Spark运行逻辑
通过 wordCount 程序, 分析Spark程序的运行逻辑
object ScalaWordCount {def main(args: Array[String]): Unit = {//创建 Scala 的配置, 设置应用程序的名字//local[*] local 代表使用本地模式运行, * 代表使用的线程数量val conf: SparkConf = new SparkConf() .setAppName("ScalaWordCount").setMaster("local[*]")val sc = new SparkContext(conf)//读取文件val liens: RDD[String] = sc.textFile(args(0))//切分压平val words: RDD[String] = liens.flatMap(_.split(" "))//单词映射val wordAndOne: RDD[(String, Int)] = words.map((_, 1))//分组聚合运算val reduceRdd: RDD[(String, Int)] = wordAndOne.reduceByKey(_ + _)//文件写出到 hdfsreduceRdd.saveAsTextFile(args(1))//释放资源sc.stop()}}
wordCount RDD个数
通过查看DAG图,图中的一个原点表示一个RDD
wordCount程序有6个RDD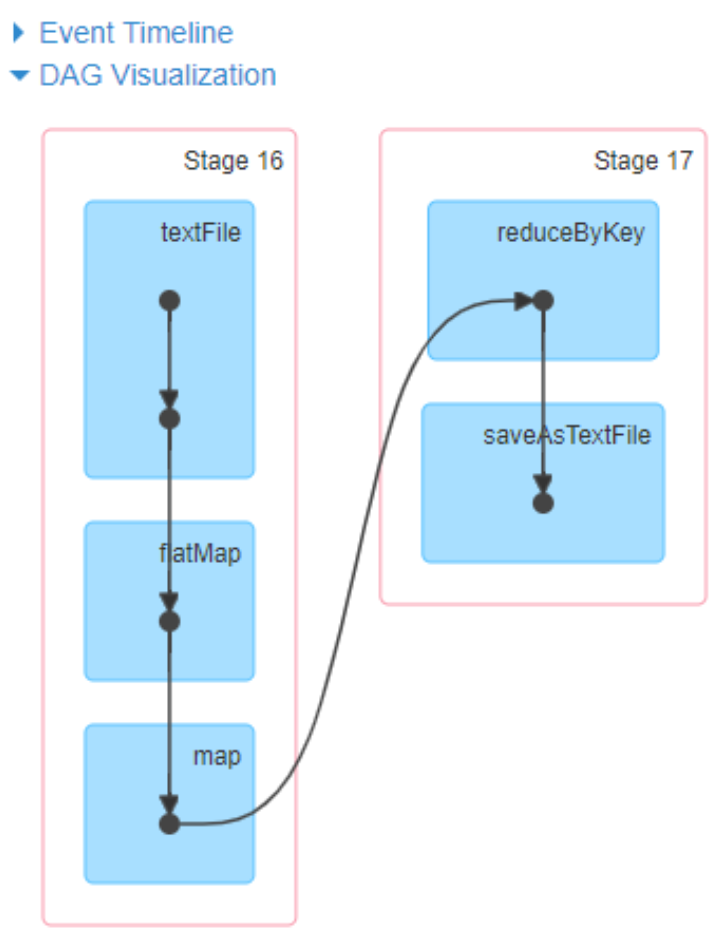
textFile()
HadoopRDD[LongWritable, Text]:调用Hadoop读取HDFS的文件,形成元组,元组内(偏移量,行内容),偏移量几乎用不着;LongWritable 和 Text 都是Hadoop的类型MapPartitionsRDD[String]:通过 map ,把偏移量去掉,只留下行内容- 也即,textFile 最终返回
MapPartitionsRDD[String]
flatMap
- 接收
MapPartitionsRDD[String],返回MapPartitionsRDD[String]
map
- 接收
MapPartitionsRDD[String],返回MapPartitionsRDD[(String, Int)]
reduceByKey
- 接收
MapPartitionsRDD[(String, Int)],返回ShuffleRDD[(String, Int)] - 先局部聚合,结果会写入Executor 的本地磁盘中,而不是保存到内存
- 进行全局聚合,根据分区器(对key进行操作,得到各个分区的编号),将本地的计算结果进行网络传输,相同的Key分到相同的 Executor,然后在Executor中进行各自Key汇总计算
ShuffleRDD[(String, Int)]内部是进行了网络传输的的
saveAsTextFile
- 接收
ShuffleRDD[(String, Int)],返回MapPartitionsRDD[NullWritable, Text]:NullWritable 和 Text 都是Hadoop的类型 - 输出内容到 HDFS 中
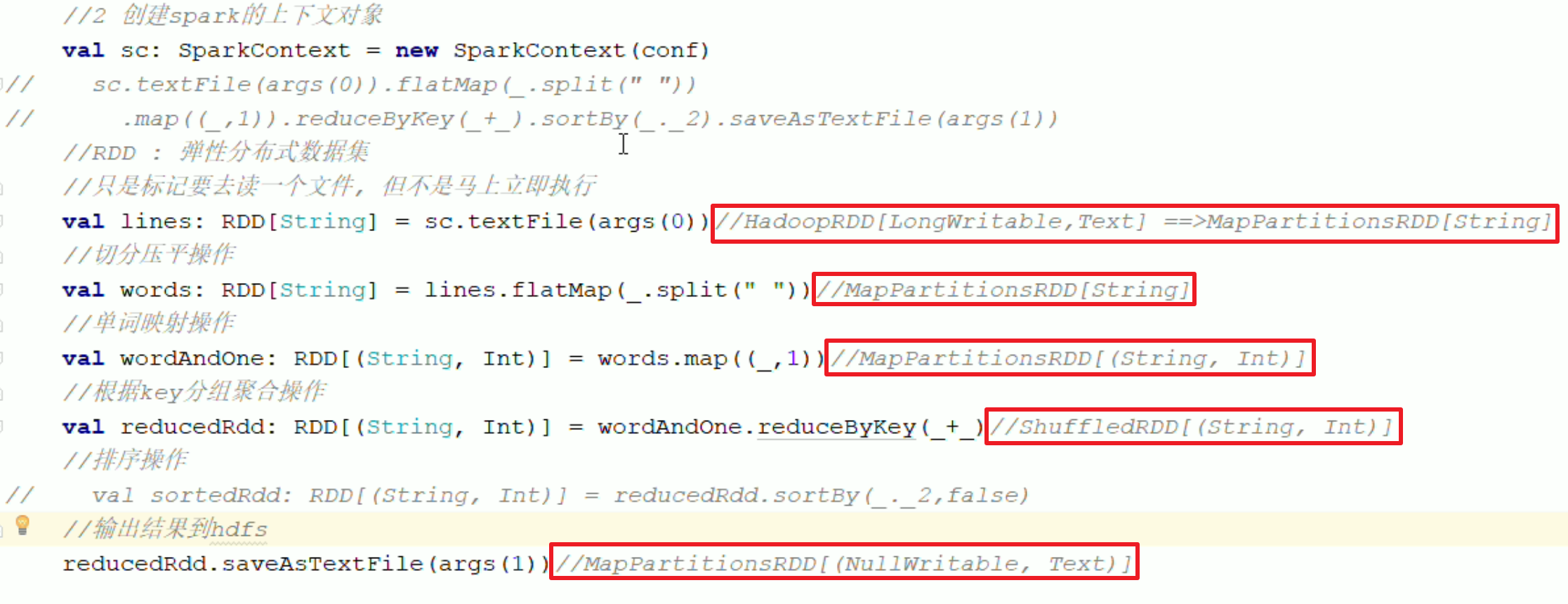
WordCount RDD 流转图形化
Shuffle 操作时
- 局部聚合操作的结果会先存到Executor的磁盘中,成为文件,而不是内存中
- 全局聚合时,Executor 读取自己磁盘的数据,将key按照分区器的划分,得到分区号,网络传输到分区所在的Executor中
Shuffle 触发时机
- 只要是返回ShuffleRDD的算子, 就会触发Shuffle操作
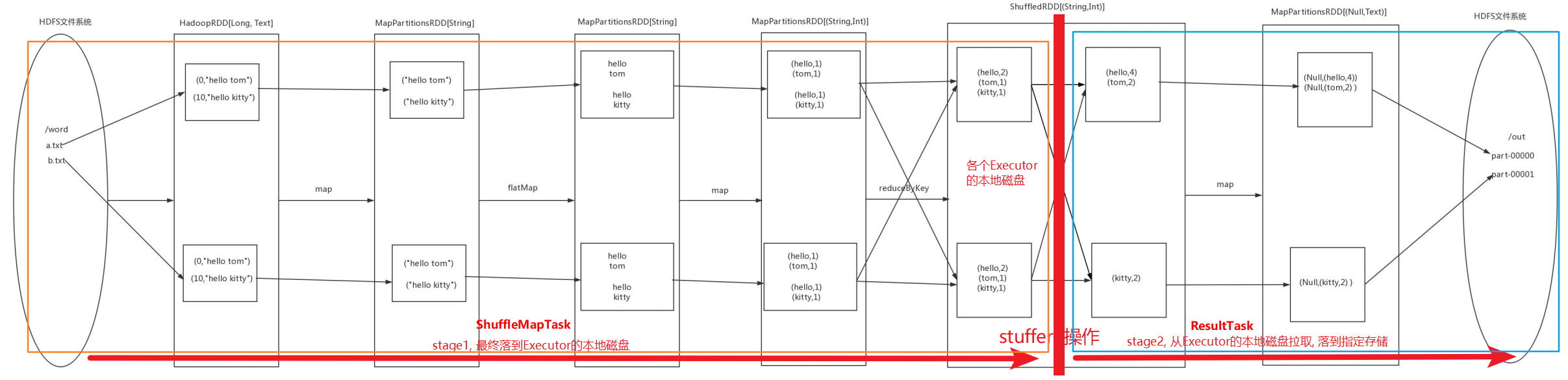
WordCount Stage 划分
以RDD写入磁盘的操作作为 stage 的划分标准
分别命名为:
- ShuffleMapStage
- ResultStage
不管是 ShuffleMapStage 还是 ResultStage,也不管其内有多少个算子,Spark 都会将 stage 作为一个完整的 Task 交给 Executor 来执行
优势
- 算子执行连贯,优化方便
- 输入输出标准,都是从磁盘(HDFS)中获取数据,最后输出到磁盘中(HDFS)
- Task 运行中其他的RDD转换都是基于内存的,不会和磁盘做交互
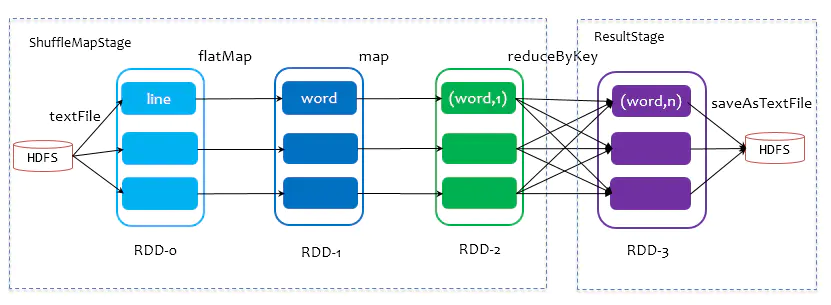
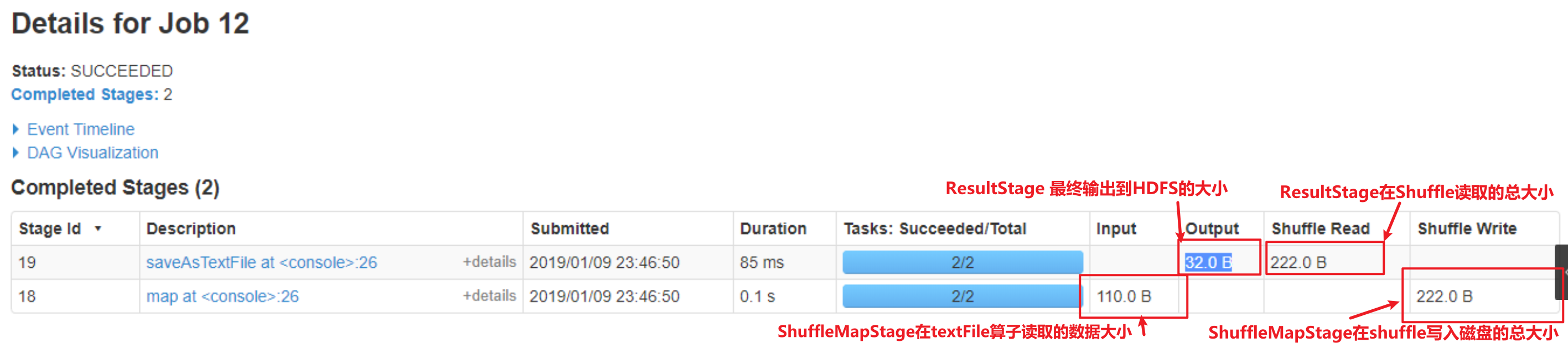
Stage 在 SparkUI 的信息
ShuffleMapStage 的输入输出
- Input:从数据源中获取的数据大小
- Shuffle Write:所有Executor 在 Shuffle 写入到磁盘的总大小
ResultStage 的输入输出
- Shuffle Read:所有Executor 在 Shuffle 从磁盘读取的总大小
- Output:输出到数据源的数据总大小
每个Stage都是划分为多个任务的,一般为一个分区一个任务,每个分区的任务分到一个Executor中执行
ResultStage每个Task的输出都是独立的,如果输出到文件,则是不同的文件,这个和MR是一致的
在spark中, 提交一个任务时,
在数据层面上, 会被拆分成分区 进行执行
在执行流程上, 也会被分成两种任务类型
ShuffleMapTask 和 ResultTask
只要是返回ShuffleRDD的算子, 就会触发Shuffle操作, 就一定会生成ShuffleMapTask任务
但是否会生成ResultTask, 要看后续是否有Action算子, 将结果输出
如果后续又有一个会触发Shuffle的算子, 则中间这段依旧是ShuffleMapTask任务
ShuffleMapTask: 即只要数据集的数据从内存落到Executor(执行的机器的容器)的本地磁盘上, 那么从这个操作往前的任务都会被视为ShuffleMapTask, 分界岭就是具有Shuffer操作的前半段
ShuffleMapTask任务在物理上, 也是被串联在一起执行的, 如上图, map, flatMap, map再到reduceByKey的局部聚合落到磁盘上的这一整个操作, 都是一个完整的任务, 会在一个程序内完成
ResultTask: 从Executor的本地磁盘上读取数据, 然后执行, 最后输出
ResultTask任务在物理上也是一个完整的程序任务, 在一个程序内
注意,如果一个任务中,遇到了两次shuffle,则会有两个ShuffleMapTask,和一个ResultTask
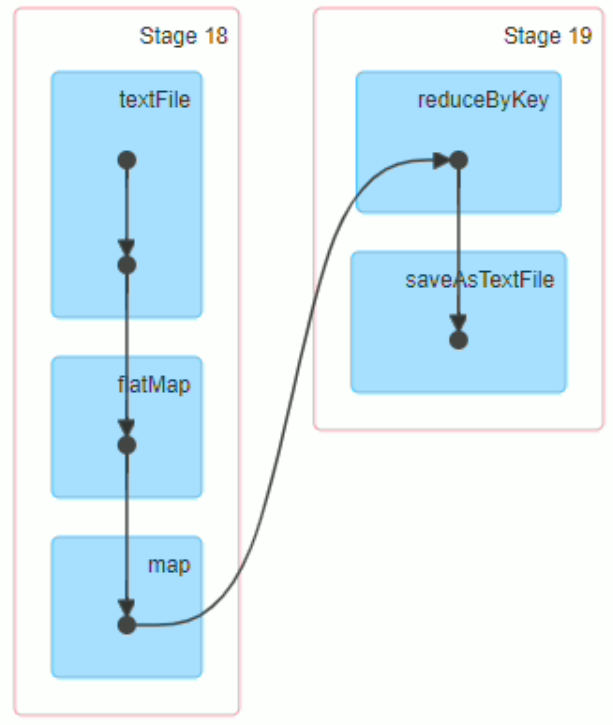
从Spark界面的DAG(有向无环图)中就可以清晰看到, wordCount 任务分为两个stage, 一个是shuffleMapTask, 一个是resultTask, 且stage本身是一个连续执行的完整子程序, 不会说执行一下停下来等算子, 而是持续执行的
算子内的节点表示RDD, 可以清楚看到, textFile中有两个节点,这两个节点分别表示HadoopRDD和mapPartitionsRDD
虽然reduceByKey被分到了stage2, 但其实其局部聚合和写入本地磁盘是在stage1中的

Input: 从HDFS写入, 这里是指写入了110.0B
Shuffle Write: 指shuffleMapTask任务结束后写入到本地磁盘的量 —> 所有分区写入的总和
Shuffle Read: 指后续的从所有Executor的本地磁盘读取的总量, 通过http的方式读取各个Executor的本地磁盘文件
Output: 写出到HDFS的文件大小
Spark 执行流程分析
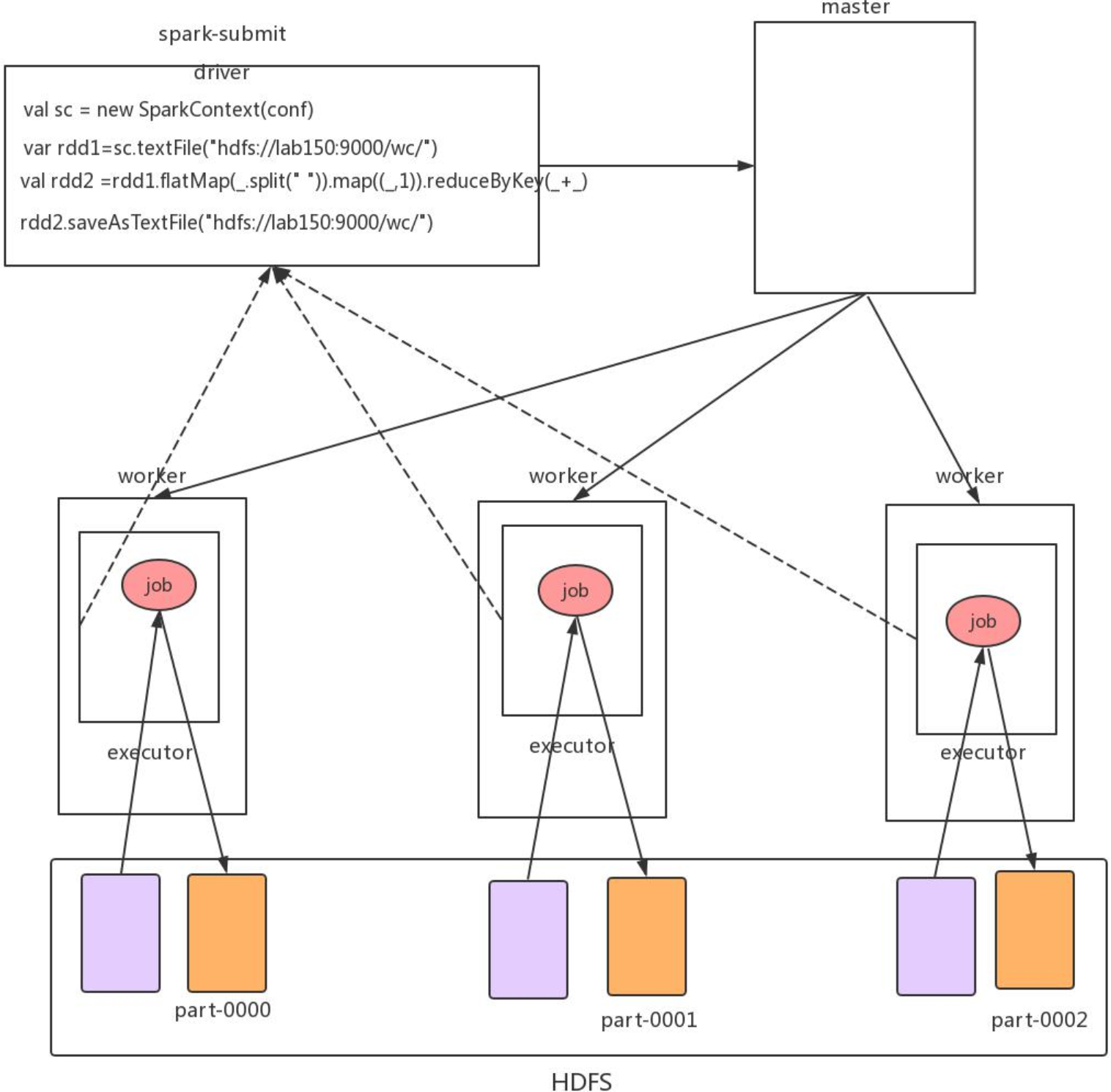
主要执行步骤
- 当我们执行
bin/spark-submit --master --executor-memory 2g --total-executor-cores 6 --class cn.wolfcode.spark.ScalaWordCount original-SparkDemo-1.0.0.jar命令时,本地程序执行 SparkSubmit 程序,该程序会告诉 Master 需要创建多少个 executor 进程- executor 的个数由分区数决定,而分区数可以自定义,也可以默认,默认时由读取的HDFS文件个数,每个文件的区块数决定
- Master 通知对应的 Worker,让 Worker 创建对应的 executor 进程
- 通过 RPC
- executor 进程创建完毕,建立和 sparkSubmit 进程之间的通信
- 通过RPC
- 开始在 SprkSubmit 进程中执行对应的程序,生成对应的 RDD(不会实际拉取数据,也不会实际运算,只是保存计算的逻辑),包括对文件分区的划分
- 当执行 Action 命令执行的时候,会生成对应的 job 任务,并且把 job 任务分发到对应的 executor 进程中执行
- 执行到有shuffle运算的算子,算子内部会有一个方法
runJob(),此时就会通过 rpc 让 executor 执行拉取 sparkSubmit 中的 rdd 的算子计算逻辑,到 executor 中进行实际的运算:从 HDFS 拉取该 executor 对应的文件区块,执行各个算子的计算 - 在 ShuffleMapTask 阶段,executor 执行的是文件分区的局部运算,算完之后调用分区器,计算好每行数据接下来需要去的分区号,存储到磁盘
- 在 ResultTask 阶段,executor 根据自己分配到的分区号,去各个 executor的磁盘中获取对应分区号的数据,拉取到自己的内存中,进行汇总计算,并输出 —> 这个汇总输出的意思是以分区号汇总数据计算,并输出
- 执行到有shuffle运算的算子,算子内部会有一个方法
如果在 executor 计算完,最终不是需要分区计算输出,而是要把全量的数据汇总进行计算的话(如计算条数 count),一般会再通过 rpc 把各个 executor 的条数传回给 SparkSubmit (Driver)程序所在的机器,也即提交任务的客户端机器所在,进行汇总计算输出
2. Spark 的 Cache
2.1. Spark 的缓存的引入
我们上传我们的文件 teacher.txt 文件(800000 万数据)复制 10 份上传到 hdfs 的指定目录
/cache,接下来我们进行单词函数的一个统计(使用 spark-shell 的操作)
再执行下面的操作val words=sc.textFile("hdfs://lab150:9000/cache/")words.count
我们会发现第一次执行的比较慢,但是第二次肯定会比第一次快
因为在我们的 job 结束以后,但是如果我们的任务程序 submit 程序没有退出的话,我们 job 程序会在 executor 上面缓存上次的一些结果在磁盘(主动),所以第二次我们在执行的时候就快很多,
那么对于这个结果其实还可以提升的更快,那就是使用我们的 Spark 的内存缓存2.2. Spark 的内存缓存
当我们在一个处理任务的程序中,如果需要对中间结果进行多次的访问统计分析,那么我们可以把中间结果缓存到我们的 executor 内存当中,极大提高我们二次查询的性能
具体操作调用 rdd 的 cache 方法,默认会把 rdd 的处理的数据存放到我们的 executor 的内存当中
- cache 并不是一个 Action 算子,执行时只会标记这个RDD需要进行缓存,等执行到 Action 算子时,才会在 Executor 中缓存
注意:
- cache 返回的是原RDD,不接收也行,cache 并不会返回新的RDD
在管理控制台查看缓存信息val cacheRDD=words.cachecacheRDD.count # 在执行统计的时候会把结果统计同时保存到 executo 的内存当中

Spark 缓存执行示意图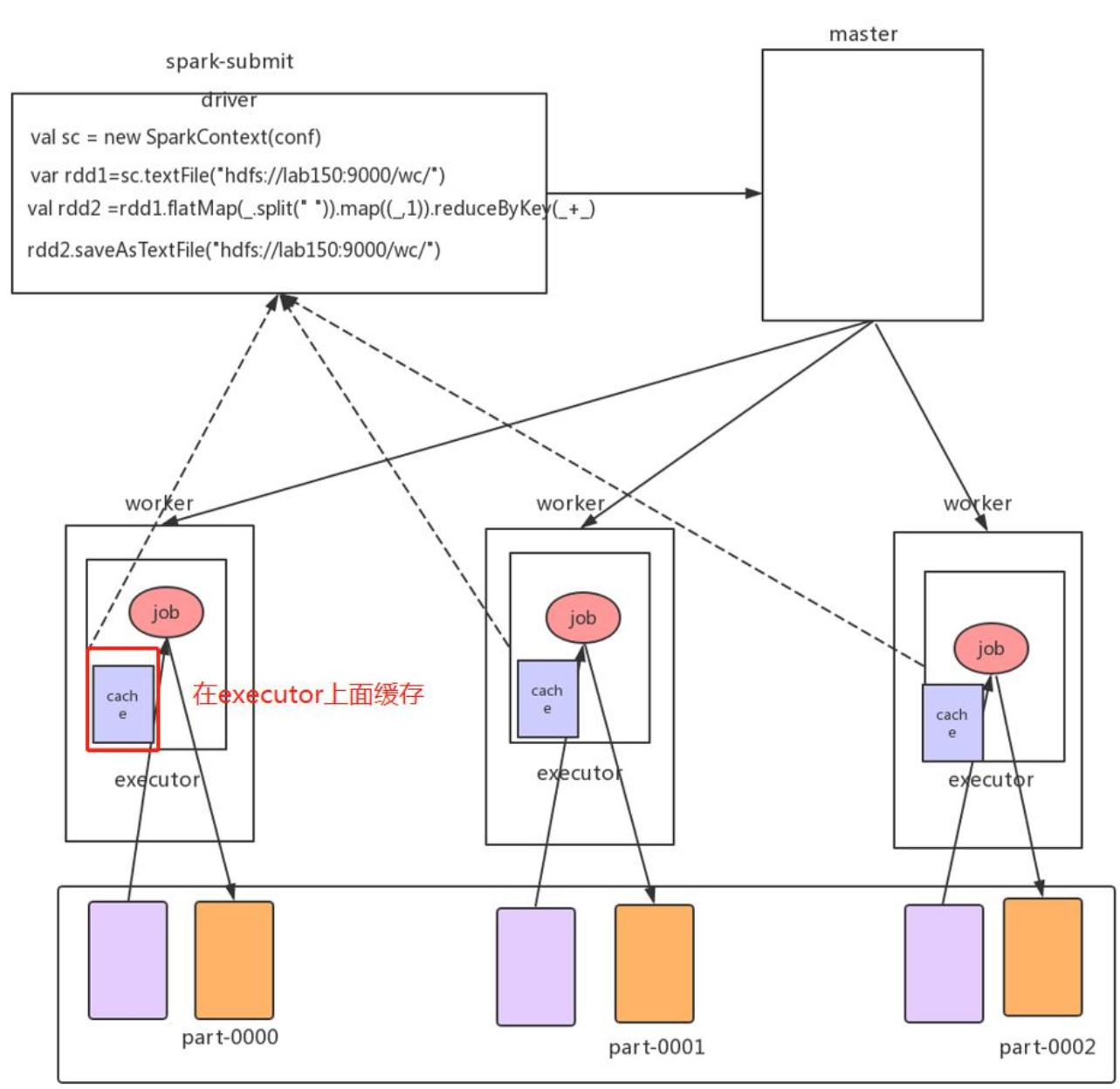
- Spark 的 RDD 第一次从 HDFS 读取数据,然后缓存在 Executor 中,返回缓存后的 RDD
- 当第二次需要使用到相同的RDD时,如果程序调用的时缓存后的RDD,Executor 就会从内存中拿出缓存的RDD进行后续的计算
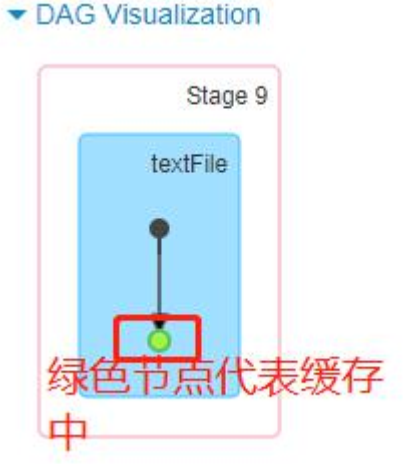
注意:缓存只是针对当前的一个会话(SparkContext),如果我们关闭 spark-shell,然后在重新执行任务的话缓存是没有, 只有重新运行程序把数据缓存到内存中后才可以使用缓存
2.3. Spark 的内存的缓存的引用
在我们编写的第二个 TopN 的统计程序中,我们是多次提交任务的,但是对于每次提交的任务都会重新去hdfs 文件系统中读取,我们把数据缓存到内存则会极大的提高后面的 Task 程序的运行效率(3s->87ms)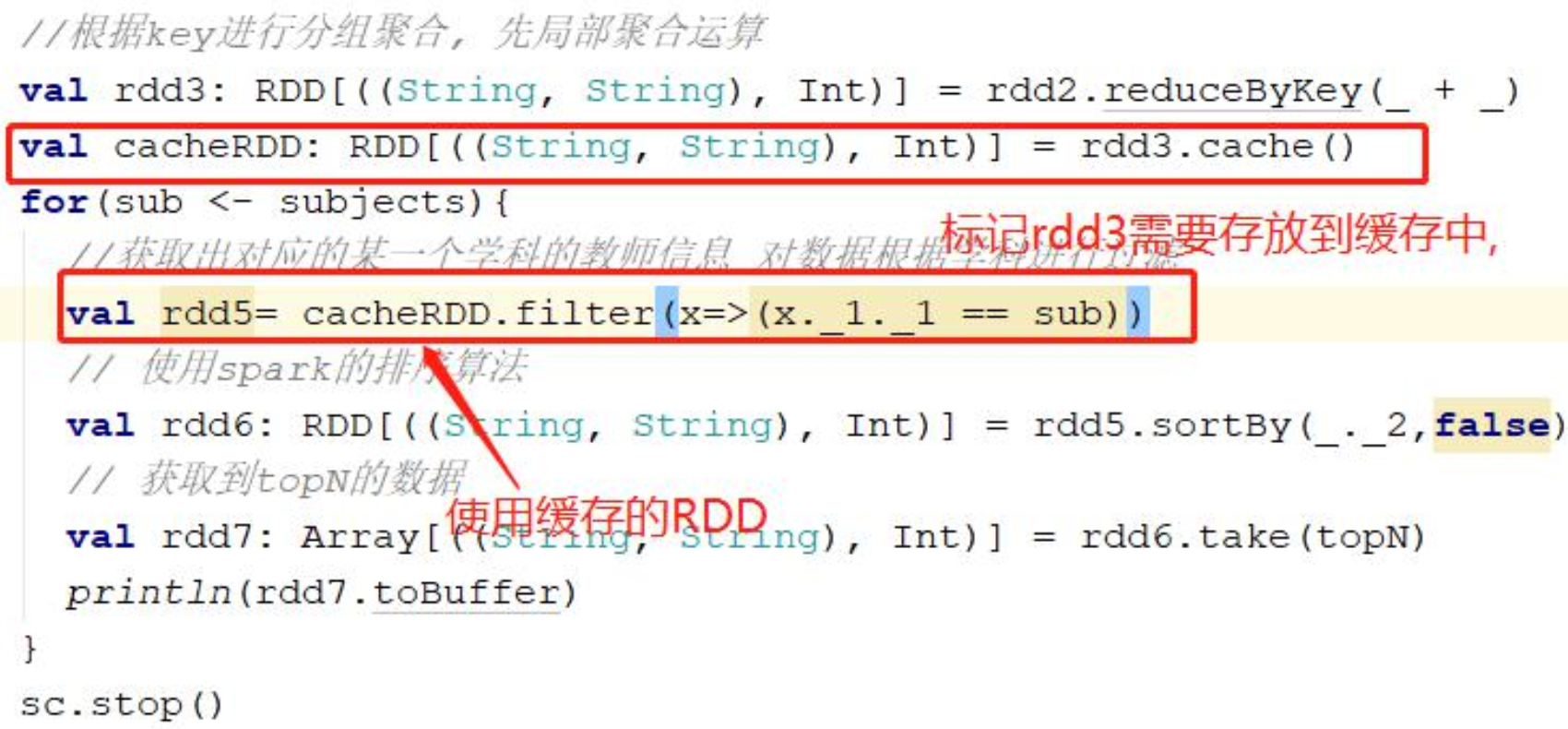
2.4. Spark 的缓存部分数据
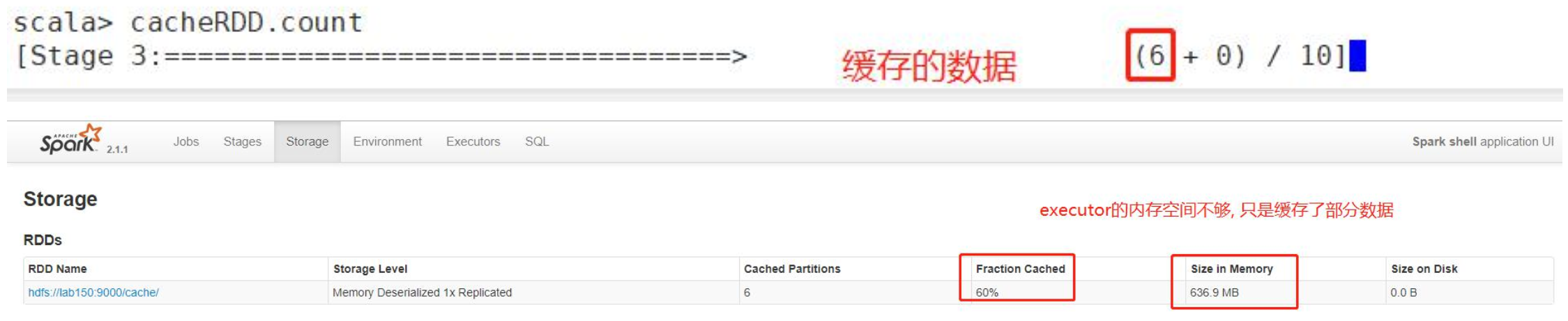
如果需要缓存的数据量比 executor 的内存还大,那么就会缓存部分数据
注意:如果需要缓存的RDD没有全部缓存到内存,那基本无意义,剩余部分仍然需要去HDFS中获取
bin/spark-shell --master spark://lab150:7077 --executor-memory 1g --total-executor-cores 6val words=sc.textFile("hdfs://lab150:9000/cache/")val cacheRDD=words.cachecacheRDD.count
2.5. Spark 缓存的应用场景
- 要求计算速度快
- 集群的资源需要足够大,可以存放足够多的数据的缓存
- 被 Cache 的数据会多次触发 Action 的操作,否则就没有缓存的意义
- 先会对原始数据进行过滤,然后在存放到缓存中
2.6. Spark 缓存的释放
当我们的任务都执行完成以后,我们需要释放对应的缓存资源,那么就可以直接调用一个方法 ```java cacheRDD.unpersist(true) # 其中 true 表示异步执行, false 表示同步执行
释放完成以后我们在管理控制台的 storage 里面是没有对应的信息<a name="iwbXl"></a>## 2.7. Spark 的缓存的源码分析、调用的 cache 方法,实际上就是调用 `persist()` 方法<br /><br /><br /><a name="pMcJw"></a># 3. Spark 的 CheckPoint 机制对于一些机器学习、人工智能的一些应用,往往需要经过无数次对中间结果的一些迭代计算。那么对于这种迭代计算的中间结果,我们可以使用 cache 存放到一个内存中,提高计算效率。<br />但是这个并不是我们的最优的解决方案, 主要存在以下几个问题:1. **局部不安全**:数据是保存在当前的 executor 中的,如果这个 executor 挂掉那么对应的缓存的数据就没有了,那么在对于中间数据比较重要的应用是灾难性的1. **全局不安全**:对于迭代计算,很可能在运行阶段我们的 **SparkSubmit 程序挂掉**,**那么这个时候所有的中间数据都会丢失**因为存在上面两种情况,我们应该把中间结果持久化保存,这个时候我们可以把我们的数据保存到分布式文件系统(HDFS)上面,这样的话我们的数据就比较安全<a name="SOGLP"></a>## 3.1. CheckPoint 的实现设置缓存目录```javasc.setCheckpointDir("hdfs://lab150:9000/ckdir") # 设置缓存的目录, 目录不存在,则会创建
设置需要缓存的文件
bigdataRDD.checkpoint() # 设置需要缓存的 RDD 的数据, 在 Action 触发的时候回执行 checkpoint 操作bigdataRDD.count
3.2. CheckPoint 的使用场景
- 需要求保证数据的安全,不可丢失
- 相对于使用 cache 来说,速度要求不高
- 将中间结果保存到 HDFS 分布式文件系统
对于我们 checkPoint 保存后的数据,下次在进行统计分析的时候对于 checkPoint 的之前的 RDD 的运算就不会在重新读取,直接从 checkPoint 的 RDD 开始进行操作计算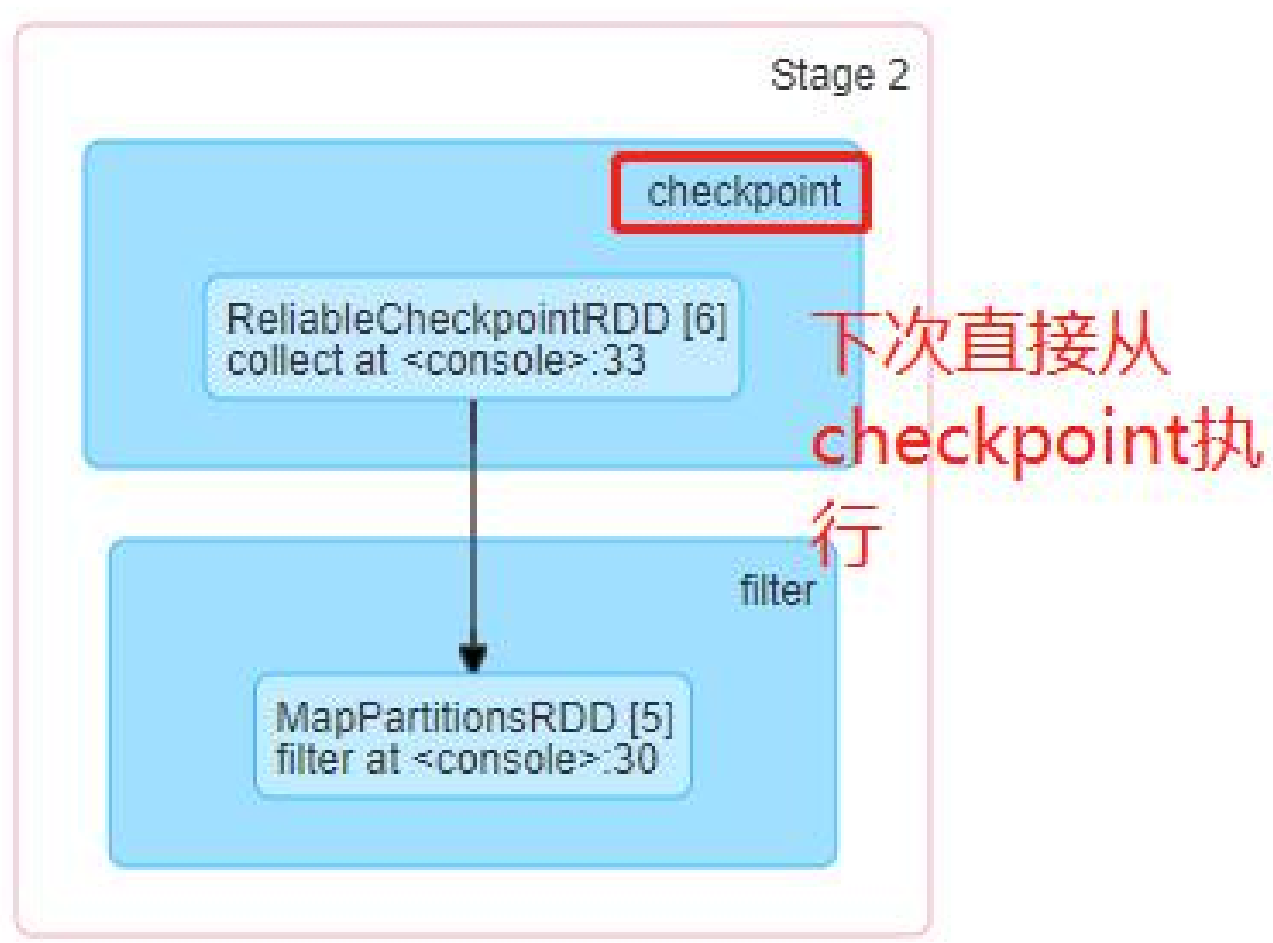
3.3. Checkpoint 源码分析

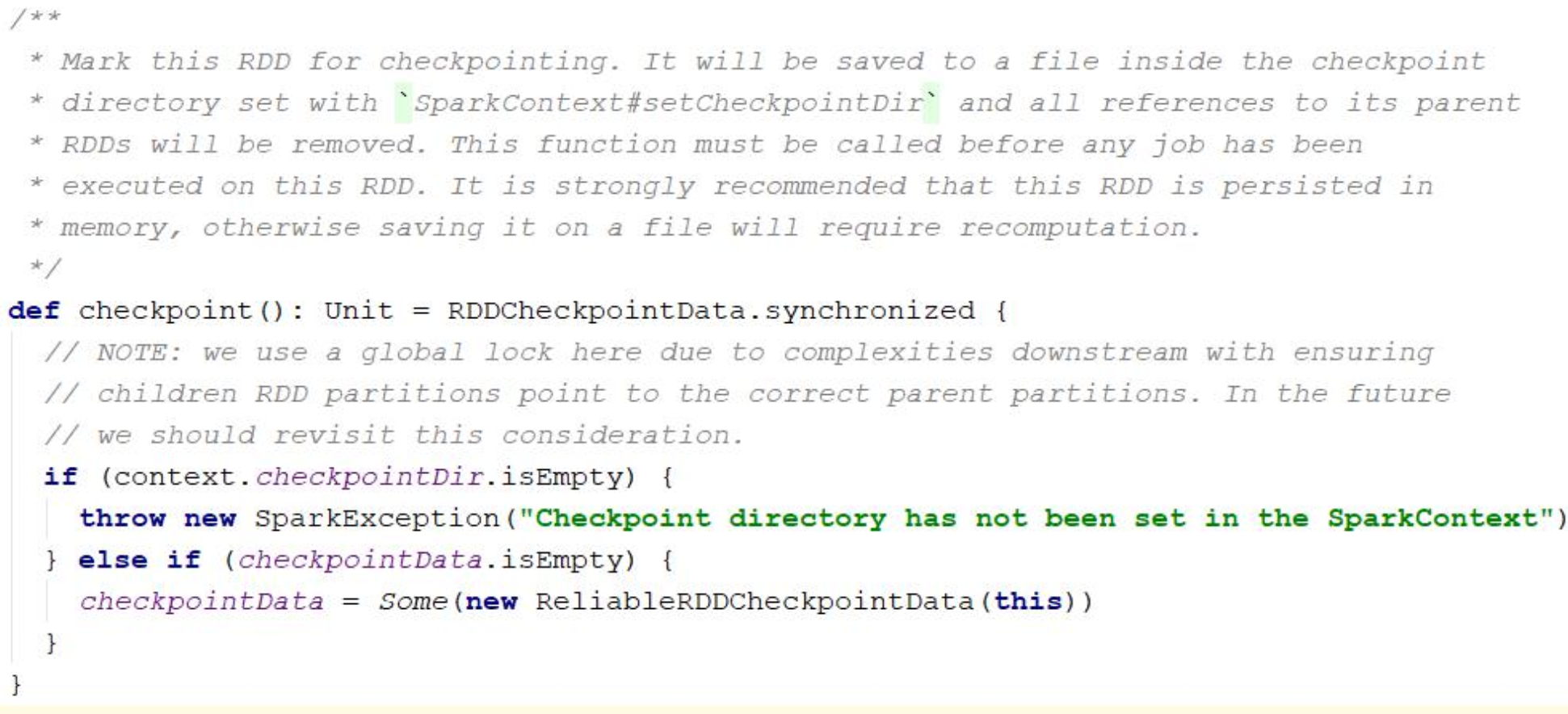
如果当前的 RDD 既做了 cache,又做了 checkpoint,那么会优先使用 cache 的数据
4. 综合案例
4.1. 根据 Ip 找到对应的省份信息的需求
在现在的业务系统,很多广告投放的时候回指定区域投放广告,比如当前的访问用户是海南的用户,如果你给他推送一个羽绒服的广告显然是在浪费钱,如果当前的访问用户是新疆的用户,我们给用户推送猪肉系列的零食显然是有问题的
所以在很多的网站,现在基本上都会通过用户的相关信息进行用户的行为分析,通过后台发送日志到日志服务器
比如京东、爱奇艺、淘宝等网站基本上都会通过日志来收集用户的相关的行为信息分析
4.2. 需求分析
根据访问用户的日志信息中的 Ip 地址计算其请求的归属地,并且按照省份统计每个省份的访问次数,然后将计算好的结果写入到 MySQL 中
- 整理用户请求的日志数据,切分出对应的 IP 地址,并且转换为十进制数据
- 加载并整理规则,取出有用的字段,然后将数据缓存到内存中(Executor 内存)
- 将访问日志的 ip 信息去规则中查找对应的省份信息(二分法查找)
- 取出对应的省份名称,然后将其和 1 组合在一起
- 按照省份名称分组聚合
- 将聚合后的数据写入到 MySQl 中
日志采集框架图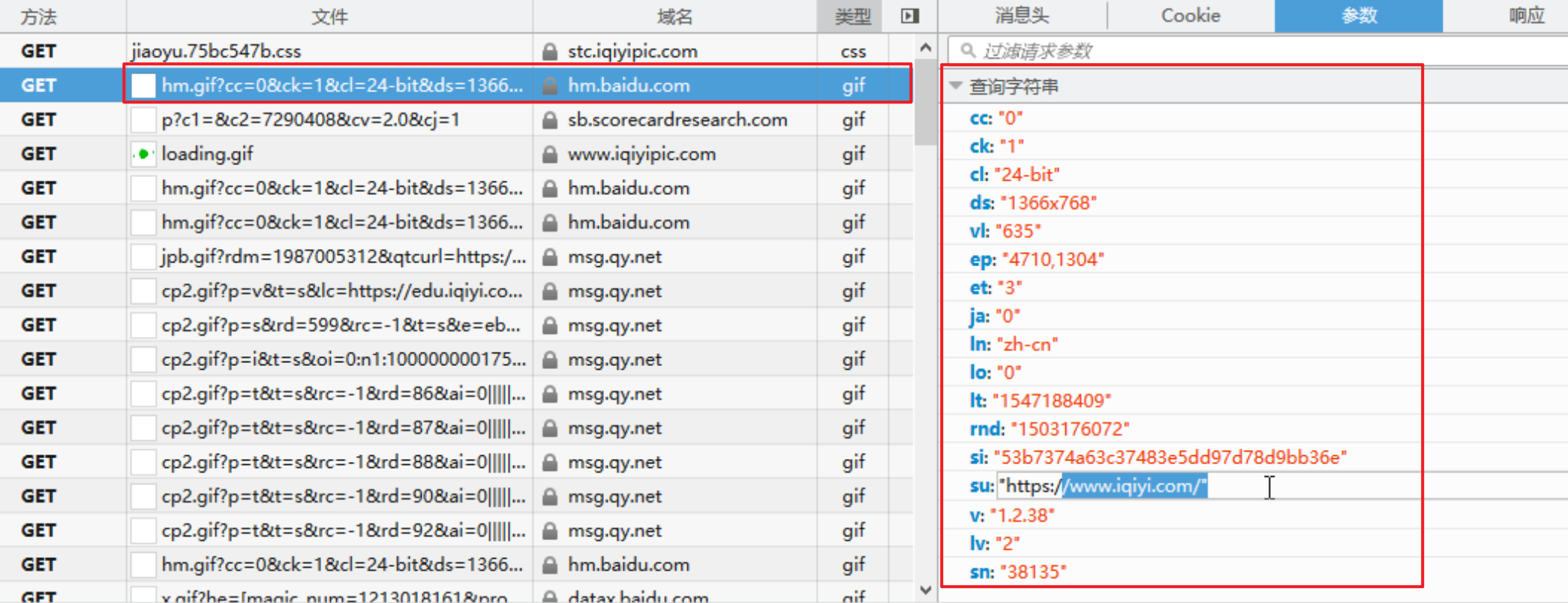
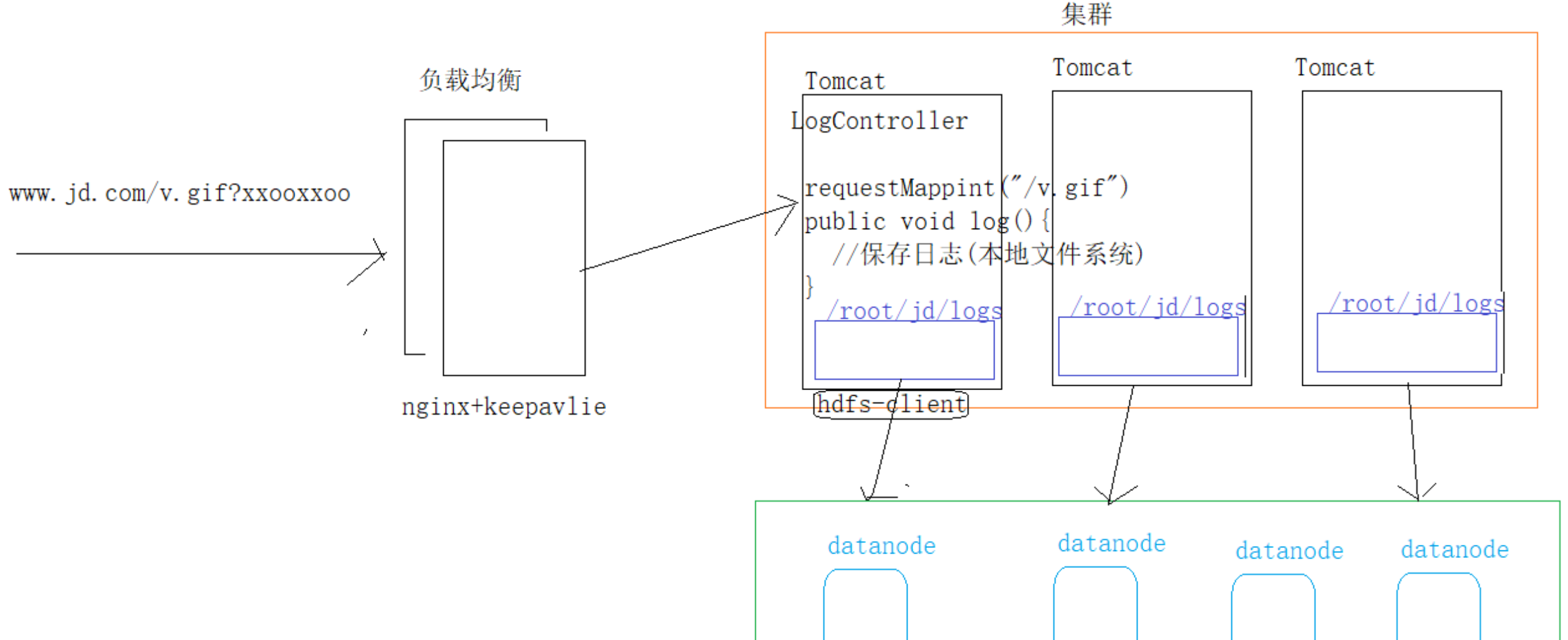
- 前端记录用户信息,发送Get请求,通常会将接口地址伪装成资源地址,如 xxx.gif
- 用户信息请求频率高,对应的api服务应当使用负载均衡
- 使用 nginx 主从进行请求负载均衡转发
- api服务多套部署
- api 服务接收到用户信息后,进行信息解析
- 解析后的信息作为日志写入到本地的日志文件中 —> 这是原始信息,应当写入文件中,而不是写入数据库中
- 另外起一个 HDFS-Client,定时将各个 api 服务机器上的文件写入 HDFS 中,然后清除机器上的日志文件
- 日志分析 ETL 启动,从 HDFS 上拉取文件
4.3. 具体实现步骤
IP 地址可以在 api 服务中直接获取
这里只是模拟日志分析ETL的实现
先完成一个单机版的
- 接收一个 ip i地址
- 转成 Long 数值
-
4.3.1.完成对于 Ip 地址的一个转换功能
IP 本身是一个 32 位的二进制数据,而 java Long 类型也是32位的,因此可以将 IP 转为 Long 数值,方便进行比对
帮助类//把 IP 转换为 Long 类型数据def ip2Long(ip: String): Long = {val fragments = ip.split("[.]")var ipNum = 0Lfor (i <- 0 until fragments.length){ipNum = fragments(i).toLong | ipNum << 8L}ipNum}
4.3.2.把规则加载到内存并返回一个数组
//读取规则def readRules(path: String): Array[(Long, Long, String)] = {//读取 ip 规则val bf: BufferedSource = Source.fromFile(path)val lines: Iterator[String] = bf.getLines()//对 ip 规则进行整理, 并放入到内存val rules: Array[(Long, Long, String)] = lines.map(line => {val fileds = line.split("[|]")val startNum = fileds(2).toLongval endNum = fileds(3).toLongval province = fileds(6)(startNum, endNum, province)}).toArrayrules}
4.3.3.二分法查找
//二分法查找数据 返回查找到对应的索引,没有找到返回-1def binarySearch(lines: Array[(Long, Long, String)], ip: Long) : Int = {var low = 0var high = lines.length - 1while (low <= high) {val middle = (low + high) / 2if ((ip >= lines(middle)._1) && (ip <= lines(middle)._2))return middleif (ip < lines(middle)._1)high = middle - 1else {low = middle + 1}}-1}
4.3.4. 单机测试
def main(args: Array[String]): Unit = {//数据是在内存中val rules: Array[(Long, Long, String)] = readRules("d:/ip/ip.txt")//将 ip 地址转换成十进制val ipNum = ip2Long("223.242.48.0")//查找val index = binarySearch(rules, ipNum)//根据脚本到 rules 中查找对应的数据val tp = rules(index)val province = tp._3println(province)}
4.3.5.日志统计业务处理流程图
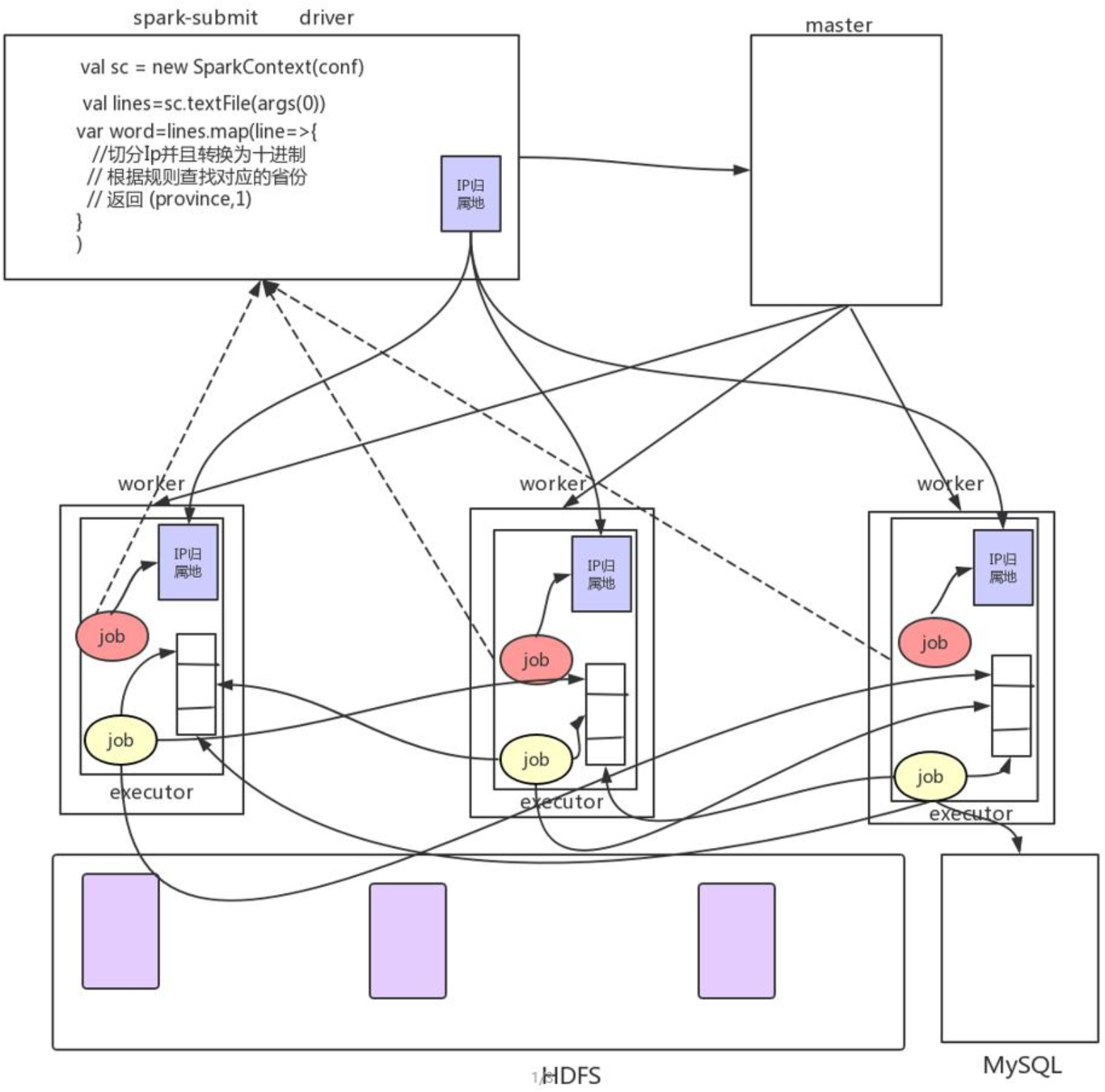
在我们的 Driver 编写客户端代码,实现 RDD 的封装和依赖关系的转换
- 在 Driver 端读取出 IP 归属地的数据到内存
- 把 Driver 端的 IP 的数据的广播到所有的 Executor 机器上面
在 Executor 执行任务把数据保存到 MySQL 数据库中
4.3.6. 读取本地的规则
注意:
规则是在本地读取的,也即是在 sparkSubmit(Driver)中读取的,而 runJob 时,只会发送RDD的运算逻辑到 Executor,读取的文件并不会主动发送过去
因此不能直接使用于 RDD 的操作中,会报错的
需要先将本地读取的文件内容进行广播,广播到各个 Executor 中,后续才能在 RDD 中使用//读取本地的规则进行数据的查找object IPLocaltion01 {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("IPLocaltion01").setMaster("local[4]")val sc = new SparkContext(conf)//第一步, 先把所有的规则读取出来val rules: Array[(Long, Long, String)] = MyUtils.readRules(args(0))// 把规则广播到对应的所有的 Executor 进程val rulesRef: Broadcast[Array[(Long, Long, String)]] = sc.broadcast(rules)//开始读取 hdfs 的中日志数据val lines: RDD[String] = sc.textFile(args(1))val func=(line:String)=>{//对每行日志进行处理//223.223.206.0|223.223.206.255|3755986432|3755986687| 亚 洲 | 中 国| 北 京 | 北 京|| 联 通 |110100|China|CN|116.405285|39.904989val fields: Array[String] = line.split("[|]")val ip=fields(1)val ipNum=MyUtils.ip2Long(ip)val rules: Array[(Long, Long, String)] = rulesRef.valuevar province="未知"val index:Int = MyUtils.binarySearch(rules,ipNum)if(index != -1){province=rules(index)._3}(province,1)}//映射操作val provinceAndOne: RDD[(String, Int)] = lines.map(func)//聚合操作val reduced: RDD[(String, Int)] = provinceAndOne.reduceByKey(_+_)//打印收集结果println(reduced.collect().toBuffer)sc.stop()}}
4.3.7.读取 HDFS 文件系统的规则
读取HDFS的内容都是在各个Executor上的,Driver不会实际运行RDD
存在问题:各个Executor 读取的HDFS文件,读取的时文件的区块,并不是 ip地域规则的完整文件,拿这个去匹配的话,会导致大量的ip匹配不上
解决方法
- 各个 Executor 读取完后,将读取的RDD归拢到Driver,再有Driver进行广播到各个Executor,进行后续的计算
操作
- textFile —> collect —> broadcast ```scala package day04.cn.wolfcode.spark import org.apache.spark.broadcast.Broadcast import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext}
object IPLocaltion02 { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(“IPLocaltion02”).setMaster(“local[4]”) val sc = new SparkContext(conf) //第一步, 从 HDFS 文件系统读取规则并且回收到 Driver 端 val ipRulesLines: RDD[String] = sc.textFile(args(0)) val ipRulesRDD: RDD[(Long, Long, String)] = ipRulesLines.map(line => { val fields: Array[String] = line.split(“[|]”) val startNum = fields(2).toLong val endNum = fields(3).toLong val province = fields(6) (startNum, endNum, province) }) val ipRules: Array[(Long, Long, String)] = ipRulesRDD.collect() val ipRulesRef: Broadcast[Array[(Long, Long, String)]] = sc.broadcast(ipRules) val func=(line:String)=>{ //对每行日志进行处理 //223.223.206.0|223.223.206.255|3755986432|3755986687| 亚 洲 | 中 国| 北 京 | 北 京|| 联 通|110100|China|CN|116.405285|39.904989 val fields: Array[String] = line.split(“[|]”) val ip=fields(1) val ipNum=MyUtils.ip2Long(ip) val rules: Array[(Long, Long, String)] = ipRulesRef.value var province=”未知” val index:Int = MyUtils.binarySearch(rules,ipNum) if(index != -1){ province=rules(index).3 } (province,1) } val lines: RDD[String] = sc.textFile(args(1)) //映射操作 val provinceAndOne: RDD[(String, Int)] = lines.map(func) //聚合操作 val reduced: RDD[(String, Int)] = provinceAndOne.reduceByKey(+_) //打印收集结果 println(reduced.collect().toBuffer) sc.stop() } }
<a name="RNdyv"></a>### 4.3.8. 保存数据到 MySQL导入连接驱动程序```xml<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.38</version></dependency>
实现代码
//保存数据到 MySQL 数据库reduced.foreachPartition(it=>MyUtils.data2MySQL(it))

若有收获,就点个赞吧
0 人点赞
