用到的模块。
import pandas as pdimport torchimport torch.utils.data as torch_dataimport torch.nn as nnimport d2lzh_pytorch as d2l
3.16.1 Kaggle比赛
比赛链接: https://www.kaggle.com/c/house-prices-advanced-regression-techniques
账号注册和提交结果都需要一点科学上网。
3.16.2 获取和读取数据集
点击图中 Download All 按钮获取数据集,或者附件链接。
Kaggle-house-prices-advanced.zip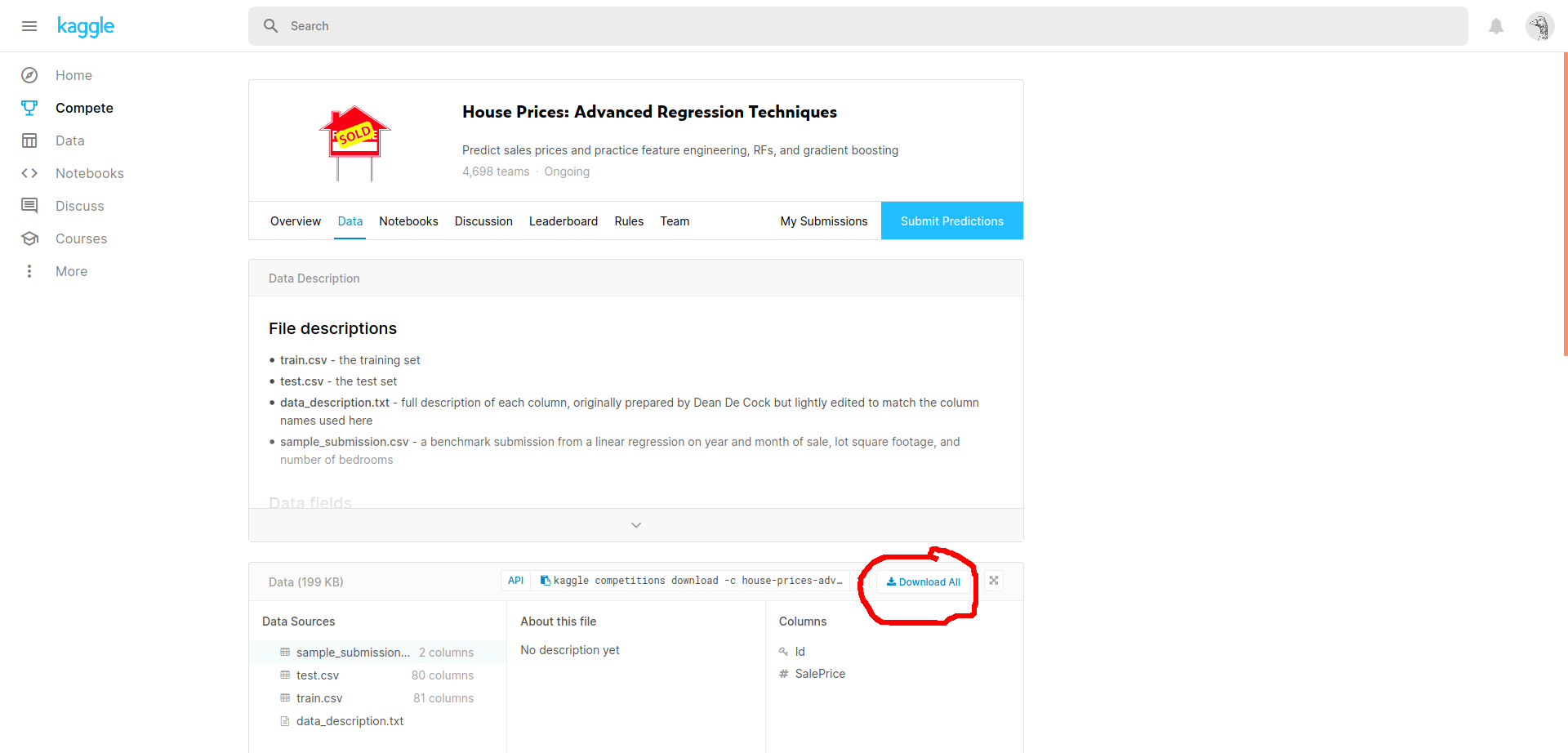
# 获取数据集torch.set_default_tensor_type(torch.FloatTensor)DATA_SRC_PATH = "/home/luzhan/My-Project/Python学习/PyTorch学习/知乎马卡斯扬-动手学深度学习PyTorch版/Data-Sets/Kaggle-house-prices-advanced/"train_src = pd.read_csv(DATA_SRC_PATH + "train.csv")test_src = pd.read_csv(DATA_SRC_PATH + "test.csv")train_size = train_src.shape[0]# 训练集包括 1460 个样本, 80 个特征, 1 个标签print(train_src.shape)# 测试集包括 1459 个样本, 80 个特征print(test_src.shape)# 展示前 5 组数据print(train_src.iloc[:5, :])
大致看一下数据的样式,当然也可以用 Excel 打开 csv 文件查看。
第 1 列的 Id 是帮助我们查看样本序号的,显然和房价没什么关系。可以看到,特征中既有我们可以直接使用的数字,也有一些文本类型描述的离散值。这样的数据集我们还需要做一定的预处理,不能直接使用。
测试集比训练集多一列,用于保存标签,测试集是 Kaggle 用来评估我们模型的,自然我们不可能知道知道正确答案。
(1460, 81)(1459, 80)Id MSSubClass MSZoning ... SaleType SaleCondition SalePrice0 1 60 RL ... WD Normal 2085001 2 20 RL ... WD Normal 1815002 3 60 RL ... WD Normal 2235003 4 70 RL ... WD Abnorml 1400004 5 60 RL ... WD Normal 250000
3.16.3 数据预处理
存储特征时,首先将 Id 项舍去,标签项 SalePrice 要另外保存。
# 数据预处理# 存储全部的特征, 舍弃第 1 个特征 Id 以及 训练集中的标签all_features = pd.concat((train_src.iloc[:, 1:-1], test_src.iloc[:, 1:]))
然后处理数值特征,进行标准化:该特征在整个数据集上的均值为μ,标准差为σ。那么,我们可以将该特征的每个值先减去μ再除以σ得到标准化后的每个特征值。对于缺失的特征值,我们将其替换成该特征的均值。
# 对所有数值特征进行标准化numeric_featrues_index = all_features.dtypes[all_features.dtypes != "object"].indexall_features[numeric_featrues_index] = all_features[numeric_featrues_index].apply(lambda x: (x - x.mean()) / x.std())# 将缺省值填充为均值(标准化后均值为 0 )all_features[numeric_featrues_index] = all_features[numeric_featrues_index].fillna(0)
接下来将离散数值转成指示特征。举个例子,假设特征MSZoning里面有两个不同的离散值RL和RM,那么这一步转换将去掉MSZoning特征,并新加两个特征MSZoning_RL和MSZoning_RM,其值为0或1。如果一个样本原来在MSZoning里的值为RL,那么有MSZoning_RL=1且MSZoning_RM=0。
# 将离散数值转换为致使特征all_features = pd.get_dummies(all_features, dummy_na=True)
看一下处理后的效果。
print(all_features)
可以看到特征数量变多了。
MSSubClass LotFrontage ... SaleCondition_Partial SaleCondition_nan0 0.067320 -0.184443 ... 0 01 -0.873466 0.458096 ... 0 02 0.067320 -0.055935 ... 0 03 0.302516 -0.398622 ... 0 04 0.067320 0.629439 ... 0 0... ... ... ... ... ...1454 2.419286 -2.069222 ... 0 01455 2.419286 -2.069222 ... 0 01456 -0.873466 3.884968 ... 0 01457 0.655311 -0.312950 ... 0 01458 0.067320 0.201080 ... 0 0[2919 rows x 331 columns]
最后我们将数据集用 values 转换成 NumPy 格式,再保存成 Tensor形式方便后续使用。同时将训练集上的标签项保存下来。
# 转换成 Tensorelem_type = torch.floattrain_features = torch.tensor(all_features[:train_size].values, dtype=elem_type)test_features = torch.tensor(all_features[train_size:].values, dtype=elem_type)train_labels = torch.tensor(train_src["SalePrice"].values, dtype=elem_type).view(-1, 1)
3.16.4 评估模型
Submissions are evaluated on Root-Mean-Squared-Error (RMSE) between the logarithm of the predicted value and the logarithm of the observed sales price. (Taking logs means that errors in predicting expensive houses and cheap houses will affect the result equally.)
以上是 Kaggle 中本题的评估标准,借助 torch.nn.MSELoss() 实现。
教程中rmse = torch.sqrt(2 * loss(clipped_preds.log(), labels.log()).mean()) 这一步进行了 2 运算,我无法理解,看 github 上也有其他读者在 issue 上提了出来。之前学习的时候到有对*平方误差函数乘1/2以抵消反向传播时求导产生的 2,但是 torch.nn.MSELoss() 我也拿简单数值试验过,应该是没有进行乘1/2的,官方文档中也没有提到,此处存疑。
更新:github上已经有人更正了,之前只看了issue没看pull request,刚刚发现。。。
def log_rmse(y_pred, y):"""对预测结果和实际标签的对数计算均方根误差Args:y_pred: 预测值y: 标签值Returns:误差值Raises:无"""with torch.no_grad():# 将小于1的值设成1,使得取对数时数值更稳定clipped_preds = torch.max(y_pred, torch.tensor(1.0))mse = nn.MSELoss()ans = torch.sqrt(mse(clipped_preds.log(), y.log()).mean()).item()return ans
3.16.5 单次训练
给定训练集进行单次训练,计算训练误差。如果给出了完整的测试集,还可以计算泛化误差。
该函数在评估模型和真正训练时都会使用到。
def train(net, train_features, train_labels, test_features, test_labels, iterate_num, batch_size, optimizer):"""训练模型, 并可视化训练过程Args:net: 学习模型train_features: 训练集特征train_labels: 训练集标签test_features: 测试集特征test_labels: 测试集标签iterate_num: 迭代次数batch_size: 数据批次大小optimizer: 优化器, 已经配置好学习率和权重衰减系数Returns:误差值Raises:无"""train_lose_list, test_lose_list = [], []train_set = torch_data.TensorDataset(train_features, train_labels)train_set_iter = torch_data.DataLoader(train_set, batch_size)loss_func = nn.MSELoss()for i in range(iterate_num):for x, y in train_set_iter:y_pred = net(x)current_lose = loss_func(y_pred, y)optimizer.zero_grad()current_lose.backward()optimizer.step()train_lose_list.append(log_rmse(net(train_features), train_labels))# 如果提供了测试集, 则计算泛化误差if test_labels is not None:test_lose_list.append(log_rmse(net(test_features), test_labels))return train_lose_list, test_lose_list
3.16.6 K 折交叉验证
K 折交叉验证被用来选择模型并调节超参数。当然在本次简单粗糙的实战中也没什么好选的。
因为 Kaggle 提供的测试集是没有标签的,这部分实际上并不是给我们训练用的。所以将原始的训练集分成两部分,一部分作为验证集,剩余的作为新的训练集。
def get_k_fold_data(k, i, features, labels):"""将原始的训练集分为 k 个子数据集, 取第 i 个作为验证集.Args:k: 子数据集数量i: 第 i 个作为验证集, i = 0, 1, ..., k - 1features: 训练集的特征labels: 训练集的标签Returns:新的训练集和验证模型的验证集.Raises:无"""assert (k > 1), "k 需大于 1"# 单个划分的规模fold_size = features.shape[0] // ktrain_set_features, train_set_labels = None, Nonefor j in range(k):# 切片选择第 j 个划分idx = slice(j * fold_size, (j + 1) * fold_size)part_features = features[idx, :]part_labels = labels[idx]# 第 i 个划分作为验证集, 其余都是新的训练集if j == i:vaild_set_features = part_featuresvaild_set_labels = part_labelselif train_set_features is None:train_set_features = part_featurestrain_set_labels = part_labelselse:train_set_features = torch.cat((train_set_features, part_features), dim=0)train_set_labels = torch.cat((train_set_labels, part_labels), dim=0)return train_set_features, train_set_labels, vaild_set_features, vaild_set_labels
3.16.7 训练准备
准备一下训练用到的超参数。
# 训练准备loss_func = nn.MSELoss()net = nn.Sequential(nn.Linear(all_features.shape[1], 1))optimizer = torch.optim.Adam(net.parameters(), lr=3, weight_decay=0)batch_size = 64iterate_num = 200k = 5
3.16.8 验证模型
验证模型,真正训练的时候这部分要禁用。
def train_and_vaild(net, train_features, train_labels, k, iterate_num, batch_size, optimizer):"""用 K 折交叉验证对模型进行训练和验证Args:net: 学习模型train_features: 训练集特征train_labels: 训练集标签k: 要分的组数iterate_num: 迭代次数batch_size: 数据批次大小optimizer: 优化器, 已经配置好学习率和权重衰减系数Returns:无Raises:无"""train_lose_sum, vaild_lost_sum = 0, 0for i in range(k):current_data_set = get_k_fold_data(k, i, train_features, train_labels)train_lose_list, vaild_lost_list = train(net, *current_data_set, iterate_num, batch_size, optimizer)if i == 0:d2l.semilogy(range(1, iterate_num + 1), train_lose_list, "epochs", "LOG_RMSE",range(1, iterate_num + 1), vaild_lost_list,["train", "vaild"], show=True)print("第{0}折:训练集误差={1:.4f}, 验证集误差={2:.4f}".format(i + 1, train_lose_list[-1], vaild_lost_list[-1]))train_lose_sum += train_lose_list[-1]vaild_lost_sum += vaild_lost_list[-1]print("平均值:训练集误差={0:.4f}, 验证集误差={1:.4f}".format(train_lose_sum / k, vaild_lost_sum / k))# 验证模型train_and_vaild(net, train_features, train_labels, k, iterate_num, batch_size, optimizer)
运行结果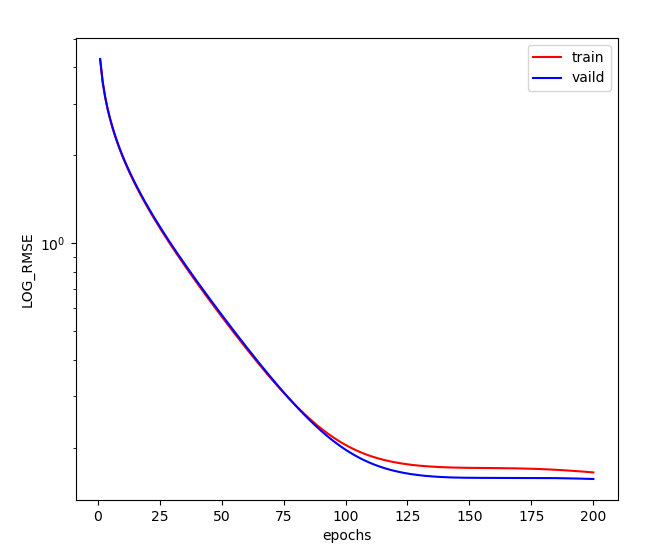
第1折:训练集误差=0.1645, 验证集误差=0.1562第2折:训练集误差=0.1318, 验证集误差=0.1437第3折:训练集误差=0.1233, 验证集误差=0.1409第4折:训练集误差=0.1273, 验证集误差=0.1271第5折:训练集误差=0.1192, 验证集误差=0.1442平均值:训练集误差=0.1332, 验证集误差=0.1424
3.16.9 训练模型并输出预测结果
验证后选择最佳方案(这里不用选。。)直接用整个数据集进行训练。
def train_and_test(net, train_features, train_labels, test_features, iterate_num, batch_size, optimizer):"""训练模型并输出测试集的预测标签Args:net: 学习模型train_features: 训练集特征train_labels: 训练集标签test_features: 测试集特征iterate_num: 迭代次数batch_size: 数据批次大小optimizer: 优化器, 已经配置好学习率和权重衰减系数Returns:真正用于训练的训练集和验证模型的验证集.Raises:无"""train_lose_list = train(net, train_features, train_labels, None, None, iterate_num, batch_size, optimizer)[0]d2l.semilogy(range(1, iterate_num + 1), train_lose_list, "epochs", "LOG_RMSE", legend=["train"], show=True)print("训练误差={0}".format(train_lose_list[-1]))return net(test_features).detach().numpy().reshape(-1)# # 训练模型并输出测试集的预测值prediction = train_and_test(net, train_features, train_labels, test_features, iterate_num, batch_size, optimizer)print(prediction)
运行结果
训练误差=0.14923113584518433[115822.91 156480.6 194104.28 ... 202581.58 105717.84 240634.23]
3.16.10 生成最终结果
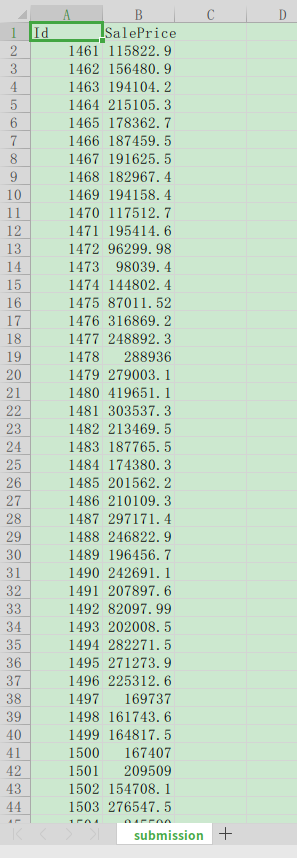
按 sample_submission.csv 的样例格式生成结果,只保留 Id 和 SalePrice 。
# 生成符合提交格式的输出文件test_src["SalePrice"] = pd.Series(prediction)submission = pd.concat([test_src["Id"], test_src["SalePrice"]], axis=1)submission.to_csv("./submission.csv", index=False)
然后就可以在当前目录看到新的文件,拿 Excel 打开瞧瞧。

3.16.11 提交结果
拖拽文件至红圈处,或点击选择上传文件。这需要科学上网,能访问 Google 就行。我用了一个 FireFox 上的谷歌访问助手插件后传上了。
悲惨的排名。
3.16.12 小结
基础章节在这里做一个结束,真的是一次非常有意义的实战,我爱这份教程。
原始的数据集不是拿来就可以用的,还需要进行预处理,我在讨论区等都看到了复杂高深的特征工程,教程中教授的只是一个入门级的方法,还有pandas也真的是边查边用,要学的东西还有很多。学习模型也用的非常简单,连隐藏层都没有。以及关于各种超参数要怎么去调节真的还没有一点头绪。
继续学习。
顺带一句,要是语雀能输入 emoji 就更好了。
3.16 实战Kaggle比赛:房价预测.py

若有收获,就点个赞吧
0 人点赞
