
总结
| 编号 | 检验类型 | 样本数量 | 检验类型 | 前提条件 | 统计检验量计算 | 检验代码【R】 | 置信区间 | 检验效力 | 样本量计算 |
|---|---|---|---|---|---|---|---|---|---|
| 1. | 参 数 检 验 |
单样本 |
均值检验 | 1. 总体方差已知 |
Z检验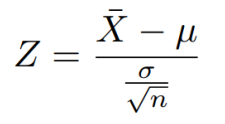 |
#计算对应z值的概率密度(Pr) >pnorm(q, lower.tail = TRUE) #计算z值 >qnorm(p,lower.tail = TRUE) #z检验 >z.test(x,alternative = “two.sided”, mu = 0, sigma.x = NULL,conf.level = 0.95) #检验样本是否符合正态分布 >shapiro.test(x) |
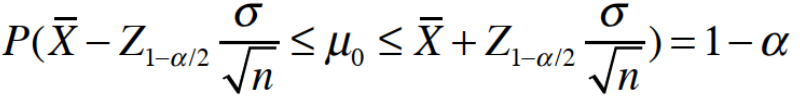 |
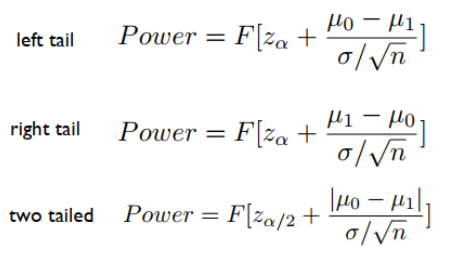 |
单边检验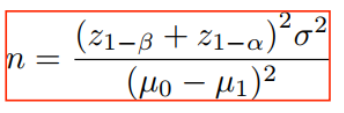 |
| 2. | 1. 总体方差未知 1. >30的大样本或总体服从正态分布的小样本 |
t检验 t = 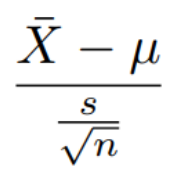 (df=n-1) |
#计算对应t值的概率密度(Pr) >pt(q, df, lower.tail = TRUE) #计算t值 >qt(p, df, lower.tail = TRUE) #t检验 >t.test(x,alternative=c(“two.sided”, “less”, “greater”) |
双边检验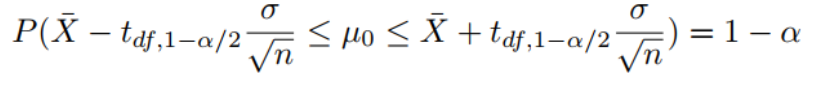 单边检验 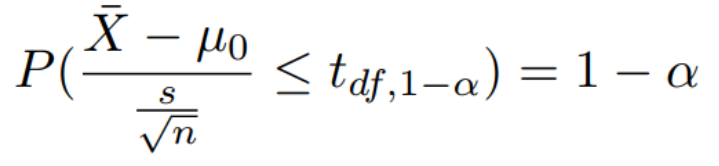 |
(|μ1-μ0|都是大的减小的)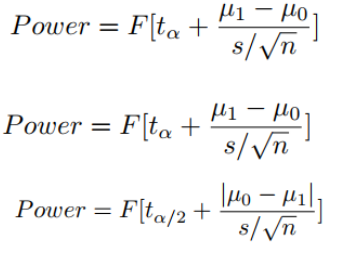 |
对于t检验的样本容量,由于t依赖于样本容量,可以使用z检验进行近似估计 | |||
| 3 | 方差检验 | 1. 总体服从正态分布 |
卡方检验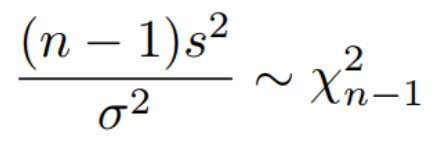 |
#计算对应X2值的概率密度(Pr) >pchisq(q, df, lower.tail = TRUE) #计算X2值 >qchisq(p, df, lower.tail = TRUE) #卡方检验 >chisq.test(X) |
双边检验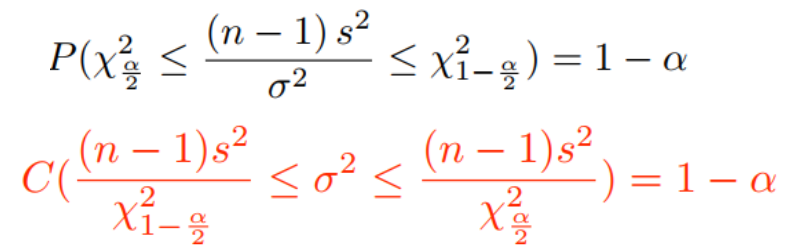 |
||||
| 4 | 比例检验 | 1. np>15 1. n(1-p)≥15 |
Z检验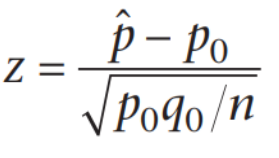 |
同1 | 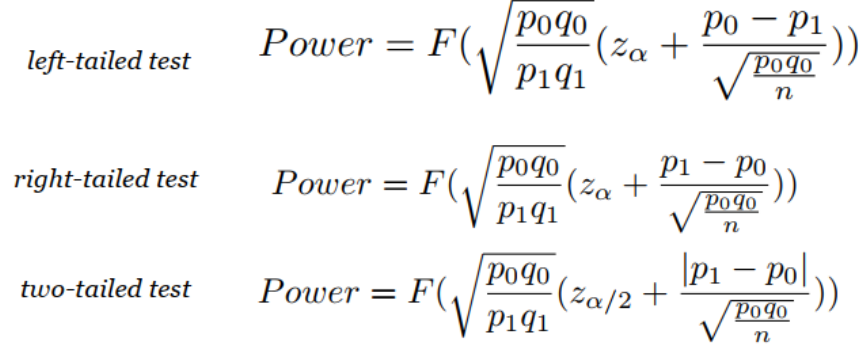 |
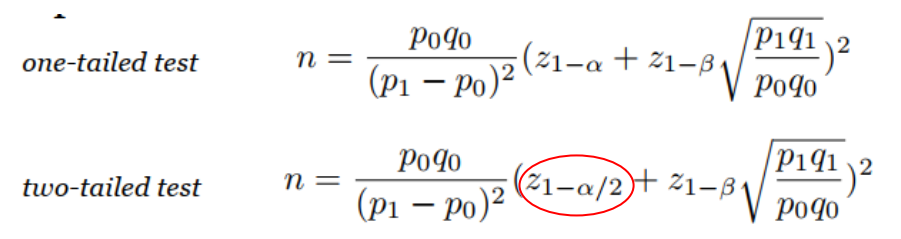 |
|||
| 5 | 1. np<15 |
二项分布 | #计算对应的概率密度值 >pbinom(q, size, prob, lower.tail = TRUE) #某值的概率 dbinom(x, size, prob, log = FALSE) #概率密度 pbinom(q, size, prob, lower.tail = TRUE, log.p = FALSE) #计算某概率下的值 qbinom(p, size, prob, lower.tail = TRUE, log.p = FALSE) #二项分布检验 >binom.test(x, n, p = 0.5, alternative = c(“two.sided”, “less”, “greater”), conf.level = 0.95) |
||||||
| 6 | 双样本 |
均值检验 | 1. 两个配对样本 |
t检验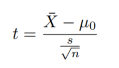 |
同2 | 双尾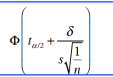 |
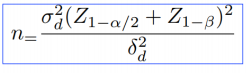 |
||
| 7 | 方差检验 | 1. 两个服从正态分布的独立样本 |
F检验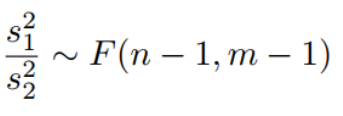 |
#F检验 >var.test(x, y, ratio = 1, alternative = c(“two.sided”, “less”, “greater”), conf.level = 0.95,) |
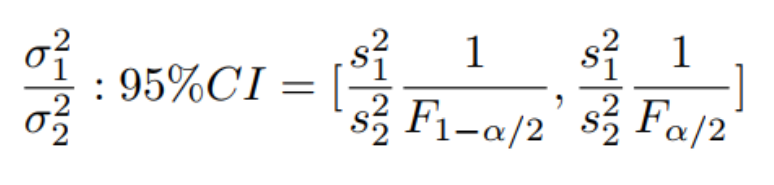 |
双尾 |
|||
| 8 | 均值检验 | 1. 两个总体都是正态分布或大样本 1. 独立样本 1. 总体方差已知 |
Z检验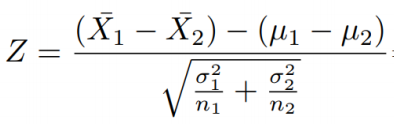 |
同1 | 两个样本量相等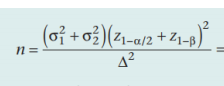 两个样本量不等 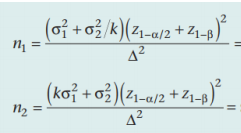 k=n2/n1 △=|μ2-μ1| #R中pwr包估计功效和样本大小 >pwr.t.test(n = NULL, d = NULL, sig.level = 0.05, power = NULL, type = c(“two.sample”, “one.sample”, “paired”),alternative = c(“two.sided”, “less”, “greater”)) |
||||
| 9 | 1. 两个总体都是正态分布或大样本 1. 独立样本 1. 总体方差未知且相等 |
t检验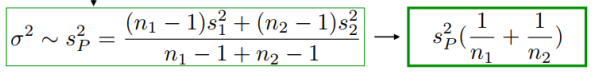 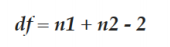 |
#t检验 >t.test(x,y,var.equal=”TRUE”) |
双尾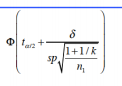 |
|||||
| 10 | 1. 两个总体都是正态分布或大样本 1. 独立样本 1. 总体方差未知且不等 |
t检验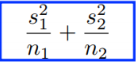 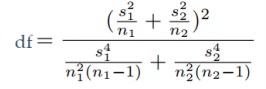 |
#t检验 >t.test(x,y,var.equal=”FALSE”) |
双尾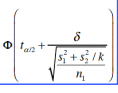 |
|||||
| 11 | 多样本 |
方差检验 | 1. 任意样本 |
Bartlett检验 Levene检验 |
#Bartlett检验 >bartlett.test(formula) #Levene检验 >leveneTest(formula) |
||||
| 12 | 均值检验 | 1. 只有一个自变量 1. 具有两个或两个以上的水平 1. 总体服从正态分布 1. 总体之间方差同质 1. 样本之间彼此独立 |
单因素ANOVA |
#ANOVA >summary(aov(formula, data = NULL)) >oneway.test(formula, data,var.equal = TRUE) #拟合线性模型 >summary(lm(formula, data = NULL)) >anova(lm(formula, data = NULL)) |
|||||
| 13 | 1. 单因素方差存在有差异样本 1. 寻找差异样本 |
成对t检验 Tukey HSD,纠正多重测试问题的替代方法 |
#pairwise.t.test检验 >pairwise.t.test(x, g, p.adjust.method = c(“bonferroni”,”fdr”)) #Tukey HSD检验 >TukeyHSD(aov(formula, data = NULL)) >plot(TukeyHSD(aov(formula, data = NULL))) |
||||||
| 14 | 1. 总体之间方差不等 |
韦尔奇的ANOVA | #Welch的ANOVA >oneway.test(formula, data,var.equal = FALSE) |
||||||
| 15 | 1. 两个变量及其相互作用 1. 总体服从正态分布 1. 总体之间方差同质 1. 样本之间彼此独立 |
双因素ANOVA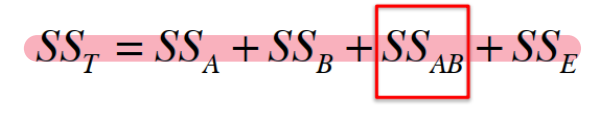 |
#ANOVA >summary(aov(formula, data = NULL)) [注:有交互作用用*表示,没有交互作用用+表示] #可视化 >interaction.plot(x.factor, trace.factor, response,type=”b”,col=c(),pch=c()) >plotmeans(response~interaction(x.factor,trace.factor,sep=””),connect=list(c(),c())) >interaction2wt(formula) |
||||||
| 16 | 1. 双因素方差存在差异样本 1. 寻找差异样本 |
后续分析 | #Tukey HSD检验 >TukeyHSD(aov(formula, data = NULL)) |
||||||
| 17 | 非 参 数 检 验 |
单样本 |
中位数检验 |
1. 任意样本 |
符号检验(sign test)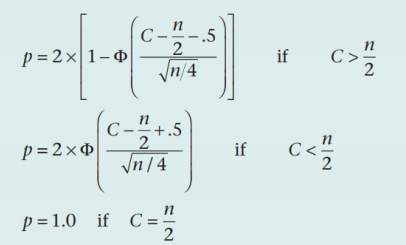 秩检验(wilcoxon test) |
#秩检验 >wilcox.test(x, y,paired = TRUE, exact = FALSE) |
符号检验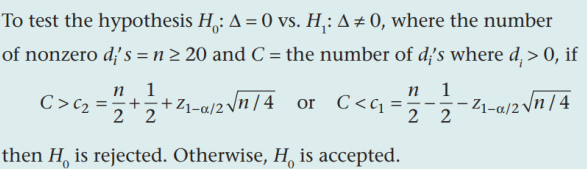 |
||
| 18 | 双样本 |
1. 配对样本 |
|||||||
| 19 | 1. 独立样本 |
秩和检验 | #秩和检验 >wilcox.test(x, y,paired = FALSE, exact = FALSE) |
||||||
| 20 | 多样本 |
1. 总体分布为非正态 1. 因变量为序数数据 |
Kruskal-Wallis检验 | #Kruskal-Wallis检验 >kruskal.test(formula, data) |
|||||
| 21 | 1. KW检验存在差异 1. 寻找差异样本 |
配对秩和检验 | #配对秩和检验 >pairwise.wilcox.test(formula,data, p.adjust.method = c(“bonferroni”,”fdr”)) |
1. 【Z检验】单样本+总体方差已知
1.1 中心极限定理
设从均值为μ、方差为σ2的任意一个总体中抽取样本量为n的样本,当n充分大 时,样本均值 的抽样分布近似服从均值为μ、方差为 σ的正态分布。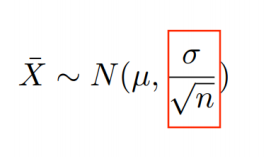
例题:波士顿市医院的1000名婴儿的平均出生体重为112.0盎司,标准偏差为20.6盎司。 10名婴儿的平均出生体重在98.0到126.0盎司之间的概率是多少?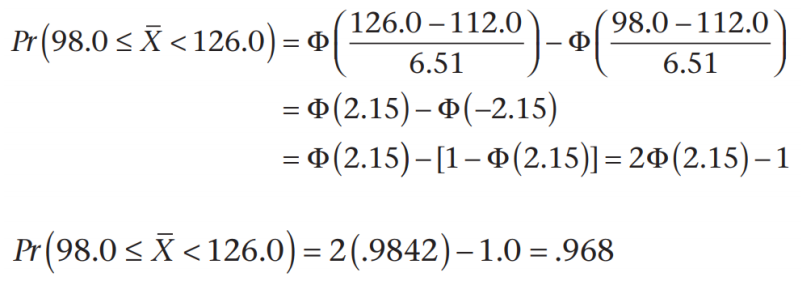
1.2 置信区间计算推导
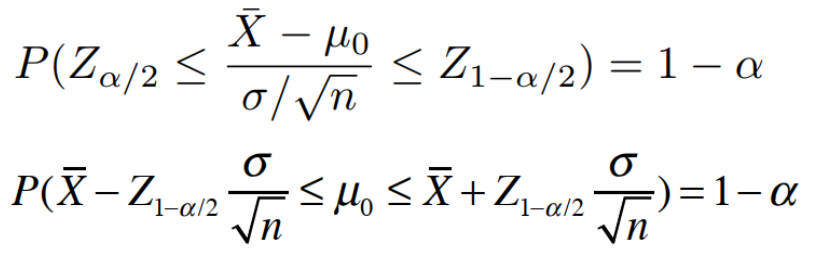
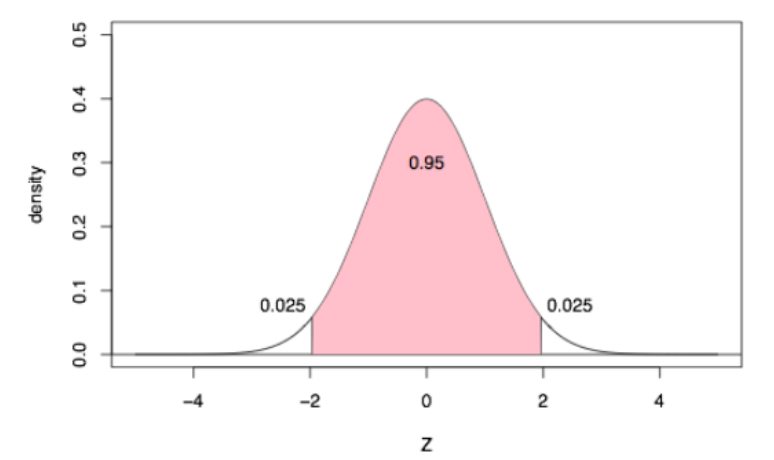
置信率=1-α
置信区间指在指定置信率下,原假设分布总体均值的估计区间
2. 【t检验】单样本+总体方差未知
2.1 确定假设检验结果的统计显著性的两种方法
- 临界值算法:计算检验统计量t,并与a水平下的临界值tn-1进行比较。
- 计算p-value值:计算出准确的p值,与α进行比较。
注意:计算p值时,要注意检验的类型(单边or双边),通过p值在分布图中的含义来进行计算。
3. 【卡方检验】单样本+方差检验
从正态分布中随机选择的数据,样本方差遵循卡方分布
例题:一种新的动脉血压仪被开发出来,并被宣传与标准血压仪相比,能够减少不同观察者所获得的测量结果的可变性。假设标准血压仪的σ2= 35。这个广告是真的吗?——双边检验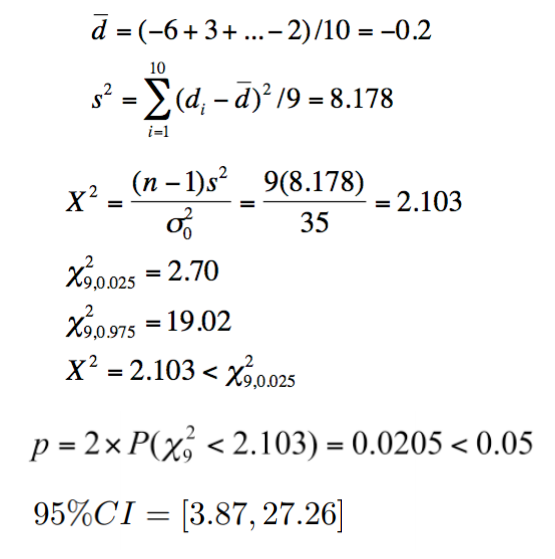
4. 【Z检验】大样本+比例检验
例题:在50-54岁的10,000名患有乳腺癌患者中,大约有400名的母亲某个时期患有乳腺癌。该年龄段的美国女性患乳腺癌的比例约为2%。家族史是否影响乳腺癌?
5. 【二项检验】小样本+比例检验
例题:在特别严重的感染中,平均每100名患者中有60人存活下来。当随机抽取15名感染患者服用一种新药时,12人存活了下来。这能证明药物有效吗?
(1)临界值算法 (2)计算p-value值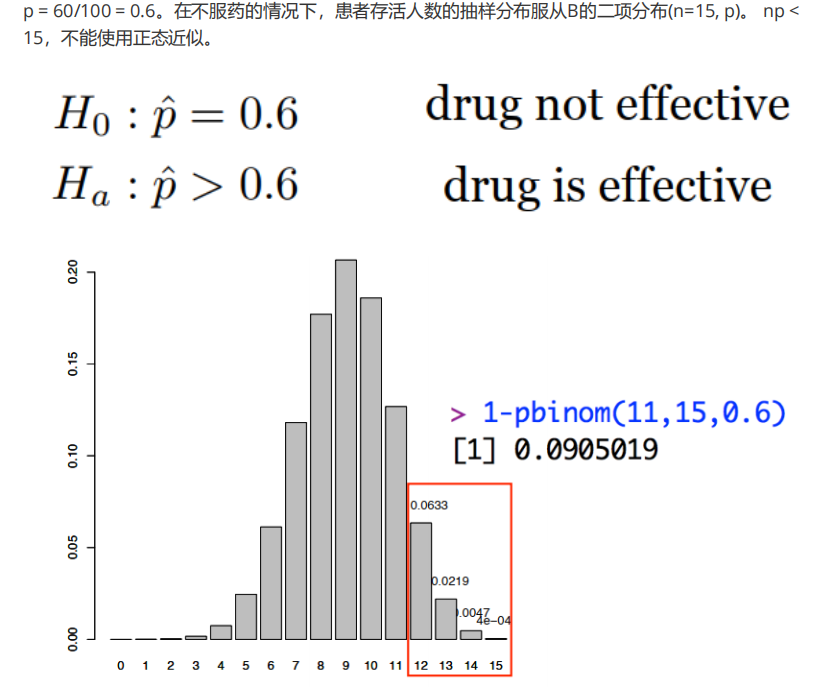

给定p = 0.6,观察到12个或更多患者存活的概率为
P(x = 12)+ P(x = 13)+ P(x = 14)+ P(x = 15)
= 0.0905019>α(0.05),故该药无效。
检验功效
1.含义

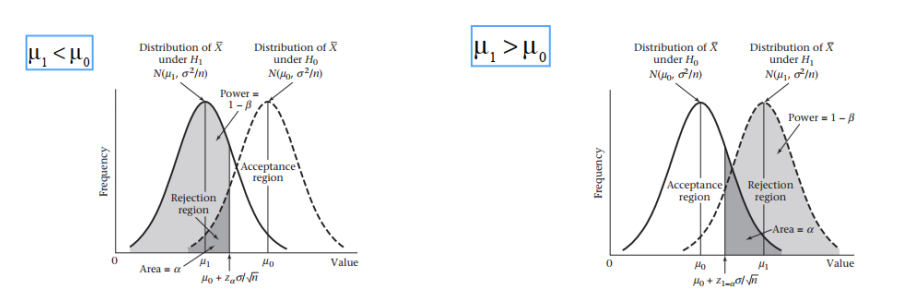
2.意义
如果备择假设是正确的——也就是说,如果真实均值与零假设下的均值不同,那么测试的功效告诉我们,在有限的样本大小n的基础上检测到统计上显著差异的可能性有多大。
如果功效太低,则几乎没有机会找到显着差异,即使被研究组的真实平均值和零平均值之间存在真正的差异,也有可能出现不显著的结果。样本容量不足通常是检测科学意义差异的低功率的原因。
3.计算
例题:在低SES地区,一家医院的100名婴儿的出生体重的平均出生体重(x)为115盎司。 假设全国平均水平为120盎司,标准偏差为24盎司。计算检验效力。【μ1<μ0】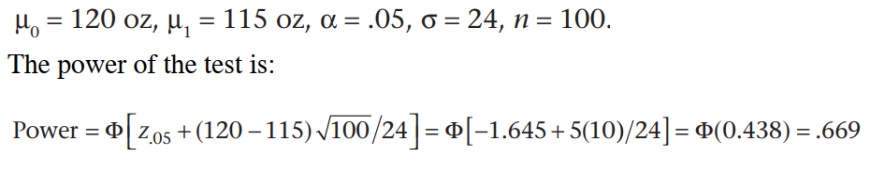
例题:假设父亲死于心脏病的10名儿童的平均胆固醇水平为175mg / dL,样本标准偏差为50mg / dL。 该测试的显着性水平为5%,平均替代值为190 mg / dL,计算检验效力。【μ1>μ0】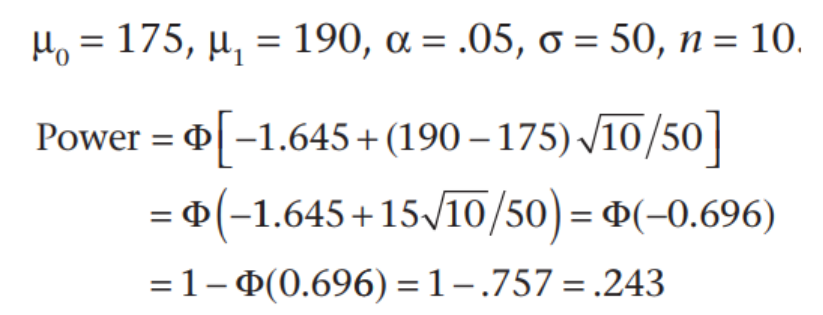
4. 提高检验功效的方法
①降低限制性水平
②增大样本量
③增大效应量【effect size】 效应量与样本量无关,表示两个总体之间的真实差异。对于足够大的样本,除非效应量恰好为零,否则p值几乎总是有意义的。但非常小的差异,即使显著,往往也是毫无意义的。
效应量与样本量无关,表示两个总体之间的真实差异。对于足够大的样本,除非效应量恰好为零,否则p值几乎总是有意义的。但非常小的差异,即使显著,往往也是毫无意义的。
④降低样本均值抽样分布的方差
非参数检验
- 含义
不依赖基本总体分布的的形式和参数;其数据可以是任意变量形式的;通常是对中位数进行检验
- 优缺点
优点:简单,仅需对数据进行计数或排序;应用范围更广,比参数检验更加稳定
缺点:没有充分利用数据的分布,效果较弱;在数据变换过程中,容易损失很多信息
11.【符号检验】
如果观测值是真是的中位数,则任何观测值都有50%的机会大于中位数,符合p=0.5的二项分布。
对于大样本,二项分布近似于正态分布,μ=n/2,σ2=n/4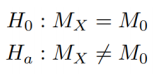
12.【秩检验】
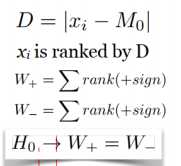
13.【秩和检验】两个独立样本的非参数检验
将两个样本进行合并,并进行排序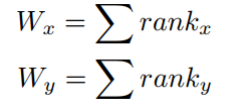
多重假设检验矫正
1. Bonferroni
一种非常简单的方法,用于在执行m个独立的假设检验时确保维持α的总体I类错误率。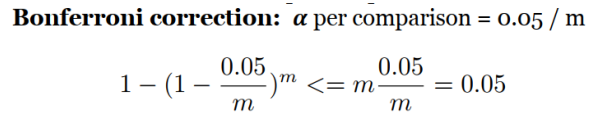
2. FWER顺序调整
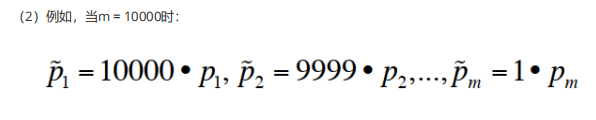
3. FDR
是控制被拒绝假设集合(R)中的假阳性比例。
单因素方差分析
- 方差分析的原理
总残差平方和(SS)=组间平方和(系统差异)+组内平方和(非系统差异)
如果SSbetween >> SSwithin ,则拒绝原假设,认为至少有一组的均值存在差异。
- 计算程序(step-by-step)

(1)读取数据
(2)计算总均值和分离均值
> GrandMean <- mean(PERCENT);GrandMean> SMeans <- aggregate(PERCENT,by=list(JUDGE),FUN=mean);SMeans
(3)计算平方和
> SVars <- aggregate(PERCENT,by=list(JUDGE),FUN=var)> SLens <- aggregate(PERCENT,by=list(JUDGE),FUN=length)> within_SS <- sum((SLens$x-1)*SVars$x)> total_SS <- sum((PERCENT-GrandMean)^2)> between_SS <- total_SS-within_SS
(4)计算自由度
> df_between <- length(levels(JUDGE))-1> df_within <- length(PERCENT) - length(levels(JUDGE))
(5)计算均方
> between_MS <- between_SS/df_between> within_MS <- within_SS/df_within
(6)F值和p值
> F_ration <- between_MS/within_MS> P_value <- 1-pf(F_ration,df_between,df_within)
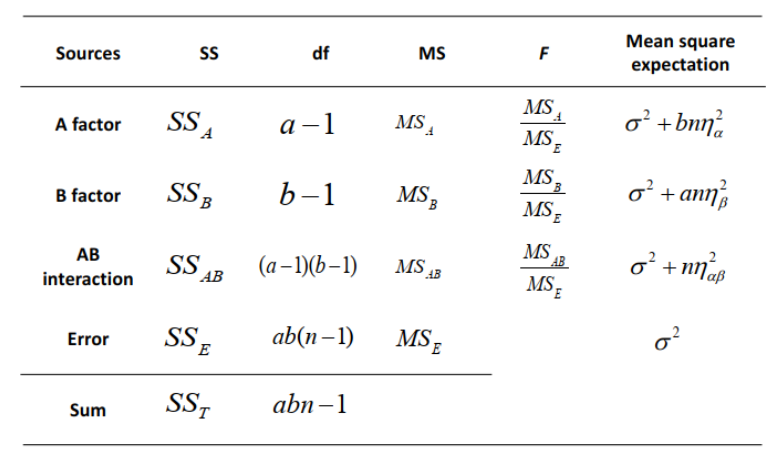
多因素方差分析
- 计算程序(step-by-step)
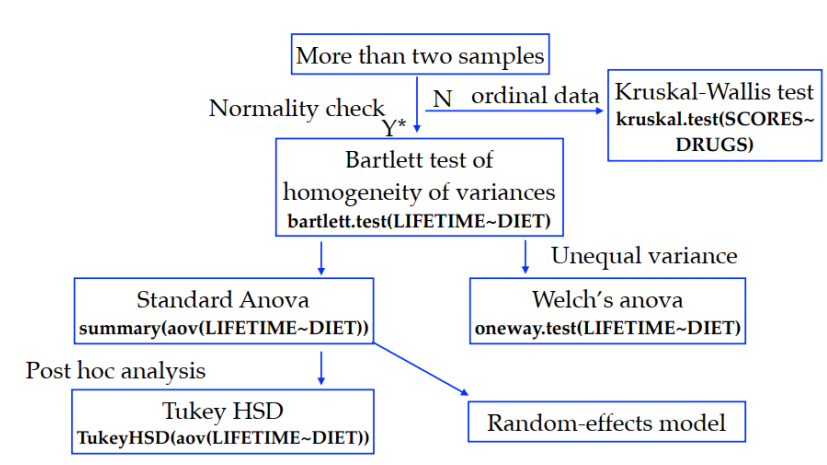
多样本检验
缺失值
#判断是否有缺失值>is.na()#寻找缺失值>md.pattern()#删除缺失值——删除行>na.omit()#可视化>aggr()>matrixplot()

若有收获,就点个赞吧
0 人点赞
