3. Spark SQL
3.1. Spark SQL 概述
3.2.1.Spark SQL 是什么
Spark SQL 是 Spark 用来处理结构化数据的一个模块,它提供了一个编程抽象叫做 DataFrame 并且作为分布式 SQL 查询引擎的作用。
3.2.2.为什么要学习 Spark SQL
我们已经学习了 Hive,它是将 Hive SQL 转换成 MapReduce 然后提交到集群上执行,大大简化了编写MapReduce 的程序的复杂性,由于 MapReduce 这种计算模型执行效率比较慢。所有 Spark SQL 的应运而生,它是将 Spark SQL 转换成 RDD,然后提交到集群执行,执行效率非常快!
3.2.3.Spark SQL 的特点
- 易整合

- 统一的数据访问方式

- 兼容 Hive
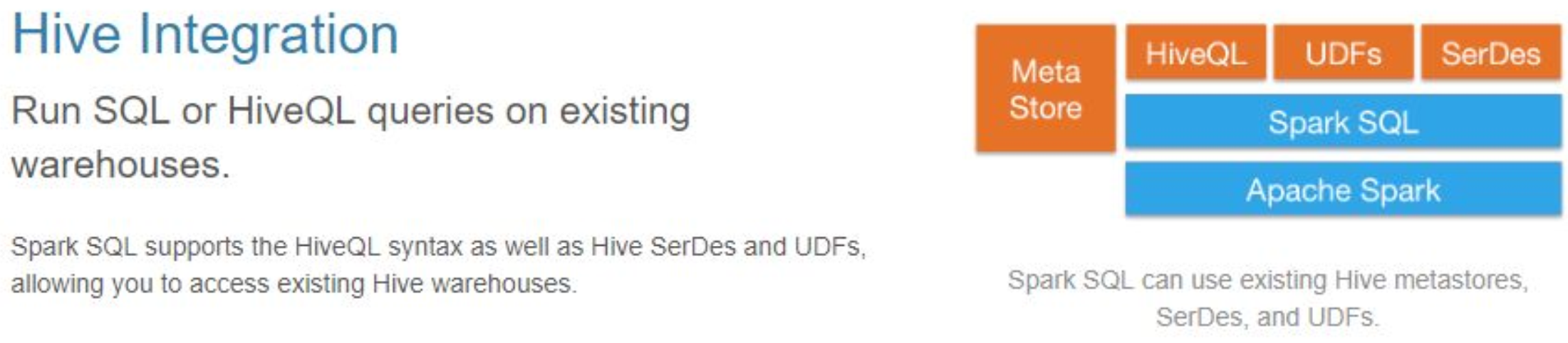
- 标准的数据连接

SparkSQL 支持两种编程 API
- SQL 方式
- DataFrame 的方式(DSL)
3.3. DataFrame
3.3.1.DataFrame 是什么
与 RDD 类似,DataFrame 也是一个分布式数据容器。
DataFrame 更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即 schema。
同时,与 Hive 类似,DataFrame 也支持嵌套数据类型(struct、array 和 map)。
从 API 易用性的角度上 看,DataFrame API 提供的是一套高层的关系操作,比函数式的RDD API 要更加友好,门槛更低。
由于与 R 和 Pandas 的 DataFrame 类似,Spark DataFrame 很好地继承了传统单机数据分析的开发体验。
DataFrame 里面存放的结构化数据的描述信息,DataFrame 要有表头(表的描述信息),描述了有多少列,每一列数叫什么名字、什么类型、能不能为空
DataFrame 是特殊的 RDD(RDD+Schema 信息就变成了 DataFrame)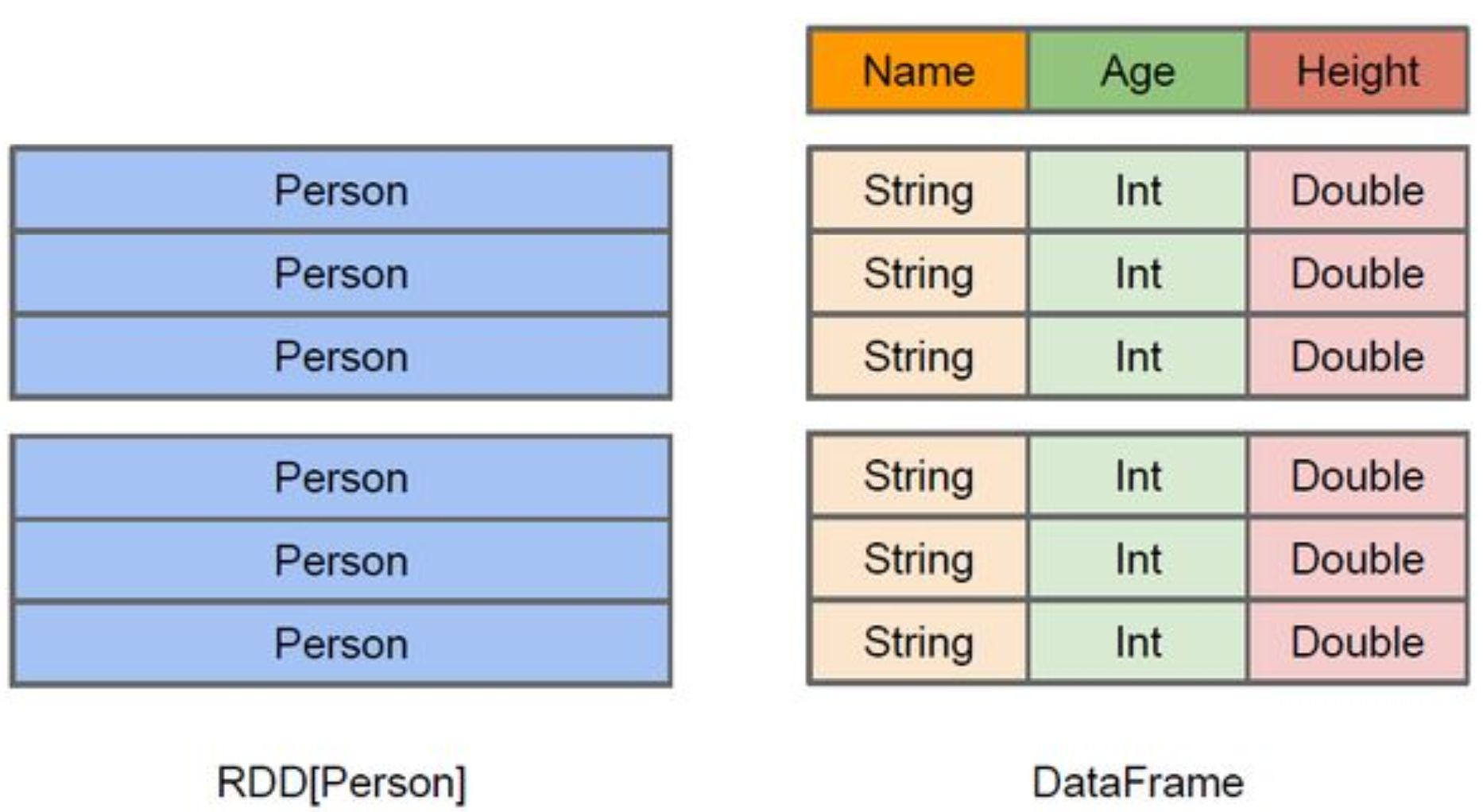
3.4. 入门程序
我们需要使用 Spark SQL,需要导入对应的 jar 包 ```javaorg.apache.spark spark-sql_2.11 ${spark.version}
SparkSQL 现在有两个版本<br />SparkSQL 1.x 和 2.x 的编程 API 有一些变化,企业中都有使用,所以两种方式都讲<a name="OnKnM"></a>### 3.4.1.SparkSQL1.x 的方式SQL 方式<br />创建一个 SQLContext1. 创建 `sparkContext`,然后再创建 `SQLContext` --> SparkSQL 1.x 版本使用1. 先创建 RDD,对数据进行清洗,然后关联 case class,**将非结构化数据转换成结构化数据**1. 导入隐式转换,显示的调用 `toDF` 方法将 RDD 转换成 DataFrame4. 注册临时表(视图)4. 执行 SQL(Transformation,lazy)4. 显示SQL执行结果 result.show()4. 关闭 sc```scalaobject SparkSQLDemo01 {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("SparkSQLDemo01").setMaster("local[4]")val sc = new SparkContext(conf)val sqlContext = new SQLContext(sc)// 读取数据,生成普通的RDDval lines: RDD[String] = sc.textFile(args(0))val userRDD: RDD[User] = lines.map(line => {val fields: Array[String] = line.split(" ")val id = fields(0).toIntval name = fields(1)val age = fields(2).toIntUser(id, name, age)})//导入隐式转换,调用 toDF 将普通RDD转成DFimport sqlContext.implicits._val df: DataFrame = userRDD.toDF()//注册临时表df.registerTempTable("t_user")//开始进行编程操作val result: DataFrame = sqlContext.sql("select id,name,age from t_user order by age desc")//查看结果result.show()sc.stop()}}//定义一个样例类case class User(id:Int,name:String,age:Int);
使用默认的 Row 类型
- 不用自定义样例类,直接使用 sparkSQL提供的Row类型来装处理好的结构化数据
- 这种方式需要定义一个 schema
- 将 schema 和 row 关联起来
通过 createDataFrame 来创建 DF,而不是使用 toDF ```scala object SparkSQLDemo02 { def main(args: Array[String]): Unit = { val conf: SparkConf =\ new SparkConf().setAppName(“SparkSQLDemo02”).setMaster(“local[4]”) val sc = new SparkContext(conf) val sqlContext = new SQLContext(sc) val lines: RDD[String] = sc.textFile(args(0)) val userRDD: RDD[Row] = lines.map(line => {
val fields: Array[String] = line.split(" ")val id = fields(0).toIntval name = fields(1)val age = fields(2).toIntRow(id, name, age)
})
//结果类型,其实就是表头,用于描述 DataFrame val schema: StructType = StructType(List(
StructField("id", IntegerType),StructField("name", StringType),StructField("age", IntegerType)
))
//将 RowRDD 关联 Schema val df: DataFrame = sqlContext.createDataFrame(userRDD,schema)
//把 DataFrame 先注册临时表 df.registerTempTable(“t_user”) //书写 SQL(SQL 方法应其实是 Transformation) val result: DataFrame = sqlContext.sql(“SELECT * FROM t_user ORDER BY age asc”) //查看结果(触发 Action) result.show() sc.stop() } }
DSL 方式1. 创建 sparkContext,然后再创建 SQLContext1. 先创建 RDD,对数据进行整理,然后关联 Row,将非结构化数据转换成结构化数据1. 定义 schema1. 调用 sqlContext 的 createDataFrame 方法1. 调用 DSL 的方法 --> 类似于函数式,拼接成SQL语句1. 执行 Action注意:- 不用创建临时表```scalapackage day06.cn.wolfcode.spark.sqlimport org.apache.spark.rdd.RDDimport org.apache.spark.sql.types._import org.apache.spark.sql.{DataFrame, Dataset, Row, SQLContext}import org.apache.spark.{SparkConf, SparkContext}object SparkSQLDemo03 {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("SparkSQLDemo03").setMaster("local[4]")val sc = new SparkContext(conf)val sqlContext = new SQLContext(sc)val lines: RDD[String] = sc.textFile(args(0))val userRDD: RDD[Row] = lines.map(line => {val fields: Array[String] = line.split(" ")val id = fields(0).toIntval name = fields(1)val age = fields(2).toIntRow(id, name, age)})//结果类型,其实就是表头,用于描述 DataFrameval schema: StructType = StructType(List(StructField("id", IntegerType),StructField("name", StringType),StructField("age", IntegerType)))//将 RowRDD 关联 Schemaval df: DataFrame = sqlContext.createDataFrame(userRDD,schema)// DSLval df1: DataFrame = df.select("id","name","age")import sqlContext.implicits._val df2: Dataset[Row] = df1.sort($"age" desc)//查看结果(触发 Action)df2.show()sc.stop()}}
3.4.2.SparkSQL2.x 的方式
sql 方式
- SparkSQL2.x 使用的不是 sqlContext,而是 SparkSession
SparkContext 通过 SparkSession来获取 ```scala object SparkSQLTest01 { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName(“SparkSQLTest01”).setMaster(“local[4]”) val sc = new SparkContext(conf)
//Spark SQL2.x 的执行入口 val sparkSession: SparkSession = SparkSession.builder().appName(“SparkSQLDemo01”).master(“local[4”).getOrCreate() val lines: RDD[String] = sparkSession.sparkContext.textFile(args(0)) //将数据进行整理 val rowRDD: RDD[Row] = lines.map(line => {
val fields = line.split(" ")val id = fields(0).toIntval name = fields(1)val age = fields(2).toIntRow(id, name, age)
}) //结果类型,其实就是表头,用于描述 DataFrame val schema: StructType = StructType(List(
StructField("id", IntegerType),StructField("name", StringType),StructField("age", IntegerType)
)) val df: DataFrame = sparkSession.createDataFrame(rowRDD,schema) df.createTempView(“v_user”)
val df2: DataFrame = sparkSession.sql(“select id,name,age from v_user where age > 20 order by age asc”) df2.show() //关闭资源 sparkSession.stop() } }
DSL 方式```scalaobject SparkSQLTest01 {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("SparkSQLTest01").setMaster("local[4]")val sc = new SparkContext(conf)//Spark SQL2.x 的执行入口val sparkSession: SparkSession = SparkSession.builder().appName("SparkSQLDemo01").master("local[4]").getOrCreate()val lines: RDD[String] = sparkSession.sparkContext.textFile(args(0))//将数据进行整理val rowRDD: RDD[Row] = lines.map(line => {val fields = line.split(" ")val id = fields(0).toIntval name = fields(1)val age = fields(2).toIntRow(id, name, age)})//结果类型,其实就是表头,用于描述 DataFrameval schema: StructType = StructType(List(StructField("id", IntegerType),StructField("name", StringType),StructField("age", IntegerType)))val df: DataFrame = sparkSession.createDataFrame(rowRDD,schema)val df1: DataFrame = df.select("id","name","age")//导入隐式转换import sparkSession.implicits._val rdd2: Dataset[Row] = df1.where($"age" > 20).orderBy($"age" desc)rdd2.show()//关闭资源sparkSession.stop()}}
4. Spark SQL 的 WordCount
SparkSQL 2.x
object DataSetWordCount {def main(args: Array[String]): Unit = {val sparkSession = SparkSession.builder().appName("sparkSQL2WordCount").master("local[2]").getOrCreate()val words: RDD[String] = sparkSession.sparkContext.textFile("h:/wordCount/wordCount.txt")val rdd2 = words.flatMap(_.split(" ")).map(word => {Row(word)})val schema: StructType = StructType(List(new StructType("value", StringType)))val df = sparkSession.createDataFrame(radd2, schema)// 建临时表df.createTempView("v_word")// 写sql并执行val df2 = sparkSession.sql("select value, count(value) as ct from v_word group by value order by ct desc")df2.showsparkSession.stop()}}
DSL
object DataSetWordCount {def main(args: Array[String]): Unit = {val sparkSession = SparkSession.builder().appName("sparkSQL2WordCount").master("local[2]").getOrCreate()val words: RDD[String] = sparkSession.sparkContext.textFile("h:/wordCount/wordCount.txt")val rdd2 = words.flatMap(_.split(" ")).map(word => {Row(word)})val schema: StructType = StructType(List(new StructType("value", StringType)))val df = sparkSession.createDataFrame(radd2, schema)//导入隐式转换import sparkSession.implicits._val df2 = df.select($"value").groupBy($"value").count().sort($"count" desc)df2.showsparkSession.stop()}}
1. Spark SQL 连接查询
1.1. 等值 join:商品的连接查询
现在有一个文件存放的是商品信息,另外有一个文件中存放的是商品类别信息,现在需要读取两个文件的信息,然后关联显示其中的所有的数据
- 分别加载两个文件
- 分别生成两个临时表
进行join ```scala object JoinDemo01 { def main(args: Array[String]): Unit = { val sqlSession: SparkSession = SparkSession.builder()
.appName("JoinDemo01").master("local[2]").getOrCreate()
// 加载商品类别信息 val ds: Dataset[String] = sqlSession.read.textFile(“D:/sparkdata/good/class.txt”) //导入隐式转换,ds 可以调用 RDD 的算子方法 import sqlSession.implicits._ val ds2: Dataset[(String, String)] = ds.map(line => {
val fields: Array[String] = line.split(",")val classSn = fields(0)val className = fields(1)(classSn, className)
}) //把 Dataset 类型的数据转换为 DataFrame 的类型 val classDF: DataFrame = ds2.toDF(“classSn”,”className”)
//加载商品信息表 val dsItem: Dataset[String] = sqlSession.read.textFile(“D:/sparkdata/good/item.txt”) val ds3: Dataset[(String, String, String, Int)] = dsItem.map(line => {
val fields: Array[String] = line.split(",")val itemSn = fields(0)val itemName = fields(1)val classId = fields(2)val price = fields(3).toInt(itemSn, itemName, classId, price)
}) val itemDF: DataFrame = ds3.toDF(“itemSn”,”itemName”,”classId”,”price”)
//方式一: 通过使用 sql 的方式 classDF.createTempView(“v_class”) itemDF.createTempView(“v_item”) val resutl: DataFrame = sqlSession.sql(“ select * from v_class join v_item on classId = classSn”) resutl.show()
//方式二: 通过 dataFrame 的 API import org.apache.spark.sql.functions._ val result: DataFrame = itemDF.join(classDF,$”classId” === $”classSn”,”left_outer”) result.show() sqlSession.stop() } }
注意事项:<br /><br /><br /><a name="giqAb"></a>## 1.2. 不等值 join:利用 SQL 计算 IP 归属地<a name="KM2ek"></a>### 1.2.1.使用 join 连接方式- 在 join 的连接条件 on 中,可以使用不等值条件 `**ip>=startNum and ip <= endNum**````scala//思路// 把 ip 规则和日志信息加载到我们的表中, 通过 sql 进行转换object IPLocation01 {def main(args: Array[String]): Unit = {val sqlSession: SparkSession = SparkSession.builder().master("local[2]").appName("IPLocation01").getOrCreate()import sqlSession.implicits._//加载 IP 规则val ipDS: Dataset[String] = sqlSession.read.textFile("d:/ip/ip.txt")val ipDS2: Dataset[(Long, Long, String)] = ipDS.map(line => {val fields: Array[String] = line.split("[|]")val startNum = fields(2).toLongval endNum = fields(3).toLongval province = fields(6)(startNum, endNum, province)})val ipDF: DataFrame = ipDS2.toDF("startNum","endNum","province")//ipDF.show()//加载读取日志文件val logDS: Dataset[String] = sqlSession.read.textFile("d:/ip/access.log")val logDS2: Dataset[Long] = logDS.map(line => {val fields: Array[String] = line.split("[|]")val ipAddr =MyUtils.ip2Long(fields(1))ipAddr})val logDF: DataFrame = logDS2.toDF("ip")//方式一: sql 方式ipDF.createTempView("v_rule")logDF.createTempView("v_log")val result: DataFrame = sqlSession.sql("select province, count(1) ct from v_log join v_rule on (ip>=startNum and ip <= endNum) group by province order by ct desc")result.show()//方式二:dsl:使用 df 的 api 方式import org.apache.spark.sql.functions._val result2: DataFrame = ipDF.join(logDF,$"ip" >= $"startNum" and $"ip" <= $"endNum").select($"province").groupBy($"province").count().orderBy($"count" desc)result2.show()sqlSession.stop()}}
缺点
- 这种方式效率比较低,因为每次都对于我们的日志解析都需要去连接 ip 规则进行查询连接
如果需要提高我们的运行效率,可以使用我们的 ip 广播的方式
1.2.2.使用 IP 规则广播 + UDF,避免 join 操作
- 先查出 ip 规则,collect 到 Driver 端,然后广播到各个 Executor
- 查询出 ip
定义一个 udf ,从广播中拿到 IP 规则,匹配返回省份 ```scala //思路 // 把 ip 规则和日志信息加载到我们的表中, 通过 sql 进行转换 object IPLocation02 { def main(args: Array[String]): Unit = { val sqlSession: SparkSession = SparkSession.builder()
.master("local[2]").appName("IPLocation02").getOrCreate()
import sqlSession.implicits._
//加载 IP 规则 val lines: RDD[String] = sqlSession.sparkContext.textFile(“d:/ip/ip.txt”) val ipDS2: RDD[(Long, Long, String)] = lines.map(line => {
val fields: Array[String] = line.split("[|]")val startNum = fields(2).toLongval endNum = fields(3).toLongval province = fields(6)(startNum, endNum, province)
}) val ipRules: Array[(Long, Long, String)] = ipDS2.collect() //广播到 executor val ipRuleRef: Broadcast[Array[(Long, Long, String)]] = sqlSession.sparkContext.broadcast(ipRules) //ipDF.show()
//加载读取日志文件 val logDS: Dataset[String] = sqlSession.read.textFile(“d:/ip/access.log”) val logDS2: Dataset[Long] = logDS.map(line => {
val fields: Array[String] = line.split("[|]")val ipAddr = MyUtils.ip2Long(fields(1))ipAddr
}) val logDF: DataFrame = logDS2.toDF(“ip”)
//定义一个 udf 自定义转换函数 def ip2province(ip:Long)={
val value: Array[(Long, Long, String)] = ipRuleRef.valuevar province="未知"val index: Int = MyUtils.binarySearch(value,ip)if(index != -1){province=value(index)._3}province
}
//注册 udf 函数 sqlSession.udf.register(“ip2province”,ip2province _)
//方式一: sql 方式 logDF.createTempView(“v_log”) val result: DataFrame = sqlSession.sql(“select province,count(1) ct from (select ip2province(ip) province from v_log) tmp group by province order by ct desc “) result.show()
//方式二: dataframe 的方式 logDF.select(callUDF(“ip2province”,$”ip”) as “province”).groupBy($”province”).count().orderBy($”count” desc).show() sqlSession.stop() } }
<a name="Kms1C"></a># 2. UDF 自定义函数对于用户自定义函数,在 Hive 中分为三种- **UDF (User Defined Funciton)**- 输入一行,返回一个结果,**一对一返回**- 方式1. 定义一个普通函数1. 注册```scala//定义一个 udf 自定义转换函数def ip2province(ip:Long)={val value: Array[(Long, Long, String)] = ipRuleRef.valuevar province="未知"val index: Int = MyUtils.binarySearch(value,ip)if(index != -1){province=value(index)._3}province}//注册 udf 函数sqlSession.udf.register("ip2province",ip2province _)
- UDTF
- 输入一行,返回多行数据
- Spark 中没有 UDTF 函数
- Spark 自带的 flatMap 即可实现该功能
- UDAF(User Defined Aggregate Function)
- 输入多行,返回一行数据,为聚合函数
- 主要包括 aggregate(聚合)、count、sum
- 复杂的业务,我们需要指定 UDAF 函数
- 方式
- 定一个类,继承
UserDefinedAggregateFunction - 覆写方法
- 定一个类,继承
- 使用
- 创建该类对象
- 和使用 UDF 一样使用
定义一个函数,用于计算几何平均数
package day07.cn.wolfcode.spark.joinimport java.lang.Longimport org.apache.spark.sql.{Dataset, Row, SparkSession}import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}import org.apache.spark.sql.types._object UdafDemo {def main(args: Array[String]): Unit = {val sqlSession = SparkSession.builder().appName("JoinTest").master("local[*]").getOrCreate()//创建一个 udaf 的对象实例val geomean = new GeoMean//生成一个 1 到 10 的序列 Datasetval range: Dataset[Long] = sqlSession.range(1,11)//方式一: sql 方式//注册函数sqlSession.udf.register("geomean",geomean)//将 range 这个 Dataset[Long]注册成视图range.createTempView("v_range")val result = sqlSession.sql("SELECT geomean(id) result FROM v_range")result.show()//方式二: dataFrame 的 APIimport org.apache.spark.sql.functions._import sqlSession.implicits._range.select(callUDF("geomean",$"id")).show()range.agg(geomean($"id").as("gm"))sqlSession.stop()}}class GeoMean extends UserDefinedAggregateFunction{//输入数据的类型override def inputSchema: StructType = StructType(List(new StructField("value",DoubleType)))//产生中间结果的数据类型override def bufferSchema: StructType = StructType(List(//相乘之后返回的积new StructField("product",DoubleType),//参与运算的数字个数new StructField("count",LongType)))//最终发返回的结果类型override def dataType: DataType = DoubleType//确保数据一致性override def deterministic: Boolean = true//指定初始值override def initialize(buffer: MutableAggregationBuffer): Unit = {//相乘的初始值buffer(0)=1.0//参与运算的数字的个数的初始值buffer(1)=0L}//每有一条数据参与运算就更新一下中间结果(update 相当于在每一个分区中的运算)override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {//每有一个数字参与运算就进行相乘(包含中间结果)buffer(0) = buffer.getDouble(0) * input.getDouble(0)//参与运算数据的个数也有更新buffer(1) = buffer.getLong(1) + 1L}//全局聚合override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {//每个分区计算的结果进行相乘buffer1(0) = buffer1.getDouble(0) * buffer2.getDouble(0)//每个分区参与预算的中间结果进行相加buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)}//计算最终的结果override def evaluate(buffer: Row): Any = {math.pow(buffer.getDouble(0), 1.toDouble / buffer.getLong(1))}}
3. Dataset 和 DataFrame
Dateset 是 spark1.6 以后推出的新的 API,也是一个分布式数据集,于 RDD 相比,保存了跟多的描述信息,概念上等同于关系型数据库中的二维表,基于保存了跟多的描述信息,spark 在运行时可以被优化。
Dateset 里面对应的的数据是强类型的,并且可以使用功能更加丰富的 lambda 表达式,弥补了函数式编程的一些缺点,使用起来更方便
在 scala 中,DataFrame 其实就是 Dateset[Row]
3.1. Dataset 的特点
- 一系列分区
- 每个切片上会有对应的函数
- 依赖关系
- kv 类型 shuffle 也会有分区器
- 如果读取 hdfs 中的数据会感知最优位置
- 会优化执行计划,在执行真正的 task 任务之前会把程序调整到最优的状态
- 支持更加智能的数据源(jdbc,cvs,json,parquet)
3.2. Dataset 和 DateFrame 之间的转换
在我们通过读取到一个 Dataset 的数据类型的时候,我们可以通过方法toDF("name", "age")转换为一个 DataFrame 对象
对于 DataFrame 对象,我们具有比较好的一个数据格式和 Scheme 信息
对于 Dataset来说,一般就是使用一个列名 (value,id 等)来表示,如果 Dataset 存放的是一个元组或者集合,那么有可能通过_1,_2这样的格式来表示列名

4. SparkSQL 的数据处理
4.1. SparkSQL 的多种格式的输出
我们可以使用 SparkSQL 的 DataFrameWriter 对象完成对 JDBC,cvs,json,text,parquet 等多种格式的持久化操作
jdbc 持久化
- 第一种 ```scala // 追加写入 val props = new Properties() props.put(“user”,”root”) props.put(“password”,”admin”) itemDF.write.mode(“append”).jdbc(“jdbc:mysql://localhost:3306/bigdata”, “item”, props)
- 第二种```scala// 覆盖写入df.write.mode("overwrite").format("jdbc").options(Map("url"->"jdbc:mysql://lab202:3306/bigdata?characterEncoding=UTF-8","dbtable"->"item","user"->"root","password"->"admin")).save()
json 格式
会保留 schema 信息
itemDF.write.json("d:/sparkdata/json")
cvs 格式
不会保留 schema 信息
itemDF.write.csv("d:/sparkdata/csv")
parquet 格式
reslut.write.parquet("d:/sparkdata/parquet")
4.2. SparkSQK 的多种格式的输入
jdbc 格式
val item: DataFrame = spark.read.format("jdbc").options(Map("url" -> "jdbc:mysql://localhost:3306/bigdata","driver" -> "com.mysql.jdbc.Driver","dbtable" -> "logs","user" -> "root","password" -> "admin")).load()
json 格式
val jsons: DataFrame = spark.read.json("d:/sparkdata/json")
parquet 格式
val parquetLine: DataFrame = spark.read.parquet("d:/sparkdata/parquet")
1. SparkSQL 补充
1.1. 分窗函数的案例:各学科最受欢迎的老师
```scala object FavTeacher { def main(args: Array[String]): Unit = { val sqlSession: SparkSession = SparkSession.builder().appName(“FavTeacher”).master(“local[4]”).getOrCreate() val lines: Dataset[String] = sqlSession.read.textFile(“D:/sparkdata/topn/teacher.txt”) import sqlSession.implicits._ val subTeacherRDD: Dataset[(String, String)] = lines.map(line => {
// 字符串切割, x 是读取到的一行的内容val words: Array[String] = line.split("/")// 获取到每个教师的姓名val teacher = words(words.length - 1)// 获取到学科的信息val subject = words(words.length - 2)//返回一个元组信息(教师,1)(subject, teacher)
}) val df: DataFrame = subTeacherRDD.toDF(“sub”,”teacher”) df.createTempView(“v_sub_teacher”) val tempDf: DataFrame = sqlSession.sql(“select sub,teacher,count(1) ct from v_sub_teacher group by sub,teacher”) tempDf.createTempView(“v_sub_teacher_tmp”) sqlSession.sql(“select sub, teacher, ct, row_number() over(partition by sub order by ct desc ) sub_rk from v_sub_teacher_tmp “).show() sqlSession.sql(“select sub, teacher, ct, row_number() over(partition by sub order by ct desc ) sub_rk, row_number() over(order by ct desc) g_rk from v_sub_teacher_tmp “).show() sqlSession.stop() } }
分窗函数- over():对数据进行分窗,括号内的为分窗条件- partition by:分窗条件,如果为 partition by sub order by ct desc,表示按照学科进行分窗(分区),每个分区的数据按照 ct 字段进行降序排序- row_number():对每个分区内的数据进行编号,从1开始<a name="GI7q5"></a>## 1.2. Join 操作的细节目前我们的 SparkSQL 支持的 Join 的方式有三种- Broadcast Hash Join(很小表+大表)- Shuffle Hash(小表+大表)- Sort-Merge Join默认情况下,这三种 join 的方式是有 SparkSQL 自己根据表的数据大小以及当前的运行环境进行自由调配<a name="Gz702"></a>### 1.2.1.Hash Join 的概念先来看看这样一条 SQL 语句:`select * from order,item where item.id = order.i_id`<br />很简单一个 Join 节点,参与 join 的两张表是 item 和 order,join key 分别是 item.id 以及 order.i_id。<br />现在假设这个 Join 采用的是 hash join 算法,整个过程会经历三步:1. 确定 Build Table 以及 Probe Table:这个概念比较重要,Build Table使用 join key构建Hash Table,而 Probe Table 使用 join key 进行探测,探测成功就可以 join 在一起。通常情况下,小表会作为 Build Table,大表作为 Probe Table。此事例中 item 为 Build Table,order 为 Probe Table。1. 构建 Hash Table:依次读取 Build Table(item)的数据,对于每一行数据根据 join key(item.id)进行 hash,hash 到对应的 Bucket,生成 hash table 中的一条记录。数据缓存在内存中,如果内存放不下需要 dump 到外存。- Hash Table 可以理解为 Build Table 的索引,3. 探测:再依次扫描 Probe Table(order)的数据,**对 Probe Table 的 join key 使用相同的 hash 函数映射 Hash Table 中的记录**,映射成功之后再检查 join 条件(item.id = order.i_id)(存在不同值的 hash 值相同,因此需要额外检查一下值),如果匹配成功就可以将两者 join 在一起。<br />这里有两个小问题需要关注1. hash join 性能如何?很显然,hash join 基本都只扫描两表一次,可以认为 o(a+b),较之最极端的笛卡尔集运算 a*b,不知甩了多少条街1. 为什么 Build Table 选择小表?道理很简单,因为构建的 Hash Table 最好能全部加载在内存,效率最高;这也决定了 hash join 算法只适合至少一个小表的 join 场景,对于两个大表的 join 场景并不适用;上文说过,**hash join 是传统数据库中的单机 join 算法**,在分布式环境下需要经过一定的**分布式改造**,说到底就是尽可能利用分布式计算资源进行并行化计算,提高总体效率。<br />hash join 分布式改造一般有两种经典方案:1. **broadcast hash join**:将其中一张小表广播分发到另一张大表所在的分区节点上,分别并发地与其上的分区记录进行 hash join。broadcast 适用于小表很小,可以直接广播的场景。1. **shuffler hash join**:一旦小表数据量较大,此时就不再适合进行广播分发。这种情况下,可以根据 join key 相同必然分区相同的原理,将两张表分别按照 join key 进行重新组织分区,这样就可以将 join 分而治之,划分为很多小 join,充分利用集群资源并行化。<a name="y7OTw"></a>### 1.2.2.Broadcast Hash Join1. broadcast 阶段:将小表广播分发到大表所在的所有主机。广播算法可以有很多,最简单的是先发给 driver,driver 再统一分发给所有 executor;要不就是基于 bittorrete 的 p2p 思路;1. hash join 阶段:在每个 executor 上执行单机版 hash join,小表映射,大表试探;默认情况下如果对于小表的大小不超过 10M,那么就会采用广播的方式, 其中默认的配置参数为 `spark.sql.autoBroadcastJoinThreshold` 默认值为 10M, 如果设置为-1,则表示禁用广播<br />总结:- Probe Table 根据分区,分到各个 Task 上- Build Table 整个表广播到各个 Executor 上- 没有涉及到 shuffle 的操作<a name="ZOppE"></a>### 1.2.3.Shuffle Hash Join在大数据条件下如果一张表很小,执行 join 操作最优的选择无疑是 broadcast hash join,效率最高。<br />但是一旦**小表数据量增大(但依旧是小表)**,广播所需内存、带宽等资源必然就会太大,broadcast hash join 就不再是最优方案。此时可以按照 join key 进行分区,根据 key 相同必然分区相同的原理,就可以将大表 join 分而治之,划分为很多小表的 join,充分利用集群资源并行化。<br /><br />如下图所示,shuffle hash join 也可以分为两步:1. shuffle 阶段:分别**将两个表按照 join key 进行分区**,将**相同 join key 的记录重分布到同一节点**,两张表的数据会被重分布到集群中所有节点。这个过程称为 shuffle1. hash join 阶段:每个分区节点上的数据单独执行**单机 hash join 算法**总结:- 两个表分别按照分区,分发到各个Task 上- **进行shuffle**,两个表依据 join key,重新进行分发(类似于 reduceByKey的shuffle过程,使用的是 hashPartitioner),相同 hash 值的份到一个 Executor 上- 在 Executor 上执行单机 hash join 算法配置使用 Shuffle Hash Join<br />`spark.sql.autoBroadcastJoinThreshold` 的值配置为`-1` 禁用广播- `sqlSession.config("spark.sql.autoBroadcastJoinThreshold", "-1")``spark.sql.join.preferSortMergeJoin` 的值配置为 `false`,禁用排序的合并的方式- `sqlSession.config("spark.sql.join.preferSortMergeJoin", "false")`<a name="uVt5O"></a>### 1.2.4.Sort-Merge JoinSparkSQL 对**两张大表 join **采用了全新的算法-**sort-merge join**,如下图所示,整个过程分为三个步骤1. shuffle 阶段:将两张大表**根据 join key 进行重新分区**,两张表数据会分布到整个集群,以便分布式并行处理(类似于 shuffle Hash join 操作)1. **sort 阶段**:对单个分区节点的两表数据,分别进行排序,**写入本地磁盘**1. **merge 阶段**:对排好序的两张分区表数据执行 join 操作。join 操作很简单,**分别遍历两个有序序列,碰到相同 join key 就 merge 输出,否则取更小一边**1. 排序后的数据就比较方便了配置使用 Sort-Merge Join<br />`spark.sql.autoBroadcastJoinThreshold` 的值配置为 `-1` 禁用广播- `sqlSession.config("spark.sql.autoBroadcastJoinThreshold", "1")`<a name="HeINu"></a># 2. SparkSQL 整合 Hive启动 Hive:- bin/spark-sql<a name="fioCk"></a>## 2.1. 基本操作<a name="qQmys"></a>### 2.1.1.创建表内部表:```sqlcreate table t2(id int,name string,age int,gender string)row format delimited fields terminated by ",";
外部表
create external table t3(id int,name string,age int,gender string)row format delimited fields terminated by ","location '/aa/bb/';
2.1.2.导入数据到表中
load data local inpath '/root/data/user.data.2' into table t1;
2.2. Spark 整合 Hive
2.2.1. 安装 MySQL 数据库,并且配置远程登录用户
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%'IDENTIFIED BY 'admin' WITH GRANT OPTION;FLUSH PRIVILEGES;
2.2.2. 添加 Hive 的配置文件 hive-site.xml
在 /root/apps/spark-2.1.1/conf 目录下面
<configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://lab153:3306/hive?createDatabaseIfNotExist=true</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>admin</value></property></configuration>
2.2.3.配置 HADOOP_HOME 环境变量
vi /etc/profile.d/hadoop.shexport HADOOP_HOME=/root/apps/hadoop-2.7.3export HADOOP_CONF_DIR=/root/apps/hadoop-2.7.3/etc/hadoopexport PATH=$PATH:$HADOOP_HOME/binsource /etc/profile
2.2.4.上传 mysql 的驱动包启动程序
启动命令
bin/spark-sql --master spark://lab150:7077--driver-class-path /root/mysql-connector-java-5.1.39
启动以后需要手动修改元数据中的一个表 DBS 中的 DB_LOCATION_URL 为
hdfs://lab150:9000/user/hive/spark-warehouse
2.3. 通过文件的方式使用 hive
bin/spark-sql -e “show databases;”bin/spark-sql -f “/root/hive.sql”
2.4. Spark 程序整合 Hive
2.4.1.在项目中导入对应的 pom 依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.11</artifactId><version>${spark.version}</version></dependency>
2.4.2.在项目中添加对应的配置文件
把 core-site.xml hdfs-site.xml hive-site.xml 这三个配置文件拷贝到项目的 resource 目录,配置好元数据的目录信息
2.4.3. 启用对 hive 的支持
在程序中调用 sqlSession 的 enableHiveSupport()启用对 hive 的支持
object HiveDemo {def main(args: Array[String]): Unit = {val sqlSession: SparkSession = SparkSession.builder().appName("JoinDemo01").master("local[2]").enableHiveSupport().getOrCreate()sqlSession.sql("select * from t1 ").show()sqlSession.stop()}}

若有收获,就点个赞吧
0 人点赞
