朴素贝叶斯的直观理解
在网上曾经有一个有意思的概率讨论,题目是这样的(我相信所有人都会愿意看一看这种有趣的问题):
有三张彩票,一张有奖。你买了一张,老板在自己剩余的两张中刮开了一张,没中。这时候他要用剩下的一张和你换,你换不换?换和不换你中奖的概率一样吗?(你可以思考一下,然后看我下面的回答)
—————————————————————————-
从直觉上来讲,彩票中奖的概率是1/3,你最先抽了一张,不管咋操作,中奖的概率应该都是1/3。这时候老板排除掉了一张没中奖的,剩下两张必有一张中奖,所以概率是1/2。换和不换应该都一样。你是这么答的吗?
这时候需要引申出贝叶斯了,贝叶斯在概率的计算中引入了先验概率,即在知道了一些事情的情况下,概率会发生变化,按照贝叶斯的解答应该是怎样的呢?
首先我们要引入概率的一些写法(事实上如果你不太明白这些公式的话,建议适当补一些概率的课程,在机器学习中非常有用)
补充知识:P(A|B)表示在B发生的情况下A发生的概率。P(A|B) = [P(B|A)P(A)] / P(B)。
—————————————————————————-
我们假设A表示你手里目前这张是中奖的,B表示老板刮出来的那张是没中奖的(虽然题目中说明了老板刮出来的没中,但还是需要将情况假设出来)
那么由上面可得:
P(A|B) = [P(B|A)P(A)] / P(B)
在式中P(B|A)表示在A发生的情况下B发生的概率,代入题目中也就是如果你手里这张是中奖的,那老板刮出来那张没中奖的概率。很显然这是必然的,因为只有一张是中奖的,所以P(B|A)=1,也就是必然的事件。P(A)表示你手里目前这张是中奖的概率,在计算P(A)时因为没有给出前提条件,所以P(A)=1/3,也就是三张彩票,你手里中奖的概率是1/3。P(B)表示老板刮出来那张是没中奖的概率,题目中已经给出前提条件老板刮出来的是没中奖的,所以概率P(A)=1.
那么将数代进式子里面:P(A|B) = [P(B|A)P(A)] / P(B) = [1 1/3] / 1 = 1/3,也就是说在老板刮出来一张没中奖的彩票前提下,你手里这张中奖的概率是1/3,老板手里剩余那张是2/3。为了中奖概率最大化,应该和老板手里的彩票交换。
是不是感觉不对劲,三张彩票我自己抽了一张,我中不中奖怎么还和老板刮不刮自己的彩票有关系了呢?P(A|B)这个算法是错的吧?当时论坛也争论了很久,但十年前的人们还不太会使用贝叶斯来武装自己,有一部分用直觉,也就是脑袋算法,坚持就是1/2。另一部分去绕来绕去分析,企图找到直觉没考虑到的地方来证明是1/3和2/3。后来有位程序员写了算法来模拟,结果确实是1/3和2/3。有兴趣的同学可以通过这个链接自行跑一下程序。https://www.zybuluo.com/zzy0471/note/111692
至于你们问我这个现象该怎么解释,可能需要很长的篇幅,但在本文中这不是重点展开的地方,这个例子和今天的朴素贝叶斯分类器有什么关系?很抱歉,没有关系,我只是想皮一下。(开个玩笑,我觉得这对于读者来说,理解前提条件对于概率来说是一种什么概念就可以了。)
————– 2020年8月24日补充—————–
评论区包括有部分同学加我微信和我聊了上面这个例子,使我发现我的博客可能写得有些草率,所以出现了不服的现象(挺胸高傲)。首先说明一点,例子没有错误。然后我们换一些角度来考虑一下这件事情。
因为老板抽的那张必定不会中奖,所以我们可以假设老板知道A、B、C三张彩票中哪张有奖,当我们抽完一张以后,他会再扔掉一张不中奖的。那在我们抽彩票的时候,3张里挑一张,这张中奖的概率是1/3. 之后老板扔掉一张,此时我们手中这张彩票的中奖概率仍然是1/3. 为啥?换个角度来思考,他本质上这样一件事情:我抽一张彩票,老板再扔掉一张没中奖的彩票,求我中奖的概率。假设彩票1中奖,我们看看下面这个表格。我们发现一共3种可能,其中我中奖的概率,仍然是1/3. 它并不会因为老板扔掉一张没中奖的,我中奖的概率就会变成1/2.(因为老板并不是先抽一张排除掉哪张不中奖,他是根据我的选择,去剩下的当中再把那张不中奖的扔掉。你甚至可以认为在这里,老板扔彩票是一种无意义的行为,因为我抽在先,他扔掉在后,而且我也知道剩下的两张中必然有至少一张是不中奖的)
| 彩票1(中奖) | 彩票2 | 彩票3 |
|---|---|---|
| 我抽中 | 老板扔掉2 | 或老板扔掉3 |
| 我抽中 | 老板扔掉 | |
| 老板扔掉 | 我抽中 |
再换种角度,我知道10张彩票里有一张中奖,我抽了一张,有两种情况:中奖和不中奖。所以剩下的彩票中我知道必定至少有8张不中奖。(因为我中奖的话,剩下9张全都不中奖,我不中奖的话,剩下的有8张不中奖)。哪怕我知道这些知识,我中奖的概率目前仍然是1/10对吗?那有个人过来偷偷看了看剩下的每张彩票,因为剩下的彩票至少有8张不中奖,所以他把其中的8张不中奖的彩票拿走了,还剩下一张,这时候我中奖的概率就变成1/2了吗?不是的,不管我抽哪张,他都能从中挑出8张不中奖的,换言之,他拿不拿走那8张,对我是否中奖一点影响都没有。
此外,对于P(B)为什么是1,因为B表示老板刮出来的是没中奖的事件。在我们的例子中,老板刮出来的已经是没中奖的了,这是事实,所以P(B)为1。我们甚至可以理解这是一个平行世界的分支,在我们这个分支中,老板挂出来的一定是没中奖的,而老板中奖的事件是另一个分支,已经坍塌了,不在我们题设之中。
这次更新尝试从直观的角度去解释这件事情,但水平一般,能力有限,还希望有疑惑的同学重新理一下,如果觉得有更好的描述方式,也欢迎在评论区写出来,方便后面的同学理解。不过对于理工男而言,公式的答案仍然是我们寻找真理最佳的依据。未来在模型训练时我们会遇到很多反直觉的结果,直觉不一定可靠,如果事实与直觉像悖,首先否定直觉,之后质疑事实,我们一起加油。
另:最近秋招,面试竟然也被问到了这个问题,所以。。(敲黑板,划重点)。
好了,我们开始正式地讲解朴素贝叶斯分类器是个啥玩意了。
机器学习算法中我们通常在这样的情况下去使用朴素贝叶斯分类器。
假设我们有一个手写的数据集样本,里面有100条记录,记录0-10是10个人各自写的0,记录11-20是10个人各自写的1,……..以此类推一共100条记录。那么这时候外头有个人进来写了个数字X,怎么识别出来它写的几呢?没学习过机器学习的人可能也能提出这样一种方法:我们只要把写的那个数字和0-9进行匹配,那个匹配度最高就是哪个数啦。没错,朴素贝叶斯用的就是这样朴素的思想(开玩笑,这里的朴素可不是这个意思)。
朴素贝叶斯工作原理:假设Y表示是数字几,写的那个数叫X,那么我们可以通过某种方法求P(Y = 1 | X),P(Y = 1 | X),…….,P(Y = 9| X)。其中P(Y = 1 | X)表示在给定手写数字X的情况下,它是1的概率。这样得出10个数字各自的概率,哪个高就最有可能是哪个。那么咋求这个P(Y = 1 | X),别着急,这就是后文重点讨论的内容,在直观理解中无须涉及。
总之,朴素贝叶斯分类器就是一个对所有可能性求概率的模型,最后输出结果中哪种可能性高就输出哪种。核心公式是P(Y | X),至于P(Y | X) = ?,这部分怎么求?我们现在开始用数学的知识开始讨论。(我尽可能简化一些公式,但本章节相对于前几章来说,公式有些稍多。读者需要习惯,学会朴素贝叶斯分类器,我们一只脚也就正式踏入了机器学习的大门)
朴素贝叶斯分类器的数学角度(配合《统计学习方法》食用更佳)
我们刚刚提到朴素贝叶斯最终需要计算得到的公式是P(Y=?|X),然后比较不同概率的大小,选择概率最大的一类输出。不妨将不同的类设为Ck,在手写识别中C0就表示数字0,C1表示数字1,以此类推。那么上式也就可以写成了P(Y=Ck|X=x),即在给定样本X为x的情况下,Y为Ck的概率。依据上文的贝叶斯公式,我们可以将该式转换为下图中的第一个等号右边这样(依据贝叶斯公式定义)。
在第一个等号右边的式子中,分子的左边P(X=x|Y=y)表示在给定数字几的情况下,出现该样本的概率,比如说随便给了一个数字不知道是几,然后被通知这个数是1,问你纸上会出现这个图案的概率(也就是说告诉你这个数是1,那么纸上出现的那团图案长得像1的可能性就大,长得像9的可能性就小),这个在给定样本进行训练的情况下是可以统计出来的(具体怎么统计会在后文讲解)。P(Y=Ck)表示每个类别出现的概率,比如说10个数里面有5个1,那P(Y=C1)=5/10,也可以通过给定训练样本进行统计得到。
式子唯一还不太明白的就是分母的P(X=x),给定一个样本的概率?将分母转换成第二个等候右边一样。P(X=x|Y=Ck)P(Y=Ck)=P(X=x, Y=Ck),表示对于每一类Y,都求一次X=x的概率,那么总的求和以后就变成了P(X=x)。(这部分不太明白的建议再补充一些概率的课程)。那么最初的式子就变成了求第二个等号右边的式子。
再往下转换,就变成了下图这样。
和上图的式子进行比对,其实就是把P(X=x|Y=Ck)这一项变成了连乘,至于为什么能连乘,下图有详细说明:
为什么可以把里面的直接拆开来连乘?概率老师不是说过只有相互独立才能直接拆吗?是的,朴素贝叶斯分类器对条件概率分布做出了条件独立性的假设。为啥?因为这样能算,就这么简单,如果条件都不独立,后面咋整?读者:那你这不严谨啊。emmm….事实上是这样,向量的特征之间大概率是不独立地,如果我们独立了,会无法避免地抛弃一些前后连贯的信息(比方说我说“三人成”,后面大概率就是个”虎“,这个虎明显依赖于前面的三个字)。在建立模型时如果这些都考虑进去,会让模型变得很复杂,后来前人说那我们试试不管它们,强行独立。诶发现效果还不错诶,那就这么用吧。这就是计算机科学家和数学家的分歧所在。
上图中P(X=x|Y=Ck)转换成能求的式子了以后,那么就是比较Y为不同Ck的情况下哪个概率最大,那就表示属于哪个类的可能性最大。所以前头式子前头加上一个argmax,表示求让后式值最大的Ck。
然后由于下图中圈出来这一项是在Y为不同Ck情况下的连乘,所以不管k为多少,所有Ck连乘结果肯定是一致的,在比较谁的值最大时,式子里面的常数无法对结果的大小造成影响,可以去掉。
[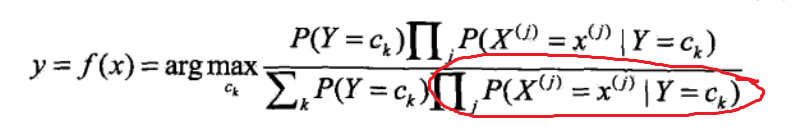 ](http://www.pkudodo.com/wp-content/uploads/2018/11/%E6%9C%B4%E7%B4%A0%E8%B4%9D%E5%8F%B6%E6%96%AF%E5%85%AC%E5%BC%8F4.png)
](http://www.pkudodo.com/wp-content/uploads/2018/11/%E6%9C%B4%E7%B4%A0%E8%B4%9D%E5%8F%B6%E6%96%AF%E5%85%AC%E5%BC%8F4.png)
就变成了下面这样:
这就是最终简化版的朴素贝叶斯分类器。至于式子里面的两项具体怎么求,我们首先看第一项。
N为训练样本的数目,假设我们手里现在有100个样本,那N就是100。分子中I是指示函数,括号内条件为真时指示函数为1,反之为0。分子啥意思呢?就是说对于Ck,在这100个样本离有多少是Ck分类的,就比如Ck为C1时表示数字类别1,这时候就是看这100个样本里有多少个数字1,处于总的100,就是类别1的概率,也就是P(Y=C1)。简单不?相当简单。我们再看第二项。
这个我觉得不用细说了,构造原理和上面第一项的一样,也是通过指示函数来计数得出概率。那么两项都能求了,给出朴素贝叶斯算法。
朴素贝叶斯算法

可以看到在步骤中首先根据给定的训练样本求先验概率和条件概率,也就是上文求的那两个式子,然后训练计数后给定一个样本,计算在不同类别下该样本出现的概率,求得最大值即可。

关于朴素贝叶斯和贝叶斯:
还记得原先求不同类别下的最大概率这一式子吗?里面有很多的连乘记得吗?
这里提出了一个问题,那么多概率连乘,如果其中有一个概率为0怎么办?那整个式子直接就是0了,这样不对。所以我们连乘中的每一项都得想办法让它保证不是0,哪怕它原先是0,(如果原先是0,表示在所有连乘项中它概率最小,那么转换完以后只要仍然保证它的值最小,对于结果的大小来说没有影响。)。这里就使用到了贝叶斯估计。
它通过分母和分子各加上一个数来保证始终不为0.为什么要分母加Sj或者K倍λ,以及分子要加个1倍λ,读者可以试验一下,这样处理以后,所有概率的总和仍然是1,所以为什么这么加,只不过这么加完以后,概率仍然是概率,总和仍然为1,但所有项都大于0。
举个例子:

关于《统计学习方法》的一些补充:
使用贝叶斯估计虽然保证了所有连乘项的概率都大于0,不会再出现某一项为0结果为0的情况。但若一个样本数据时高维的,比如说100维(100其实并不高),连乘项都是0-1之间的,那100个0-1之间的数相乘,最后的数一定是非常非常小了,可能无限接近于0。对于程序而言过于接近0的数可能会造成下溢出,也就是精度不够表达了。所以我们会给整个连乘项取对数,这样哪怕所有连乘最后结果无限接近0,那取完log以后数也会变得很大(虽然是负的很大),计算机就可以表示了。同样,多项连乘取对数,对数的连乘可以表示成对数的相加,在计算上也简便了。所以在实际运用中,不光需要使用贝叶斯估计(保证概率不为0),同时也要取对数(保证连乘结果不下溢出)。
有人可能关心取完log以后结果会不会发生变化,答案是不会的。log在定义域内是递增函数,log(x)中的x也是递增函数(x在x轴的最大处,x值也就越大,有些拗口,可以仔细想想)。在单调性相同的情况下,连乘得到的结果大,log取完也同样大,并不影响不同的连乘结果的大小的比较。好啦,上代码。
贴代码:(建议去本文最上方的github链接下载,有书中所有算法的实现以及详细注释)
mport numpy as npimport timedef loadData(fileName):'''加载文件:param fileName:要加载的文件路径:return: 数据集和标签集'''#存放数据及标记dataArr = []; labelArr = []#读取文件fr = open(fileName)#遍历文件中的每一行for line in fr.readlines():#获取当前行,并按“,”切割成字段放入列表中#strip:去掉每行字符串首尾指定的字符(默认空格或换行符)#split:按照指定的字符将字符串切割成每个字段,返回列表形式curLine = line.strip().split(',')#将每行中除标记外的数据放入数据集中(curLine[0]为标记信息)#在放入的同时将原先字符串形式的数据转换为整型#此外将数据进行了二值化处理,大于128的转换成1,小于的转换成0,方便后续计算dataArr.append([int(int(num) > 128) for num in curLine[1:]])#将标记信息放入标记集中#放入的同时将标记转换为整型labelArr.append(int(curLine[0]))#返回数据集和标记return dataArr, labelArrdef NaiveBayes(Py, Px_y, x):'''通过朴素贝叶斯进行概率估计:param Py: 先验概率分布:param Px_y: 条件概率分布:param x: 要估计的样本x:return: 返回所有label的估计概率'''#设置特征数目featrueNum = 784#设置类别数目classNum = 10#建立存放所有标记的估计概率数组P = [0] * classNum#对于每一个类别,单独估计其概率for i in range(classNum):#初始化sum为0,sum为求和项。#在训练过程中对概率进行了log处理,所以这里原先应当是连乘所有概率,最后比较哪个概率最大#但是当使用log处理时,连乘变成了累加,所以使用sumsum = 0#获取每一个条件概率值,进行累加for j in range(featrueNum):sum += Px_y[i][j][x[j]]#最后再和先验概率相加(也就是式4.7中的先验概率乘以后头那些东西,乘法因为log全变成了加法)P[i] = sum + Py[i]#max(P):找到概率最大值#P.index(max(P)):找到该概率最大值对应的所有(索引值和标签值相等)return P.index(max(P))def model_test(Py, Px_y, testDataArr, testLabelArr):'''对测试集进行测试:param Py: 先验概率分布:param Px_y: 条件概率分布:param testDataArr: 测试集数据:param testLabelArr: 测试集标记:return: 准确率'''#错误值计数errorCnt = 0#循环遍历测试集中的每一个样本for i in range(len(testDataArr)):#获取预测值presict = NaiveBayes(Py, Px_y, testDataArr[i])#与答案进行比较if presict != testLabelArr[i]:#若错误 错误值计数加1errorCnt += 1#返回准确率return 1 - (errorCnt / len(testDataArr))def getAllProbability(trainDataArr, trainLabelArr):'''通过训练集计算先验概率分布和条件概率分布:param trainDataArr: 训练数据集:param trainLabelArr: 训练标记集:return: 先验概率分布和条件概率分布'''#设置样本特诊数目,数据集中手写图片为28*28,转换为向量是784维。# (我们的数据集已经从图像转换成784维的形式了,CSV格式内就是)featureNum = 784#设置类别数目,0-9共十个类别classNum = 10#初始化先验概率分布存放数组,后续计算得到的P(Y = 0)放在Py[0]中,以此类推#数据长度为10行1列Py = np.zeros((classNum, 1))#对每个类别进行一次循环,分别计算它们的先验概率分布#计算公式为书中"4.2节 朴素贝叶斯法的参数估计 公式4.8"for i in range(classNum):#下方式子拆开分析#np.mat(trainLabelArr) == i:将标签转换为矩阵形式,里面的每一位与i比较,若相等,该位变为Ture,反之False#np.sum(np.mat(trainLabelArr) == i):计算上一步得到的矩阵中Ture的个数,进行求和(直观上就是找所有label中有多少个#为i的标记,求得4.8式P(Y = Ck)中的分子)#np.sum(np.mat(trainLabelArr) == i)) + 1:参考“4.2.3节 贝叶斯估计”,例如若数据集总不存在y=1的标记,也就是说#手写数据集中没有1这张图,那么如果不加1,由于没有y=1,所以分子就会变成0,那么在最后求后验概率时这一项就变成了0,再#和条件概率乘,结果同样为0,不允许存在这种情况,所以分子加1,分母加上K(K为标签可取的值数量,这里有10个数,取值为10)#参考公式4.11#(len(trainLabelArr) + 10):标签集的总长度+10.#((np.sum(np.mat(trainLabelArr) == i)) + 1) / (len(trainLabelArr) + 10):最后求得的先验概率Py[i] = ((np.sum(np.mat(trainLabelArr) == i)) + 1) / (len(trainLabelArr) + 10)#转换为log对数形式#log书中没有写到,但是实际中需要考虑到,原因是这样:#最后求后验概率估计的时候,形式是各项的相乘(“4.1 朴素贝叶斯法的学习” 式4.7),这里存在两个问题:1.某一项为0时,结果为0.#这个问题通过分子和分母加上一个相应的数可以排除,前面已经做好了处理。2.如果特诊特别多(例如在这里,需要连乘的项目有784个特征#加一个先验概率分布一共795项相乘,所有数都是0-1之间,结果一定是一个很小的接近0的数。)理论上可以通过结果的大小值判断, 但在#程序运行中很可能会向下溢出无法比较,因为值太小了。所以人为把值进行log处理。log在定义域内是一个递增函数,也就是说log(x)中,#x越大,log也就越大,单调性和原数据保持一致。所以加上log对结果没有影响。此外连乘项通过log以后,可以变成各项累加,简化了计算。#在似然函数中通常会使用log的方式进行处理(至于此书中为什么没涉及,我也不知道)Py = np.log(Py)#计算条件概率 Px_y=P(X=x|Y = y)#计算条件概率分成了两个步骤,下方第一个大for循环用于累加,参考书中“4.2.3 贝叶斯估计 式4.10”,下方第一个大for循环内部是#用于计算式4.10的分子,至于分子的+1以及分母的计算在下方第二个大For内#初始化为全0矩阵,用于存放所有情况下的条件概率Px_y = np.zeros((classNum, featureNum, 2))#对标记集进行遍历for i in range(len(trainLabelArr)):#获取当前循环所使用的标记label = trainLabelArr[i]#获取当前要处理的样本x = trainDataArr[i]#对该样本的每一维特诊进行遍历for j in range(featureNum):#在矩阵中对应位置加1#这里还没有计算条件概率,先把所有数累加,全加完以后,在后续步骤中再求对应的条件概率Px_y[label][j][x[j]] += 1#第二个大for,计算式4.10的分母,以及分子和分母之间的除法#循环每一个标记(共10个)for label in range(classNum):#循环每一个标记对应的每一个特征for j in range(featureNum):#获取y=label,第j个特诊为0的个数Px_y0 = Px_y[label][j][0]#获取y=label,第j个特诊为1的个数Px_y1 = Px_y[label][j][1]#对式4.10的分子和分母进行相除,再除之前依据贝叶斯估计,分母需要加上2(为每个特征可取值个数)#分别计算对于y= label,x第j个特征为0和1的条件概率分布Px_y[label][j][0] = np.log((Px_y0 + 1) / (Px_y0 + Px_y1 + 2))Px_y[label][j][1] = np.log((Px_y1 + 1) / (Px_y0 + Px_y1 + 2))#返回先验概率分布和条件概率分布return Py, Px_yif __name__ == "__main__":start = time.time()# 获取训练集print('start read transSet')trainDataArr, trainLabelArr = loadData('../Mnist/mnist_train.csv')# 获取测试集print('start read testSet')testDataArr, testLabelArr = loadData('../Mnist/mnist_test.csv')#开始训练,学习先验概率分布和条件概率分布print('start to train')Py, Px_y = getAllProbability(trainDataArr, trainLabelArr)#使用习得的先验概率分布和条件概率分布对测试集进行测试print('start to test')accuracy = model_test(Py, Px_y, testDataArr, testLabelArr)#打印准确率print('the accuracy is:', accuracy)#打印时间print('time span:', time.time() -start)

若有收获,就点个赞吧
0 人点赞
