1. 集群维护
etcd启动参数中--initial-advertise-peer-urls --initial-cluster --initial-cluster-state --initial-cluster-token仅在创建新的member节点中使用,对于已经添加到集群中的节点而言是不生效的,因此在大部分情况,不需要修改现有etcd启动命令中的这几个参数的,同理这个参数也不能代表集群中节点的真实状态。集群的维护操作主要有以下几种:
- 增加集群节点:比如从3个节点增加到5个节点,提升客户端读取性能
- 移除集群节点:比如从5个节点减少到3个节点,提升客户端写入性能
- 节点迁移维护:节点磁盘故障、节点配置升级、系统升级需要停服维护
- 集群灾难恢复:多数节点不可用,需要用旧数据重新建立集群
- etcd版本升级:需要参考官方文档,确认各个版本区别,然后逐个升级
- etcd证书替换:证书到期后更换证书
1.1. 增加集群节点
向当前集群添加etcd-4: https://10.4.7.123:2380和etcd-5: https://10.4.7.125:2380,操作步骤如下:
确认当前集群成员信息,确保当前集群能正常对外提供服务
[root@duduniao etcd]# etc member list --write-out=table+------------------+---------+--------+-------------------------+-------------------------+------------+| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |+------------------+---------+--------+-------------------------+-------------------------+------------+| 4fe2b98ed7b794f7 | started | etcd-3 | https://10.4.7.123:2380 | https://10.4.7.123:2379 | false || bbd6739258f69625 | started | etcd-1 | https://10.4.7.121:2380 | https://10.4.7.121:2379 | false || c5542f3740ec56cd | started | etcd-2 | https://10.4.7.122:2380 | https://10.4.7.122:2379 | false |+------------------+---------+--------+-------------------------+-------------------------+------------+
签发新节点的证书
# 重新签发server证书,因为原来的server证书不包含etcd-4和etcd-5。
# 从v3.2.0开始,每次客户端连接会自动加载server证书和peer证书,可以动态替换旧证书。
[root@duduniao ssl]# cat server.json
{
"CN": "local-etcd.duduniao.com",
"hosts": [
"10.4.7.121",
"10.4.7.122",
"10.4.7.123",
"10.4.7.124",
"10.4.7.125",
"127.0.0.1",
"etcd-1",
"etcd-2",
"etcd-3",
"etcd-4",
"etcd-5",
"localhost"
],
"key": {
"algo": "ecdsa",
"size": 256
},
"names": [
{
"C": "CN",
"L": "Shanghai",
"ST": "Shanghai"
}
]
}
[root@duduniao ssl]# rm -f server.csr server*.pem
[root@duduniao ssl]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=server server.json | cfssljson -bare server
# 以 etcd-4为例,签发 peer 证书
[root@duduniao ssl]# cat etcd-4.json
{
"CN": "local-etcd-4.duduniao.com",
"hosts": [
"10.4.7.124",
"etcd-4"
],
"key": {
"algo": "ecdsa",
"size": 256
},
"names": [
{
"C": "CN",
"L": "Shanghai",
"ST": "Shanghai"
}
]
}
[root@duduniao ssl]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=peer etcd-4.json | cfssljson -bare etcd-4
[root@duduniao ssl]# ll etcd-4*.pem etcd-5*.pem
-rw------- 1 root root 227 2021-10-19 23:06:14 etcd-4-key.pem
-rw-r--r-- 1 root root 1147 2021-10-19 23:06:14 etcd-4.pem
-rw------- 1 root root 227 2021-10-19 23:06:26 etcd-5-key.pem
-rw-r--r-- 1 root root 1147 2021-10-19 23:06:26 etcd-5.pem
# 下发etcd证书
[root@duduniao ssl]# ssh 10.4.7.124 "mkdir -pv /data/etcd/{ssl,data}"
mkdir: created directory '/data/etcd'
mkdir: created directory '/data/etcd/ssl'
mkdir: created directory '/data/etcd/data'
[root@duduniao ssl]# scp ca.pem etcd-4.pem etcd-4-key.pem 10.4.7.124:/data/etcd/ssl/
# 同步所有节点的server证书,这里只是为了方便管理,旧节点可以不用替换。
[root@duduniao ssl]# for i in 10.4.7.12{1..5};do echo $i ; scp server.pem server-key.pem $i:/data/etcd/ssl/ ;done
- 添加新节点 ``` [root@duduniao etcd]# etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.121:2379 member add etcd-4 —peer-urls https://10.4.7.124:2380 Member 79b3746506cf2fc1 added to cluster 23ce29301256c4ff
ETCD_NAME=”etcd-4” ETCD_INITIAL_CLUSTER=”etcd-3=https://10.4.7.123:2380,etcd-4=https://10.4.7.124:2380,etcd-1=https://10.4.7.121:2380,etcd-2=https://10.4.7.122:2380“ ETCD_INITIAL_ADVERTISE_PEER_URLS=”https://10.4.7.124:2380“ ETCD_INITIAL_CLUSTER_STATE=”existing”
[root@duduniao etcd]# etc member list —write-out=table # 当前状态是未启动 +—————————+—————-+————+————————————-+————————————-+——————+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +—————————+—————-+————+————————————-+————————————-+——————+ | 4fe2b98ed7b794f7 | started | etcd-3 | https://10.4.7.123:2380 | https://10.4.7.123:2379 | false | | 79b3746506cf2fc1 | unstarted | | https://10.4.7.124:2380 | | false | | bbd6739258f69625 | started | etcd-1 | https://10.4.7.121:2380 | https://10.4.7.121:2379 | false | | c5542f3740ec56cd | started | etcd-2 | https://10.4.7.122:2380 | https://10.4.7.122:2379 | false | +—————————+—————-+————+————————————-+————————————-+——————+
查看任意一台节点的etcd日志:
Oct 19 15:17:05 ubuntu-1804-121 etcd[23741]: {“level”:”warn”,”ts”:”2021-10-19T15:17:05.569Z”,”caller”:”rafthttp/probing_status.go:68”,”msg”:”prober detected unhealthy status”,”round-tripper-name”:”ROUND_TRIPPER_RAFT_MESSAGE”,”remote-peer-id”:”79b3746506cf2fc1”,”rtt”:”0s”,”error”:”dial tcp 10.4.7.124:2380: connect: connection refused”} Oct 19 15:17:05 ubuntu-1804-121 etcd[23741]: {“level”:”warn”,”ts”:”2021-10-19T15:17:05.569Z”,”caller”:”rafthttp/probing_status.go:68”,”msg”:”prober detected unhealthy status”,”round-tripper-name”:”ROUND_TRIPPER_SNAPSHOT”,”remote-peer-id”:”79b3746506cf2fc1”,”rtt”:”0s”,”error”:”dial tcp 10.4.7.124:2380: connect: connection refused”}
4. 启动新节点(etcd-4)
[root@duduniao etcd]# cat etcd-4.service [Unit] Description=Etcd Server After=network.target After=network-online.target Wants=network-online.target Documentation=https://github.com/coreos
[Service] Type=notify WorkingDirectory=/data/etcd Environment=ETCD_NAME=”etcd-4” Environment=ETCD_INITIAL_CLUSTER=”etcd-3=https://10.4.7.123:2380,etcd-4=https://10.4.7.124:2380,etcd-1=https://10.4.7.121:2380,etcd-2=https://10.4.7.122:2380“ Environment=ETCD_INITIAL_ADVERTISE_PEER_URLS=”https://10.4.7.124:2380“ Environment=ETCD_INITIAL_CLUSTER_STATE=”existing”
ExecStart=/usr/local/bin/etcd \ —listen-peer-urls https://10.4.7.124:2380 \ —listen-client-urls https://10.4.7.124:2379,https://127.0.0.1:2379 \ —advertise-client-urls https://10.4.7.124:2379 \ —initial-cluster-token etcd-cluster-1 \ —client-cert-auth \ —cert-file ssl/server.pem \ —key-file ssl/server-key.pem \ —trusted-ca-file ssl/ca.pem \ —peer-client-cert-auth \ —peer-trusted-ca-file ssl/ca.pem \ —peer-cert-file ssl/etcd-4.pem \ —peer-key-file ssl/etcd-4-key.pem \ —data-dir data \ —snapshot-count 50000 \ —auto-compaction-retention 1 \ —auto-compaction-mode periodic \ —max-request-bytes 10485760 \ —quota-backend-bytes 8589934592 Restart=always RestartSec=15 LimitNOFILE=65536 OOMScoreAdjust=-999
[Install] WantedBy=multi-user.target
[root@duduniao etcd]# scp etcd-4.service 10.4.7.124:/lib/systemd/system/etcd.service [root@duduniao etcd]# scp etcd-v3.5.1-linux-amd64/etcd* 10.4.7.124:/usr/local/bin/ [root@duduniao etcd]# ssh 10.4.7.124 “systemctl daemon-reload && systemctl enable etcd && systemctl start etcd”
[root@duduniao etcd]# etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.124:2379 endpoint status —write-out table +————————————-+—————————+————-+————-+—————-+——————+—————-+——————+——————————+————+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +————————————-+—————————+————-+————-+—————-+——————+—————-+——————+——————————+————+ | https://10.4.7.124:2379 | 79b3746506cf2fc1 | 3.5.1 | 20 kB | false | false | 2 | 76 | 76 | | +————————————-+—————————+————-+————-+—————-+——————+—————-+——————+——————————+————+ [root@duduniao etcd]# etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.124:2379 member list —write-out table +—————————+————-+————+————————————-+————————————-+——————+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +—————————+————-+————+————————————-+————————————-+——————+ | 4fe2b98ed7b794f7 | started | etcd-3 | https://10.4.7.123:2380 | https://10.4.7.123:2379 | false | | 79b3746506cf2fc1 | started | etcd-4 | https://10.4.7.124:2380 | https://10.4.7.124:2379 | false | | bbd6739258f69625 | started | etcd-1 | https://10.4.7.121:2380 | https://10.4.7.121:2379 | false | | c5542f3740ec56cd | started | etcd-2 | https://10.4.7.122:2380 | https://10.4.7.122:2379 | false | +—————————+————-+————+————————————-+————————————-+——————+
5. 添加etcd-5
重复操作步骤3和步骤4即可.
[root@duduniao etcd]# etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.125:2379 endpoint status —write-out table +————————————-+—————————+————-+————-+—————-+——————+—————-+——————+——————————+————+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +————————————-+—————————+————-+————-+—————-+——————+—————-+——————+——————————+————+ | https://10.4.7.125:2379 | d0756e0778ff59b4 | 3.5.1 | 20 kB | false | false | 2 | 78 | 78 | | +————————————-+—————————+————-+————-+—————-+——————+—————-+——————+——————————+————+ [root@duduniao etcd]# etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.124:2379 member list —write-out table +—————————+————-+————+————————————-+————————————-+——————+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +—————————+————-+————+————————————-+————————————-+——————+ | 4fe2b98ed7b794f7 | started | etcd-3 | https://10.4.7.123:2380 | https://10.4.7.123:2379 | false | | 79b3746506cf2fc1 | started | etcd-4 | https://10.4.7.124:2380 | https://10.4.7.124:2379 | false | | bbd6739258f69625 | started | etcd-1 | https://10.4.7.121:2380 | https://10.4.7.121:2379 | false | | c5542f3740ec56cd | started | etcd-2 | https://10.4.7.122:2380 | https://10.4.7.122:2379 | false | | d0756e0778ff59b4 | started | etcd-5 | https://10.4.7.125:2380 | https://10.4.7.125:2379 | false | +—————————+————-+————+————————————-+————————————-+——————+
<a name="o2nHI"></a>
## 1.2. 移除集群节点
当集群中,需要缩减集群规模,需要移除现有的节点。如从5节点缩减至3节点,操作方式如下:
1. 检查集群状态
[root@duduniao etcd]# etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.121:2379 member list —write-out table +—————————+————-+————+————————————-+————————————-+——————+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +—————————+————-+————+————————————-+————————————-+——————+ | 4fe2b98ed7b794f7 | started | etcd-3 | https://10.4.7.123:2380 | https://10.4.7.123:2379 | false | | 79b3746506cf2fc1 | started | etcd-4 | https://10.4.7.124:2380 | https://10.4.7.124:2379 | false | | bbd6739258f69625 | started | etcd-1 | https://10.4.7.121:2380 | https://10.4.7.121:2379 | false | | c5542f3740ec56cd | started | etcd-2 | https://10.4.7.122:2380 | https://10.4.7.122:2379 | false | | d0756e0778ff59b4 | started | etcd-5 | https://10.4.7.125:2380 | https://10.4.7.125:2379 | false | +—————————+————-+————+————————————-+————————————-+——————+
2. 移除节点
移除etcd-5
[root@duduniao etcd]# etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.121:2379 member remove d0756e0778ff59b4 Member d0756e0778ff59b4 removed from cluster 23ce29301256c4ff
移除etcd-4
[root@duduniao etcd]# etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.121:2379 member remove 79b3746506cf2fc1 Member 79b3746506cf2fc1 removed from cluster 23ce29301256c4ff
[root@duduniao etcd]# etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.121:2379 member list —write-out table +—————————+————-+————+————————————-+————————————-+——————+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +—————————+————-+————+————————————-+————————————-+——————+ | 4fe2b98ed7b794f7 | started | etcd-3 | https://10.4.7.123:2380 | https://10.4.7.123:2379 | false | | bbd6739258f69625 | started | etcd-1 | https://10.4.7.121:2380 | https://10.4.7.121:2379 | false | | c5542f3740ec56cd | started | etcd-2 | https://10.4.7.122:2380 | https://10.4.7.122:2379 | false | +—————————+————-+————+————————————-+————————————-+——————+
3. 停止移除节点上的etcd服务
[root@duduniao etcd]# ssh 10.4.7.124 “systemctl stop etcd && systemctl disable etcd” [root@duduniao etcd]# ssh 10.4.7.125 “systemctl stop etcd && systemctl disable etcd”
<a name="uJvlC"></a>
## 1.3. 节点迁移维护
如果只是当前节点升级配置、服务器重启等操作,直接停服后操作即可,无需特殊处理。针对节点数据磁盘故障、或者当前节点数据迁移到新的节点上的两种场景,有两种解决方案:
- 按照1.2 方式移旧节点,再按照 1.1 方式新增节点,如果新旧节点IP不变,则不需要签发新的证书
- 如果数据较大(大于50MB)且旧节点数据未损坏,可用迁移节点方式
这里针对需要进行数据迁移的场景进行演示,迁移etcd-3节点到 10.4.7.124:
+—————————+————-+————+————————————-+————————————-+——————+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +—————————+————-+————+————————————-+————————————-+——————+ | 4fe2b98ed7b794f7 | started | etcd-3 | https://10.4.7.123:2380 | https://10.4.7.123:2379 | false | | bbd6739258f69625 | started | etcd-1 | https://10.4.7.121:2380 | https://10.4.7.121:2379 | false | | c5542f3740ec56cd | started | etcd-2 | https://10.4.7.122:2380 | https://10.4.7.122:2379 | false | +—————————+————-+————+————————————-+————————————-+——————+
1. 模拟etcd-3故障
root@ubuntu-1804-123:~# systemctl stop etcd
2. 迁移 10.4.7.123 上的etcd数据到 10.4.7.124
[root@duduniao etcd]# ssh 10.4.7.123 “cd /data/etcd && tar -zcf etcd-3.tar.gz data” [root@duduniao etcd]# scp 10.4.7.123 /data/etcd/etcd-3.tar.gz ./
[root@duduniao etcd]# scp etcd-3.tar.gz 10.4.7.124:/tmp/ [root@duduniao etcd]# ssh 10.4.7.124 “rm -fr /data/etcd/data ; mkdir -pv /data/etcd/ssl ; tar -xf /tmp/etcd-3.tar.gz -C /data/etcd && rm -f /tmp/etcd-3.tar.gz && ls -l /data/etcd”
3. 生成 10.4.7.124 上的etcd server证书和peer证书
参考 1.1 添加新节点中证书签发步骤,最终结果如下:
[root@duduniao etcd]# ssh 10.4.7.124 “ls -l /data/etcd/ssl” total 20 -rw-r—r— 1 root root 1387 Oct 19 15:31 ca.pem -rw———- 1 root root 227 Oct 19 15:31 etcd-3-key.pem -rw-r—r— 1 root root 1147 Oct 19 15:31 etcd-3.pem -rw———- 1 root root 227 Oct 19 15:37 server-key.pem -rw-r—r— 1 root root 1245 Oct 19 15:37 server.pem
4. 更新集群中的member成员信息
[root@duduniao etcd]# etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.121:2379 member update 4fe2b98ed7b794f7 —peer-urls=”https://10.4.7.124:2379“ Member 4fe2b98ed7b794f7 updated in cluster 23ce29301256c4ff
client URL需要启动后etcd进程后才能更新
[root@duduniao etcd]# etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.121:2379 member list —write-out table +—————————+————-+————+————————————-+————————————-+——————+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +—————————+————-+————+————————————-+————————————-+——————+ | 4fe2b98ed7b794f7 | started | etcd-3 | https://10.4.7.124:2379 | https://10.4.7.123:2379 | false | | bbd6739258f69625 | started | etcd-1 | https://10.4.7.121:2380 | https://10.4.7.121:2379 | false | | c5542f3740ec56cd | started | etcd-2 | https://10.4.7.122:2380 | https://10.4.7.122:2379 | false | +—————————+————-+————+————————————-+————————————-+——————+
5. 启动新节点的 etcd 服务
/lib/systemd/system/etcd.service
[Unit] Description=Etcd Server After=network.target After=network-online.target Wants=network-online.target Documentation=https://github.com/coreos
[Service] Type=notify WorkingDirectory=/data/etcd Environment=ETCD_NAME=”etcd-3”
ExecStart=/usr/local/bin/etcd \ —listen-peer-urls https://10.4.7.124:2380 \ —listen-client-urls https://10.4.7.124:2379,https://127.0.0.1:2379 \ —advertise-client-urls https://10.4.7.124:2379 \ —initial-cluster-token etcd-cluster-1 \ —client-cert-auth \ —cert-file ssl/server.pem \ —key-file ssl/server-key.pem \ —trusted-ca-file ssl/ca.pem \ —peer-client-cert-auth \ —peer-trusted-ca-file ssl/ca.pem \ —peer-cert-file ssl/etcd-3.pem \ —peer-key-file ssl/etcd-3-key.pem \ —data-dir data \ —snapshot-count 50000 \ —auto-compaction-retention 1 \ —auto-compaction-mode periodic \ —max-request-bytes 10485760 \ —quota-backend-bytes 8589934592 Restart=always RestartSec=15 LimitNOFILE=65536 OOMScoreAdjust=-999
[Install] WantedBy=multi-user.target
```
[root@duduniao etcd]# ssh 10.4.7.124 "systemctl start etcd && systemctl enable etcd"
# 此时集群中的etcd节点 client URL已经发生了变化
[root@duduniao etcd]# etcdctl --cacert ssl/ca.pem --cert ssl/client.pem --key ssl/client-key.pem --endpoints https://10.4.7.121:2379 member list --write-out table
+------------------+---------+--------+-------------------------+-------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+--------+-------------------------+-------------------------+------------+
| 4fe2b98ed7b794f7 | started | etcd-3 | https://10.4.7.124:2379 | https://10.4.7.124:2379 | false |
| bbd6739258f69625 | started | etcd-1 | https://10.4.7.121:2380 | https://10.4.7.121:2379 | false |
| c5542f3740ec56cd | started | etcd-2 | https://10.4.7.122:2380 | https://10.4.7.122:2379 | false |
+------------------+---------+--------+-------------------------+-------------------------+------------+
[root@duduniao etcd]# etcdctl --cacert ssl/ca.pem --cert ssl/client.pem --key ssl/client-key.pem --endpoints https://10.4.7.124:2379 endpoint status --write-out table
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.4.7.124:2379 | 4fe2b98ed7b794f7 | 3.5.1 | 20 kB | false | false | 2 | 135 | 135 | |
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
1.4. 集群灾难恢复
etcd集群选择leader时,是少数服从多数,因此不会出现脑裂问题。当集群中的大部分节点不可用时,集群无法对外提供正常的服务,此时需要尽快启动不可用节点,只要节点数据超过半数,集群状态会自动恢复:
- 当少数节点不可用时 ``` [root@duduniao etcd]# etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.121:2379 member list —write-out table +—————————+————-+————+————————————-+————————————-+——————+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +—————————+————-+————+————————————-+————————————-+——————+ | 4fe2b98ed7b794f7 | started | etcd-3 | https://10.4.7.124:2379 | https://10.4.7.124:2379 | false | | bbd6739258f69625 | started | etcd-1 | https://10.4.7.121:2380 | https://10.4.7.121:2379 | false | | c5542f3740ec56cd | started | etcd-2 | https://10.4.7.122:2380 | https://10.4.7.122:2379 | false | +—————————+————-+————+————————————-+————————————-+——————+
停止etcd-3模拟集群中少数节点故障
[root@duduniao etcd]# ssh 10.4.7.124 “systemctl stop etcd”
```
# 节点状态正常
[root@duduniao etcd]# etcdctl --cacert ssl/ca.pem --cert ssl/client.pem --key ssl/client-key.pem --endpoints https://10.4.7.121:2379 member list --write-out table
+------------------+---------+--------+-------------------------+-------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+--------+-------------------------+-------------------------+------------+
| 4fe2b98ed7b794f7 | started | etcd-3 | https://10.4.7.124:2379 | https://10.4.7.124:2379 | false |
| bbd6739258f69625 | started | etcd-1 | https://10.4.7.121:2380 | https://10.4.7.121:2379 | false |
| c5542f3740ec56cd | started | etcd-2 | https://10.4.7.122:2380 | https://10.4.7.122:2379 | false |
+------------------+---------+--------+-------------------------+-------------------------+------------+
[root@duduniao etcd]# etcdctl --cacert ssl/ca.pem --cert ssl/client.pem --key ssl/client-key.pem --endpoints https://10.4.7.121:2379 endpoint health --write-out table
+-------------------------+--------+----------+-------+
| ENDPOINT | HEALTH | TOOK | ERROR |
+-------------------------+--------+----------+-------+
| https://10.4.7.121:2379 | true | 6.6047ms | |
+-------------------------+--------+----------+-------+
# 集群读写正常
[root@duduniao etcd]# etcdctl --cacert ssl/ca.pem --cert ssl/client.pem --key ssl/client-key.pem --endpoints https://10.4.7.121:2379 put k1 v1
OK
[root@duduniao etcd]# etcdctl --cacert ssl/ca.pem --cert ssl/client.pem --key ssl/client-key.pem --endpoints https://10.4.7.121:2379 get k1
k1
v1
- 模拟多数节点宕机 ``` [root@duduniao etcd]# ssh 10.4.7.122 “systemctl stop etcd”
节点状态异常,集群状态异常
[root@duduniao etcd]# etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.121:2379 endpoint health —write-out table {“level”:”warn”,”ts”:1634910316.3861823,”logger”:”client”,”caller”:”v3/retry_interceptor.go:62”,”msg”:”retrying of unary invoker failed”,”target”:”etcd-endpoints://0xc0004308c0/10.4.7.121:2379”,”attempt”:0,”error”:”rpc error: code = DeadlineExceeded desc = context deadline exceeded”} +————————————-+————+—————-+—————————————-+ | ENDPOINT | HEALTH | TOOK | ERROR | +————————————-+————+—————-+—————————————-+ | https://10.4.7.121:2379 | false | 5.001016s | context deadline exceeded | +————————————-+————+—————-+—————————————-+ Error: unhealthy cluster
节点读写报错
[root@duduniao etcd]# etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.121:2379 put k1 v1 {“level”:”warn”,”ts”:”2021-10-22T21:46:29.288+0800”,”logger”:”etcd-client”,”caller”:”v3/retry_interceptor.go:62”,”msg”:”retrying of unary invoker failed”,”target”:”etcd-endpoints://0xc000622540/10.4.7.121:2379”,”attempt”:0,”error”:”rpc error: code = DeadlineExceeded desc = context deadline exceeded”} Error: context deadline exceeded [root@duduniao etcd]# etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.121:2379 get k1 {“level”:”warn”,”ts”:”2021-10-22T21:46:13.352+0800”,”logger”:”etcd-client”,”caller”:”v3/retry_interceptor.go:62”,”msg”:”retrying of unary invoker failed”,”target”:”etcd-endpoints://0xc0004348c0/10.4.7.121:2379”,”attempt”:0,”error”:”rpc error: code = DeadlineExceeded desc = context deadline exceeded”} Error: context deadline exceeded
3. 模拟多数节点顺利启动
[root@duduniao etcd]# ssh 10.4.7.124 “systemctl start etcd”
集群状态和节点状态正常
[root@duduniao etcd]# etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.121:2379 endpoint health —write-out table +————————————-+————+—————+———-+ | ENDPOINT | HEALTH | TOOK | ERROR | +————————————-+————+—————+———-+ | https://10.4.7.121:2379 | true | 6.8057ms | | +————————————-+————+—————+———-+ [root@duduniao etcd]# etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.121:2379 member list —write-out table +—————————+————-+————+————————————-+————————————-+——————+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +—————————+————-+————+————————————-+————————————-+——————+ | 4fe2b98ed7b794f7 | started | etcd-3 | https://10.4.7.124:2379 | https://10.4.7.124:2379 | false | | bbd6739258f69625 | started | etcd-1 | https://10.4.7.121:2380 | https://10.4.7.121:2379 | false | | c5542f3740ec56cd | started | etcd-2 | https://10.4.7.122:2380 | https://10.4.7.122:2379 | false | +—————————+————-+————+————————————-+————————————-+——————+ [root@duduniao etcd]# etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.121:2379 put k1 v1 OK
考虑到一种极端情况,当大部分节点无法启动etcd,需要从快照或者历史备份中恢复数据,并组建一个新的集群:
1. 停止大部分节点,使得集群无法对外提供服务
[root@duduniao etcd]# ssh 10.4.7.122 “systemctl stop etcd” [root@duduniao etcd]# ssh 10.4.7.124 “systemctl stop etcd”
2. 从可用节点生成V3的快照,如果全部节点不可用则从etcd的数据目录下找到`member/snap/db`进行恢复,或者从历史备份恢复
v2版本的恢复方式和v3不太一样,可参考[官方文档](https://etcd.io/docs/v2.3/admin_guide#disaster-recovery)
[root@duduniao etcd]# ETCDCTL_API=3 etcdctl —cacert ssl/ca.pem —cert ssl/client.pem —key ssl/client-key.pem —endpoints https://10.4.7.121:2379 snapshot save snapshot.db [root@duduniao etcd]# ll -h snapshot.db -rw———- 1 root root 21K 2021-10-22 22:08:43 snapshot.d
3. 停止节点上etcd进程,清理历史数据目录
[root@duduniao etcd]# ssh 10.4.7.121 “systemctl stop etcd ; mv /data/etcd/data /data/etcd/data.20211022.bak” [root@duduniao etcd]# ssh 10.4.7.122 “systemctl stop etcd ; mv /data/etcd/data /data/etcd/data.20211022.bak” [root@duduniao etcd]# ssh 10.4.7.124 “systemctl stop etcd ; mv /data/etcd/data /data/etcd/data.20211022.bak”
[root@duduniao etcd]# scp snapshot.db 10.4.7.121:/tmp/ [root@duduniao etcd]# scp snapshot.db 10.4.7.122:/tmp/ [root@duduniao etcd]# scp snapshot.db 10.4.7.124:/tmp/
4. 重建集群
root@ubuntu-1804-121:~# ETCDCTL_API=3 etcdctl snapshot restore /tmp/snapshot.db —data-dir /data/etcd/data —initial-advertise-peer-urls https://10.4.7.121:2380 —initial-cluster etcd-1=https://10.4.7.121:2380,etcd-2=https://10.4.7.122:2380,etcd-3=https://10.4.7.124:2380 —initial-cluster-token etcd-cluster-1 —name etcd-1 root@ubuntu-1804-122:~# ETCDCTL_API=3 etcdctl snapshot restore /tmp/snapshot.db —data-dir /data/etcd/data —initial-advertise-peer-urls https://10.4.7.122:2380 —initial-cluster etcd-1=https://10.4.7.121:2380,etcd-2=https://10.4.7.122:2380,etcd-3=https://10.4.7.124:2380 —initial-cluster-token etcd-cluster-1 —name etcd-2 root@ubuntu-1804-124:~# ETCDCTL_API=3 etcdctl snapshot restore /tmp/snapshot.db —data-dir /data/etcd/data —initial-advertise-peer-urls https://10.4.7.124:2380 —initial-cluster etcd-1=https://10.4.7.121:2380,etcd-2=https://10.4.7.122:2380,etcd-3=https://10.4.7.124:2380 —initial-cluster-token etcd-cluster-1 —name etcd-3
root@ubuntu-1804-121:~# systemctl start etcd root@ubuntu-1804-122:~# systemctl start etcd root@ubuntu-1804-124:~# systemctl start etcd
```
# 验证集群
[root@duduniao etcd]# etcdctl --cacert ssl/ca.pem --cert ssl/client.pem --key ssl/client-key.pem --endpoints https://10.4.7.121:2379 member list --write-out table
+------------------+---------+--------+-------------------------+-------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+--------+-------------------------+-------------------------+------------+
| 8bb2a873a59fd89b | started | etcd-3 | https://10.4.7.124:2380 | https://10.4.7.124:2379 | false |
| bbd6739258f69625 | started | etcd-1 | https://10.4.7.121:2380 | https://10.4.7.121:2379 | false |
| c5542f3740ec56cd | started | etcd-2 | https://10.4.7.122:2380 | https://10.4.7.122:2379 | false |
+------------------+---------+--------+-------------------------+-------------------------+------------+
[root@duduniao etcd]# etcdctl --cacert ssl/ca.pem --cert ssl/client.pem --key ssl/client-key.pem --endpoints https://10.4.7.121:2379 get k1
k1
v1
1.5. etcd版本升级
1.6. etcd证书替换
etcd的证书替换分为四种类型:
- server 证书更换:从v3.2.0开始,每个请求会重载证书,因此证书替换会变得非常方便
- peer 证书更换:从v3.2.0开始,每个请求会重载证书,因此证书替换会变得非常方便
- ca 证书更换: ca证书的替换会变得比较麻烦,需要停服维护,做好前期准备工作,停服时间在1分钟以内
上述的第一和第二种情况很容易处理,签发证书直接下发即可,老版本的etcd可用逐个重启服务。以下针对第三种情况进行操作:
- 生成新的证书
- 下发证书,并重启etcd ``` [root@duduniao etcd]# scan_host.sh cmd -h 10.4.7.121 10.4.7.122 10.4.7.124 “cp -r /data/etcd/ssl /data/etcd/ssl-20211021.bak” [root@duduniao ssl-new]# scan_host.sh cmd -h 10.4.7.121 10.4.7.122 10.4.7.124 “mkdir /data/etcd/ssl-new” [root@duduniao ssl-new]# scp ca.pem server.pem server-key.pem etcd-1.pem etcd-1-key.pem 10.4.7.121:/data/etcd/ssl-new/ [root@duduniao ssl-new]# scp ca.pem server.pem server-key.pem etcd-2.pem etcd-2-key.pem 10.4.7.122:/data/etcd/ssl-new/ [root@duduniao ssl-new]# scp ca.pem server.pem server-key.pem etcd-3.pem etcd-3-key.pem 10.4.7.124:/data/etcd/ssl-new/
[root@duduniao etcd]# scan_host.sh cmd -h 10.4.7.121 10.4.7.122 10.4.7.124 “systemctl stop etcd “ [root@duduniao etcd]# scan_host.sh cmd -h 10.4.7.121 10.4.7.122 10.4.7.124 “rm -fr /data/etcd/ssl ; mv /data/etcd/ssl-new /data/etcd/ssl” [root@duduniao etcd]# scan_host.sh cmd -h 10.4.7.121 10.4.7.122 10.4.7.124 “systemctl start etcd “
```
[root@duduniao etcd]# etcdctl --cacert ssl-new/ca.pem --cert ssl-new/client.pem --key ssl-new/client-key.pem --endpoints https://10.4.7.121:2379 member list --write-out table
+------------------+---------+--------+-------------------------+-------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+--------+-------------------------+-------------------------+------------+
| 8bb2a873a59fd89b | started | etcd-3 | https://10.4.7.124:2380 | https://10.4.7.124:2379 | false |
| bbd6739258f69625 | started | etcd-1 | https://10.4.7.121:2380 | https://10.4.7.121:2379 | false |
| c5542f3740ec56cd | started | etcd-2 | https://10.4.7.122:2380 | https://10.4.7.122:2379 | false |
+------------------+---------+--------+-------------------------+-------------------------+------------+
[root@duduniao etcd]# etcdctl --cacert ssl-new/ca.pem --cert ssl-new/client.pem --key ssl-new/client-key.pem --endpoints https://10.4.7.121:2379 endpoint status --write-out table
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.4.7.121:2379 | bbd6739258f69625 | 3.5.1 | 20 kB | false | false | 7 | 37 | 37 | |
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
[root@duduniao etcd]# etcdctl --cacert ssl-new/ca.pem --cert ssl-new/client.pem --key ssl-new/client-key.pem --endpoints https://10.4.7.122:2379 endpoint status --write-out table
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.4.7.122:2379 | c5542f3740ec56cd | 3.5.1 | 20 kB | false | false | 7 | 37 | 37 | |
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
[root@duduniao etcd]# etcdctl --cacert ssl-new/ca.pem --cert ssl-new/client.pem --key ssl-new/client-key.pem --endpoints https://10.4.7.124:2379 endpoint status --write-out table
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.4.7.124:2379 | 8bb2a873a59fd89b | 3.5.1 | 20 kB | true | false | 7 | 37 | 37 | |
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
2. 备份和恢复
大部分etcd集群的数据都是很小的,可以考虑每个小时备份一次,只需要从一个节点进行备份即可,不需要每个节点都进行备份。数据恢复是指通过现有的快照数据,重新建立集群,备份和恢复的方式可以参考 1.4. 集群灾难恢复。
3. 监控和告警
3.1. 监控配置
配置prometheus
# etcd指标采集的任务配置,需要配置客户端访问的证书 - job_name: 'etcd' scrape_interval: 15s scheme: https tls_config: ca_file: /etc/prometheus/ssl/ca.pem cert_file: /etc/prometheus/ssl/client.pem key_file: /etc/prometheus/ssl/client-key.pem static_configs: - targets: ['10.4.7.121:2379','10.4.7.122:2379','10.4.7.124:2379']
配置grafana模板
官方提供了 etcd 监控的dashborad模板,但是该模板存在问题,导入后无法展示,需要进行调整。可用使用以下附件导入grafana。
grafana.json
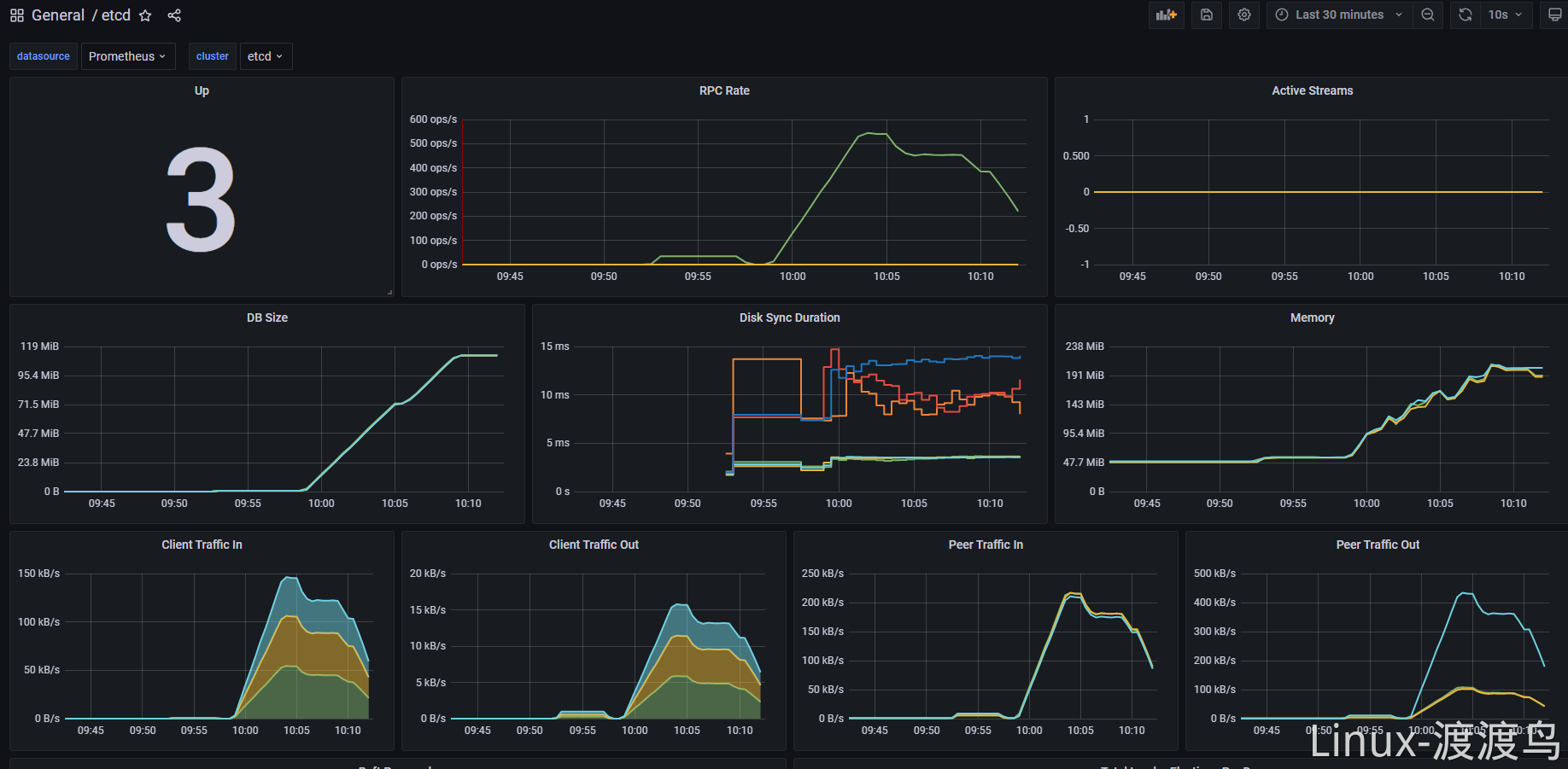
压测 etcd 集群,查看监控曲线
[root@duduniao ssl-new]# go get go.etcd.io/etcd/v3/tools/benchmark [root@duduniao ssl-new]# benchmark put --cacert ca.pem --cert client.pem --key client-key.pem --clients 5 --conns 100 --endpoints $END_POINTS put --val-size 256 --total 1000003.2. 配置告警
配置prometheus规则
# prometheus.yml ...... alerting: alertmanagers: - timeout: 10s static_configs: - targets: ["alertmanager:9093"] rule_files: - /etc/prometheus/rules.d/etcd_alerting.yaml官方提供了告警规则,用户可用根据需求自行调整: ```yaml
etcd_alerting.yaml
groups:
- name: etcd
rules:
- alert: etcdMembersDown
annotations:
description: ‘etcd cluster “{{ $labels.job }}”: members are down ({{ $value }}).’
summary: etcd cluster members are down.
expr: |
max without (endpoint) (
orsum without (instance) (up{job=~".*etcd.*"} == bool 0)
)count without (To) ( sum without (instance) (rate(etcd_network_peer_sent_failures_total{job=~".*etcd.*"}[120s])) > 0.01 )0 for: 10m labels: severity: critical
- alert: etcdInsufficientMembers annotations: description: ‘etcd cluster “{{ $labels.job }}”: insufficient members ({{ $value }}).’ summary: etcd cluster has insufficient number of members. expr: | sum(up{job=~”.etcd.“} == bool 1) without (instance) < ((count(up{job=~”.etcd.“}) without (instance) + 1) / 2) for: 3m labels: severity: critical
- alert: etcdNoLeader annotations: description: ‘etcd cluster “{{ $labels.job }}”: member {{ $labels.instance }} has no leader.’ summary: etcd cluster has no leader. expr: | etcd_server_has_leader{job=~”.etcd.“} == 0 for: 1m labels: severity: critical
- alert: etcdHighNumberOfLeaderChanges annotations: description: ‘etcd cluster “{{ $labels.job }}”: {{ $value }} leader changes within the last 15 minutes. Frequent elections may be a sign of insufficient resources, high network latency, or disruptions by other components and should be investigated.’ summary: etcd cluster has high number of leader changes. expr: | increase((max without (instance) (etcd_server_leader_changes_seen_total{job=~”.etcd.“}) or 0absent(etcd_server_leader_changes_seen_total{job=~”.etcd.*”}))[15m:1m]) >= 4 for: 5m labels: severity: warning
- alert: etcdHighNumberOfFailedGRPCRequests
annotations:
description: ‘etcd cluster “{{ $labels.job }}”: {{ $value }}% of requests for {{ $labels.grpc_method }} failed on etcd instance {{ $labels.instance }}.’
summary: etcd cluster has high number of failed grpc requests.
expr: |
100 sum(rate(grpc_server_handled_total{job=~”.etcd.*”, grpc_code!=”OK”}[5m])) without (grpc_type, grpc_code)
sum(rate(grpc_server_handled_total{job=~”.etcd.“}[5m])) without (grpc_type, grpc_code)/
for: 10m labels: severity: warning> 1 - alert: etcdHighNumberOfFailedGRPCRequests
annotations:
description: ‘etcd cluster “{{ $labels.job }}”: {{ $value }}% of requests for {{ $labels.grpc_method }} failed on etcd instance {{ $labels.instance }}.’
summary: etcd cluster has high number of failed grpc requests.
expr: |
100 sum(rate(grpc_server_handled_total{job=~”.etcd.*”, grpc_code!=”OK”}[5m])) without (grpc_type, grpc_code)
sum(rate(grpc_server_handled_total{job=~”.etcd.“}[5m])) without (grpc_type, grpc_code)/
for: 5m labels: severity: critical> 5 - alert: etcdGRPCRequestsSlow
annotations:
description: ‘etcd cluster “{{ $labels.job }}”: gRPC requests to {{ $labels.grpc_method }} are taking {{ $value }}s on etcd instance {{ $labels.instance }}.’
summary: etcd grpc requests are slow
expr: |
histogram_quantile(0.99, sum(rate(grpc_server_handling_seconds_bucket{job=~”.etcd.“, grpc_type=”unary”}[5m])) without(grpc_type))
0.15 for: 10m labels: severity: critical
- alert: etcdMemberCommunicationSlow
annotations:
description: ‘etcd cluster “{{ $labels.job }}”: member communication with {{ $labels.To }} is taking {{ $value }}s on etcd instance {{ $labels.instance }}.’
summary: etcd cluster member communication is slow.
expr: |
histogram_quantile(0.99, rate(etcd_network_peer_round_trip_time_seconds_bucket{job=~”.etcd.“}[5m]))
0.15 for: 10m labels: severity: warning
- alert: etcdHighNumberOfFailedProposals annotations: description: ‘etcd cluster “{{ $labels.job }}”: {{ $value }} proposal failures within the last 30 minutes on etcd instance {{ $labels.instance }}.’ summary: etcd cluster has high number of proposal failures. expr: | rate(etcd_server_proposals_failed_total{job=~”.etcd.“}[15m]) > 5 for: 15m labels: severity: warning
- alert: etcdHighFsyncDurations
annotations:
description: ‘etcd cluster “{{ $labels.job }}”: 99th percentile fsync durations are {{ $value }}s on etcd instance {{ $labels.instance }}.’
summary: etcd cluster 99th percentile fsync durations are too high.
expr: |
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~”.etcd.“}[5m]))
0.5 for: 10m labels: severity: warning
- alert: etcdHighFsyncDurations
annotations:
message: ‘etcd cluster “{{ $labels.job }}”: 99th percentile fsync durations are {{ $value }}s on etcd instance {{ $labels.instance }}.’
expr: |
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~”.etcd.“}[5m]))
1 for: 10m labels: severity: critical
- alert: etcdHighCommitDurations
annotations:
description: ‘etcd cluster “{{ $labels.job }}”: 99th percentile commit durations {{ $value }}s on etcd instance {{ $labels.instance }}.’
summary: etcd cluster 99th percentile commit durations are too high.
expr: |
histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~”.etcd.“}[5m]))
0.25 for: 10m labels: severity: warning
- alert: etcdBackendQuotaLowSpace annotations: message: ‘etcd cluster “{{ $labels.job }}”: database size exceeds the defined quota on etcd instance {{ $labels.instance }}, please defrag or increase the quota as the writes to etcd will be disabled when it is full.’ expr: | (etcd_mvcc_db_total_size_in_bytes/etcd_server_quota_backend_bytes)*100 > 95 for: 10m labels: severity: critical
- alert: etcdExcessiveDatabaseGrowth annotations: message: ‘etcd cluster “{{ $labels.job }}”: Observed surge in etcd writes leading to 50% increase in database size over the past four hours on etcd instance {{ $labels.instance }}, please check as it might be disruptive.’ expr: | increase(((etcd_mvcc_db_total_size_in_bytes/etcd_server_quota_backend_bytes)*100)[240m:1m]) > 50 for: 10m labels: severity: warning ```
- alert: etcdMembersDown
annotations:
description: ‘etcd cluster “{{ $labels.job }}”: members are down ({{ $value }}).’
summary: etcd cluster members are down.
expr: |
max without (endpoint) (
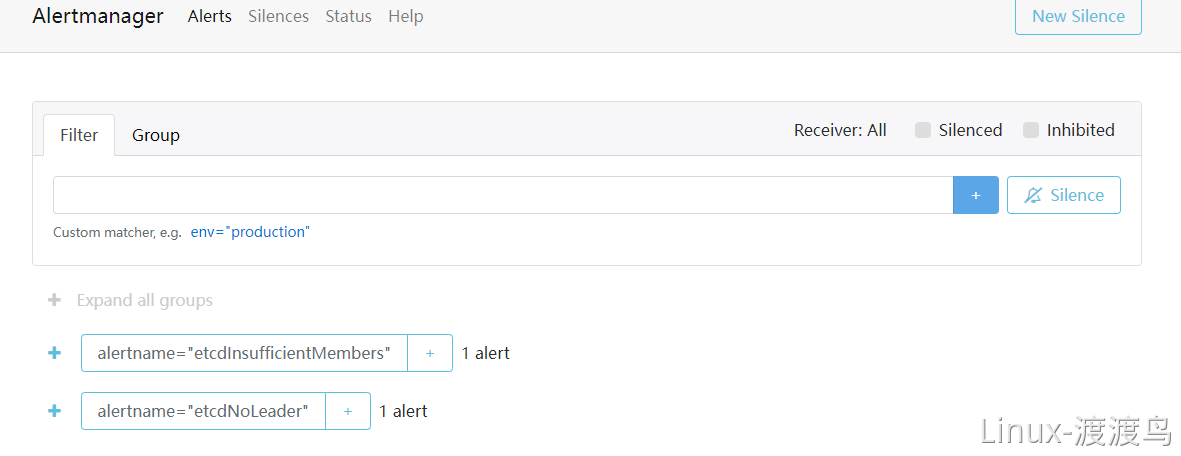
- 配置alertmanager,参考以下配置

若有收获,就点个赞吧
0 人点赞
