小钱袋是蚂蚁金服体验技术部基于余额宝子卡开发的一个产品,家长通过在开通一个余额宝子卡,可以给孩子创建一个单独的存钱账户,可以支付宝中搜索小钱袋找到应用。
特色
小钱袋就是支付宝上一个非常简单小应用,但是因为来自于体验技术部,所以小钱袋应用整体技术栈都是 js 的,和大部分面向用户端的 node 应用不一样的点在于,小钱袋不仅仅是 BFF 应用,我们有自己完整的数据层。
很多来自前端团队的内部产品也都会有自己的数据层,比如 凤蝶、basement 应用,和这些应用相比小钱袋最大的特点是,小钱袋用户是支付宝 C 端用户。依托于支付宝 App ,我们可以运营的用户是亿级别的,产品要做到千万级用户规模,并不算很难。
总结来说,技术上有两个特点
- 小钱袋是有数据层
- 面向 C 端用户,用户规模 1000w+
下面我们主要来讲一下,这样一个应用如何基于 NodeJS 开发。
TypeScript
必要性
2016 年开始做第一个产品时,当时我做的第一个决定就是后端使用 TypeScript 。在这之前,我在做凤蝶,凤蝶应用发展到第三年,代码越来越难以维护,中间经过两次大的架构升级,但历史的包袱太重了,后来云凤蝶彻底重写了。
凤蝶最初还是 chair + java 结构部署的,我们都有参与 java 应用的开发,相对说 java 应用要好维护得多。我觉得强类型更适合这种多人维护的复杂应用。
解决代码腐化的方案
- 单元测试,测试保证修改后代码还能正确运行
- 重构,再好的架构设计,也都需要不停进化的
凤蝶最初试遇到了很严重的稳定性问题,后面我们把测试用例补全,但是代码还是不可逆的变得难以维护。单元测试可以部分提高稳定性,但是对于可维护性还是不够。
TypeScript 的主要优势
- 增加代码和数据之间的强关联,并且这种关联是具有约束性的
- 函数有准确的接口和入参
强大的类型体系
函数接口 js 中也可以通过繁琐的注释来声明,但是注释的表达性比起 TypeScript 语言级支持来说,只能算是一个小宝宝,并且 TypeScript 的类型体系还在不断进化。比如 ts 中我们可以声明一个这样描述函数:
// example 1function validate<K extends string>(payload: unknow, fields: K[]): { [key in K]: string; } {// function body}// const data: { a: string; }const data = validate({ a: 'a', b: 'b' }, ['a']);// example 2type QueryFilter<T> = Partial<{ [P in keyof T]: T[P] | Array<T[P]>}>;function query<T>(filter: QueryFilter<T>): Promise<T> {return this.mysql.get('table', filter);}
第一个例子,data 可以动态得到类型 { a: string} 。第二个例子,可能不大好看懂,实际上就是 egg-mysql 底层 ali-rds 的 get 方法。我们可以看到官方文档接口描述是这样的,对应加上接口描述后。


这里类型是支持运算的,注释无论如何也是做不到的,这种类型描述有很多,可以极大提高函数透明度。上面函数我们不需要写注释,函数本身接口可以说明函数如何运行。
数据和代码之间关联性
此外,我们可以解决重构 js 代码最大难点,代码和数据之间是割裂的,我们有一个模型,这个模型在哪里使用,在哪里被修改是不可知的。
已有的数据模型中随意增加一个字段,或者给字段增加一种枚举类型,在 js 中是很艰难的,改动的时候缺少数据和代码之间关联性,风险不可知,这时候我们通常选择不断新增字段,老的字段继续保留,这样数据模型会越来越臃肿。
TypeScript 增加的类型,让代码关联性更加明确。比如我们的数据层基本结构如下
所有的方法都和泛型 T 自动关联,这样后面对数据层的所有操作都可以和 Data Object 接口关联上,数据和代码真正关联上,后面重构会非常方便。
有类型,就这一个理由就非常值得我们尝试了。虽然当时整体上基础设施还非常差,蚂蚁这边很少应用使用 ts 。而后面我们的应用经历过好几次大的技术升级改造,TypeScript 确实给予我们很多的帮助。
下面先说说我们使用过程中遇到的问题
发展过程
egg 使用 TypeScript 主要在于解决这几个问题。
- 异常定位
- 类型规范
- 最佳实践
异常定位
最开始,最担心的是异常定位问题,ts 运行是编译后的 js ,正常情况错误拿到的应该是编译后的 js 堆栈。如果异常定位是错误的,对于后续线上问题排查是非常麻烦的,这是基础能力。
这个问题,社区很早之前就有解决方案。V8 提供了一个自定义错误堆栈的接口 Stack Trace API,基于这个接口我们可以在异常抛出的时候错误定位到 ts 源码上,具体过程参考 Node.js 中 sourcemap 使用问题总结 。
类型规范
使用 TypeScript 最大的一个问题就是外部依赖需要类型声明,chair 当时并没有类型声明,当时几个内部应用比如凤蝶、basement 各自写了自己的类型描述文件。chair 开源后,外部也很多人问题类型的问题,chair 也就有了类型的需求。这个问题好解决,纯粹体力活,后来我发了一个 pr ,把第一版类型文件加上了。有了官方版本后,大家使用类型有了一个公共的约定。
最佳实践
前面几个点主要是使用的基础设施问题,这些基础功能完成了。后面大家就想能不能把最佳实践整理下,让更多人方便使用。
当时遇到主要几个问题
- 开发环境什么时候编译 ts ,如何调试
- 类型声明怎么写
第一个问题,一开始都是开启 watch 实时编译 ts ,后来 egg 的 loader 支持 ts 加载,也可以在单元测试的时候直接依赖 ts-node 运行。这个问题天猪改造了 egg 底层,终于完善了。
第二个问题,因为 egg 底层是自动加载,service 是自动注入到请求上下文的,最初的方案,我们需要写了一个 service 文件后,需要把这个 service 的类型手动 merge 到请求上下文中。这个后来 egg 官方推荐的是 egg-ts-helper ,自动生成这个类型描述文件。
import News from './News';declare module 'egg' {interface IService {news: News;}}
自动注入 vs 依赖注入
egg-ts-helper 是一种解决方案,但这种方案我感觉并不理想。这个描述文件手动还是自动,我觉得并不核心问题。核心问题在于 egg 底层的自动加载机制。egg 应用通过目录约定,自动把所有的服务都挂载到请求上下文。这也就是 egg 奉行的 约定优于配置 原则。
这种方式优点是使用简单,所有的服务可以随便用。但是,对于复杂应用来说,service 分层是必要的,所有的服务都注入到上下文对象,这样不利于服务分层。
当时我看到凤蝶重写的时候使用了依赖注入,从凤蝶最开始到后来的小钱袋,我们都慢慢遇到了需要对 service 进行分组、整理的需求,这时候自动注入反而不合适。我们可以通过目录来隔离,但那种还只是约定上的隔离。依赖注入的方式,让我们显式申明了依赖的服务,也可以解决类型需要额外手动 merge 的问题。
依赖注入的引入,实际上更多是一种心理上的负担更小。在写一个服务的时候,需要用到那个服务的时候,声明一下依赖,这样我们面对的就不是所有服务。这种方式在多人开发的情况,更不容易乱。
当一个维护者面对一个 service 文件时候,如果他可以一眼看到这个服务依赖,这样他只需要了解依赖那么几个服务。如果他需要面对整个应用所有的服务,这样可能更加容易无从下手。
所以,后来我们放弃了 egg 自动注入,采用了依赖注入的方式来处理依赖。并且,对 service 进行了分层。这里给 egg-di 打一个广告,使用 TypeScript 的开发者可以看看。
依赖注入使用的基本例子如下
import UserService from 'service/user/user';import { inject } from 'egg-di';export default class UserController extends BaseController {@inject() readonly userService: UserService;async createUser(payload) {await this.userService.createUser(payload);}}
分层架构设计
服务分层的基本原理
选择依赖注入,服务之间可见性是可控的,我们可以从思维上摆脱 chair 自动注入导致的服务不可隔离问题。同时可以突破 chair 应用目录约束,服务可以在 npm 包中,也可以在任意其他目录。
服务分层,需要做到分层之间满足以下规则
- 分层之间数据是单向流动
- 层级之间依赖关系需要简单、清晰,也就是所谓的强内聚、松耦合
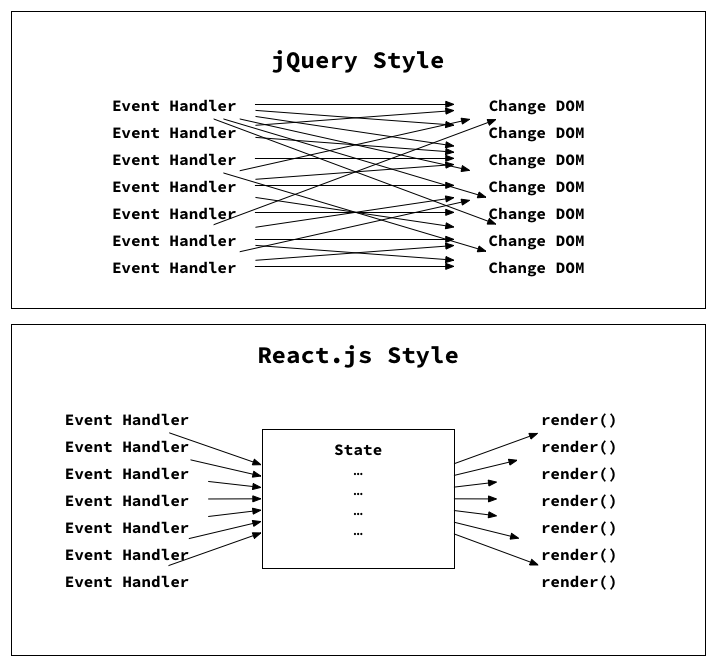
单向数据流在前端也越来越流行,从 react 渲染到 flux 分层架构都是如此。单向数据流的优势在于这种数据结构流动是非常简单、清晰的,非常利于理解。下面的结构,大家基本上一看就能理解。
小钱袋的应用架构遵循着这么几个标准
- 标准化,每一层逻辑标准化,层级之间保持隔离
- 灵活
- 类型完备
这个标准,我们具体看在后面讲怎么实现的。这里小钱袋应用架构图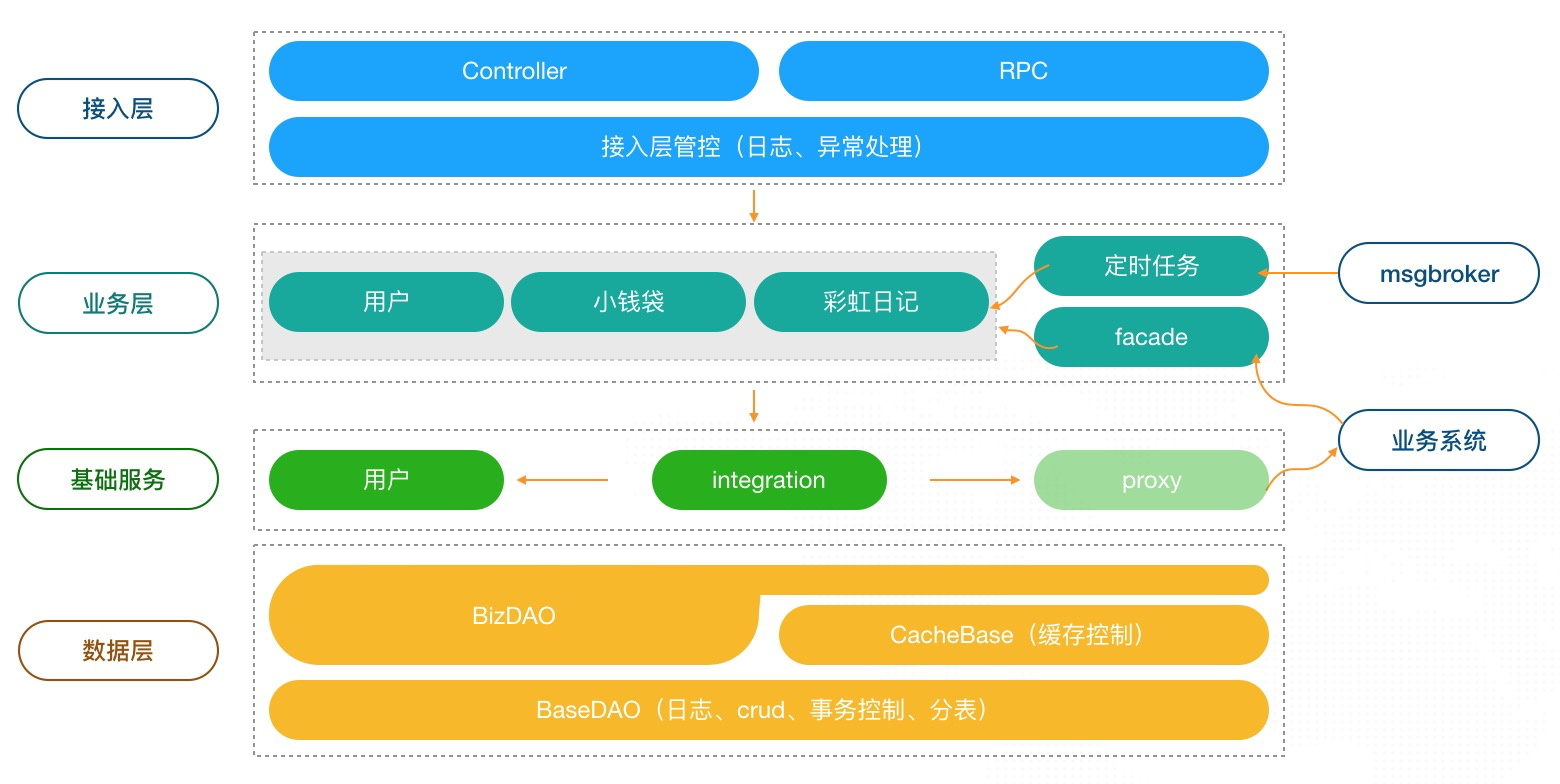
数据是从上往下,或者从下往上的单向流动。服务进行分组,同一层级依赖也是单向的,尽量减少相互交叉依赖。
下面依次看每个层具体如何设计的。
接入层
接入层是最标准化的一层,与其说是写代码,不如说是写配置。
import UserService from 'service/biz/user';import { inject } from 'egg-di';import BaseController, { LogType } from 'common/rpcBase';export default class UserController extends BaseController {@inject() readonly userService: UserService;@bizLogger(LogType.CREATE_USER, { transaction: true })async createUser(payload: unknow) {const params = this.validate(payload, [ 'nick', 'gender', 'birthday' ]);const data = await this.userService.createUser(params);return { result: data, bizId: data.userId };}}
函数最开头一个装饰器,两个入参,第一个配置了日志枚举,第二个定义了 MySQL事物控制开启。隐藏的还附带了一层逻辑,异常处理,通过这个装饰器装饰,会把函数包裹到一层 try catch 中。这个 try catch 中我们可以增加很多业务属性的逻辑的,包括
- 异常标准化
- 日志处理
- 事务控制

接入层 base 处理基本逻辑如下流程图
这几个事情实际上需要也最应该在接入层统一处理了,有了明确异常处理,我们可以记录这个请求的结果是成功还是失败。对于失败,也可以区分已知异常还是未知异常,对于未知异常可以进行业务报警。
有了统一的异常处理,在其他层中,可以更放心的把异常抛出来。在 service 层,我们可以遵循 所有 service 方法只返回成功结果,异常信息通过自定义异常抛出 的标准。遵循这样的原则,对于减少思维负担很有用的。比如我们写鉴权逻辑
/*** 是否是小孩家庭的户主*/async checkIsMaster(userId: string, guardianId: string) {// 是否是小孩的家长const guardian = await this.checkIsGuardian(userId, guardianId);// 是否是户主if (!guardian.isMaster) {throwCustomError(ERROR.E_NOT_MASTER);}return guardian;}
如果一个函数同时返回成功和失败两种数据,那么这对于使用者是很麻烦的事情,如果当前层无法处理的异常,需要把异常一层层手动抛出去。同时,这种结构在 ts 中是很难写类型描述的。后来我们慢慢全部改成了异常直接抛出的方式,这种方式更适合在应用内部之间处理异常。对外接口,我们可能需要把结果包装为成功和失败两个不同的状态。
如果后续需要处理异常,在这里可以开启事务,后面可以自动化处理事务提交和回滚逻辑。业务代码开发过程,就可以完全忽略事务存在了。
这里单独记录日志,可以准确区分系统异常和业务自定义异常。对于系统异常,这种属于非常严重的问题,我们可以加入到报警系统。另外,有了统一的日志,可以在 xflush 上做一个业务日志报表。
业务层 & 基础层
这两层,就是 chair 文件结构中的 service 。这里每个框就是一个文件夹,一开始我们就全部放在 service 目录里面,打平结构,可以说只有业务层。
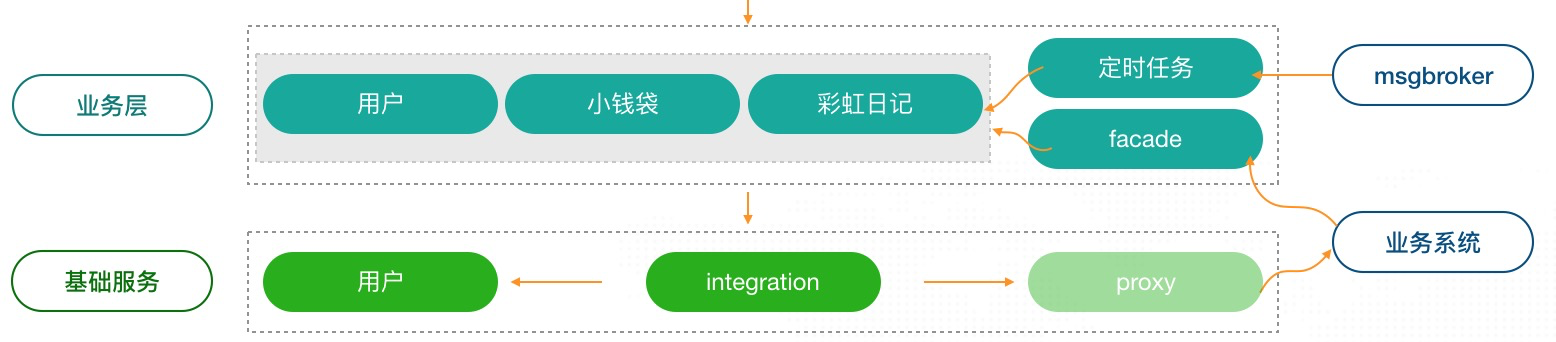
分层的核心在于数据单向流动,服务之间尽量少的相互依赖。一开始小钱袋我们在服务层经常会出现循环依赖的情况,这样会导致整体结构混乱,服务之间还是交叉、混杂在一起。有了隔离,但是隔离做的还不够。
分层不只是目录结构更清晰,更重要的是内在逻辑结构的清晰,这样看代码的可以一眼理解系统逻辑,写代码的时候尽量有据可依,不需要太纠结新的代码放哪里,有了这样的结构,多人合作才不会混乱。如果新加代码放哪里这个问题是模糊的,很容易出现同一份代码多处实现,有多种使用方式的情况。这非常不利于后续的维护,碎片化的代码多了,代码就开始腐化了。
小钱袋一开始做的时候,是没有领域层概念。当我们慢慢把用户服务中公共部分抽离出来,我发现用户服务会被所有业务层依赖,但实际上依赖的方法并不多。这几个方法抽离出来,就可以构成 user 的领域服务了。这样业务层之间不再需要相互依赖,user 领域服务层下沉。这样一改结构清晰多了。大致变动如下
一开始是相互交叉依赖,这个图是已经被我简化过很多的依赖关系,实际依赖关系图要复杂得多
第一次改进,把 User 拆分成 BizUser 和 UserDomain ,依赖关系一下子清晰多了,我们可以进一步优化,把 Trade 拆分
Trade 拆分后,依赖会更加清晰,不过线还是很多,但都是单向流动,就不至于乱,我们也可以直接抽象成分层之间的依赖 Biz —> Domain
小钱袋这样规模的应用,领域层并不是必须的,我们参考了领域驱动设计的思想,但并不完全基于此实现。
业务层和领域层的区别没有那么明显,关键是是否会形成循环依赖。简单业务情况下,可以直接写业务层,更加简单灵活,比如上面 User —> Diary 的依赖 。当一个服务被多个服务依赖的时候,需要把业务层和领域层分开,否则会业务之间会耦合在一起,越来越难以维护。
数据层

数据层主要处理数据库相关逻辑,每个数据表对应一个 dao(Data Access Object)。数据层封装了两个 Base
- BaseDAO 负责处理基础的日志、简单 crud 封装、事务控制、分表相关逻辑
- CacheBaseDAO 缓存相关逻辑
对于开发者,我们大部分时候只需要写简单的 BizDAO ,基本结构如下
BaseDAO
主要负责处理逻辑
- 数据结构转换,保证输出的结构都是和标准 do(Data Object) 对象
- 日志、简单 crud 封装、事务控制、分表相关逻辑
mysql 是关系型数据库,所以只能表示二维结构,在 ts 对象中,会包含更多数据结构。我们的数据库要求数据表命名必须是蛇形(snake case)命名,在 ts 里面,我们用的都是驼峰命名,数据流入数据库之前,需要做一次 deconvert ,key 转换为蛇形,反之亦然。
基础的 create、update、read(query/queryAll)、delete(update) 方法,而且都和泛型 T 保证关系。这样 BizDAO 写的所有方法,基本上都可以有完备的类型。
类型完备分为两个流程,数据流出和数据流入,流出入口是在 BaseDAO ,从这里出去的数据,全部都是 do 对象,通过手动写接口描述文件。数据流入,来自 controller ,经过统一的 validate 方法处理,得到过滤后的合法的数据结构。
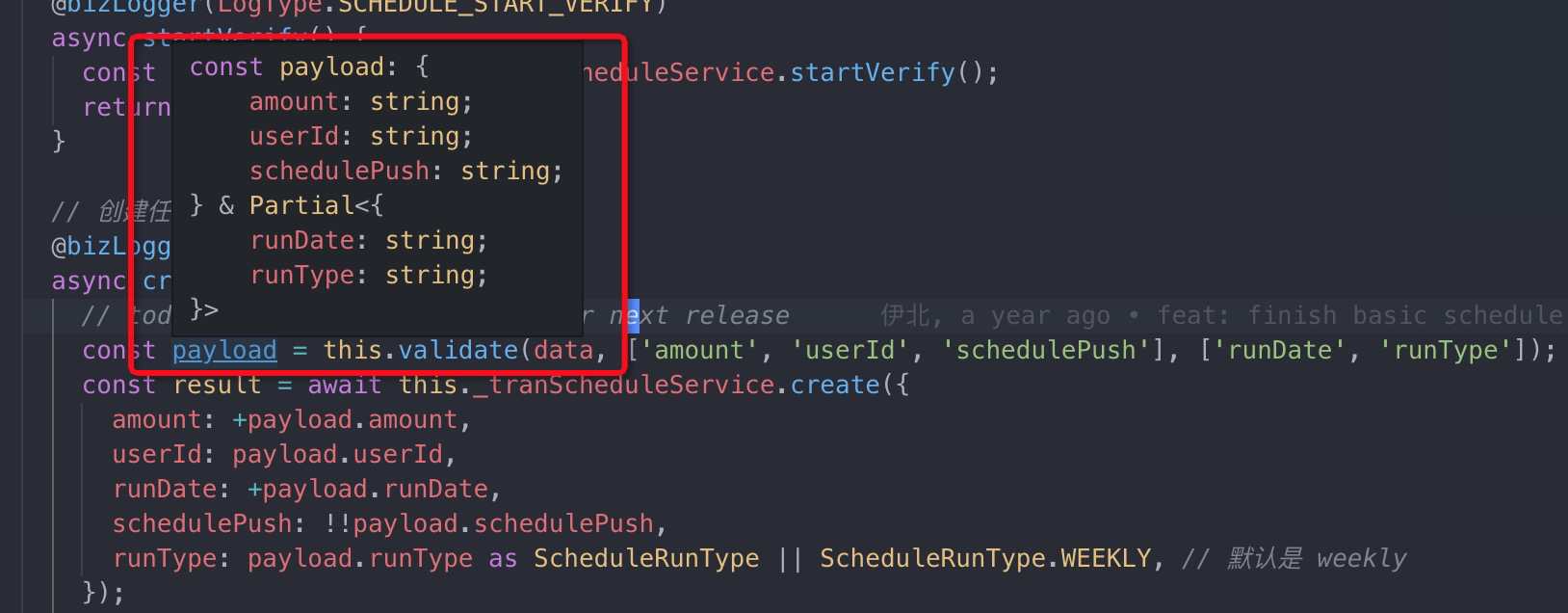
从 controller 过来的数据都是 string ,如果我们不小心处理,很容易当成 number 来用了,这种在 js 中有时候会给你意想不到的惊喜。
日志实现也很简单,所有的 sql 都经过 base ,我们只需要对 sql 查询方法进行一次代理。记录 sql 日志,我们可以做一个 sql 报表了,这本应该是 zdal 提供的逻辑,但是 chair 版本的 zdal 有点太简单了。

有了这个报表,可以对 sql 进行更细致的业务报警处理,比如小钱袋处理的
- sql 查询超过 300ms 报警
- 对查询量最大的 sql 加上缓存层,提高性能优化
- 在分表业务的时候,可以定制一个分表切流大盘,观测分表流量是否正常
对于大流量业务,监控是强需求。没有监控,后续的优化无法做,做了也无法评估。
事务控制和接入层相呼应,接入层控制开关,开启事务逻辑后,在 base 层代理使用事务连接进行查询,两边都在 base 层中处理,对于业务开发来说,基本上不需要考虑事务。
踩过的坑
最后总结一下小钱袋应用遇到过的一些故障,服务端的问题相对来说比较少,大部分异常都和数据库相关。这里主要说下三个比较典型的问题
数据库性能
小钱袋最开始上线的时候没有做压测,业务量一直很小,问题并没有暴露。有一次运营在腰封推广了 1000w 余额宝活跃用户,然后服务器直接挂掉了。数据库服务器直接 cpu 慢了,导致所有的请求都开始堆积,业务基本上挂了半个小时。
问题原因就是没有命中索引,导致每次查询都需要扫描几十万行代码,耗时 100ms 左右。这在业务量小的情况,问题并没有暴露。后来我们加上了 MySQL 监控,并且在 MySQL 查询超过 20ms 的情况,就要开始排查问题了。
后来我们结果几次压测,MySQL 命中索引的情况,性能是非常好的。最高集群压到 1w qps ,数据库毫无压力,可以继续压,不过八台应用服务器已经有点扛不住了。小钱袋也完全达不到那么的业务量,就没有继续压测了。
业务唯一性保证
我的经验,唯一索引是唯一值得信赖的。业务逻辑总是可能会有漏洞,最终只能数据库兜底,来保证业务的唯一性。
小钱袋遇到一个故障是子卡重复问题,这个问题本质上是业务唯一性失效导致的。
业务上,每个小孩对应一个余额宝子卡,资金存在余额宝子卡中,我们有两个表,一个记录小孩,一个记录子卡信息。有一段时间,有一部分用户最多只能开一个子卡,当时我们在业务逻辑上保证了,一个用户只能创建一个小孩。
但漏掉了一个非常小的场景,导致这个逻辑失效,一个人可以同时创建三个子卡,但是子卡创建的时候,余额宝返回了同一个子卡。这样,三个小孩用同一个资金账号,最终影响了线上四百多个用户。这是我们距离资损最近的一次故障了。
这种场景如果有加小孩 id 和子卡号唯一索引,那么这个用户只会开户失败,不会出现数据错误,这种错误在金融领域有可能导致严重的资损,一定要非常小心。
金额不对等的问题
小钱袋多人转入过程,实际上是 A 转给 B ,然后 B 转入子卡,两个流程。上线初期,我们遇到过 A 转给 B 0.88 元,到第二个步骤,变成 B 转入子卡 0.89 元的故障。
因为在第一步只冻结了 0.88 ,到第二个流程自然就失败了。收到了线上解冻失败报警后,排查了一下发现问题是这样的
在一个活动场景,用户输入了 0.888 的金额,在第一阶段,这个金额被转账处理成了 0.88 。同时数字传递到小钱袋服务器,小钱袋并没有过滤处理,直接给了 MySQL 数据库,数据库字段是 decimal(15,2) ,自动四舍五入变成了 0.89 。
这个问题解决很简单,这种 0.888 的金额,应该做一层服务端拦截的,否则还是很容易出现问题的。后来看 Java 应用,一般金额用 int 存,单位为分,而不是元,这样处理更合理。
总结
小钱袋应用首先选择了 TypeScript 作为服务端开发语言,并且逐步完善类型体系,尽量做到应用整体类型完备。
经过一段时间发展,业务层越来越复杂,在尝试对业务层进行分组的时候,我们选择了使用依赖注入的方式,做到服务之间可见性可控。慢慢在业务层中抽象一些领域服务下沉到基础服务中,最终实现业务层和基础层数据单向流动的结构。
小钱袋应该规模相对于 Java 应用来说,还是非常简单的应用。小钱袋本身也是在逐步发展、演变成现在这样,还是有很多不完善的,感觉整体上参考 Java 是一个比较合理的方向。

若有收获,就点个赞吧
0 人点赞
