
 ">
">
参考同济大学赵兴明老师PPT以及《R语言实战(第2版)》
Ⅰ. 一元线性回归(Linear Regresion)
1. 线性回归
1.相关与回归:假设检验只能对样本之间的相关性进行定性分析,而回归分析可以对x和y的相关性进行定量分析
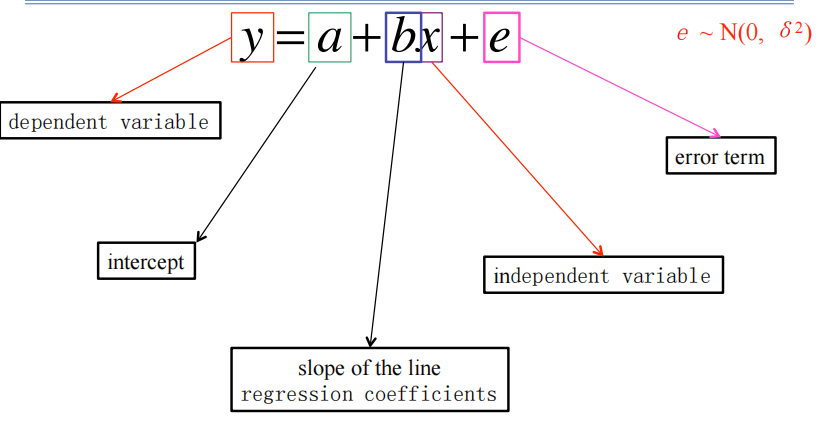
2.模型:b为回归系数[与one-way ANOVA类比]
2. 拟合回归曲线
1.原理:使误差总和(残差平方和)最小:即
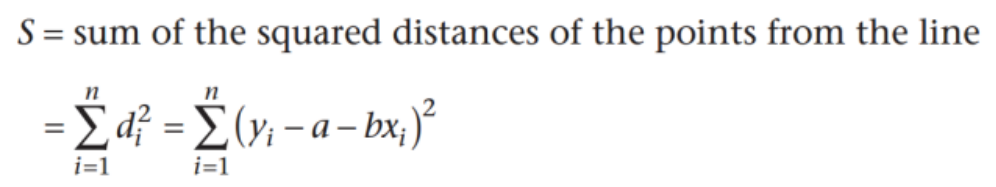
2.公式推导(通过求导,令残差总和最小)

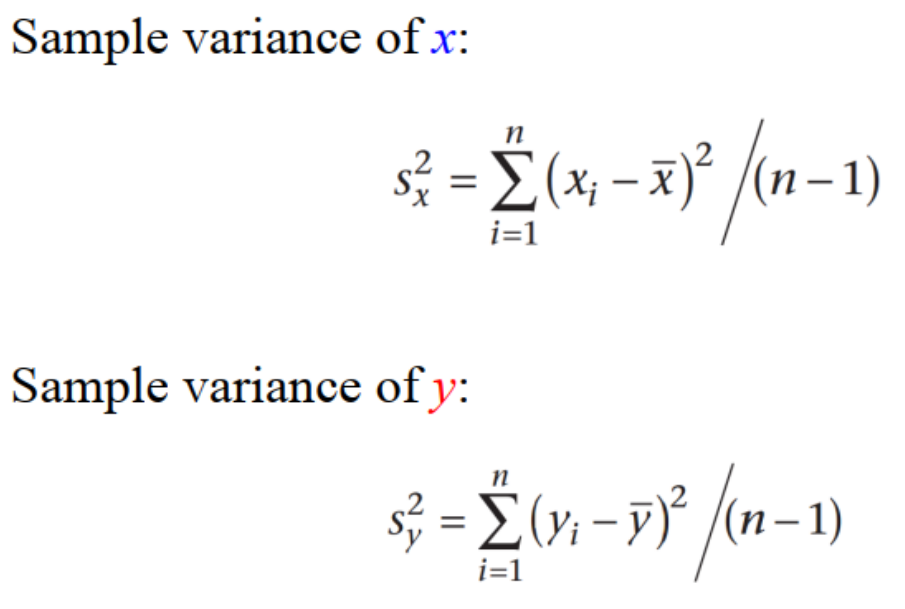
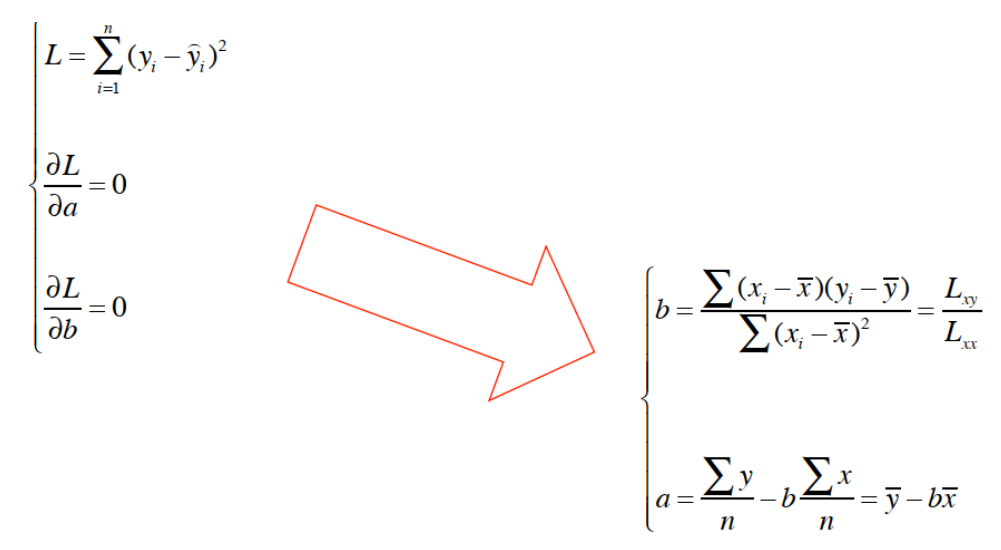
3.手动计算回归方程【step-by-dtep】

4.R——lm()函数
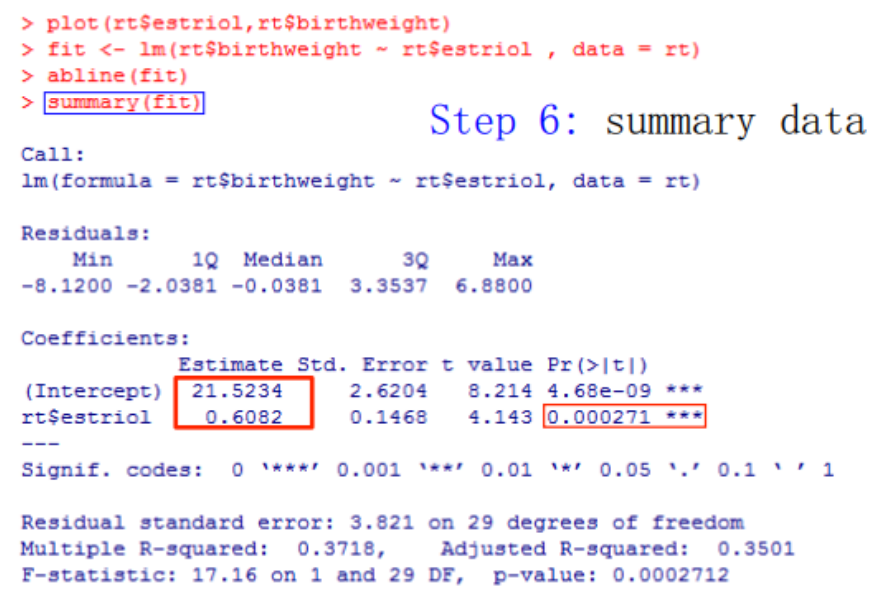
5.拟合回归线的步骤
(1)用R函数计算
#导入数据#绘制散点图,观察数据的分布特点> plot(x,y)#拟合回归方程> myfit <- lm(formula=Y~X1+X2+X3, data)#拟合回归线> abline(myfit)#分析拟合情况> summary(myfit) #可以模型相关参数和相关统计量> anova(myfit) #可以显示F检验的结果
(2)手动计算——Step-by-Step【这是一个完整的计算步骤】
6.拟合回归方程重要的函数

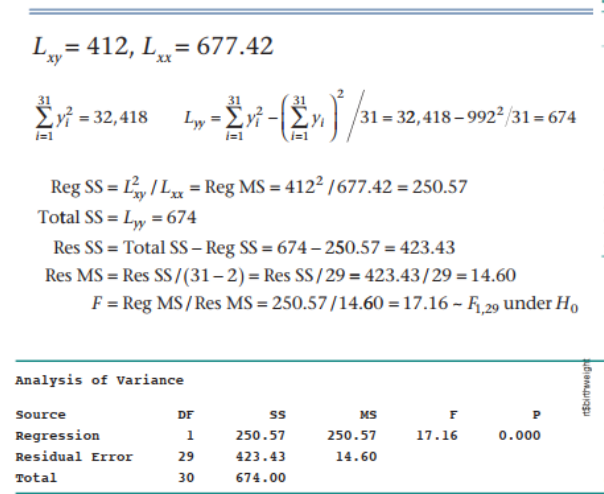
3. 回归线的拟合度检验——回归平方和(RegSS)大,残差平方和(ResSS)小
1.F单尾检验:总体平方和[Total SS]=回归平方和[Reg SS]+残差平方和[Res SS]
注:Reg SS、ResSS、TotalSS的计算有两种方法:①根据定义直接计算。②根据推导公式一步步计算。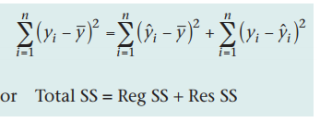
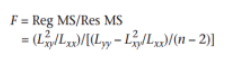
2.回归线的拟合优度——决定系数【R2】:可以用x来解释y的比例,越大越好(~1)

注:summary(lm())中包含F值和R2值。
3.t双尾检验:
我们认为,样本回归系数b使总体回归系数β的无偏估计,故可对b进行t检验。
Ⅱ. 非线性回归
1. 两种转换
1.线性变换
2.非线性转换

#输入并绘制数据> t <- seq(1,10)> subscribers=c(1.6,2.7,4.4,6.4,8.9,13.1,19.3,28.2,38.2,48.7)> plot(t,subscribers)#数据转换> plot(t,log(subscribers))> fit=lm(log(subscribers)~t)> abline(fit)> summary(fit)
2. 回归诊断——图形化验证功效模型
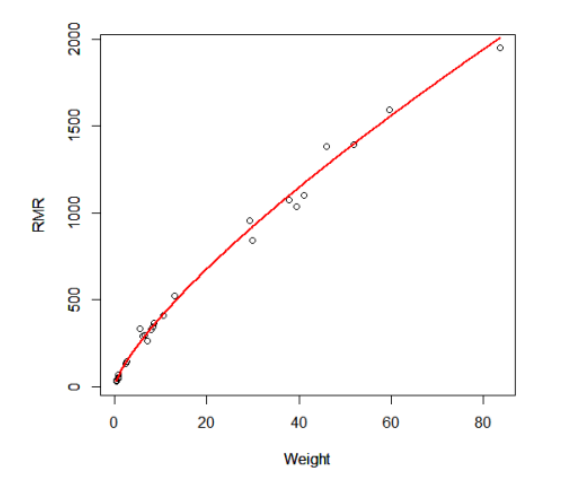
(1)根据拟合回归线判断
#数据点> plot(t,subscribers)#根据拟合的回归线生成回归线> range(t)> t=seq(1,10,0.1)> y=1.300827*exp(0.3774*t)#判断拟合程度> lines(t,y,type="l",lwd=2,col="red")
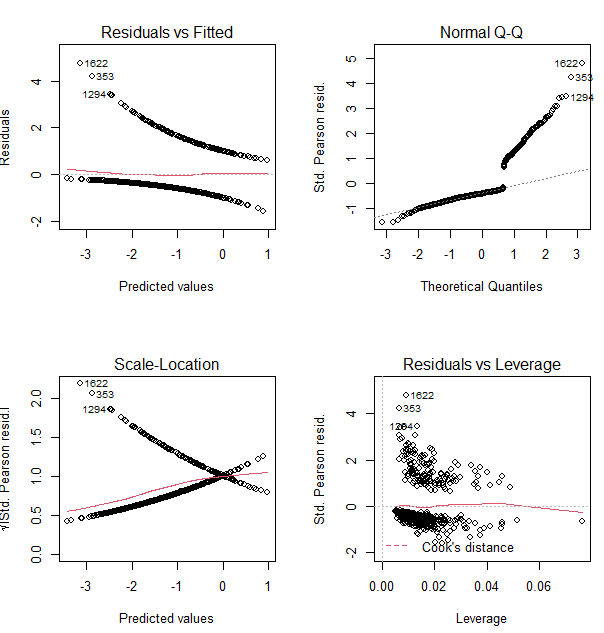
(2)标准方法——四幅诊断图
> par(mfrow=c(2,2))> plot(fit)
注:四幅诊断图分析
①左上【残差图与拟合图】:若因变量与自变量线性相关,那么残差值与拟合值应该没有任何关系。如果在图中发现两者之间具有曲线关系,这表示回归模型不是线性关系。
②右上【正态Q-Q图】:在正态分布对应的值下,标准化残差的概率图。若满足正态假设,那么图上的点应该落在呈45°角的直线上,否则,就违反了正态性假设(预测变量固定,因变量成正态分布,那么残差值也应该是一个均值为0的正态分布)。
③左下【位置尺度图】:若满足不变方差假设(因变量的方差不随自变量的水平不同而改变),则水平线周围的点应该随机分布。
④右下【残差与杠杆图】:从该图中可以鉴别离群点(预测效果不佳)、高杠杆指点和强影响点。
(3)car包
car包提供了大量的函数,大大增强了拟合和评价回归模型的能力
#分位数比较图> qqplot() #正态性检验#增强的散点图矩阵> scatterplotMatrix()
3. 样本(person)相关系数(r)
1.r,为两个变量之间的相关性提供了一种定量测度,|r|越大,两个变量之间的相关性就越强
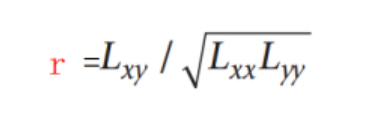
> Correlation(rt$Height,rt$FEV)
2.b. 样本相关系数r和回归系数b的关系
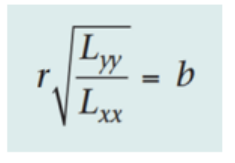
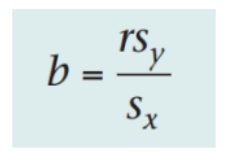
3.可视化特征值之间的关系——散点图矩阵(scatterplot matrix)
将一个散点图集合排列在一个网格中,包含着相互紧邻在一起的多种因素的图表。
> library(graphics)> pairs(rt$Height,rt$FEV)> install.packages("psych")> library(psych)> pairs.panels(rt$Height,rt$FEV)
手把手教线性回归分析(附R语言实例)
https://blog.csdn.net/tMb8Z9Vdm66wH68VX1/article/details/79544739
Ⅲ 多元线性回归
1. 多元线性回归模型
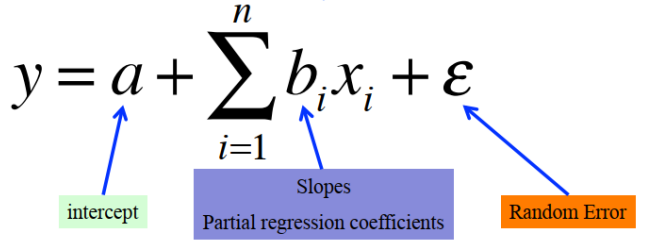
2. 拟合回归模型
> ff <- lm(y~x1+x2)> summary(ff)
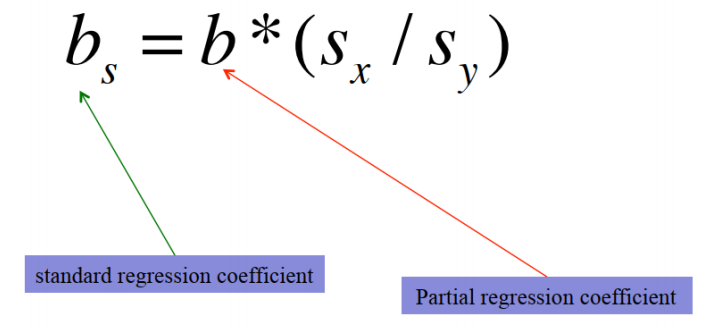
3. 变量权重的比较——标准化回归系数
4. 回归线的拟合度
1.F检验——整体的检验

2. t检验——评估不同自变量的贡献值

3.部分F检验——评估不同自变量的贡献值

5. 模型评估
不同的变量之间可能本身就存在一定的线性、掩盖等关系,因此可以对我们的模型进行简化。
#导入数据(lm()输入需要是一个数据框,而state.x77是一个矩阵,先进行转换)> states <- as.data.frame(state.x77[,c("murder","population","illiteracy","income","frost")])#多元回归分析,先检查变量之间的相关性> cor(states) #二变量之间的相关系数> library(car)> scatterplotMatrix(States) #散点图矩阵。非对角线区域绘制变量间的散点图,并添加平滑(loess)和线性拟合曲线。#对角线区域绘制每个变量的密度图和轴须图。#拟合模型> ff <- lm(murder~population+illiteracy+income+frost,data=states)#简化模型> summary(ff)> ff1 <- lm(murder~population+illiteracy,data=states)#评估模型之间的差异> anova(ff,ff1) #根据p-value值评判两个模型是否存在显著性差异
Ⅳ Logistic回归
【概念引入】
回归分析通过的是一系列连续性和/或类别型预测变量来预测正态分布的响应变量。但是当结果变量为类别型(二值变量/多分类变量)或者计数型时,不是正态分布时就无法进行线性回归分析。于是有了广义线性模型的概念,针对非正态因变量的分析。
【广义线性分析两种分析模型】
①Logistic回归——针对类别型因变量
②泊松回归——针对计数型因变量
1. 线性回归与逻辑回归
| 线性回归 | 逻辑回归 | |
|---|---|---|
| 解决的问题 | 回归问题 | 分类问题 |
| 变量类型 | 连续的变量 | 连续、离散、二值型 (不需要变量的分布、均方差等) |
| 自、因变量之间的关系 | 线性关系 | 非线性关系 |
| 结果呈现 | 直观表达变量之间的量化关系 | 通过概率来衡量结果的可能性 |
2. 逻辑回归模型
对于二元结果变量,每个X值下都是一个“案例”,我们只能衡量每种特定结果发生的概率。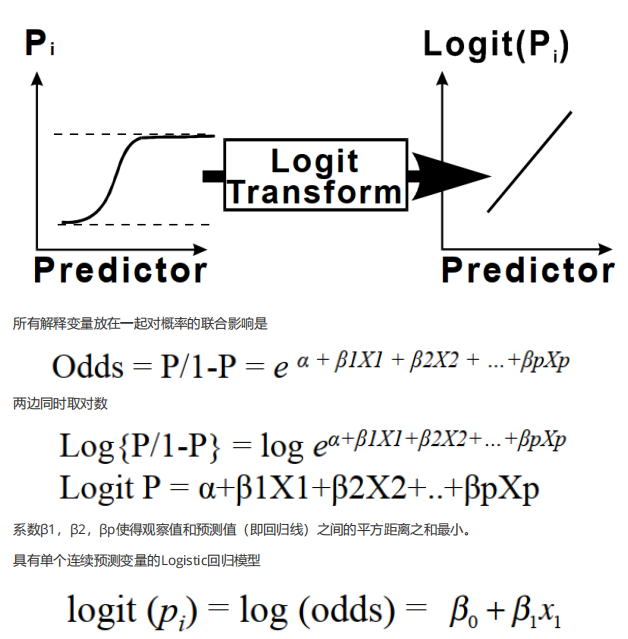
3. R中进行逻辑回归分析——glm()函数
> glm(formula,family=family(link=function),data=)#family 指概率分布和相应默认的连接函数(function)#常用的family:binomial(link = "logit")possion(link = "log")
4.标准分析流程
1.【逻辑分析】
#读取数据> install.packages("AER")> library(AER)> data(Affairs,packages="AER")> View(Affairs)> summary(Affairs)#将affairs转换为二值型因子——“是否有婚外情”> Affairs$ynaffair[Affairs$affairs>0] <- 1> Affairs$ynaffair[Affairs$affairs==0] <- 0> Affairs$ynaffair <- factor(Affairs$ynaffair,levels=c(0,1),labels=c("No","Yes"))> table(Affairs$ynaffair)No Yes451 150#进行Logistic回归分析> fit.full <-glm(ynaffair~gender+age+yearsmarried+children+religiousness+education+occupation+rating,data = Affairs,family = binomial())> summary(fit.full)Call:glm(formula = ynaffair ~ gender + age + yearsmarried + children +religiousness + education + occupation + rating, family = binomial(),data = Affairs)Deviance Residuals:Min 1Q Median 3Q Max-1.5713 -0.7499 -0.5690 -0.2539 2.5191Coefficients:Estimate Std. Error z value Pr(>|z|)(Intercept) 1.37726 0.88776 1.551 0.120807gendermale 0.28029 0.23909 1.172 0.241083age -0.04426 0.01825 -2.425 0.015301 *yearsmarried 0.09477 0.03221 2.942 0.003262 **childrenyes 0.39767 0.29151 1.364 0.172508religiousness -0.32472 0.08975 -3.618 0.000297 ***education 0.02105 0.05051 0.417 0.676851occupation 0.03092 0.07178 0.431 0.666630rating -0.46845 0.09091 -5.153 2.56e-07 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1(Dispersion parameter for binomial family taken to be 1)Null deviance: 675.38 on 600 degrees of freedomResidual deviance: 609.51 on 592 degrees of freedomAIC: 627.51Number of Fisher Scoring iterations: 4#简化模型> fit.reduce <-glm(ynaffair~+age+yearsmarried+religiousness+rating,data = Affairs,family = binomial())#使用anova()函数会两个模型进行比较,对于广义线性回归,可用卡方检验> anova(fit.reduce,fit.full,test = "Chisq")Analysis of Deviance TableModel 1: ynaffair ~ +age + yearsmarried + religiousness + ratingModel 2: ynaffair ~ gender + age + yearsmarried + children + religiousness +education + occupation + ratingResid. Df Resid. Dev Df Deviance Pr(>Chi)1 596 615.362 592 609.51 4 5.8474 0.2108
2.【解释模型参数】
#显示回归系数[log(Pi)]> coef(fit.full)(Intercept) gendermale age yearsmarried childrenyes1.37725816 0.28028665 -0.04425502 0.09477302 0.39767213religiousness education occupation rating-0.32472063 0.02105086 0.03091971 -0.46845426#进行e转换[Pi]> exp(coef(fit.full))(Intercept) gendermale age yearsmarried childrenyes3.9640180 1.3235091 0.9567099 1.0994093 1.4883560religiousness education occupation rating0.7227292 1.0212740 1.0314027 0.6259691
3.【预测变量】
#根据模型进行预测> testdata <- data.frame(rating=c(1,2,3,4,5),age=mean(Affairs$age),yearsmarried=mean(Affairs$yearsmarried),religiousness=mean(Affairs$religiousness))> testdata$prob <- predict(fit.reduce,newdata = testdata,type = "response")> testdatarating age yearsmarried religiousness prob1 1 32.48752 8.177696 3.116473 0.53022962 2 32.48752 8.177696 3.116473 0.41573773 3 32.48752 8.177696 3.116473 0.30967124 4 32.48752 8.177696 3.116473 0.22045475 5 32.48752 8.177696 3.116473 0.1513079
回归系数的含义:当其他预测变量不变时,一单位预测变量的变化可引起响应变量的变化。
5. 偏相关和多重相关
偏相关:感兴趣的两个变量之间的皮尔逊相关——r值,控制其他协变量
多重相关:y和所有变量的关系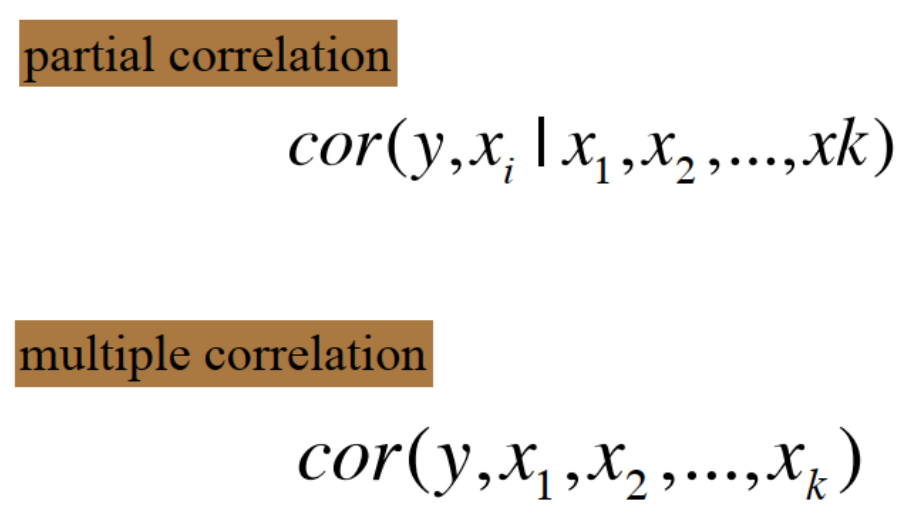
1.用R计算偏相关系数
> install.packages("ggm")> library(ggm)> #计算偏相关系数> pcor(c(1,5,2,3,6),cov(states))[1] 0.3462724
2.手动计算偏相关系数
Cor(y,x1)=sqrt(X1 Squared Partial Corr Typr Ⅱ)
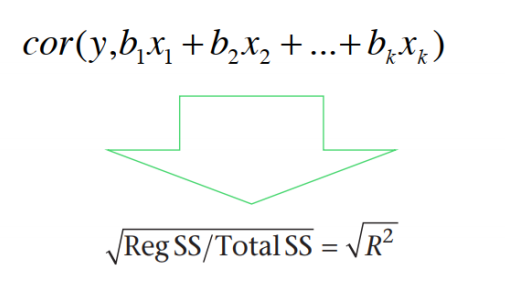
3.手动计算多重相关系数

若有收获,就点个赞吧
0 人点赞
