发布时间:2016 年 12 月,迁移之后置顶了
凤蝶是蚂蚁金服营销活动搭建的平台,本文主要介绍凤蝶可视化编辑是如何实现的。
概述
可视化编辑实现架构图如下:
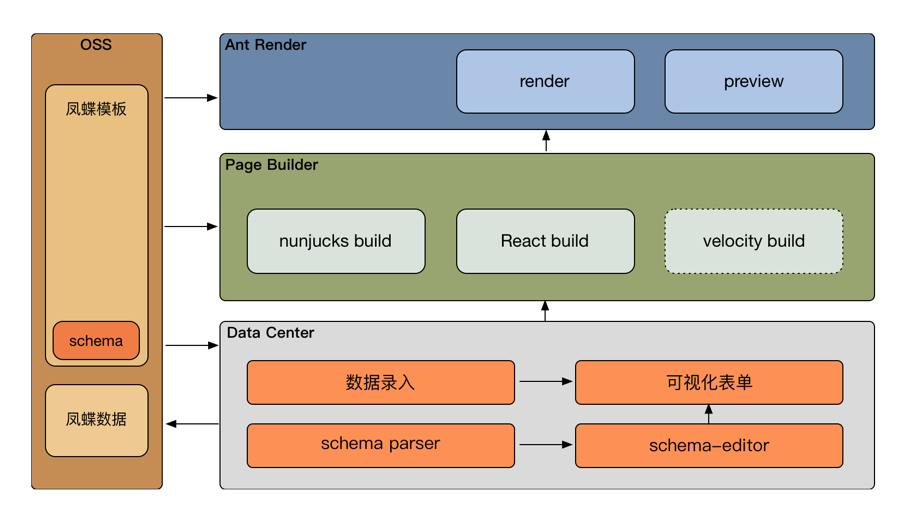
凤蝶主要有两个功能模块
- 数据中心,通过定义一套数据描述语法,开发者来自主描述数据结构,运营编辑数据,最终产出页面需要的数据
- 页面生成器,构建成前置容器(basement.render)可渲染的文件
本文主要介绍数据部分实现逻辑,页面生成相关后面再找机会再写。
现在凤蝶活动数据主要来源都是运营手动录入,为了支持动态输入、排期等功能,我们实现了凤蝶数据模块。凤蝶数据实现了一套数据自动更新导入逻辑,这是一块还在 0.5 阶段,也比较复杂,后面更完善了可以单独来介绍。
凤蝶可视化编辑实现,主要分两个功能模块
- 数据描述语法 schema parser
- 可视化表单 schema-editor
凤蝶 schema
开发者通过凤蝶定义数据描述语法(凤蝶 schema)来描述需要运营输入的数据结构。
凤蝶 schema 是一种特殊的领域语言 DSL(Domain Specific Language) ,是基于 jison 实现的。
比如一个基本的数组描述如下:
Array(foo) {href(href): URLtitle(title)img(image url): Imageamount(money amout)}
基本语法结构非常简单。对于前端工程师而言,json 是最友好的数据结构了,凤蝶 schema 描述就是 json 数据结构。数据结构上主要分为集合和原生类型,和普通 json 类似集合数据结构是支持嵌套的。凤蝶 schema 最终会解析为 JSON Schema 数据对象。
JSON Schema 本身用于描述数据 json 结构是非常合适的,但有一个非常致命的问题:对于使用者而言,直接描述 JSON Schema 太繁琐了,出错概率非常高。所以淘宝 tms 在使用 JSON Schema 的时候,还同时提供了在线编辑 schema 的工具。还有一种方案就是通过 json -> schema 的转换,来简化 schema 描述过程。
上述两种方案,开发者都需要理解 JSON Schema,在我们看来这是不必要的。为了解决 JSON Schema 书写非常不方便的问题。凤蝶在如何描述 json 数据上也探索过很多方案,最终参考 graphql 的模式通过语法描述来定义数据格式。这种方式就是上面例子所示的代码,选择这种模式,主要基于以下考虑:
易上手
这种描述本身和 json 数据格式或者 js 对象描述是非常接近。这对于开发者而言,只需要看几个基本的例子就知道如何来定义自己的结构了。
凤蝶 schema 简化了 JSON Schema 所有不必要的信息。这样描述数据结构的时候不需要关心 JSON Schema 如何描述的,开发者只需要关心他需要的数据结构就可以了。
在描述凤蝶 schema 的时候,开发者关注三点
- 数据类型:每个字段是什么类型的
- 数据结构:字段的 key 是什么,基本结构关系是什么
- 数据含义:每个字段如何让运营知道其含义,方便运营编辑
凤蝶 schema 中所有需要描述的都和这几点有关,没有多余的信息。
举个例子,我们需要描述一个简单的对象
{a: "string",b: "image"}
如果使用 js 来描述,会缺失第三点,数据含义,直接 a,b 这种 key 是给开发者用的,运营必须用中文描述字段含义。
使用 JSON Schema 描述是这样的
{"title": "test","type": "object","properties": {"a": {"type": "string","title": "这是字段描述"},"b": {"type": "image","title": "这是字段描述"}}}
一共 13 行代码,是原生数据的 3 倍,使用凤蝶 schema 是这样的
Object(test) {a(这是字段描述): Stringb(这是字段描述): Image}
和 js 描述代码行数一致,结构也是基本一致,只增加了必要的字段含义描述而已。
容易扩展
凤蝶 schema 是自定义语法规范,可以很方便的扩展,支持更多高级的特性描述。比如自定数据类型、描述字段校验、数据类型、字段之间的关系等等。
比如凤蝶中比较常用的 box 类型的数据,用来描述一个 dom 元素相对父容器位置,对应开发者而已就是 css 属性集合(width, height, top, left)。在凤蝶中,可以直接通过
Object(test) {pos(pos): Box}
来获得一组完整的描述 dom 位置的数据,而这份数据运营可以通过拖拽来实现输入。这种数据格式通过凤蝶 schema 以及配套的渲染、mock 工具方法,开发者可以灵活使用 box 在任意元素上,运营则可视化拖拽元素的位置。
另外,可以通过扩展语法,来描述数据之间的关系
Object(enums) {enum(锚点选择): Enum [ source: "urls" ]urls(urls): Array {label(名字)value(链接)}}
上面代码描述了一个对象,包含一个枚举和一个数组,而枚举中的可枚举的数据来源于这份数据的数组。
schema-editor
schema-editor 基本结构是这样的
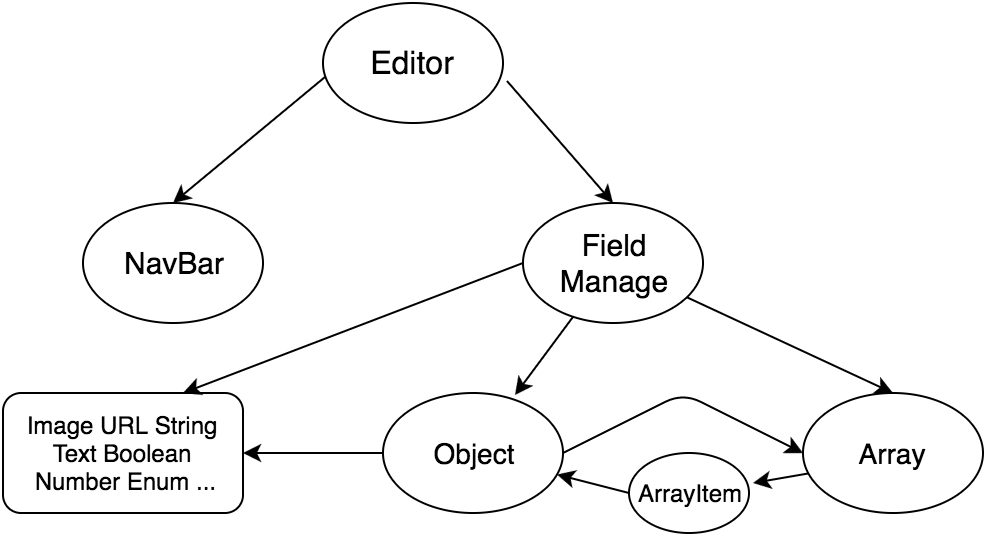
渲染是树结构,最上层 Editor 负责数据准备以及对外接口,处理输入和输出。最下层每个对象与 schema 的每种类型一一对应。
渲染过程是从上往下数据流,数据修改则是反向的事件流。
渲染过程
渲染完成后,最终得到一个运营可编辑的表单。参考上面的树结构,可以看到字段渲染是相互嵌套的,对象的子节点可能是对象、数组,数组的子节点包括对象。
这种对象嵌套的树结构在程序实现上并没有什么问题,但如何在视觉呈现上让运营理解,是比较困难的。通过加导航条来实现任意层级结构。
实现原理也很简单,每次进入 Object 的时候,如果下一级节点是对象,渲染一个可点击的元素,其他元素正常渲染。这样,页面只展示了第一级可编辑的节点。而嵌套的对象节点,通过点击触发进入子节点对象的编辑状态。
具体效果点击下图:
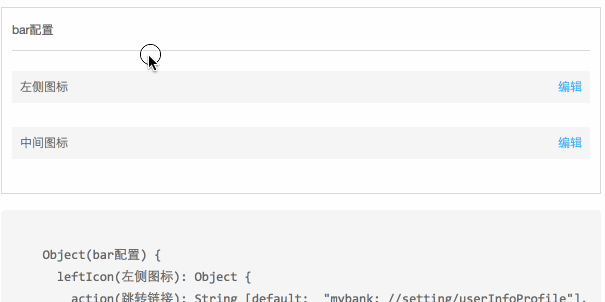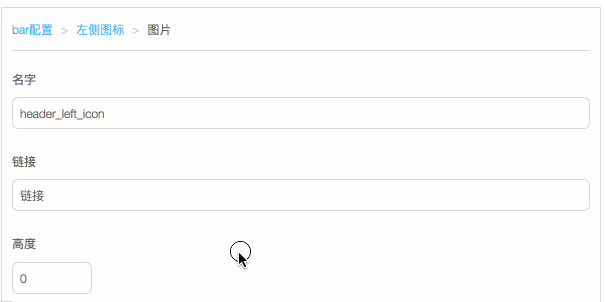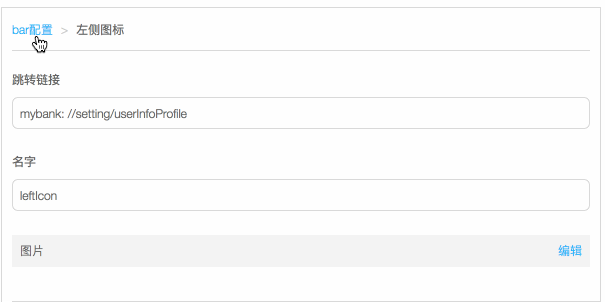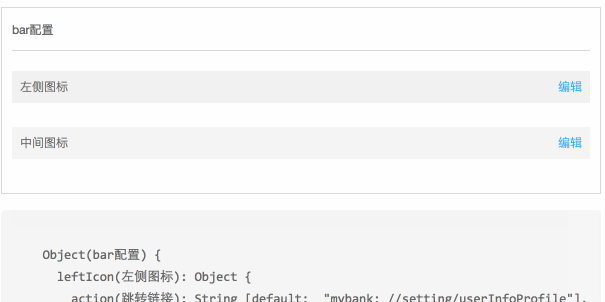
可以实现上述效果,有一个很重要的条件,每个 schema 节点都是一个完整的 schema 结构。在 schema-editor 中,所有 Field 都是基于统一输入来渲染的,所以渲染过程中层级切换过程中,对于 FieldManager 来说是没有任何区别的。
所有的节点渲染都是基于这样模式渲染的
<Field schema={schema} data={data} onChange={}>
每个节点统一输入,同时基本输出也是一致。通过这样的规范,还可以自定义任意类型数据的渲染,满足不同业务的个性化需求。
数据修改过程
数据修改是基于事件流,从根节点触发,一直冒泡到最外层容器。
每个节点都有基于相同的输入和输出模式,输出主要是 onChange 事件行为。每个节点都有一个 onChange 的 prop 传递过来,当节点被修改的时候,调用 onChange 方法,开启事件流。
this.props.onChange({ value: val, fields: [ this.props.field ] });
根节点的父容器一般都是 Object / Array 这种集合元素。父节点 onChange 方法只需要把子节点的事件继续往上冒,同时增加路径信息(在 fields 中添加当前元素的 field)。
onChange(e) {const field = this.props.field;if (field !== undefined) {e.fields.unshift(field);}this.props.onChange(e);}
一直到最外层容器,通过事件对象 e 就可以知道两个信息
- 修改后的数据的值 value
- 数据所在节点的路径,基于这个路径从数据根依次查找,找到最终节点,然后修改数据
通过这样的策略,可以实现任意节点的数据修改。每个节点本身只需要关注自身数据修改,然后按照约定抛出事件。
在子节点中还可以在事件中添加一些附加信息,来说明当前修改的值的含义,包括基本的数据修改、数组添加、删除等。基于这些信息,可以对某些数据改造执行一些特殊的逻辑,譬如数组添加的时候对其中某些数据进行去重,图片修改的时候获得图片的背景颜色。
总结
schema-editor 基于自上而下的数据流渲染,统一所有数据类型渲染的输入和输出,结合层级导航,可以完成任意层级数据的展示。
通过事件流接力棒式从下而上传递,可以完成任意嵌套层级的数据修改。
本文主要介绍了凤蝶活动可视化编辑实现中数据层具体实现逻辑。schema-editor 面向运营输出可操作编辑表单,凤蝶 schema 语法提供给开发者描述模板中需要的数据结构。schema-editor 是一个 React 组件,其他有类型需求的,也可以直接引入。凤蝶可视化编辑实现其他相关内容,以后再整理。

若有收获,就点个赞吧
0 人点赞
