区块为应用提供便捷的数据编辑与快速发布上线的功能,在内部 egg 应用中使用非常普遍。本文主要介绍一下区块功能实现方案的历史,以及区块一个文件丢失的遗留 bug 排查过程。
凤蝶区块 1.0
凤蝶区块功能源自最初的 cms 区块,cms 区块就是一段 html 代码片段,中间有一些占位符,可以让运营编辑,功能上是支持把页面的一部分支持动态配置。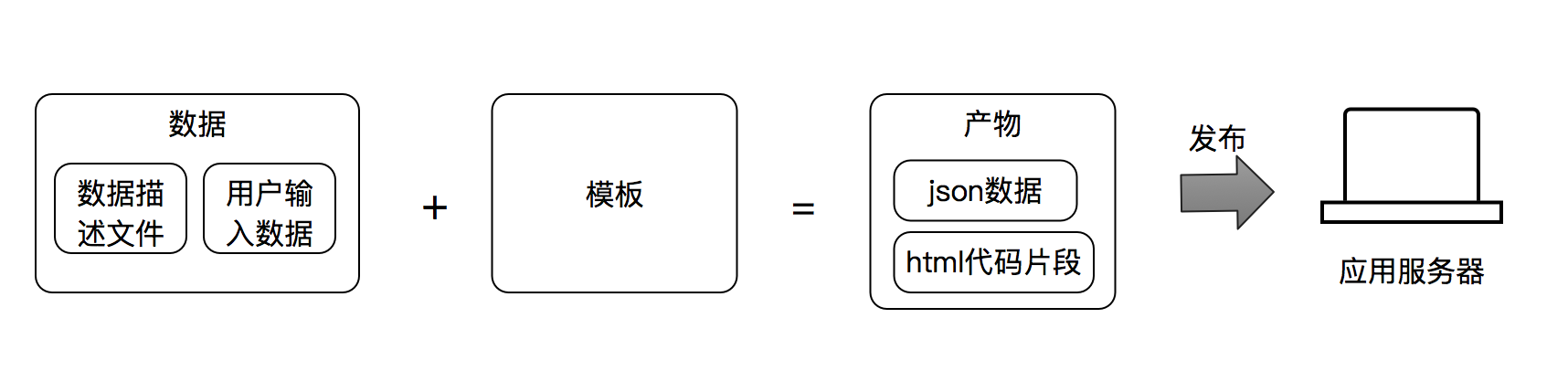
最初版本的凤蝶也是同样的基本思想,但是凤蝶设计把数据描述独立出来,数据部分慢慢成为了区块最核心的功能,模板功能慢慢被使用者弃用了。1.0 fengdie 插件功能设计非常简单,agent.js 监听 uiweb/fengdie 目录,文件夹有变化,直接触发一个更新的消息。然后 app.fengdie 依次读取本地文件夹所有的 json 文件,读取内容,注入到 app.fengdie 。
 文件初始化由 chair 构建脚本负责初始化,读取凤蝶平台的
文件初始化由 chair 构建脚本负责初始化,读取凤蝶平台的 /api/cms/install 接口,得到所有依赖的 json ,写到本地。开发环境由 chair-bin 负责实现同样的问题。
文件更新由凤蝶平台完成,凤蝶服务器直接通过 zpublish 服务发布文件到应用集群,文件更新后,由fengdie 插件负责更新内存数据。
这套方案就是主动推的模式,文件由凤蝶主动推送到应用服务器,这样有几个问题
- 依赖环节过多,插件同时依赖了凤蝶站点和构建脚本,本地开发还需要手动触发初始化
- 推模式发布慢,大的应用有几千台机器,zpublish 批量推送非常慢,并且 zpublish 稳定性是一个瓶颈,大批量推送,经常会有失败
- 更新机制,每次都是全量触发文件更新,会导致更新的瞬间,cpu 消耗过大
fengdie-pull
针对 1.0 版本的问题,后来不四开发了 egg-fengdie-pull 插件。相对于 1.0 的 push 模式,新版本最大的特点是改用 pull 模式。实现逻辑如下
 主要区别在于文件初始化和更新逻辑,全部由插件自身从 oss 下载文件,更新逻辑由凤蝶主动推送改成客户端拉模式。每分钟触发一次 head 请求,检查配置文件是否有更新,更新的时候下载更新的文件,然后只更新修改的部分。
主要区别在于文件初始化和更新逻辑,全部由插件自身从 oss 下载文件,更新逻辑由凤蝶主动推送改成客户端拉模式。每分钟触发一次 head 请求,检查配置文件是否有更新,更新的时候下载更新的文件,然后只更新修改的部分。
这样模式,一方面 oss 稳定性更高,同时客户端主动拉,应用机器数量不再是瓶颈,发布时间相对更加可控。更新也是局部更新,不会出现批量更新导致服务器 cpu 负载过高。
问题
新的 fengdie-pull 插件很快替代了老的模式,但是实际使用中,遇到一个非常严重的问题,文件丢失。
所以在业务线最佳实践里,凤蝶区块使用都是要做非空判断的,比如
const config = this.fengdie.insmutual_health_notice_switch || {};const { date = '2019-05-01' } = config;
区块数据有些可以兜底,有些是没法兜的。比如配置的一些抽奖活动 id ,没有活动就挂了,这是一个非常严重的问题了。
fengdie-pull 插件在 4.x 版本修复了数据丢失的问题,但是 chair 1.4 版本还是使用老的 3.x 有问题版本。并且,chair 中间件维护者,也不打算继续维护老版本的插件了。线上出现好几次问题,我们只能通过服务器重启或者重新发布区块解决。但这个问题始终是一个定时炸弹,随时可能爆炸。
当然,升级框架是一个彻底解决问题的好方法,但是保险业务 bff 应用集合了八百多个接口,测试回归成本太高了。有点积重难返了,就像凤蝶最初的渲染容器 cmspromo 系统,上面承载了一堆历史遗迹,render 替代渲染容器将近四五年了,cmspromo 还是保留在线运行着,只是机器非常少罢了。
无法升级,可以先让这个应用变得慢慢不重要,随着时间流逝,改造的风险也就越来越小了。
第一次尝试
面对上面的问题,chair 官方已经没法依靠了,升级也没那么快,那只能靠自己了。
花了半天研究了一下 egg-fengdie-pull 插件的源码,代码不多,看由于引用了一个 sdk-base 的包,而且代码流是通过事件触发,有点没看懂。
通过调试,找到代码 fengdie.xxx 读取逻辑部分代码
Object.defineProperty(this, key, {get() {// 优先从拉模式获取,文件不存在时通过推模式容灾if (this._pull.store[key]) return this._pull.store[key];if (this._push.store[key]) {// 因为现在文件都落盘了this.emit('warn', [ '[failover][%s] from file', key ]);return this._push.store[key];}},});
但线上问题出现的概率非常低,无法重现。只能靠猜测,也行 fengdie.xxx 调用的时候, this._pull.store 和 this._push.store 里面的数据都丢失了,那么在这里加一段兜底逻辑,也许就好了吧。
if (this._push.store[key]) {return this._push.store[key];}+ return this.failover(key);
当然,最终这个修复方案发布后,线上问题依然存在的,这个兜底逻辑完全没有进来。我也忙于业务开发,问题暂时搁置了。
第二次尝试
一直到三个月后,线上这个问题又重现了。我们接到营销那边报警,错误是活动 id 为空,找到对应的代码,活动 id 配置在凤蝶上。很明显,区块为空的问题重现了。
第一次修复的方式,后来想想,兜底失效还是因为 defineProperty 本身没执行,所以自然无法正在兜底了。关键还是在于,没有定位到问题的真正原因。
问题重现了,没有办法,只能继续硬着头皮上了,这次一定要定位到问题真正原因。如果实在不行,那只能对 app.fengdie 做一层代理了,找不到的 key 直接进入到兜底逻辑。
这个问题最难的点还是在于没有找到问题重现的步骤。
日志分析
首先,只能从日志里面分析了。首先,基于有问题的 traceId 找到对应的 rpc 接口。然后查询了一下这个 rpc 接口的所有请求记录。这时候发现一个规律,同一个 rpc 请求,大部分都是正常的,有一小半的是报错了。通过肉眼可以看到,这些报错的请求,都是源自统一进程 id 。
继续排查这个进程对于的请求,所有的请求都挂了。这时候可以推断出,只有这一个进程是挂了的,其他三个进程是没问题的。这个进程的特殊之处在于,它是昨天启动的,那说明这个进程之前,有一个进程挂了,然后 chair 主进程重新启动了一个子进程。
现在找到问题出现的一个必要条件,进程挂掉,重启的时候可能会出现问题。
开发机调试
接下来我拉了一个新的测试迭代,部署了一台测试机。同时修改业务代码,让代码在特定请求下主动 throw 一个无法捕获的异常,主动挂掉进程。
if (fengdieData.error) {setTimeout(() => {throw new Error('haha');}, 20);}
这时候,请求接口,如果传递了一个 error 为 key 对象,接口就直接会导致进程重启。但试了几次,还是无法重现问题。看了很久,只能暂时再等等看了,线上场景是放一段时间,然后突然不行了,我也先放放吧。
第二天早上,开发机真的重现问题了。难道,规律是重启后等一个晚上,内存数据就丢失了?这里的逻辑还是不通,但已经好很多了,我感觉越来越接近真相了。
增加日志
问题重现了,但是还是无法定位到原因。还得再加点日志才行,于是我把 egg-fengdie-pull 源码修改,增加了一批日志,发布了一个新的 egg-fengdie-pull-1 的包,在应用代码中强制指定使用新的测试包。
开发机重现构建部署,继续重复昨天的步骤。到第二天早上,尝试重启进程,问题果然重现了。这时候有了更多的日志,可以方便分析了。
2019-10-10 22:12:41,433 INFO 4577 [egg-fengdie-pull] defineProperty fengdie.instrabem_sample from Pull2019-10-10 22:12:41,458 INFO 4577 [egg-fengdie-pull] init with config: {"ossRoot":"http://alipay-rmsdeploy-image.cn-hangzhou.alipay.aliyun-inc.com/filesync/dev/z/fengdie","configUrl":"http://alipay-rmsdeploy-image.cn-hangzhou.alipay.aliyun-inc.com/filesync/z/dev/insbffweb.json","backupDir":"/home/admin/run/fengdie_cache","pushRoot":"/home/admin/uiweb/fengdie","dumpRoot":"/home/admin/uiweb_dump/fengdie","cmsPushRoot":"/home/admin/uiweb","checkInterval":60000,"fileBackup":false,"dumpVm":false,"lru":null,"reportEndpoint":["https://filesync.alipay.com/report"],"pullUitpl":false,"uitplUrl":"https://gw-office.alipayobjects.com/basement_prod/3af05f6b-b0cc-4c88-9dda-e8de1c365caa.tgz","uitplRoot":"/home/admin/uiweb"}2019-10-10 23:05:27,585 WARN 4577 [egg-fengdie-pull] [failover pull][insbffweb_common_fuse] async loading2019-10-10 23:05:27,588 INFO 4577 [egg-fengdie-pull] read file from dumpRoot insbffweb_common_fuse
看到些日志,问题很明显了,新重启的进程 4577 初始化的时候,只 defineProperty 了一个文件。
上 basement 控制台看了下 instrabem/sample 这个文件,恰好在 22:12 这个时间发布过,问题重现的第二个步骤也找到了。
从日志上来看,先发布一次区块,然后触发进程重启,这个新启动的进程就会异常。
问题重现
基于上面的猜测,服务器重启,然后发布一个区块,再触发进程重启,这时候果然文件丢失的问题重现了。
这里走过一次弯路,第一天重现的时候,当时有过猜测,是否和区块发布有关。当时还尝试过发布一个区块,但当时发布的那个区块并没有被 insbffweb 应用引用,自然不会触发区块更新,导致多排查了一整天。
找到问题重现的步骤,后面修复就简单了。
问题修复
egg-fengdie-pull 插件本身的运行原理大致是这样的
 凤蝶区块会启动一个 agent 进程,用于负责文件相关操作,初始化文件读取,区块更新事件监听以及成功上报。
凤蝶区块会启动一个 agent 进程,用于负责文件相关操作,初始化文件读取,区块更新事件监听以及成功上报。
work 进程负责正在的请求逻辑,work 进程启动的时候,会监听 pullConfigFiles 事件,这个事件由 master 来控制,这里可以具体参考 egg 文档 多进程模型和进程间通讯 。
问题出现在,当文件有更新的时候,事件 pullConfigFiles 的内容变成了 diff 后的数据。所以,这之后如果有进程重启,只能拿到最近一次发布的区块文件。
修复方式也很简单,把初始化和更新两部分换成两个不同的事件,这样进程重启的时候就不会被更新逻辑影响到了。
chair 官方有过处理这个问题,新版本的插件修复方式是绕过了这个问题。进程重启的时候,由 work 主动拉所有的文件,而不是通过 agent 通知。当时 chair 维护者也没有定位到真正的问题,只是通过换一种实现方案来解决问题。这种修改改动量非常大,所以插件维护者也不愿意对老版本进行修复了。
总结
凤蝶插件这个问题,本质上还是由于进程挂了,然后重启,但进程间通信导致数据丢失了。这种模式在本地开发环境非常难以测试,线上出现概率也不大。进程挂掉是非常严重的问题,线上还是非常少见的。

若有收获,就点个赞吧
0 人点赞
