloaddef le(self, other: Union[builtins.float, builtins.int], *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef le(self, other: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef le_(self, other: Union[builtins.float, builtins.int]) -> 'Tensor': ...@overloaddef le_(self, other: 'Tensor') -> 'Tensor': ...def lerp(self, end: 'Tensor', weight: Union[builtins.float, builtins.int], *, out: Optional['Tensor']=None) -> 'Tensor': ...def lerp_(self, end: 'Tensor', weight: Union[builtins.float, builtins.int]) -> 'Tensor': ...def log(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def log10(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def log10_(self) -> 'Tensor': ...def log1p(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def log1p_(self) -> 'Tensor': ...def log2(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def log2_(self) -> 'Tensor': ...def log_(self) -> 'Tensor': ...def log_normal_(self, mean: builtins.float=1, std: builtins.float=2, *, generator: Generator=None) -> 'Tensor': ...def logdet(self) -> 'Tensor': ...def logsumexp(self, dim: builtins.int, keepdim: bool=False, *, out: Optional['Tensor']=None) -> 'Tensor': ...def long(self) -> 'Tensor': ...@overloaddef lt(self, other: Union[builtins.float, builtins.int], *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef lt(self, other: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef lt_(self, other: Union[builtins.float, builtins.int]) -> 'Tensor': ...@overloaddef lt_(self, other: 'Tensor') -> 'Tensor': ...def map_(tensor: 'Tensor', callable: Callable) -> 'Tensor': ...def masked_fill(self, mask, value): ...@overloaddef masked_fill_(self, mask: 'Tensor', value: Union[builtins.float, builtins.int]) -> 'Tensor': ...@overloaddef masked_fill_(self, mask: 'Tensor', value: 'Tensor') -> 'Tensor': ...def masked_scatter(self, mask, tensor): ...def masked_scatter_(self, mask: 'Tensor', source: 'Tensor') -> 'Tensor': ...def masked_select(self, mask: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...def matmul(self, other: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...def matrix_power(self, n: builtins.int) -> 'Tensor': ...@overloaddef max(self, other: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef max(self, *, out: Optional['Tensor']=None) -> Union[builtins.float, builtins.int]: ...@overloaddef max(self, dim: builtins.int, keepdim: bool=False, *, out: Optional['Tensor']=None) -> Tuple['Tensor', 'Tensor']: ...@overloaddef mean(self, *, dtype: _dtype, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef mean(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef mean(self, dim: builtins.int, keepdim: bool, *, dtype: _dtype, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef mean(self, dim: builtins.int, keepdim: bool=False, *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef mean(self, dim: builtins.int, *, dtype: _dtype, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef median(self, *, out: Optional['Tensor']=None) -> Union[builtins.float, builtins.int]: ...@overloaddef median(self, dim: builtins.int, keepdim: bool=False, *, out: Optional['Tensor']=None) -> Tuple['Tensor', 'Tensor']: ...@overloaddef min(self, other: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef min(self, *, out: Optional['Tensor']=None) -> Union[builtins.float, builtins.int]: ...@overloaddef min(self, dim: builtins.int, keepdim: bool=False, *, out: Optional['Tensor']=None) -> Tuple['Tensor', 'Tensor']: ...def mm(self, mat2: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...def mode(self, dim: builtins.int=-1, keepdim: bool=False, *, out: Optional['Tensor']=None) -> Tuple['Tensor', 'Tensor']: ...@overloaddef mul(self, other: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef mul(self, other: Union[builtins.float, builtins.int], *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef mul_(self, other: 'Tensor') -> 'Tensor': ...@overloaddef mul_(self, other: Union[builtins.float, builtins.int]) -> 'Tensor': ...def multinomial(self, num_samples: builtins.int, replacement: bool=False, *, generator: Generator=None, out: Optional['Tensor']=None) -> 'Tensor': ...def mv(self, vec: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...def mvlgamma(self, p: builtins.int) -> 'Tensor': ...def mvlgamma_(self, p: builtins.int) -> 'Tensor': ...def narrow(self, dim: builtins.int, start: builtins.int, length: builtins.int) -> 'Tensor': ...def narrow_copy(self, dim: builtins.int, start: builtins.int, length: builtins.int) -> 'Tensor': ...def ndimension(self) -> builtins.int: ...@overloaddef ne(self, other: Union[builtins.float, builtins.int], *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef ne(self, other: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef ne_(self, other: Union[builtins.float, builtins.int]) -> 'Tensor': ...@overloaddef ne_(self, other: 'Tensor') -> 'Tensor': ...def neg(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def neg_(self) -> 'Tensor': ...def nelement(self) -> builtins.int: ...def new_empty(self, size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], dtype: Optional[_dtype]=None, device: Union[device, str, None]=None, requires_grad: bool=False) -> 'Tensor': ...def new_full(self, size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], value: Union[builtins.float, builtins.int], dtype: Optional[_dtype]=None, device: Union[device, str, None]=None, requires_grad: bool=False) -> 'Tensor': ...def new_ones(self, size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], dtype: Optional[_dtype]=None, device: Union[device, str, None]=None, requires_grad: bool=False) -> 'Tensor': ...def new_tensor(self, data: Any, dtype: Optional[_dtype]=None, device: Union[device, str, None]=None, requires_grad: bool=False) -> 'Tensor': ...def new_zeros(self, size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], dtype: Optional[_dtype]=None, device: Union[device, str, None]=None, requires_grad: bool=False) -> 'Tensor': ...def nonzero(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def norm(self, p='fro', dim=None, keepdim=False): ...def normal_(self, mean: builtins.float=0, std: builtins.float=1, *, generator: Generator=None) -> 'Tensor': ...def numel(self) -> builtins.int: ...def numpy(self) -> Any: ...def orgqr(self, input2: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...def ormqr(self, input2: 'Tensor', input3: 'Tensor', left: bool=True, transpose: bool=False, *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef permute(self, dims: Union[Tuple[builtins.int, ...], List[builtins.int], Size]) -> 'Tensor': ...@overloaddef permute(self, *dims: builtins.int) -> 'Tensor': ...def pinverse(self, rcond: builtins.float=1e-15) -> 'Tensor': ...def potrf(self, upper: bool=True, *, out: Optional['Tensor']=None) -> 'Tensor': ...def potri(self, upper: bool=True, *, out: Optional['Tensor']=None) -> 'Tensor': ...def potrs(self, input2: 'Tensor', upper: bool=True, *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef pow(self, exponent: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef pow(self, exponent: Union[builtins.float, builtins.int], *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef pow_(self, exponent: Union[builtins.float, builtins.int]) -> 'Tensor': ...@overloaddef pow_(self, exponent: 'Tensor') -> 'Tensor': ...@overloaddef prod(self, *, dtype: _dtype, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef prod(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef prod(self, dim: builtins.int, keepdim: bool, *, dtype: _dtype, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef prod(self, dim: builtins.int, keepdim: bool=False, *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef prod(self, dim: builtins.int, *, dtype: _dtype, out: Optional['Tensor']=None) -> 'Tensor': ...def pstrf(self, upper: bool=True, tol: Union[builtins.float, builtins.int]=-1, *, out: Optional['Tensor']=None) -> Tuple['Tensor', 'Tensor']: ...def put_(self, index: 'Tensor', source: 'Tensor', accumulate: bool=False) -> 'Tensor': ...def qr(self, *, out: Optional['Tensor']=None) -> Tuple['Tensor', 'Tensor']: ...@overloaddef random_(self, from_: builtins.int, to: builtins.int, *, generator: Generator=None) -> 'Tensor': ...@overloaddef random_(self, to: builtins.int, *, generator: Generator=None) -> 'Tensor': ...@overloaddef random_(self, *, generator: Generator=None) -> 'Tensor': ...def reciprocal(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def reciprocal_(self) -> 'Tensor': ...def register_hook(self, hook): ...@overloaddef remainder(self, other: Union[builtins.float, builtins.int], *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef remainder(self, other: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef remainder_(self, other: Union[builtins.float, builtins.int]) -> 'Tensor': ...@overloaddef remainder_(self, other: 'Tensor') -> 'Tensor': ...def renorm(self, p: Union[builtins.float, builtins.int], dim: builtins.int, maxnorm: Union[builtins.float, builtins.int], *, out: Optional['Tensor']=None) -> 'Tensor': ...def renorm_(self, p: Union[builtins.float, builtins.int], dim: builtins.int, maxnorm: Union[builtins.float, builtins.int]) -> 'Tensor': ...@overloaddef repeat(self, repeats: Union[Tuple[builtins.int, ...], List[builtins.int], Size]) -> 'Tensor': ...@overloaddef repeat(self, *repeats: builtins.int) -> 'Tensor': ...def requires_grad_(self, mode: bool=True) -> 'Tensor': ...@overloaddef reshape(self, shape: Union[Tuple[builtins.int, ...], List[builtins.int], Size]) -> 'Tensor': ...@overloaddef reshape(self, *shape: builtins.int) -> 'Tensor': ...def reshape_as(self, other: 'Tensor') -> 'Tensor': ...@overloaddef resize_(self, size: Union[Tuple[builtins.int, ...], List[builtins.int], Size]) -> 'Tensor': ...@overloaddef resize_(self, *size: builtins.int) -> 'Tensor': ...def resize_as_(self, the_template: 'Tensor') -> 'Tensor': ...def retain_grad(self): ...def rfft(self, signal_ndim: builtins.int, normalized: bool=False, onesided: bool=True) -> 'Tensor': ...def rot90(self, k: builtins.int=1, dims: Union[Tuple[builtins.int, ...], List[builtins.int], Size]=(0,1)) -> 'Tensor': ...def round(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def round_(self) -> 'Tensor': ...def rsqrt(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def rsqrt_(self) -> 'Tensor': ...def scatter(self, dim, index, source): ...@overloaddef scatter_(self, dim: builtins.int, index: 'Tensor', src: 'Tensor') -> 'Tensor': ...@overloaddef scatter_(self, dim: builtins.int, index: 'Tensor', value: Union[builtins.float, builtins.int]) -> 'Tensor': ...def scatter_add(self, dim, index, source): ...def scatter_add_(self, dim: builtins.int, index: 'Tensor', src: 'Tensor') -> 'Tensor': ...def select(self, dim: builtins.int, index: builtins.int) -> 'Tensor': ...@overloaddef set_(self, source: Storage) -> 'Tensor': ...@overloaddef set_(self, source: Storage, storage_offset: builtins.int, size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], stride: Union[Tuple[builtins.int, ...], List[builtins.int], Size]=()) -> 'Tensor': ...@overloaddef set_(self, source: 'Tensor') -> 'Tensor': ...@overloaddef set_(self) -> 'Tensor': ...def share_memory_(self): ...def short(self) -> 'Tensor': ...def sigmoid(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def sigmoid_(self) -> 'Tensor': ...def sign(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def sign_(self) -> 'Tensor': ...def sin(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def sin_(self) -> 'Tensor': ...def sinh(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def sinh_(self) -> 'Tensor': ...@overloaddef size(self) -> Size: ...@overloaddef size(self, dim: builtins.int) -> builtins.int: ...def slogdet(self) -> Tuple['Tensor', 'Tensor']: ...def sort(self, dim: builtins.int=-1, descending: bool=False, *, out: Optional['Tensor']=None) -> Tuple['Tensor', 'Tensor']: ...def split(self, split_size, dim=0): ...def sqrt(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def sqrt_(self) -> 'Tensor': ...@overloaddef squeeze(self) -> 'Tensor': ...@overloaddef squeeze(self, dim: builtins.int) -> 'Tensor': ...@overloaddef squeeze_(self) -> 'Tensor': ...@overloaddef squeeze_(self, dim: builtins.int) -> 'Tensor': ...@overloaddef std(self, unbiased: bool=True, *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef std(self, dim: builtins.int, unbiased: bool=True, keepdim: bool=False, *, out: Optional['Tensor']=None) -> 'Tensor': ...def stft(self, n_fft, hop_length=None, win_length=None, window=None, center=True, pad_mode='reflect', normalized=False, onesided=True): ...def storage(self) -> Storage: ...def storage_offset(self) -> builtins.int: ...@overloaddef stride(self) -> Tuple[builtins.int]: ...@overloaddef stride(self, dim: builtins.int) -> builtins.int: ...@overloaddef sub(self, other: 'Tensor', *, alpha: Union[builtins.float, builtins.int]=1, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef sub(self, other: Union[builtins.float, builtins.int], alpha: Union[builtins.float, builtins.int]=1, *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef sub_(self, other: 'Tensor', *, alpha: Union[builtins.float, builtins.int]=1) -> 'Tensor': ...@overloaddef sub_(self, other: Union[builtins.float, builtins.int], alpha: Union[builtins.float, builtins.int]=1) -> 'Tensor': ...@overloaddef sum(self, *, dtype: _dtype, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef sum(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef sum(self, dim: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size], keepdim: bool, *, dtype: _dtype, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef sum(self, dim: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size], keepdim: bool=False, *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef sum(self, dim: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size], *, dtype: _dtype, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef sum(self, *dim: builtins.int, dtype: _dtype, out: Optional['Tensor']=None) -> 'Tensor': ...def svd(self, some: bool=True, compute_uv: bool=True, *, out: Optional['Tensor']=None) -> Tuple['Tensor', 'Tensor', 'Tensor']: ...def symeig(self, eigenvectors: bool=False, upper: bool=True, *, out: Optional['Tensor']=None) -> Tuple['Tensor', 'Tensor']: ...def t(self) -> 'Tensor': ...def t_(self) -> 'Tensor': ...def take(self, index: 'Tensor', *, out: Optional['Tensor']=None) -> 'Tensor': ...def tan_(self) -> 'Tensor': ...def tanh(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def tanh_(self) -> 'Tensor': ...@overloaddef to(self, device: Union[device, str, None], dtype: _dtype, non_blocking: bool=False, copy: bool=False) -> 'Tensor': ...@overloaddef to(self, dtype: _dtype, non_blocking: bool=False, copy: bool=False) -> 'Tensor': ...@overloaddef to(self, device: Union[device, str, None], non_blocking: bool=False, copy: bool=False) -> 'Tensor': ...@overloaddef to(self, other: 'Tensor', non_blocking: bool=False, copy: bool=False) -> 'Tensor': ...def tolist(self) -> List: ...def topk(self, k: builtins.int, dim: builtins.int=-1, largest: bool=True, sorted: bool=True, *, out: Optional['Tensor']=None) -> Tuple['Tensor', 'Tensor']: ...def trace(self) -> Union[builtins.float, builtins.int]: ...def transpose(self, dim0: builtins.int, dim1: builtins.int) -> 'Tensor': ...def transpose_(self, dim0: builtins.int, dim1: builtins.int) -> 'Tensor': ...def tril(self, diagonal: builtins.int=0, *, out: Optional['Tensor']=None) -> 'Tensor': ...def tril_(self, diagonal: builtins.int=0) -> 'Tensor': ...def triu(self, diagonal: builtins.int=0, *, out: Optional['Tensor']=None) -> 'Tensor': ...def triu_(self, diagonal: builtins.int=0) -> 'Tensor': ...def trtrs(self, A: 'Tensor', upper: bool=True, transpose: bool=False, unitriangular: bool=False, *, out: Optional['Tensor']=None) -> Tuple['Tensor', 'Tensor']: ...def trunc(self, *, out: Optional['Tensor']=None) -> 'Tensor': ...def trunc_(self) -> 'Tensor': ...def type(self, dtype: Union[None, str, _dtype]=None, non_blocking: bool=False) -> Union[str, 'Tensor']: ...def type_as(self, other: 'Tensor') -> 'Tensor': ...def unbind(self, dim: builtins.int=0) -> Union[Tuple['Tensor', ...],List['Tensor']]: ...def unfold(self, dimension: builtins.int, size: builtins.int, step: builtins.int) -> 'Tensor': ...def uniform_(self, from_: builtins.float=0, to: builtins.float=1, *, generator: Generator=None) -> 'Tensor': ...def unique(self, sorted=False, return_inverse=False, dim=None): ...def unsqueeze(self, dim: builtins.int) -> 'Tensor': ...def unsqueeze_(self, dim: builtins.int) -> 'Tensor': ...@overloaddef var(self, unbiased: bool=True, *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef var(self, dim: builtins.int, unbiased: bool=True, keepdim: bool=False, *, out: Optional['Tensor']=None) -> 'Tensor': ...@overloaddef view(self, size: Union[Tuple[builtins.int, ...], List[builtins.int], Size]) -> 'Tensor': ...@overloaddef view(self, *size: builtins.int) -> 'Tensor': ...def view_as(self, other: 'Tensor') -> 'Tensor': ...def where(self, condition: 'Tensor', other: 'Tensor') -> 'Tensor': ...def zero_(self) -> 'Tensor': ...def abs(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def acos(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def adaptive_avg_pool1d(self: Tensor, output_size: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]) -> Tensor: ...@overloaddef add(self: Tensor, other: Tensor, *, alpha: Union[builtins.float, builtins.int]=1, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef add(self: Tensor, other: Union[builtins.float, builtins.int], alpha: Union[builtins.float, builtins.int]=1, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef add(self: Tensor, alpha: Union[builtins.float, builtins.int], other: Tensor) -> Tensor: ...@overloaddef add(self: Tensor, alpha: Union[builtins.float, builtins.int], other: Tensor, *, out: Tensor) -> Tensor: ...@overloaddef addbmm(self: Tensor, batch1: Tensor, batch2: Tensor, *, beta: Union[builtins.float, builtins.int]=1, alpha: Union[builtins.float, builtins.int]=1, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef addbmm(beta: Union[builtins.float, builtins.int], self: Tensor, alpha: Union[builtins.float, builtins.int], batch1: Tensor, batch2: Tensor) -> Tensor: ...@overloaddef addbmm(beta: Union[builtins.float, builtins.int], self: Tensor, alpha: Union[builtins.float, builtins.int], batch1: Tensor, batch2: Tensor, *, out: Tensor) -> Tensor: ...@overloaddef addbmm(beta: Union[builtins.float, builtins.int], self: Tensor, batch1: Tensor, batch2: Tensor) -> Tensor: ...@overloaddef addbmm(beta: Union[builtins.float, builtins.int], self: Tensor, batch1: Tensor, batch2: Tensor, *, out: Tensor) -> Tensor: ...@overloaddef addcdiv(self: Tensor, tensor1: Tensor, tensor2: Tensor, *, value: Union[builtins.float, builtins.int]=1, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef addcdiv(self: Tensor, value: Union[builtins.float, builtins.int], tensor1: Tensor, tensor2: Tensor) -> Tensor: ...@overloaddef addcdiv(self: Tensor, value: Union[builtins.float, builtins.int], tensor1: Tensor, tensor2: Tensor, *, out: Tensor) -> Tensor: ...@overloaddef addcmul(self: Tensor, tensor1: Tensor, tensor2: Tensor, *, value: Union[builtins.float, builtins.int]=1, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef addcmul(self: Tensor, value: Union[builtins.float, builtins.int], tensor1: Tensor, tensor2: Tensor) -> Tensor: ...@overloaddef addcmul(self: Tensor, value: Union[builtins.float, builtins.int], tensor1: Tensor, tensor2: Tensor, *, out: Tensor) -> Tensor: ...@overloaddef addmm(self: Tensor, mat1: Tensor, mat2: Tensor, *, beta: Union[builtins.float, builtins.int]=1, alpha: Union[builtins.float, builtins.int]=1, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef addmm(beta: Union[builtins.float, builtins.int], self: Tensor, alpha: Union[builtins.float, builtins.int], mat1: Tensor, mat2: Tensor) -> Tensor: ...@overloaddef addmm(beta: Union[builtins.float, builtins.int], self: Tensor, alpha: Union[builtins.float, builtins.int], mat1: Tensor, mat2: Tensor, *, out: Tensor) -> Tensor: ...@overloaddef addmm(beta: Union[builtins.float, builtins.int], self: Tensor, mat1: Tensor, mat2: Tensor) -> Tensor: ...@overloaddef addmm(beta: Union[builtins.float, builtins.int], self: Tensor, mat1: Tensor, mat2: Tensor, *, out: Tensor) -> Tensor: ...@overloaddef addmv(self: Tensor, mat: Tensor, vec: Tensor, *, beta: Union[builtins.float, builtins.int]=1, alpha: Union[builtins.float, builtins.int]=1, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef addmv(beta: Union[builtins.float, builtins.int], self: Tensor, alpha: Union[builtins.float, builtins.int], mat: Tensor, vec: Tensor) -> Tensor: ...@overloaddef addmv(beta: Union[builtins.float, builtins.int], self: Tensor, alpha: Union[builtins.float, builtins.int], mat: Tensor, vec: Tensor, *, out: Tensor) -> Tensor: ...@overloaddef addmv(beta: Union[builtins.float, builtins.int], self: Tensor, mat: Tensor, vec: Tensor) -> Tensor: ...@overloaddef addmv(beta: Union[builtins.float, builtins.int], self: Tensor, mat: Tensor, vec: Tensor, *, out: Tensor) -> Tensor: ...@overloaddef addr(self: Tensor, vec1: Tensor, vec2: Tensor, *, beta: Union[builtins.float, builtins.int]=1, alpha: Union[builtins.float, builtins.int]=1, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef addr(beta: Union[builtins.float, builtins.int], self: Tensor, alpha: Union[builtins.float, builtins.int], vec1: Tensor, vec2: Tensor) -> Tensor: ...@overloaddef addr(beta: Union[builtins.float, builtins.int], self: Tensor, alpha: Union[builtins.float, builtins.int], vec1: Tensor, vec2: Tensor, *, out: Tensor) -> Tensor: ...@overloaddef addr(beta: Union[builtins.float, builtins.int], self: Tensor, vec1: Tensor, vec2: Tensor) -> Tensor: ...@overloaddef addr(beta: Union[builtins.float, builtins.int], self: Tensor, vec1: Tensor, vec2: Tensor, *, out: Tensor) -> Tensor: ...def allclose(self: Tensor, other: Tensor, rtol: builtins.float=1e-05, atol: builtins.float=1e-08, equal_nan: bool=False) -> bool: ...@overloaddef arange(start: Union[builtins.float, builtins.int], end: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef arange(start: Union[builtins.float, builtins.int], end: Union[builtins.float, builtins.int], step: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef arange(end: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...def argmax(input, dim=None, keepdim=False): ...def argmin(input, dim=None, keepdim=False): ...def argsort(input, dim=None, descending=False): ...def as_tensor(data: Any, dtype: _dtype=None, device: Optional[device]=None) -> Tensor: ...def asin(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def atan(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def atan2(self: Tensor, other: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def avg_pool1d(self: Tensor, kernel_size: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size], stride: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=(), padding: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=0, ceil_mode: bool=False, count_include_pad: bool=True) -> Tensor: ...@overloaddef baddbmm(self: Tensor, batch1: Tensor, batch2: Tensor, *, beta: Union[builtins.float, builtins.int]=1, alpha: Union[builtins.float, builtins.int]=1, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef baddbmm(beta: Union[builtins.float, builtins.int], self: Tensor, alpha: Union[builtins.float, builtins.int], batch1: Tensor, batch2: Tensor) -> Tensor: ...@overloaddef baddbmm(beta: Union[builtins.float, builtins.int], self: Tensor, alpha: Union[builtins.float, builtins.int], batch1: Tensor, batch2: Tensor, *, out: Tensor) -> Tensor: ...@overloaddef baddbmm(beta: Union[builtins.float, builtins.int], self: Tensor, batch1: Tensor, batch2: Tensor) -> Tensor: ...@overloaddef baddbmm(beta: Union[builtins.float, builtins.int], self: Tensor, batch1: Tensor, batch2: Tensor, *, out: Tensor) -> Tensor: ...@overloaddef bartlett_window(window_length: builtins.int, *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef bartlett_window(window_length: builtins.int, periodic: bool, *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef bernoulli(self: Tensor, *, generator: Generator=None, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef bernoulli(self: Tensor, p: builtins.float, *, generator: Generator=None, out: Optional[Tensor]=None) -> Tensor: ...def bincount(self: Tensor, weights: Optional[Tensor]=None, minlength: builtins.int=0) -> Tensor: ...@overloaddef blackman_window(window_length: builtins.int, *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef blackman_window(window_length: builtins.int, periodic: bool, *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...def bmm(self: Tensor, mat2: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def broadcast_tensors(*tensors:Tensor) -> List[Tensor]: ...def btrifact(A:Tensor, info:Union[Tensor, None]=None, pivot:bool=True) -> Tuple[Tensor, Tensor]: ...def btrifact_with_info(self: Tensor, *, pivot: bool=True, out: Optional[Tensor]=None) -> Tuple[Tensor, Tensor, Tensor]: ...def btrisolve(self: Tensor, LU_data: Tensor, LU_pivots: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def btriunpack(LU_data:Tensor, LU_pivots:Tensor, unpack_data:bool=True, unpack_pivots:bool=True) -> Tuple[Tensor, Tensor, Tensor]: ...def cat(tensors: Union[Tuple[Tensor, ...],List[Tensor]], dim: builtins.int=0, *, out: Optional[Tensor]=None) -> Tensor: ...def ceil(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def celu_(self: Tensor, alpha: Union[builtins.float, builtins.int]=1.0) -> Tensor: ...def chain_matmul(*matrices): ...def chunk(self: Tensor, chunks: builtins.int, dim: builtins.int=0) -> Union[Tuple[Tensor, ...],List[Tensor]]: ...def clamp(self, min: builtins.float=-math.inf, max: builtins.float=math.inf, *, out: Optional[Tensor]=None) -> Tensor: ...def compiled_with_cxx11_abi(): ...def conv1d(input: Tensor, weight: Tensor, bias: Tensor=None, stride: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=1, padding: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=0, dilation: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=1, groups: builtins.int=1) -> Tensor: ...def conv2d(input: Tensor, weight: Tensor, bias: Tensor=None, stride: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=1, padding: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=0, dilation: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=1, groups: builtins.int=1) -> Tensor: ...def conv3d(input: Tensor, weight: Tensor, bias: Tensor=None, stride: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=1, padding: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=0, dilation: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=1, groups: builtins.int=1) -> Tensor: ...def conv_tbc(self: Tensor, weight: Tensor, bias: Tensor, pad: builtins.int=0) -> Tensor: ...def conv_transpose1d(input: Tensor, weight: Tensor, bias: Tensor=None, stride: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=1, padding: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=0, output_padding: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=0, groups: builtins.int=1, dilation: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=1) -> Tensor: ...def conv_transpose2d(input: Tensor, weight: Tensor, bias: Tensor=None, stride: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=1, padding: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=0, output_padding: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=0, groups: builtins.int=1, dilation: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=1) -> Tensor: ...def conv_transpose3d(input: Tensor, weight: Tensor, bias: Tensor=None, stride: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=1, padding: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=0, output_padding: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=0, groups: builtins.int=1, dilation: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size]=1) -> Tensor: ...def cos(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def cosh(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def cross(self: Tensor, other: Tensor, dim: builtins.int=-1, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef cumprod(self: Tensor, dim: builtins.int, *, dtype: _dtype, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef cumprod(self: Tensor, dim: builtins.int, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef cumsum(self: Tensor, dim: builtins.int, *, dtype: _dtype, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef cumsum(self: Tensor, dim: builtins.int, *, out: Optional[Tensor]=None) -> Tensor: ...def det(self: Tensor) -> Tensor: ...def diag(self: Tensor, diagonal: builtins.int=0, *, out: Optional[Tensor]=None) -> Tensor: ...def diagflat(self: Tensor, offset: builtins.int=0) -> Tensor: ...def diagonal(self: Tensor, offset: builtins.int=0, dim1: builtins.int=0, dim2: builtins.int=1) -> Tensor: ...def digamma(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def dist(self: Tensor, other: Tensor, p: Union[builtins.float, builtins.int]=2) -> Union[builtins.float, builtins.int]: ...@overloaddef div(self: Tensor, other: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef div(self: Tensor, other: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None) -> Tensor: ...def dot(self: Tensor, tensor: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def eig(self: Tensor, eigenvectors: bool=False, *, out: Optional[Tensor]=None) -> Tuple[Tensor, Tensor]: ...def einsum(equation:str, *operands:Tensor) -> Tensor: ...@overloaddef empty(size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef empty(*size: builtins.int, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef empty_like(self: Tensor) -> Tensor: ...@overloaddef empty_like(self: Tensor, *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef eq(self: Tensor, other: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef eq(self: Tensor, other: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def equal(self: Tensor, other: Tensor) -> bool: ...def erf(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def erfc(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def erfinv(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def exp(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def expm1(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef eye(n: builtins.int, *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef eye(n: builtins.int, m: builtins.int, *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...def fft(self: Tensor, signal_ndim: builtins.int, normalized: bool=False) -> Tensor: ...def flatten(self: Tensor, start_dim: builtins.int=0, end_dim: builtins.int=-1) -> Tensor: ...def flip(self: Tensor, dims: Union[Tuple[builtins.int, ...], List[builtins.int], Size]) -> Tensor: ...def floor(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef fmod(self: Tensor, other: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef fmod(self: Tensor, other: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def frac(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def from_numpy(ndarray) -> Tensor: ...def full(size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], fill_value: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef full_like(self: Tensor, fill_value: Union[builtins.float, builtins.int]) -> Tensor: ...@overloaddef full_like(self: Tensor, fill_value: Union[builtins.float, builtins.int], *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...def gather(self: Tensor, dim: builtins.int, index: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef ge(self: Tensor, other: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef ge(self: Tensor, other: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def gels(self: Tensor, A: Tensor, *, out: Optional[Tensor]=None) -> Tuple[Tensor, Tensor]: ...def geqrf(self: Tensor, *, out: Optional[Tensor]=None) -> Tuple[Tensor, Tensor]: ...def ger(self: Tensor, vec2: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def gesv(self: Tensor, A: Tensor, *, out: Optional[Tensor]=None) -> Tuple[Tensor, Tensor]: ...def get_default_dtype() -> _dtype: ...def get_num_threads() -> builtins.int: ...def get_rng_state(): ...@overloaddef gt(self: Tensor, other: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef gt(self: Tensor, other: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef hamming_window(window_length: builtins.int, *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef hamming_window(window_length: builtins.int, periodic: bool, *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef hamming_window(window_length: builtins.int, periodic: bool, alpha: builtins.float, *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef hamming_window(window_length: builtins.int, periodic: bool, alpha: builtins.float, beta: builtins.float, *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef hann_window(window_length: builtins.int, *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef hann_window(window_length: builtins.int, periodic: bool, *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...def histc(self: Tensor, bins: builtins.int=100, min: Union[builtins.float, builtins.int]=0, max: Union[builtins.float, builtins.int]=0, *, out: Optional[Tensor]=None) -> Tensor: ...def ifft(self: Tensor, signal_ndim: builtins.int, normalized: bool=False) -> Tensor: ...def index_select(self: Tensor, dim: builtins.int, index: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def initial_seed(): ...def inverse(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def irfft(self: Tensor, signal_ndim: builtins.int, normalized: bool=False, onesided: bool=True, signal_sizes: Union[Tuple[builtins.int, ...], List[builtins.int], Size]=()) -> Tensor: ...def is_storage(obj): ...def is_tensor(obj): ...def isfinite(tensor:Tensor) -> Tensor: ...def isinf(tensor:Tensor) -> Tensor: ...def isnan(tensor:Tensor) -> Tensor: ...def kthvalue(self: Tensor, k: builtins.int, dim: builtins.int=-1, keepdim: bool=False, *, out: Optional[Tensor]=None) -> Tuple[Tensor, Tensor]: ...@overloaddef le(self: Tensor, other: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef le(self: Tensor, other: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def lerp(self: Tensor, end: Tensor, weight: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef linspace(start: Union[builtins.float, builtins.int], end: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef linspace(start: Union[builtins.float, builtins.int], end: Union[builtins.float, builtins.int], steps: builtins.int, *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...def load(f, map_location=None, pickle_module=pickle): ...def log(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def log10(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def log1p(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def log2(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def logdet(self: Tensor) -> Tensor: ...@overloaddef logspace(start: Union[builtins.float, builtins.int], end: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef logspace(start: Union[builtins.float, builtins.int], end: Union[builtins.float, builtins.int], steps: builtins.int, *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...def logsumexp(self: Tensor, dim: builtins.int, keepdim: bool=False, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef lt(self: Tensor, other: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef lt(self: Tensor, other: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def manual_seed(seed): ...def masked_select(self: Tensor, mask: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def matmul(self: Tensor, other: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def matrix_power(self: Tensor, n: builtins.int) -> Tensor: ...@overloaddef matrix_rank(self: Tensor, tol: builtins.float, symmetric: bool=False) -> Tensor: ...@overloaddef matrix_rank(self: Tensor, symmetric: bool=False) -> Tensor: ...@overloaddef max(self: Tensor, other: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef max(self: Tensor, *, out: Optional[Tensor]=None) -> Union[builtins.float, builtins.int]: ...@overloaddef max(self: Tensor, dim: builtins.int, keepdim: bool=False, *, out: Optional[Tensor]=None) -> Tuple[Tensor, Tensor]: ...@overloaddef mean(self: Tensor, *, dtype: _dtype, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef mean(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef mean(self: Tensor, dim: builtins.int, keepdim: bool, *, dtype: _dtype, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef mean(self: Tensor, dim: builtins.int, keepdim: bool=False, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef mean(self: Tensor, dim: builtins.int, *, dtype: _dtype, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef median(self: Tensor, *, out: Optional[Tensor]=None) -> Union[builtins.float, builtins.int]: ...@overloaddef median(self: Tensor, dim: builtins.int, keepdim: bool=False, *, out: Optional[Tensor]=None) -> Tuple[Tensor, Tensor]: ...def meshgrid(*tensors, **kwargs): ...@overloaddef min(self: Tensor, other: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef min(self: Tensor, *, out: Optional[Tensor]=None) -> Union[builtins.float, builtins.int]: ...@overloaddef min(self: Tensor, dim: builtins.int, keepdim: bool=False, *, out: Optional[Tensor]=None) -> Tuple[Tensor, Tensor]: ...def mm(self: Tensor, mat2: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def mode(self: Tensor, dim: builtins.int=-1, keepdim: bool=False, *, out: Optional[Tensor]=None) -> Tuple[Tensor, Tensor]: ...@overloaddef mul(self: Tensor, other: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef mul(self: Tensor, other: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None) -> Tensor: ...def multinomial(self: Tensor, num_samples: builtins.int, replacement: bool=False, *, generator: Generator=None, out: Optional[Tensor]=None) -> Tensor: ...def mv(self: Tensor, vec: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def mvlgamma(self: Tensor, p: builtins.int) -> Tensor: ...def narrow(self: Tensor, dim: builtins.int, start: builtins.int, length: builtins.int) -> Tensor: ...@overloaddef ne(self: Tensor, other: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef ne(self: Tensor, other: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def neg(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def nonzero(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def norm(input, p='fro', dim=None, keepdim=False, out=None): ...@overloaddef normal(mean: Tensor, std: builtins.float=1, *, generator: Generator=None, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef normal(mean: builtins.float, std: Tensor, *, generator: Generator=None, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef normal(mean: Tensor, std: Tensor, *, generator: Generator=None, out: Optional[Tensor]=None) -> Tensor: ...def numel(self: Tensor) -> builtins.int: ...@overloaddef ones(size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef ones(*size: builtins.int, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef ones_like(self: Tensor) -> Tensor: ...@overloaddef ones_like(self: Tensor, *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...def orgqr(self: Tensor, input2: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def ormqr(self: Tensor, input2: Tensor, input3: Tensor, left: bool=True, transpose: bool=False, *, out: Optional[Tensor]=None) -> Tensor: ...def pdist(self: Tensor, p: builtins.float=2) -> Tensor: ...def pinverse(self: Tensor, rcond: builtins.float=1e-15) -> Tensor: ...def pixel_shuffle(self: Tensor, upscale_factor: builtins.int) -> Tensor: ...def potrf(self: Tensor, upper: bool=True, *, out: Optional[Tensor]=None) -> Tensor: ...def potri(self: Tensor, upper: bool=True, *, out: Optional[Tensor]=None) -> Tensor: ...def potrs(self: Tensor, input2: Tensor, upper: bool=True, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef pow(self: Tensor, exponent: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef pow(self: Union[builtins.float, builtins.int], exponent: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef pow(self: Tensor, exponent: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef prod(self: Tensor, *, dtype: _dtype, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef prod(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef prod(self: Tensor, dim: builtins.int, keepdim: bool, *, dtype: _dtype, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef prod(self: Tensor, dim: builtins.int, keepdim: bool=False, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef prod(self: Tensor, dim: builtins.int, *, dtype: _dtype, out: Optional[Tensor]=None) -> Tensor: ...def pstrf(self: Tensor, upper: bool=True, tol: Union[builtins.float, builtins.int]=-1, *, out: Optional[Tensor]=None) -> Tuple[Tensor, Tensor]: ...def qr(self: Tensor, *, out: Optional[Tensor]=None) -> Tuple[Tensor, Tensor]: ...@overloaddef rand(size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef rand(*size: builtins.int, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef rand(size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], *, generator: Generator, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef rand(*size: builtins.int, generator: Generator, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef rand_like(self: Tensor) -> Tensor: ...@overloaddef rand_like(self: Tensor, *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef randint(high: builtins.int, size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef randint(high: builtins.int, size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], *, generator: Generator, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef randint(low: builtins.int, high: builtins.int, size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef randint(low: builtins.int, high: builtins.int, size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], *, generator: Generator, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef randint_like(self: Tensor, high: builtins.int) -> Tensor: ...@overloaddef randint_like(self: Tensor, low: builtins.int, high: builtins.int) -> Tensor: ...@overloaddef randint_like(self: Tensor, high: builtins.int, *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef randint_like(self: Tensor, low: builtins.int, high: builtins.int, *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef randn(size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef randn(*size: builtins.int, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef randn(size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], *, generator: Generator, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef randn(*size: builtins.int, generator: Generator, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef randn_like(self: Tensor) -> Tensor: ...@overloaddef randn_like(self: Tensor, *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef randperm(n: builtins.int, *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef randperm(n: builtins.int, *, generator: Generator, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef range(start: Union[builtins.float, builtins.int], end: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef range(start: Union[builtins.float, builtins.int], end: Union[builtins.float, builtins.int], step: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...def reciprocal(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def relu_(self: Tensor) -> Tensor: ...@overloaddef remainder(self: Tensor, other: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef remainder(self: Tensor, other: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def renorm(self: Tensor, p: Union[builtins.float, builtins.int], dim: builtins.int, maxnorm: Union[builtins.float, builtins.int], *, out: Optional[Tensor]=None) -> Tensor: ...def reshape(self: Tensor, shape: Union[Tuple[builtins.int, ...], List[builtins.int], Size]) -> Tensor: ...def rfft(self: Tensor, signal_ndim: builtins.int, normalized: bool=False, onesided: bool=True) -> Tensor: ...def rot90(self: Tensor, k: builtins.int=1, dims: Union[Tuple[builtins.int, ...], List[builtins.int], Size]=(0,1)) -> Tensor: ...def round(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def rrelu_(self: Tensor, lower: Union[builtins.float, builtins.int]=0.125, upper: Union[builtins.float, builtins.int]=0.3333333333333333, training: bool=False, generator: Generator=None) -> Tensor: ...def rsqrt(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def save(obj, f, pickle_module=pickle, pickle_protocol=2): ...def selu_(self: Tensor) -> Tensor: ...def set_default_dtype(d): ...def set_default_tensor_type(t): ...def set_flush_denormal(mode: bool) -> bool: ...def set_num_threads(num: builtins.int) -> None: ...def set_printoptions(precision=None, threshold=None, edgeitems=None, linewidth=None, profile=None): ...def set_rng_state(new_state): ...def sigmoid(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def sign(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def sin(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def sinh(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def slogdet(self: Tensor) -> Tuple[Tensor, Tensor]: ...def sort(self: Tensor, dim: builtins.int=-1, descending: bool=False, *, out: Optional[Tensor]=None) -> Tuple[Tensor, Tensor]: ...@overloaddef sparse_coo_tensor(indices: Tensor, values: Tensor) -> Tensor: ...@overloaddef sparse_coo_tensor(indices: Tensor, values: Tensor, size: Union[Tuple[builtins.int, ...], List[builtins.int], Size]) -> Tensor: ...@overloaddef sparse_coo_tensor(size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef sparse_coo_tensor(*size: builtins.int, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef sparse_coo_tensor(indices: Tensor, values: Tensor, *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef sparse_coo_tensor(indices: Tensor, values: Tensor, size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...def split(tensor:Tensor, split_size_or_sections:Union[List[builtins.int], builtins.int], dim:builtins.int=0) -> List[Tensor]: ...def sqrt(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef squeeze(self: Tensor) -> Tensor: ...@overloaddef squeeze(self: Tensor, dim: builtins.int) -> Tensor: ...@overloaddef sspaddmm(beta: Union[builtins.float, builtins.int], self: Tensor, alpha: Union[builtins.float, builtins.int], mat1: Tensor, mat2: Tensor) -> Tensor: ...@overloaddef sspaddmm(beta: Union[builtins.float, builtins.int], self: Tensor, mat1: Tensor, mat2: Tensor) -> Tensor: ...def stack(tensors: Union[Tuple[Tensor, ...],List[Tensor]], dim: builtins.int=0, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef std(self: Tensor, unbiased: bool=True, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef std(self: Tensor, dim: builtins.int, unbiased: bool=True, keepdim: bool=False, *, out: Optional[Tensor]=None) -> Tensor: ...def stft(input, n_fft, hop_length=None, win_length=None, window=None, center=True, pad_mode='reflect', normalized=False, onesided=True): ...@overloaddef sub(self: Tensor, alpha: Union[builtins.float, builtins.int], other: Tensor) -> Tensor: ...@overloaddef sub(self: Tensor, alpha: Union[builtins.float, builtins.int], other: Tensor, *, out: Tensor) -> Tensor: ...@overloaddef sum(self: Tensor, *, dtype: _dtype, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef sum(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef sum(self: Tensor, dim: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size], keepdim: bool, *, dtype: _dtype, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef sum(self: Tensor, dim: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size], keepdim: bool=False, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef sum(self: Tensor, dim: Union[builtins.int, Tuple[builtins.int, ...], List[builtins.int], Size], *, dtype: _dtype, out: Optional[Tensor]=None) -> Tensor: ...def svd(self: Tensor, some: bool=True, compute_uv: bool=True, *, out: Optional[Tensor]=None) -> Tuple[Tensor, Tensor, Tensor]: ...def symeig(self: Tensor, eigenvectors: bool=False, upper: bool=True, *, out: Optional[Tensor]=None) -> Tuple[Tensor, Tensor]: ...def t(self: Tensor) -> Tensor: ...def take(self: Tensor, index: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def tan(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def tanh(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef tensor(data: Any, dtype: Optional[_dtype]=None, device: Union[device, str, None]=None, requires_grad: bool=False) -> Tensor: ...@overloaddef tensor(storage: Storage, storageOffset: builtins.int, size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], stride: Union[Tuple[builtins.int, ...], List[builtins.int], Size]=()) -> Tensor: ...@overloaddef tensor(size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], stride: Union[Tuple[builtins.int, ...], List[builtins.int], Size]) -> Tensor: ...def tensordot(a:Tensor, b:Tensor, dims=2) -> Tensor: ...def topk(self: Tensor, k: builtins.int, dim: builtins.int=-1, largest: bool=True, sorted: bool=True, *, out: Optional[Tensor]=None) -> Tuple[Tensor, Tensor]: ...def trace(self: Tensor) -> Union[builtins.float, builtins.int]: ...def transpose(self: Tensor, dim0: builtins.int, dim1: builtins.int) -> Tensor: ...def tril(self: Tensor, diagonal: builtins.int=0, *, out: Optional[Tensor]=None) -> Tensor: ...def triu(self: Tensor, diagonal: builtins.int=0, *, out: Optional[Tensor]=None) -> Tensor: ...def trtrs(self: Tensor, A: Tensor, upper: bool=True, transpose: bool=False, unitriangular: bool=False, *, out: Optional[Tensor]=None) -> Tuple[Tensor, Tensor]: ...def trunc(self: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...def unbind(self: Tensor, dim: builtins.int=0) -> Union[Tuple[Tensor, ...],List[Tensor]]: ...def unique(input, sorted=False, return_inverse=False, dim=None): ...def unsqueeze(self: Tensor, dim: builtins.int) -> Tensor: ...@overloaddef var(self: Tensor, unbiased: bool=True, *, out: Optional[Tensor]=None) -> Tensor: ...@overloaddef var(self: Tensor, dim: builtins.int, unbiased: bool=True, keepdim: bool=False, *, out: Optional[Tensor]=None) -> Tensor: ...def where(condition: Tensor, self: Tensor, other: Tensor) -> Tensor: ...@overloaddef zeros(size: Union[Tuple[builtins.int, ...], List[builtins.int], Size], *, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef zeros(*size: builtins.int, out: Optional[Tensor]=None, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...@overloaddef zeros_like(self: Tensor) -> Tensor: ...@overloaddef zeros_like(self: Tensor, *, dtype: _dtype=None, layout: layout=strided, device: Optional[device]=None, requires_grad:bool=False) -> Tensor: ...class DoubleStorage(Storage): ...class FloatStorage(Storage): ...class LongStorage(Storage): ...class IntStorage(Storage): ...class ShortStorage(Storage): ...class CharStorage(Storage): ...class ByteStorage(Storage): ...class DoubleTensor(Tensor): ...class FloatTensor(Tensor): ...class LongTensor(Tensor): ...class IntTensor(Tensor): ...class ShortTensor(Tensor): ...class CharTensor(Tensor): ...class ByteTensor(Tensor): ...complex128: dtype = ...complex32: dtype = ...complex64: dtype = ...double: dtype = ...float: dtype = ...float16: dtype = ...float32: dtype = ...float64: dtype = ...half: dtype = ...int: dtype = ...int16: dtype = ...int32: dtype = ...int64: dtype = ...int8: dtype = ...long: dtype = ...short: dtype = ...uint8: dtype = ...

若有收获,就点个赞吧
0 人点赞
