前言
本文和一篇文章有一些类似,本文写于 cod 平台诞生后半年,cod 从诞生,达到了稳定程度,理念上有了一些更加完备的设计
Cod 是一个动态 tr 解决方案,简单说就是动态 tr 接口转发,在 tr 动态能力之上,我们加上了逻辑运算、依赖的支持,走向了服务编排这条路。
公司内部已经有很多团队在做服务编排了,大部分都从可视化编排入手,Cod 特色在于,我们做代码编排。我们认为,我们的用户是专业的前端开发,代码是更合理的接口形式。
下面慢慢介绍这个过程是如何一步步发展而来的。
问题
自从有了 BFF ,后端就开开心心的安心写服务,Controller 逻辑都丢给前端了。
这导致我们需要维护发布一个服务端应用。在业务中,有大量 BFF 接口做的事情模板化的,入参读取 -> 调用 tr -> 返回数据。
为了解决这个问题,团队砂瀑做了 common.invoke ,通过一个接口,转发到 proxy 的方法。调用方式大致如下
await getRPC('common.invoke', {method: 'healthUserFriendListFacade.queryRemindSwitch',params: { bizType: 'XHB_BIZTYPE' },});
这样简化了很多,以后每次 BFF 接口,只需要新增 proxy 配置,然后发布一下就好了。
但还是会有些麻烦,发布一次本身成本很高,我们就开始思考,能不能不需要修改代码、发布应用,直接动态调用 tr 接口呢?答案就是我们的第一版 Cod 。
动态 tr 实现
有一个和我们类似的产品陆游,他们也同样实现了 hsf 接口的动态调用。他们主打的是代码热更新平台,这体现了我们两者实现的区别,Cod 不做代码更新,我们发布的都是配置,没有动态执行代码的能力。
我们决定坚持一个原则,代码发布,应用发布,可以动态化的只有配置,这也是符合标准应用开发的基本原则。动态下发代码,安全性和可维护性保障是更加困难的,我们的目标场景是替代 BFF 开发,自然需要面对最专业的前端,最高频的接口场景,稳定性,安全性和性能上,是必须等同于标准应用开发模式的。
原理
整体上,实现并不复杂,先看看实现流图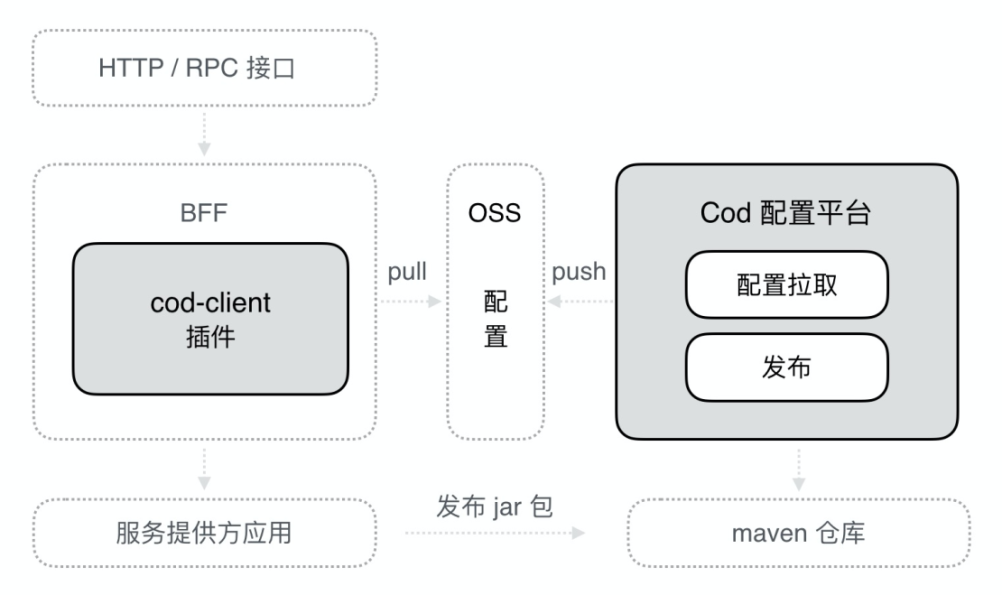
目前,主要分为两个大的部分
- cod 平台,cod.alibaba-inc.com 。主要管理应用,jar 包,最终完成接口配置下发。通过这个平台,调用 jar2proxy 生成 jar 包类型元数据,最后由开发者负责发布接口配置。数据通过 filesync 同步到 chair 应用的区块上
- 完成配置下发后,第二部分负责执行 tr 动态调用,这一部分,是一个 Chair 插件实现的
采坑
动态调用本身并不复杂,框架已经封装的很好了,对于使用者,只需要关注请求元数据,然后就可以调用接口了。有了 jar2proxy 生成的元数据,动态发 tr 请求就可以实现了。很快我们搞定了,和老的方式对比快了很多。
但 tr 动态化以前一直没人做,这条路是不是真的通,有没有大坑都是未知的。我们摸着 API 调用成功了,但底层是否真的支持的很好,我们是没有底的,只能先跑起来在看。后来,真遇到了大坑,我们花了几个月,差一点就被埋在坑里面了。
当时一个新应用接入 Cod ,预发测试 ok ,到线上直接挂了。报一个序列化异常的错误
Exception caught in invocation. responseStatus: 18
排查了好久,然后请教了一下 chair 维护团队成员,他们恰好也在搞 tr 动态化,然后他告诉我他们遇到的坑。
根本原因
tr 协议实现最初,是没有考虑过动态化存在的可能的,在调用的很多链路上,为了提高性能加上了很多缓存逻辑。主要包括两部分,ClassMap 复用,入参预编译缓存。
ClassMap 在 Connection 层面会缓存,同时在协议层的入参预编译,会导致 tr 元数据修改了,同时还需要更新相应的缓存。
当时这个问题看起来是无解的,云凤蝶在 OneAPI 中实现,折腾了很久,最终给出一个 hack 的方案:
- 把 sofa-hessian-node 的 classMap 覆盖,不使用预编译的缓存
- 每次调用的时候先把上一个版本的实例和对应的 connection 给 destroy 掉
第一个方案解决序列化入参结构缓存的问题,第二个解决 connection 层缓存,导致元数据无法透传问题。彻底解决,当时我们想着依靠 chair 本身的升级,从底层支持动态化。
解决与思考
问题明确了,我们觉得不应该使用 OneAPI 那种方式,我们需要应用于 C 端请求,缓存本身为了提高性能,OneAPI 的方案会导致整个应用 tr 调用性能下降,这是对我们和使用者来说,都是不可接受的。
后来风棋把 tr 请求整个链路研究了一遍。给出了一个 hack 的方案,npm 包覆盖黑魔法,直接覆盖协议实现的 npm 包,支持动态化调用。反反复复折腾,终于搞出了第一版解决方案。
但始终如芒在刺,万一底层实现改了,我们不就挂了吗?而且这样的代码,我们也不好意思拿出去给别人用,只能自己用用了,也许后续只能等待 Chair 底层改造了,问了下零一,说目前还在排期。
最后,我们想明白了,这个问题对于 Cod 来说是立身之本,不解决 Cod 的基础就倒了,但对于 OneAPI 或者 Chair 来说,只是一个特性加强,锦上添花的东西。这个问题最需要的是我们自己,如果等待官方的解决,那可能永远等不到,或者半年一年以后去了。既然如此,那么我们想办法自己来搞定吧,然后就开始尝试自己来修复这个问题。
最终,经过反复的修改和讨论,风棋完成对 sofa-hessian-node 和 tr-client 进行改造,彻底解决协议层实现上无法支持动态 tr 的问题,并且不影响性能。最终代码改动不多,但其实经过几周反复讨论,修改,最终实现了让大家都觉得可行的方案。
现在回头想想,如果一开始就知道存在这么大的坑,我们可能就直接放弃了,或者等待 chair 团队给终极方案。但那时候比较尴尬,线上已经用了,牛皮也吹出去了,退无可退,只能硬着头皮上了。最终我们发现,这个问题的解决并没有想象的复杂,改动范围也是可控的。更关键的是,通过这个过程,我们最终对 tr 协议本身有了深入的认识和理解,对我们的服务本身,也有了真正底气。
codql
经过几个月的开发和填坑,底层终于稳定了。然后我们开始思考,如果能够解决更多问题。接口转发是一个场景,但还是有点局限。
Cod 从一开始就做了 simpleql ,一种简化了的 graphql 语法来查询。从这开始就支持了简单的服务编排能力,并且后来我们加上了处理器的设计,支持对数据进行一定的处理。稍微复杂的接口我们也能实现了,当时还尝试过一个非常复杂的逻辑编排
isSamePerson: Cod(method: IdentityService.isSamePerson) | get(model),hasInsUser: Cod(method: InsUserQueryFacade.getInsUser) | get(model),userNo: Cod($if: "isSamePerson && hasInsUser", method: InsUserFacade.addUser) | get(data)_attachment: Empty($$userNo) | assign($attachQuery)attachment: Cod(method: insUserAuthFacade.uploadCertificateAttachment, params: $$_attachment)
功能是支持了,但是这个查询语句大家表示看不懂,没有必要,直接写代码多好。
存在的基础:简单
最终让我决定放弃 simpleql 是源自一次集体 review ,一个项目搞定之后,我开心的和大家说,看我这次开发,所有接口都是用 cod 搞定了。小组成员纷纷表示这代码看不懂,并且发出灵魂拷问:这代码以后怎么维护啊?
看到自我感觉牛逼的查询语法,被大家嫌弃,我当时有些震惊、不解。再后来我仔细思考了很久,我想明白了,对于 Cod 服务编排来说,做的足够简单是存在的基础条件,如果做不到比写代码简单很多,就没有存在的意义,直接写代码就够了。
服务编排说起来高大上,但做到足够简单很难,矛盾点在于逻辑本身是复杂的,没法做的非常简单,但如果不够简单,开发者何不直接写代码呢?通过可视化方式来编排逻辑,我认为方向就错了,可视化是给运营、小白用户使用的,对于开发者来说,最简单最直接的还是代码本身。
如何做的简单,我们给的答案就是 codql 。
查询语法
最终我们完成一套新的 codql 查询语法,新的语法,我们只引入了 wait 和 when 两个概念,其他所有语法直接借用 js 语法,对于开发者来说是基本没有学习成本。下面是一个示例
import { cod, tr, rpc } from 'codql';const query = cod({gray: tr('GrayFacade.grayJudgeByBizCode', args),config: fengdie('insxhbbff_healthNotice'),iopData: rpc('common.insiop.get', iopParam),});const data = await fetchRPC('common.query', query);
目前,我们支持三个基本的查询类型
- tr: 发起一个 tr 请求,动态 tr 能力支持
- fengdie: 读取区块配置数据
- rpc:请求本地 rpc 方法,这个是自定义函数的支持,有些复杂的逻辑可以通和往常一样开发一个 rpc 接口,然后和 cod 其他查询结合使用
当然,我们还支持更加复杂的查询语句,主要包括
- wait 参数依赖
- when 逻辑依赖
说起来有些复杂,看看具体的例子
cod({// 调用 tr ,创建一个 topic ,得到一个 topicIdtopicId: Tr('CommonTopicFacade.createCommonTopic', data).get('model'),// topicId 作为 belongId 属性,请求创建 post 请求post: Tr('PostFacade.createPost', {belongId: wait('topicId'),...args1,},});
还有前面举的复杂例子,换成 codql ,可读性就好多了。
cod({isSamePerson: tr('IdentityService.isSamePerson').get('model'),hasInsUser: tr('InsUserQueryFacade.getInsUser').get('model'),userNo: when('isSamePerson && hasInsUser').tr('InsUserFacade.addUser').get(data)attachment: tr('insUserAuthFacade.uploadCertificateAttachment', {userNo: wait('userNo'),}),});
编排可视化
可视化是有价值的,能够让我们直接看到逻辑过程。后来我们还加上了编排可视化的支持,也就是自动把 codql 语法,转换成为 plantuml 图。比如,前面那个复制的例子,生成的图是这样的
 对于我们来说,可视化是服务编排的结果和辅助手段,有了图,我们可以更方便的理解逻辑流程。
对于我们来说,可视化是服务编排的结果和辅助手段,有了图,我们可以更方便的理解逻辑流程。
总结
经过将近一年时间,我们慢慢摸索出一套 Cod 特色的服务编排解决方案。目前正式对内部使用了 5 个月时间,一共有 8 个 BFF 应用真实使用,主要覆盖了相互宝、保险理赔、保险平台等业务中,每天接口访问量目前在 1500w 左右的调用量。
目前,cod 处于功能基本稳定,开始准备对外推广的阶段了。
一路走来,我们坚持着三个基本原则
- 下发数据配置
- 代码编排
- 简单是存在的基础
有了第一个原则,我们才可以在前端编排逻辑,流程上整体会很轻便。我们坚持应该给开发者代码形式的接口,而不是可视化操作,也就是我们所谓的代码编排。最终,通过 codql 和编排可视化,让整个编排过程足够简单,可理解,可维护。

若有收获,就点个赞吧
0 人点赞
