Map
https://javadoop.com/post/hashmap (Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析)
Java7 HashMap

HashMap里面是一个数组,数组的每一个元素是一个单向链表。链表中的每一个元素是一个Entry实例,Entry包含四个属性:key、value、hash值和用于单向链表的next。
capacity:当前数组的容量,始终保持2^n,可以扩容,扩容后数组大小是当前的2倍。
loadFactor:负载因子,默认是0.75.
threshold:扩容的阈值。等于capacityloadFactor。
*HashMap的put方法:
public V put(K key, V value) {// 当插入第一个元素的时候,需要先初始化数组大小if (table == EMPTY_TABLE) {inflateTable(threshold);}// 如果 key 为 null,感兴趣的可以往里看,最终会将这个 entry 放到 table[0] 中if (key == null)return putForNullKey(value);// 1. 求 key 的 hash 值int hash = hash(key);// 2. 找到对应的数组下标int i = indexFor(hash, table.length);// 3. 遍历一下对应下标处的链表,看是否有重复的 key 已经存在,// 如果有,直接覆盖,put 方法返回旧值就结束了for (Entry<K,V> e = table[i]; e != null; e = e.next) {Object k;if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}modCount++;// 4. 不存在重复的 key,将此 entry 添加到链表中,细节后面说addEntry(hash, key, value, i);return null;}
数组的初始化:
第一次插入元素的时候进行数组的初始化,首先确定初始数组的大小(2 n ),并计算数组扩容的阈值。
private void inflateTable(int toSize) {// 保证数组大小一定是 2 的 n 次方。// 比如这样初始化:new HashMap(20),那么处理成初始数组大小是 32int capacity = roundUpToPowerOf2(toSize);// 计算扩容阈值:capacity * loadFactorthreshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);// 算是初始化数组吧table = new Entry[capacity];initHashSeedAsNeeded(capacity); //ignore}
计算插入数组的位置:
static int indexFor(int hash, int length) {// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";return hash & (length-1);}
取hash值得低n位,如在数组长度为32的时候,其实就是取的key的hash值得低5位,作为它在数组中的下标位置。
添加节点到链表中:
找到数组下标后,会先进行 key 判重,如果没有重复,就准备将新值放入到链表的表头。
void addEntry(int hash, K key, V value, int bucketIndex) {// 如果当前 HashMap 大小已经达到了阈值,并且新值要插入的数组位置已经有元素了,那么要扩容if ((size >= threshold) && (null != table[bucketIndex])) {// 扩容,后面会介绍一下resize(2 * table.length);// 扩容以后,重新计算 hash 值hash = (null != key) ? hash(key) : 0;// 重新计算扩容后的新的下标bucketIndex = indexFor(hash, table.length);}// 往下看createEntry(hash, key, value, bucketIndex);}// 这个很简单,其实就是将新值放到链表的表头,然后 size++void createEntry(int hash, K key, V value, int bucketIndex) {Entry<K,V> e = table[bucketIndex];table[bucketIndex] = new Entry<>(hash, key, value, e);size++;}
这个方法的主要逻辑就是先判断是否需要扩容,需要的话先扩容,然后再将这个新的数据插入到扩容后的数组的相应位置处的链表的表头。
数组扩容:
如果当前的 size 已经达到了阈值,并且要插入的数组位置上已经有元素,那么就会触发扩容,扩容后,数组大小为原来的 2 倍。
void resize(int newCapacity) {Entry[] oldTable = table;int oldCapacity = oldTable.length;if (oldCapacity == MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return;}// 新的数组Entry[] newTable = new Entry[newCapacity];// 将原来数组中的值迁移到新的更大的数组中transfer(newTable, initHashSeedAsNeeded(newCapacity));table = newTable;threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);}
扩容就是用一个新的大数组替换原来的小数组,并将原来数组中的值迁移到新的数组中。
由于是双倍扩容,迁移过程中,会将原来 table[i] 中的链表的所有节点,分拆到新的数组的 newTable[i] 和 newTable[i + oldLength] 位置上。如原来数组长度是 16,那么扩容后,原来 table[0] 处的链表中的所有元素会被分配到新数组中 newTable[0] 和 newTable[16] 这两个位置。
扩容时的元素迁移使用的是头插法,会出现链表导致,并发访问可能会出现环,导致cpu100%。
get过程:
- 根据 key 计算 hash 值。
- 找到相应的数组下标:hash & (length - 1)。
遍历该数组位置处的链表,直到找到相等(==或equals)的 key。
public V get(Object key) { // 之前说过,key 为 null 的话,会被放到 table[0],所以只要遍历下 table[0] 处的链表就可以了 if (key == null) return getForNullKey(); // Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); } // 遍历链表get具体的entry final Entry<K,V> getEntry(Object key) { if (size == 0) { return null; } int hash = (key == null) ? 0 : hash(key); // 确定数组下标,然后从头开始遍历链表,直到找到为止 for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }Java8 HashMap
Java8对HashMap进行了一些修改,最大的不同就是利用了红黑树,所以其由数组+链表+红黑树组成。
在Java7中,HashMap查找的时候,根据hash值很快能定位到数组的下标,但之后就要遍历链表,时间复杂度取决于链表的长度,为O(n)
在Java8中,当链表的长度达到8时,会将链表转换为红黑树,在这些位置进行查找可以将时间复杂度降低为O(logN)
Java7中使用Entry来代表每个HashMap的数据节点,Java8使用Node,基本没有区别,都是key、value、hash和next四个属性,不过,Node只能用于链表的情况,红黑树的情况需要使用TreeNode。
我们根据数组元素中,第一个节点数据类型是Node还是TreeNode来判断该位置下是链表还是红黑树。
put方法过程分析: ```java public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }
// 第四个参数 onlyIfAbsent 如果是 true,那么只有在不存在该 key 时才会进行 put 操作
// 第五个参数 evict 我们这里不关心
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node
else {// 数组该位置有数据
Node<K,V> e; K k;
// 首先,判断该位置的第一个数据和我们要插入的数据,key 是不是"相等",如果是,取出这个节点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 如果该节点是代表红黑树的节点,调用红黑树的插值方法,本文不展开说红黑树
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 到这里,说明数组该位置上是一个链表
for (int binCount = 0; ; ++binCount) {
// 插入到链表的最后面(Java7 是插入到链表的最前面)
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// TREEIFY_THRESHOLD 为 8,所以,如果新插入的值是链表中的第 8 个
// 会触发下面的 treeifyBin,也就是将链表转换为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 如果在该链表中找到了"相等"的 key(== 或 equals)
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 此时 break,那么 e 为链表中[与要插入的新值的 key "相等"]的 node
break;
p = e;
}
}
// e!=null 说明存在旧值的key与要插入的key"相等"
// 对于我们分析的put操作,下面这个 if 其实就是进行 "值覆盖",然后返回旧值
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 如果 HashMap 由于新插入这个值导致 size 已经超过了阈值,需要进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
和Java7稍微不一样的地方就是,Java7是先扩容后插入新值,Java8是先插值再扩容。java7使用头插法,java8保留元素顺序。<br />**数组扩容:**<br />resize()方法用于初始化数组或数组扩容,每次扩容后,容量是原来的2倍,并进行数据迁移。
```java
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) { // 对应数组扩容
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 将数组大小扩大一倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 将阈值扩大一倍
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // 对应使用 new HashMap(int initialCapacity) 初始化后,第一次 put 的时候
newCap = oldThr;
else {// 对应使用 new HashMap() 初始化后,第一次 put 的时候
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
// 用新的数组大小初始化新的数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab; // 如果是初始化数组,到这里就结束了,返回 newTab 即可
if (oldTab != null) {
// 开始遍历原数组,进行数据迁移。
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 如果该数组位置上只有单个元素,那就简单了,简单迁移这个元素就可以了
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 如果是红黑树,具体我们就不展开了
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
// 这块是处理链表的情况,
// 需要将此链表拆成两个链表,放到新的数组中,并且保留原来的先后顺序
// loHead、loTail 对应一条链表,hiHead、hiTail 对应另一条链表,代码还是比较简单的
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
// 第一条链表
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 第二条链表的新的位置是 j + oldCap,这个很好理解
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
get方法过程分析:
- 计算 key 的 hash 值,根据 hash 值找到对应数组下标: hash & (length-1)
- 判断数组该位置处的元素是否刚好就是我们要找的,如果不是,走第三步
- 判断该元素类型是否是 TreeNode,如果是,用红黑树的方法取数据,如果不是,走第四步
- 遍历链表,直到找到相等(==或equals)的 key
```java
public V get(Object key) {
Node
// 具体获取Node
final Node
// 链表遍历
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
<a name="seVJ1"></a>
### Java7 ConcurrentHashMap
ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。<br />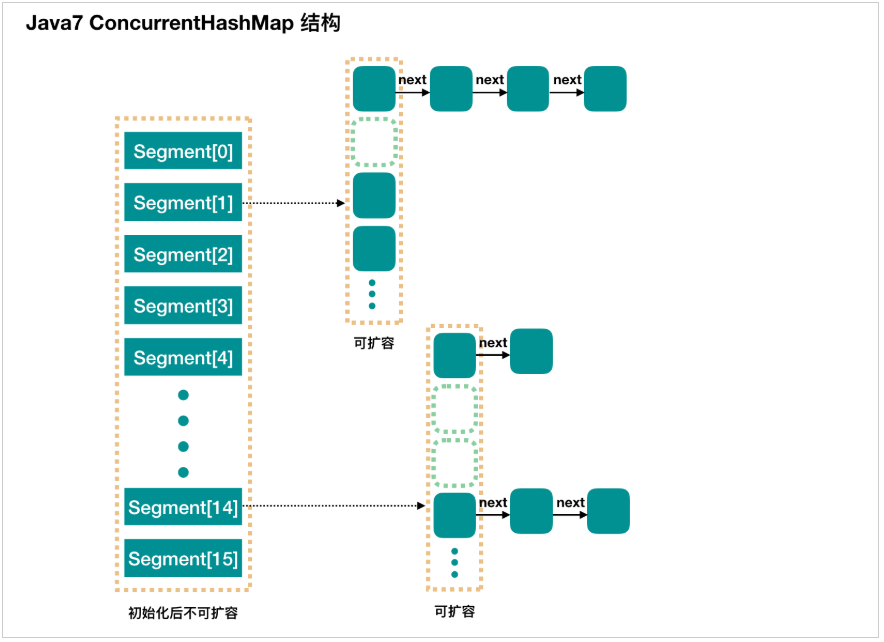<br />**concurrencyLevel:**并行级别、并发数、Segment数,默认为16,也就是说ConcurrentHashMap有16个segments,所以理论上最多支持16个线程并发,只要他们的操作分布在不用的segment上。这个值可以再初始化的时候设置其他值,但一旦初始化就不可以扩容的。<br />每个Segment内部就像一个HashMap,不过需要保证线程安全。<br />**初始化:**<br />initialCapacity:初始容量,这个值指的是整个 ConcurrentHashMap 的初始容量,实际操作的时候需要平均分给每个 Segment。<br />loadFactor:负载因子,之前我们说了,Segment 数组不可以扩容,所以这个负载因子是给每个 Segment 内部使用的。
```java
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
// 计算并行级别 ssize,因为要保持并行级别是 2 的 n 次方
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// 我们这里先不要那么烧脑,用默认值,concurrencyLevel 为 16,sshift 为 4
// 那么计算出 segmentShift 为 28,segmentMask 为 15,后面会用到这两个值
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// initialCapacity 是设置整个 map 初始的大小,
// 这里根据 initialCapacity 计算 Segment 数组中每个位置可以分到的大小
// 如 initialCapacity 为 64,那么每个 Segment 或称之为"槽"可以分到 4 个
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
// 默认 MIN_SEGMENT_TABLE_CAPACITY 是 2,这个值也是有讲究的,因为这样的话,对于具体的槽上,
// 插入一个元素不至于扩容,插入第二个的时候才会扩容
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// 创建 Segment 数组,
// 并创建数组的第一个元素 segment[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
// 往数组写入 segment[0]
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
当使用 new ConcurrentHashMap() 无参构造函数进行初始化,那么初始化完成后:
- Segment 数组长度为 16,不可以扩容
- Segment[i] 的默认大小为 2,负载因子是 0.75,得出初始阈值为 1.5,也就是以后插入第一个元素不会触发扩容,插入第二个会进行第一次扩容
- 这里初始化了 segment[0],其他位置还是 null,至于为什么要初始化 segment[0],后面的代码会介绍
- 当前 segmentShift 的值为 32 - 4 = 28,segmentMask 为 16 - 1 = 15,姑且把它们简单翻译为移位数和掩码,这两个值马上就会用到
put方法过程分析:
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
// 1. 计算 key 的 hash 值
int hash = hash(key);
// 2. 根据 hash 值找到 Segment 数组中的位置 j
// hash 是 32 位,无符号右移 segmentShift(28) 位,剩下高 4 位,
// 然后和 segmentMask(15) 做一次与操作,也就是说 j 是 hash 值的高 4 位,也就是槽的数组下标
int j = (hash >>> segmentShift) & segmentMask;
// 刚刚说了,初始化的时候初始化了 segment[0],但是其他位置还是 null,
// ensureSegment(j) 对 segment[j] 进行初始化
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
// 3. 插入新值到 槽 s 中
return s.put(key, hash, value, false);
}
这一层很简单,根据 hash 值很快就能找到相应的 Segment,之后就是 Segment 内部的 put 操作了。
Segment 内部是由 数组+链表 组成的。
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 在往该 segment 写入前,需要先获取该 segment 的独占锁
// 先看主流程,后面还会具体介绍这部分内容
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
// 这个是 segment 内部的数组
HashEntry<K,V>[] tab = table;
// 再利用 hash 值,求应该放置的数组下标
int index = (tab.length - 1) & hash;
// first 是数组该位置处的链表的表头
HashEntry<K,V> first = entryAt(tab, index);
// 下面这串 for 循环虽然很长,不过也很好理解,想想该位置没有任何元素和已经存在一个链表这两种情况
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
// 覆盖旧值
e.value = value;
++modCount;
}
break;
}
// 继续顺着链表走
e = e.next;
}
else {
// node 到底是不是 null,这个要看获取锁的过程,不过和这里都没有关系。
// 如果不为 null,那就直接将它设置为链表表头;如果是null,初始化并设置为链表表头。
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// 如果超过了该 segment 的阈值,这个 segment 需要扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node); // 扩容后面也会具体分析
else
// 没有达到阈值,将 node 放到数组 tab 的 index 位置,
// 其实就是将新的节点设置成原链表的表头
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
// 解锁
unlock();
}
return oldValue;
}
初始化槽:ensureSegment
ConcurrentHashMap 初始化的时候会初始化第一个槽 segment[0],对于其他槽来说,在插入第一个值的时候进行初始化。这里需要考虑并发,因为很可能会有多个线程同时进来初始化同一个槽 segment[k],不过只要有一个成功了就可以。
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
// 这里看到为什么之前要初始化 segment[0] 了,
// 使用当前 segment[0] 处的数组长度和负载因子来初始化 segment[k]
// 为什么要用“当前”,因为 segment[0] 可能早就扩容过了
Segment<K,V> proto = ss[0];
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
// 初始化 segment[k] 内部的数组
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) { // 再次检查一遍该槽是否被其他线程初始化了。
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
// 使用 while 循环,内部用 CAS,当前线程成功设值或其他线程成功设值后,退出
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
总的来说,ensureSegment(int k) 比较简单,对于并发操作使用 CAS 进行控制。
获取写入锁:scanAndLockForPut
前面我们看到,在往某个 segment 中 put 的时候,首先会调用 node = tryLock() ? null : scanAndLockForPut(key, hash, value),也就是说先进行一次 tryLock() 快速获取该 segment 的独占锁,如果失败,那么进入到 scanAndLockForPut 这个方法来获取锁。
这个方法就是看似复杂,但是其实就是做了一件事,那就是获取该 segment 的独占锁,如果需要的话顺便实例化了一下 node。
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
// 循环获取锁
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
// 进到这里说明数组该位置的链表是空的,没有任何元素
// 当然,进到这里的另一个原因是 tryLock() 失败,所以该槽存在并发,不一定是该位置
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
// 顺着链表往下走
e = e.next;
}
// 重试次数如果超过 MAX_SCAN_RETRIES(单核1多核64),那么不抢了,进入到阻塞队列等待锁
// lock() 是阻塞方法,直到获取锁后返回
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
// 这个时候是有大问题了,那就是有新的元素进到了链表,成为了新的表头
// 所以这边的策略是,相当于重新走一遍这个 scanAndLockForPut 方法
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
这个方法有两个出口,一个是 tryLock() 成功了,循环终止,另一个就是重试次数超过了 MAX_SCAN_RETRIES,进到 lock() 方法,此方法会阻塞等待,直到成功拿到独占锁。
扩容:rehash
重复一下,segment 数组不能扩容,扩容是 segment 数组某个位置内部的数组 HashEntry\
首先,我们要回顾一下触发扩容的地方,put 的时候,如果判断该值的插入会导致该 segment 的元素个数超过阈值,那么先进行扩容,再插值,读者这个时候可以回去 put 方法看一眼。
该方法不需要考虑并发,因为到这里的时候,是持有该 segment 的独占锁的。
// 方法参数上的 node 是这次扩容后,需要添加到新的数组中的数据。
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
// 2 倍
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
// 创建新数组
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
// 新的掩码,如从 16 扩容到 32,那么 sizeMask 为 31,对应二进制 ‘000...00011111’
int sizeMask = newCapacity - 1;
// 遍历原数组,老套路,将原数组位置 i 处的链表拆分到 新数组位置 i 和 i+oldCap 两个位置
for (int i = 0; i < oldCapacity ; i++) {
// e 是链表的第一个元素
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
// 计算应该放置在新数组中的位置,
// 假设原数组长度为 16,e 在 oldTable[3] 处,那么 idx 只可能是 3 或者是 3 + 16 = 19
int idx = e.hash & sizeMask;
if (next == null) // 该位置处只有一个元素,那比较好办
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
// e 是链表表头
HashEntry<K,V> lastRun = e;
// idx 是当前链表的头结点 e 的新位置
int lastIdx = idx;
// 下面这个 for 循环会找到一个 lastRun 节点,这个节点之后的所有元素是将要放到一起的
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
// 将 lastRun 及其之后的所有节点组成的这个链表放到 lastIdx 这个位置
newTable[lastIdx] = lastRun;
// 下面的操作是处理 lastRun 之前的节点,
// 这些节点可能分配在另一个链表中,也可能分配到上面的那个链表中
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// 将新来的 node 放到新数组中刚刚的 两个链表之一 的 头部
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
get方法过程分析:
- 计算 hash 值,找到 segment 数组中的具体位置,或我们前面用的“槽”
- 槽中也是一个数组,根据 hash 找到数组中具体的位置
- 到这里是链表了,顺着链表进行查找即可
public V get(Object key) { Segment<K,V> s; // manually integrate access methods to reduce overhead HashEntry<K,V>[] tab; // 1. hash 值 int h = hash(key); long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; // 2. 根据 hash 找到对应的 segment if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null && (tab = s.table) != null) { // 3. 找到segment 内部数组相应位置的链表,遍历 for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE); e != null; e = e.next) { K k; if ((k = e.key) == key || (e.hash == h && key.equals(k))) return e.value; } } return null; }
Java8 ConcurrentHashMap
Java7 中实现的 ConcurrentHashMap 说实话还是比较复杂的,Java8 对 ConcurrentHashMap 进行了比较大的改动。对于 ConcurrentHashMap,Java8 也引入了红黑树。
初始化:
// 这构造函数里,什么都不干
public ConcurrentHashMap() {
}
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
通过提供初始容量,计算了 sizeCtl,sizeCtl = 【 (1.5 initialCapacity + 1),然后向上取最近的 2 的 n 次方】。如 initialCapacity 为 10,那么得到 sizeCtl 为 16,如果 initialCapacity 为 11,得到 sizeCtl 为 32。
*put方法过程分析:
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 得到 hash 值
int hash = spread(key.hashCode());
// 用于记录相应链表的长度
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果数组"空",进行数组初始化
if (tab == null || (n = tab.length) == 0)
// 初始化数组,后面会详细介绍
tab = initTable();
// 找该 hash 值对应的数组下标,得到第一个节点 f
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 如果数组该位置为空,
// 用一次 CAS 操作将这个新值放入其中即可,这个 put 操作差不多就结束了,可以拉到最后面了
// 如果 CAS 失败,那就是有并发操作,进到下一个循环就好了
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// hash 居然可以等于 MOVED,这个需要到后面才能看明白,不过从名字上也能猜到,肯定是因为在扩容
else if ((fh = f.hash) == MOVED)
// 帮助数据迁移,这个等到看完数据迁移部分的介绍后,再理解这个就很简单了
tab = helpTransfer(tab, f);
else { // 到这里就是说,f 是该位置的头结点,而且不为空
V oldVal = null;
// 获取数组该位置的头结点的监视器锁
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) { // 头结点的 hash 值大于 0,说明是链表
// 用于累加,记录链表的长度
binCount = 1;
// 遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果发现了"相等"的 key,判断是否要进行值覆盖,然后也就可以 break 了
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 到了链表的最末端,将这个新值放到链表的最后面
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) { // 红黑树
Node<K,V> p;
binCount = 2;
// 调用红黑树的插值方法插入新节点
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 判断是否要将链表转换为红黑树,临界值和 HashMap 一样,也是 8
if (binCount >= TREEIFY_THRESHOLD)
// 这个方法和 HashMap 中稍微有一点点不同,那就是它不是一定会进行红黑树转换,
// 如果当前数组的长度小于 64,那么会选择进行数组扩容,而不是转换为红黑树
// 具体源码我们就不看了,扩容部分后面说
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//
addCount(1L, binCount);
return null;
}
初始化数组:initTable
这个比较简单,主要就是初始化一个合适大小的数组,然后会设置 sizeCtl。
初始化方法中的并发问题是通过对 sizeCtl 进行一个 CAS 操作来控制的。
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// 初始化的"功劳"被其他线程"抢去"了
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// CAS 一下,将 sizeCtl 设置为 -1,代表抢到了锁
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
// DEFAULT_CAPACITY 默认初始容量是 16
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
// 初始化数组,长度为 16 或初始化时提供的长度
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
// 将这个数组赋值给 table,table 是 volatile 的
table = tab = nt;
// 如果 n 为 16 的话,那么这里 sc = 12
// 其实就是 0.75 * n
sc = n - (n >>> 2);
}
} finally {
// 设置 sizeCtl 为 sc,我们就当是 12 吧
sizeCtl = sc;
}
break;
}
}
return tab;
}
链表转红黑树:treeifyBin
treeifyBin 不一定就会进行红黑树转换,也可能是仅仅做数组扩容。
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
// MIN_TREEIFY_CAPACITY 为 64
// 所以,如果数组长度小于 64 的时候,其实也就是 32 或者 16 或者更小的时候,会进行数组扩容
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
// 后面我们再详细分析这个方法
tryPresize(n << 1);
// b 是头结点
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
// 加锁
synchronized (b) {
if (tabAt(tab, index) == b) {
// 下面就是遍历链表,建立一颗红黑树
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
// 将红黑树设置到数组相应位置中
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
扩容:tryPresize
// 首先要说明的是,方法参数 size 传进来的时候就已经翻了倍了
private final void tryPresize(int size) {
// c:size 的 1.5 倍,再加 1,再往上取最近的 2 的 n 次方。
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);
int sc;
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table; int n;
// 这个 if 分支和之前说的初始化数组的代码基本上是一样的,在这里,我们可以不用管这块代码
if (tab == null || (n = tab.length) == 0) {
n = (sc > c) ? sc : c;
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
sc = n - (n >>> 2); // 0.75 * n
}
} finally {
sizeCtl = sc;
}
}
}
else if (c <= sc || n >= MAXIMUM_CAPACITY)
break;
else if (tab == table) {
// 我没看懂 rs 的真正含义是什么,不过也关系不大
int rs = resizeStamp(n);
if (sc < 0) {
Node<K,V>[] nt;
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// 2. 用 CAS 将 sizeCtl 加 1,然后执行 transfer 方法
// 此时 nextTab 不为 null
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
// 1. 将 sizeCtl 设置为 (rs << RESIZE_STAMP_SHIFT) + 2)
// 我是没看懂这个值真正的意义是什么?不过可以计算出来的是,结果是一个比较大的负数
// 调用 transfer 方法,此时 nextTab 参数为 null
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
}
}
}
这个方法的核心在于 sizeCtl 值的操作,首先将其设置为一个负数,然后执行 transfer(tab, null),再下一个循环将 sizeCtl 加 1,并执行 transfer(tab, nt),之后可能是继续 sizeCtl 加 1,并执行 transfer(tab, nt)。
所以,可能的操作就是执行 1 次 transfer(tab, null) + 多次 transfer(tab, nt),这里怎么结束循环的需要看完 transfer 源码才清楚。
get方法过程分析:
- 计算 hash 值
- 根据 hash 值找到数组对应位置: (n - 1) & h
根据该位置处结点性质进行相应查找
- 如果该位置为 null,那么直接返回 null 就可以了
- 如果该位置处的节点刚好就是我们需要的,返回该节点的值即可
- 如果该位置节点的 hash 值小于 0,说明正在扩容,或者是红黑树,后面我们再介绍 find 方法
如果以上 3 条都不满足,那就是链表,进行遍历比对即可
public V get(Object key) { Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; int h = spread(key.hashCode()); if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) { // 判断头结点是否就是我们需要的节点 if ((eh = e.hash) == h) { if ((ek = e.key) == key || (ek != null && key.equals(ek))) return e.val; } // 如果头结点的 hash 小于 0,说明 正在扩容,或者该位置是红黑树 else if (eh < 0) // 参考 ForwardingNode.find(int h, Object k) 和 TreeBin.find(int h, Object k) return (p = e.find(h, key)) != null ? p.val : null; // 遍历链表 while ((e = e.next) != null) { if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) return e.val; } } return null; }ConcurrentSkipListMap
特点:有序链表的实现,无锁实现;value不能为空;层级越高跳跃性越大,数据越少,查询理论越快。
新的Node是否抽出来作为Index,随机决定。
- index对应的level由随机数决定。(随机数比特位连续为1的数量)
- 每层的元素,headIndex固定为所有Node中最小的。
查找数据时,按照从下到上,从左往右的顺序查找。
时间复杂度O(logN),空间复杂度O(n)。
空间换时间,数据库索引类似的概念,skiplist在很多开源组件中有使用(levelDB、Redis)
put方法过程分析:
private V doPut(K key, V value, boolean onlyIfAbsent) {
Node<K,V> z; // added node
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer: for (;;) {// 查找这个节点应该塞到哪一个节点后面 cas+循环,无锁,不断重试
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
if (n != null) { // n 代表next位置,不为空则代表已经有数据存在,应该继续寻找后续的位置
Object v; int c;
Node<K,V> f = n.next;
if (n != b.next) // inconsistent read 如果next发生了变化,表示出现脏读,则退出重试
break;
if ((v = n.value) == null) { // n is deleted // 如果next节点的内容置空了,则应该删除该节点
n.helpDelete(b, f);
break;
}
if (b.value == null || v == n) // b is deleted // 如果当前node内容置空了,则退出重试
break;
if ((c = cpr(cmp, key, n.key)) > 0) { // 比较next和当前要插入的key,如果大于next的key,则继续寻找后续的next
b = n;
n = f;
continue;
}
if (c == 0) { // c 比对的结果,如果为0,则代表key相等,相等则直接cas替换
if (onlyIfAbsent || n.casValue(v, value)) {
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
break; // restart if lost race to replace value
}
// else c < 0; fall through
}
// 如果找到了合适的前置节点
z = new Node<K,V>(key, value, n); //
if (!b.casNext(n, z)) // CAS 将当前数据塞到前置节点后面
break; // restart if lost race to append to b // 如果失败,继续循环
break outer;
}
}
// 上面的代码,是将node插入到合适的位置。接下来就需要重构一下skiplist,判断是否需要增加level
// Tony: 防止源码编译报错,我注释掉了后面一段
int rnd = 0; // ThreadLocalRandom.nextSecondarySeed(); // 这里的代码是生成随机数
if ((rnd & 0x80000001) == 0) { // test highest and lowest bits // 随机数是正偶数,则升级level
int level = 1, max;
while (((rnd >>>= 1) & 1) != 0) // 根据随机数计算level。从低2位开始向左有多少个连续的1
++level;
Index<K,V> idx = null;
HeadIndex<K,V> h = head;
if (level <= (max = h.level)) {// 随机计算出来的level小于当前的level级别,不需要增加层级
for (int i = 1; i <= level; ++i)
idx = new Index<K,V>(z, idx, null); // 构建一个index,归属于随机到的level
}
else { // try to grow by one level // 升级
level = max + 1; // hold in array and later pick the one to use // 每次升一级
@SuppressWarnings("unchecked")Index<K,V>[] idxs =
(Index<K,V>[])new Index<?,?>[level+1]; // 创建一个index集合,数量是level数量
for (int i = 1; i <= level; ++i) // 给上面新建的数组,赋值(idxs好像没什么卵用)
idxs[i] = idx = new Index<K,V>(z, idx, null);
for (;;) {
h = head;
int oldLevel = h.level;
if (level <= oldLevel) // 新level小于就得level,代表其他线程更新了level,此次升级失败。
break;
HeadIndex<K,V> newh = h;
Node<K,V> oldbase = h.node;
for (int j = oldLevel+1; j <= level; ++j)
newh = new HeadIndex<K,V>(oldbase, newh, idxs[j], j); // 生成一个新的headIndex。最高level
if (casHead(h, newh)) { // 将head引用到新的index
h = newh;
idx = idxs[level = oldLevel];
break;
}
}
}
// find insertion points and splice in //将新的Index插入对应level链表上
splice: for (int insertionLevel = level;;) {
int j = h.level;
for (Index<K,V> q = h, r = q.right, t = idx;;) {// 从head index开始找位置
if (q == null || t == null)
break splice;
if (r != null) { // 比对,找到level中合适的节点进行插入
Node<K,V> n = r.node;
// compare before deletion check avoids needing recheck
int c = cpr(cmp, key, n.key);
if (n.value == null) {
if (!q.unlink(r))
break;
r = q.right;
continue;
}
if (c > 0) {
q = r;
r = r.right;
continue;
}
}
if (j == insertionLevel) {
if (!q.link(r, t))
break; // restart
if (t.node.value == null) {
findNode(key);
break splice;
}
if (--insertionLevel == 0)
break splice;
}
if (--j >= insertionLevel && j < level)
t = t.down;
q = q.down;
r = q.right;
}
}
}
return null;
}
List
CopyOnWriteArrayList
CopyOnWriteArrayList即写时复制的容器,和ArrayList比较,优点是并发安全的,缺点有两个:
- 多了内存占用:写数据是copy一份完整的数据,单独进行操作。占用双份内存。
- 数据一致性:数据写完之后,其他线程不一定马上读取到最新的内容。

Set
set和list的区别:不重复
Queue
Queue-队列数据结构的实现。分为阻塞队列和非阻塞队列。下面蓝色区块为阻塞队列的特有方法。
ArrayBlockingQueue
// 它是基于数组的阻塞循环队列, 此队列按 FIFO(先进先出)原则对元素进行排序。
public class ArrayBlockingQueueDemo {
public static void main(String[] args) throws InterruptedException {
// 构造时需要指定容量(量力而行),可以选择是否需要公平(最先进入阻塞的,先操作)
ArrayBlockingQueue<String> queue = new ArrayBlockingQueue<>(3, false);
// 1秒消费数据一个
new Thread(() -> {
while (true) {
try {
System.out.println("取到数据:" + queue.poll()); // poll非阻塞
Thread.sleep(1000L);
} catch (InterruptedException e) {
}
}
}).start();
Thread.sleep(3000L); // 让前面的线程跑起来
// 三个线程塞数据
for (int i = 0; i < 6; i++) {
new Thread(() -> {
try {
queue.put(Thread.currentThread().getName()); // put阻塞(如果当前的队列已经塞满了数据,线程不会继续往下执行,等待其他线程把
// 队列的数据拿出去// )
// queue.offer(Thread.currentThread().getName()); // offer非阻塞,满了返回false
System.out.println(Thread.currentThread() + "塞入完成");
} catch (Exception e) {
e.printStackTrace();
}
}).start();
}
}
}
LinkedBlockingQueue
// 它是基于链表的队列,此队列按 FIFO(先进先出)排序元素。
// 如果有阻塞需求,用这个。类似生产者消费者场景
public class LinkedBlockingQueueDemo {
public static void main(String[] args) throws InterruptedException {
// 构造时可以指定容量,默认Integer.MAX_VALUE
LinkedBlockingQueue<String> queue = new LinkedBlockingQueue<String>(3);
// 1秒消费数据一个
new Thread(() -> {
while (true) {
try {
System.out.println("取到数据:" + queue.poll()); // poll非阻塞
Thread.sleep(1000L);
} catch (InterruptedException e) {
}
}
}).start();
Thread.sleep(3000L); // 让前面的线程跑起来
// 三个线程塞数据
for (int i = 0; i < 6; i++) {
new Thread(() -> {
try {
// queue.put(Thread.currentThread().getName()); // put阻塞
queue.offer(Thread.currentThread().getName()); // offer非阻塞,满了返回false
System.out.println(Thread.currentThread() + "塞入完成");
} catch (Exception e) {
e.printStackTrace();
}
}).start();
}
}
}
PriorityQueue
// 是一个带优先级的 队列,而不是先进先出队列。
// 元素按优先级顺序被移除,该队列也没有上限
// 没有容量限制的,自动扩容
// 虽然此队列逻辑上是无界的,但是由于资源被耗尽,所以试图执行添加操作可能会导致 OutOfMemoryError),
// 但是如果队列为空,
// 那么取元素的操作take就会阻塞,所以它的检索操作take是受阻的。另外,
// 入该队列中的元素要具有比较能力
public class PriorityQueueDemo {
public static void main(String[] args) {
// 可以设置比对方式
PriorityQueue<String> priorityQueue = new PriorityQueue<>(new Comparator<String>() {
@Override //
public int compare(String o1, String o2) {
// 实际就是 元素之间的 比对。
return 0;
}
});
priorityQueue.add("c");
priorityQueue.add("a");
priorityQueue.add("b");
System.out.println(priorityQueue.poll());
System.out.println(priorityQueue.poll());
System.out.println(priorityQueue.poll());
PriorityQueue<MessageObject> MessageObjectQueue = new PriorityQueue<>(new Comparator<MessageObject>() {
@Override
public int compare(MessageObject o1, MessageObject o2) {
return o1.order > o2.order ? -1 : 1;
}
});
}
}
class MessageObject {
String content;
int order;
}
PriorityBlockingQueue
// 包装了 PriorityQueue
// 是一个带优先级的 队列,而不是先进先出队列。
// 元素按优先级顺序被移除,该队列也没有上限
// 没有容量限制的,自动扩容
// 虽然此队列逻辑上是无界的,但是由于资源被耗尽,所以试图执行添加操作可能会导致 OutOfMemoryError),
// 但是如果队列为空,
// 那么取元素的操作take就会阻塞,所以它的检索操作take是受阻的。另外,
// 入该队列中的元素要具有比较能力
public class PriorityBlockingQueueDemo {
public static void main(String[] args) {
// 可以设置比对方式
PriorityBlockingQueue<String> priorityQueue = new PriorityBlockingQueue<>(2);
priorityQueue.add("c");
priorityQueue.add("a");
priorityQueue.add("b");
System.out.println(priorityQueue.poll());
System.out.println(priorityQueue.poll());
System.out.println(priorityQueue.poll());
}
}
DelayQueue
// (基于PriorityQueue来实现的)是一个存放Delayed 元素的无界阻塞队列,
// 只有在延迟期满时才能从中提取元素。该队列的头部是延迟期满后保存时间最长的 Delayed 元素。
// 如果延迟都还没有期满,则队列没有头部,并且poll将返回null。
// 当一个元素的 getDelay(TimeUnit.NANOSECONDS) 方法返回一个小于或等于零的值时,
// 则出现期满,poll就以移除这个元素了。此队列不允许使用 null 元素。
public class DelayQueueDemo {
public static void main(String[] args) throws InterruptedException {
DelayQueue<Message> delayQueue = new DelayQueue<Message>();
// 这条消息5秒后发送
Message message = new Message("message - 00001", new Date(System.currentTimeMillis() + 5000L));
delayQueue.add(message);
while (true) {
System.out.println(delayQueue.poll());
Thread.sleep(1000L);
}
// 线程池中的定时调度就是这样实现的
}
}
// 实现Delayed接口的元素才能存到DelayQueue
class Message implements Delayed {
// 判断当前这个元素,是不是已经到了需要被拿出来的时间
@Override
public long getDelay(TimeUnit unit) {
// 默认纳秒
long duration = sendTime.getTime() - System.currentTimeMillis();
return TimeUnit.NANOSECONDS.convert(duration, TimeUnit.MILLISECONDS);
}
@Override
public int compareTo(Delayed o) {
return o.getDelay(TimeUnit.NANOSECONDS) > this.getDelay(TimeUnit.NANOSECONDS) ? 1 : -1;
}
String content;
Date sendTime;
/**
* @param content 消息内容
* @param sendTime 定时发送
*/
public Message(String content, Date sendTime) {
this.content = content;
this.sendTime = sendTime;
}
@Override
public String toString() {
return "Message{" +
"content='" + content + '\'' +
", sendTime=" + sendTime +
'}';
}
}
SynchronousQueue
SynchronousQueue没有容量,与其他BlockingQueue不同,SynchronousQueue是一个不存储元素的BlockingQueue。每一个put操作必须等待一个take操作,否则不能继续添加元素,反之亦然。
public class BlockingQueueDemo {
public static void main(String[] args) {
BlockingQueue<String> queue = new SynchronousQueue<>();
new Thread(()->{
try {
System.out.println(Thread.currentThread().getName()+"\t put 1");
queue.put("1");
System.out.println(Thread.currentThread().getName()+"\t put 2");
queue.put("2");
System.out.println(Thread.currentThread().getName()+"\t put 3");
queue.put("3");
} catch (InterruptedException e) {
e.printStackTrace();
}
},"AAA").start();
new Thread(()->{
for (int i=0;i<3;i++) {
try {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "\t" + queue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"BBB").start();
}
}
Fork_join框架
ForkJoinPool是ExecutorService接口的实现,它专为可以递归分解成小块的工作而设计。
fork/join框架将任务分配给线程池中的工作线程,充分利用多处理器的优势,提高程序性能。
使用fork/join框架的第一步是编写执行不部分工作的代码,类似的伪代码如下:
将此代码包装在ForkJoinTask子类中,通常是RecursiveTask(可以返回结果)或RecursiveAction。
意图梳理
关键点:分解任务fork出新任务,汇集join任务执行结果。
实现思路
- 每个Worker线程都维护一个任务队列,即ForkJoinWorkerThread中的任务队列
- 任务队列是双向队列,这样可以同时实现LIFO和FIFO
- 子任务会被加入到原先任务所在Worker线程的任务队列
- Worker线程用LIFO的方式取出任务,后进任务队列的先取出来(子任务总是后进队列,但是需要先执行)
- 当任务队列为空,会随机从其他的worker的队列中拿走一个任务执行(工作窃取:steal work)
- 如果一个worker线程遇到了join操作,而这时候正在处理其他任务,会等到这个任务执行结束,否则直接返回
如果一个worker线程窃取任务失败,它会用yield或者sleep之类的方法休息一会,再尝试(如果所有线程都是空闲状态,即没有任务运行,那么该线程也会进入阻塞状态等待新任务的到来) ```java /**
并行调用http接口 */ @Service public class UserServiceForkJoin { // 本质是一个线程池,默认的线程数量:CPU的核数 ForkJoinPool forkJoinPool = new ForkJoinPool(10, ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);@Autowired private RestTemplate restTemplate;
/**
查询多个系统的数据,合并返回 */ public Object getUserInfo(String userId) throws ExecutionException, InterruptedException { // 其他例子, 查数据库的多个表数据,分多次查询 // fork/join // forkJoinPool.submit() ArrayList
urls = new ArrayList<>(); urls.add(“http://www.tony.com/userinfo-api/get?userId=“ + userId); urls.add(“http://www.tony.com/integral-api/get?userId=“ + userId); HttpJsonRequest httpJsonRequest = new HttpJsonRequest(restTemplate, urls, 0, urls.size() - 1); ForkJoinTask
forkJoinTask = forkJoinPool.submit(httpJsonRequest); JSONObject result = forkJoinTask.get(); return result; } }
// 任务
class HttpJsonRequest extends RecursiveTask
RestTemplate restTemplate;
ArrayList<String> urls;
int start;
int end;
HttpJsonRequest(RestTemplate restTemplate, ArrayList<String> urls, int start, int end) {
this.restTemplate = restTemplate;
this.urls = urls;
this.start = start;
this.end = end;
}
// 就是实际去执行的一个方法入口(任务拆分)
@Override
protected JSONObject compute() {
int count = end - start; // 代表当前这个task需要处理多少数据
// 自行根据业务场景去判断是否是大任务,是否需要拆分
if (count == 0) {
String url = urls.get(start);
// TODO 如果只有一个接口调用,立刻调用
long userinfoTime = System.currentTimeMillis();
String response = restTemplate.getForObject(url, String.class);
JSONObject value = JSONObject.parseObject(response);
System.out.println(Thread.currentThread() + " 接口调用完毕" + (System.currentTimeMillis() - userinfoTime) + " #" + url);
return value;
} else { // 如果是多个接口调用,拆分成子任务 7,8, 9,10
System.out.println(Thread.currentThread() + "任务拆分一次");
int x = (start + end) / 2;
HttpJsonRequest httpJsonRequest = new HttpJsonRequest(restTemplate, urls, start, x);// 负责处理哪一部分?
httpJsonRequest.fork();
HttpJsonRequest httpJsonRequest1 = new HttpJsonRequest(restTemplate, urls, x + 1, end);// 负责处理哪一部分?
httpJsonRequest1.fork();
// join获取处理结果
JSONObject result = new JSONObject();
result.putAll(httpJsonRequest.join());
result.putAll(httpJsonRequest1.join());
return result;
}
}
}
<a name="fd8hG"></a>
#### 适用
- 适用尽可能少的线程池,在大多数情况下,最好的决定是为每个应用程序或系统使用一个线程池
- 如果不需要特定调整,使用默认的公共线程池
- 使用合理的阈值将ForkJoinTask拆分为子任务(CPU线程数)
- 避免在ForkJoinTask中出现阻塞
- 适合数据处理、结果汇总、统计等场景
- Java8中使用实例:java.util.Arrays类用于其parallelSort()方法
<a name="7M4np"></a>
### FutureTask
<a name="PgaRO"></a>
#### Future
Future表示异步计算的结果,提供了用于检查计算是否完成、等待计算完成,以及获取结果的方法。<br />
<a name="4xntm"></a>
#### Callable
有返回值的任务必须实现 Callable 接口,类似的,无返回值的任务必须 Runnable 接口。执行 Callable 任务后,可以获取一个 Future 的对象,在该对象上调用 get 就可以获取到 Callable 任务 返回的 Object 了,再结合线程池接口 ExecutorService 就可以实现传说中有返回结果的多线程了。<br />**使用线程池执行Callable:**
```java
public class FutureDemo {
public static void main(String[] args) throws Exception {
// 创建线程池
ExecutorService callablePool = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.SECONDS,
new LinkedBlockingDeque<Runnable>(), new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r);
}
});
long oldTime = System.currentTimeMillis();
// 创建多个有返回值的任务
List<Future> list = new ArrayList();
for (int i=0;i<8;i++){
Callable callable = new MyCallable(i+"");
// 执行任务并获取Future对象
Future future = callablePool.submit(callable);
list.add(future);
}
//关闭线程池
callablePool.shutdown();
// 获取所有并发任务的执行结果
for(Future f : list){
// 从 Future 对象上获取任务的返回值,并输出到控制台
System.out.println("Res: "+ f.get().toString());
}
System.out.println("总用时:"+(System.currentTimeMillis()-oldTime)+"ms");
}
}
class MyCallable implements Callable {
private String i;
public MyCallable(String i){
this.i = i;
}
@Override
public Object call() throws Exception {
long delay = (long) (Math.random()*3000+2000);
Thread.sleep(delay);
return "callable-"+i+", delay: "+delay;
}
}
使用FutureTask执行Callable:
public class FutureDemo1 {
public static void main(String[] args) throws Exception {
long oldTime = System.currentTimeMillis();
// 创建多个有返回值的任务
List<FutureTask> list = new ArrayList();
for (int i=0;i<8;i++){
Callable callable = new MyCallable1(i+"");
// 用FutureTask包装Callable
FutureTask futureTask = new FutureTask(callable);
list.add(futureTask);
new Thread(futureTask).start();
}
// 获取所有并发任务的执行结果
for(FutureTask f : list){
// 从 Future 对象上获取任务的返回值,并输出到控制台
System.out.println("Res: "+ f.get());
}
System.out.println("总用时:"+(System.currentTimeMillis()-oldTime)+"ms");
}
}
class MyCallable1 implements Callable {
private String i;
public MyCallable1(String i){
this.i = i;
}
@Override
public Object call() throws Exception {
long delay = (long) (Math.random()*3000+2000);
Thread.sleep(delay);
return "callable-"+i+", delay: "+delay;
}
}
Callable和Runnable的区别
- Callable有返回值,Runnable没有
- Callable可以抛异常,Runnable没有
- Callable重写call方法,Runnable重写run方法
- 在线程池中Callable使用submit方法并返回Future,Runnable使用execute方法
- Callable本质上是被Runnable调用,call方法最终运行在run方法中
FutureTask应用

- 总的执行时间取决于执行最慢的任务。
- 逻辑之间无依赖关系,可同时执行,则可以应用多线程技术进行优化。
模拟实现FutureTask:
// (jdk本质,就是利用一些底层API,为开发人员提供便利)
public class DukzFutureTask<T> implements Runnable, Future { // 获取 线程异步执行结果 的方式
Callable<T> callable; // 业务逻辑在callable里面
T result = null;
volatile String state = "NEW"; // task执行状态
LinkedBlockingQueue<Thread> waiters = new LinkedBlockingQueue<>();// 定义一个存储等待者的集合
public DukzFutureTask(Callable<T> callable) {
this.callable = callable;
}
@Override
public void run() {
try {
result = callable.call();
} catch (Exception e) {
e.printStackTrace();
// result = exception
} finally {
state = "END";
}
// 唤醒等待者
Thread waiter = waiters.poll();
while (waiter != null) {
LockSupport.unpark(waiter);
waiter = waiters.poll(); // 继续取出队列中的等待者
}
}
// 返回结果,
@Override
public T get() {
if ("END".equals(state)) {
return result;
}
waiters.offer(Thread.currentThread()); // 加入到等待队列,线程不继续往下执行
while (!"END".equals(state)) {
LockSupport.park(); // 线程通信的知识点
}
// 如果没有结束,那么调用get方法的线程,就应该进入等待
return result;
}
@Override
public boolean cancel(boolean mayInterruptIfRunning) {
return false;
}
@Override
public boolean isCancelled() {
return false;
}
@Override
public boolean isDone() {
return false;
}
@Override
public Object get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException {
return null;
}
}

若有收获,就点个赞吧
0 人点赞
